時系列基盤モデルへ②:UniTS【論文】


UniTS: Building a Unified Time Series Model
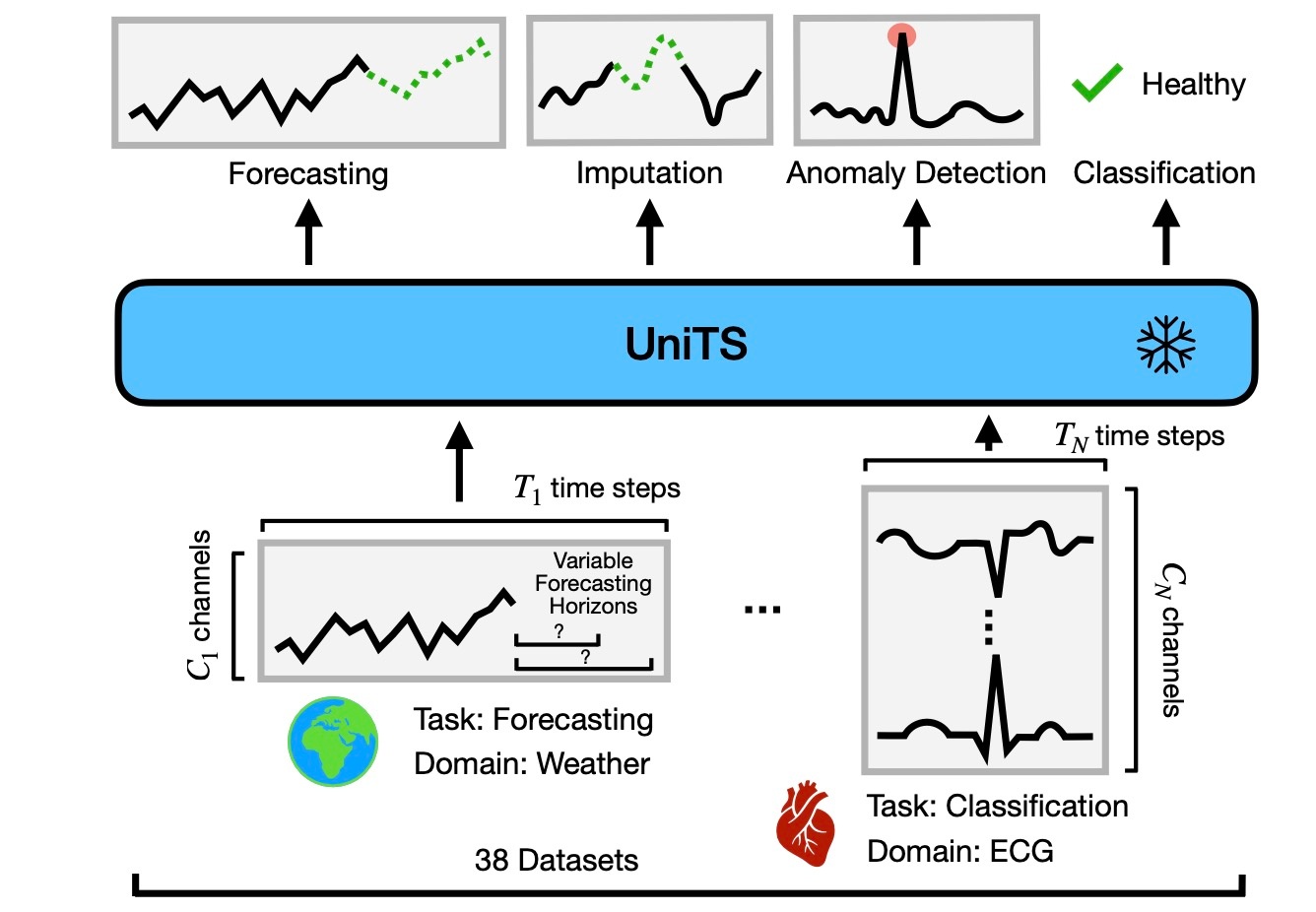
今回も, 前回に引き続き時系列基盤モデルを確認します. 今回はUniTSというモデルです. とても簡単にまとめると以下の図のようになります.
関連リンク
問題設定
まずは, この論文でどのようなタスクを解きたいのかを設定します. 以後登場する文字は断りのない限りここで定義したものです.
与えられるのは, 複数ドメインのデータセットの集合
時系列データは
- sequence token:
\boldsymbol{z}_s\in\mathbb{R}^{l_s\times v\times d} - prompt token:
\boldsymbol{z}_p\in\mathbb{R}^{l_p\times v\times d} - mask token:
\boldsymbol{z}_m\in\mathbb{R}^{1\times v\times d} - CLS token:
\boldsymbol{z}_c\in\mathbb{R}^{1\times v\times d} - category token:
\boldsymbol{z}_e\in\mathbb{R}^{k\times v\times d}
時系列タスクでは, 様々な性質を持つデータと様々なタスクが考えられるので, それらに合わせてモデル設計をしていました. しかし, ここではそれを統一的に行うことを考えます. すなわち, 任意のタスクについて
- Multi-domain time series: モデル
F x l_{\mathrm{in}} v \mathcal{X} - Universal task specification: モデル
F \mathcal{Y} F(\mathcal{X}, \theta)\rightarrow\mathcal{Y} - No task-specific modules: タスク間で重み
\theta F
仰々しく書かれていますが, 様々な時系列データと時系列タスクに対応し, それをfine-tuningなしでこなせるモデルを作ることが目標になります.
UniTS Model
まず, UniTSの全体像を確認します. 下図の(b)や(c)をみてわかるように, promptベースのモデルになります. モデルへの入力はprompt token, sequence token, task tokenの3つのトークンを結合したものになります.
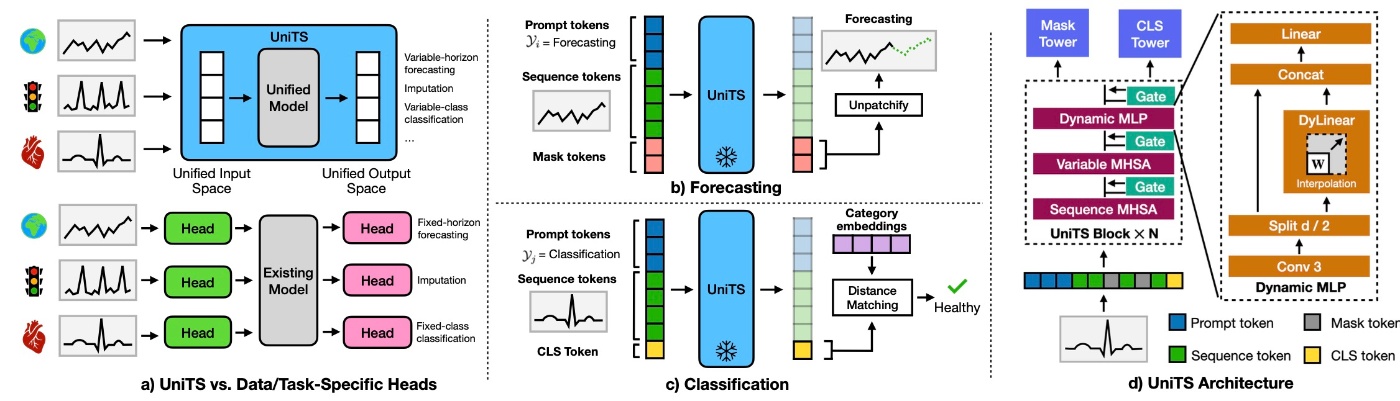
これらプロンプトを駆使して異なるタスクを統一的に扱います. それぞれ確認します.
sequence token
PatchTSTにしたがって, 時系列データ
このアプローチはLLMsなどの他の分野からの統一モデルの直接的な適用を阻害します. これに対処するために, 任意の数の変量を処理できる柔軟なネットワーク構造を提案しています.
prompt token
prompt token
task token
図の(b, c)に示されるように, task tokenは以下の2つの主要なタイプに分類されます.
- Mask token: 予測, 補完, 異常検知などの生成モデリングで用います.
- CLS token and category embeddings: 分類などの認識タスクで用います.
task tokenはタスクを表現する一般的なフォーマットを定義することで, 新しいタスクに柔軟に対応することが可能です.
- 予測: mask token
\boldsymbol{z}_m - 分類: UNITS 出力の CLS token
\boldsymbol{z}_c \boldsymbol{z}_e - 補完: 欠損部分はmask tokenを用いて補完されます.
- 異常検知: モデルが返すノイズ除去されたsequence tokenを用いて, 異常なデータポイントを特定します
どのようにtask tokenを作るかですが, Appendix C.1に書かれています. ここでは予測タスクの場合を確認します.
mask token
です. CAはconcatenation, REはrepeatを表します.
続いて, アーキテクチャの部分を見ます. 先ほどの図の(d)を再掲します.

これを見ればわかるように, UniTS Blockを
以降では, 主要な3つのモジュールとDynamic MLPの中にあるDyLinearについて深掘りします.
Sequence and Variable MHSA
時系列データは系列長や変量の数が異なりますが, それらを統一的に扱うのがこの2つのモジュールになっています. 統一的に扱うとは言っても片方ずつ処理して最終的に幅広いデータに対応します. Sequence MHSAはPatchTSTでも用いられているMHSAをそのまま利用します. Variable MHSAは長い系列に対する計算量を抑えつつ, 系列全体にわたる変量の関係性を細くするために
Variable MHSAの出力は当然
です. 簡単のためSingle Headで記述されていますが, 実際にはMulti-Headで行います.
DyLinear
Sequence MHSAは普通のattentionなので類似度ベースです. それとは対照的に, token間の密な関係をモデリングする動的線形演算子DyLinearをここでは導入します. 様々な系列長に対応するための重み補完スキームと見ることができて, 長さ
Interpはバイリニア補完で
Dynamic MLP
DyLinearを盛り込んで, 局所的な詳細と大域的な関係性を捉えるモジュールです. 局所的な詳細を捉えるためにkernel sizeが3の畳み込み層を適用します. その後,
Training
生成タスクと認識タスクに対応するための学習を行います. 基本的にはmasked modelingですが, prompt tokenとCLS tokenの両方の意味内容を効果的に再構成します. lossは以下のように表されます.
masked modelingとは別の学習方法として, 教師あり学習を行います (公式実装を見る限り追加訓練ではないと思います). 1つのデータセットからランダムに取り出して行います. lossは
で,
実験
データセットとベースラインを確認してから実験結果を見ます.
データセット
38のデータを集めて用います. human activity, healthcare, financeなどの多様なドメインを持ち, 20は系列長が60から720までの予測タスク, 18が2クラスから52クラスまでの分類タスクです. 以下に概要を示します.
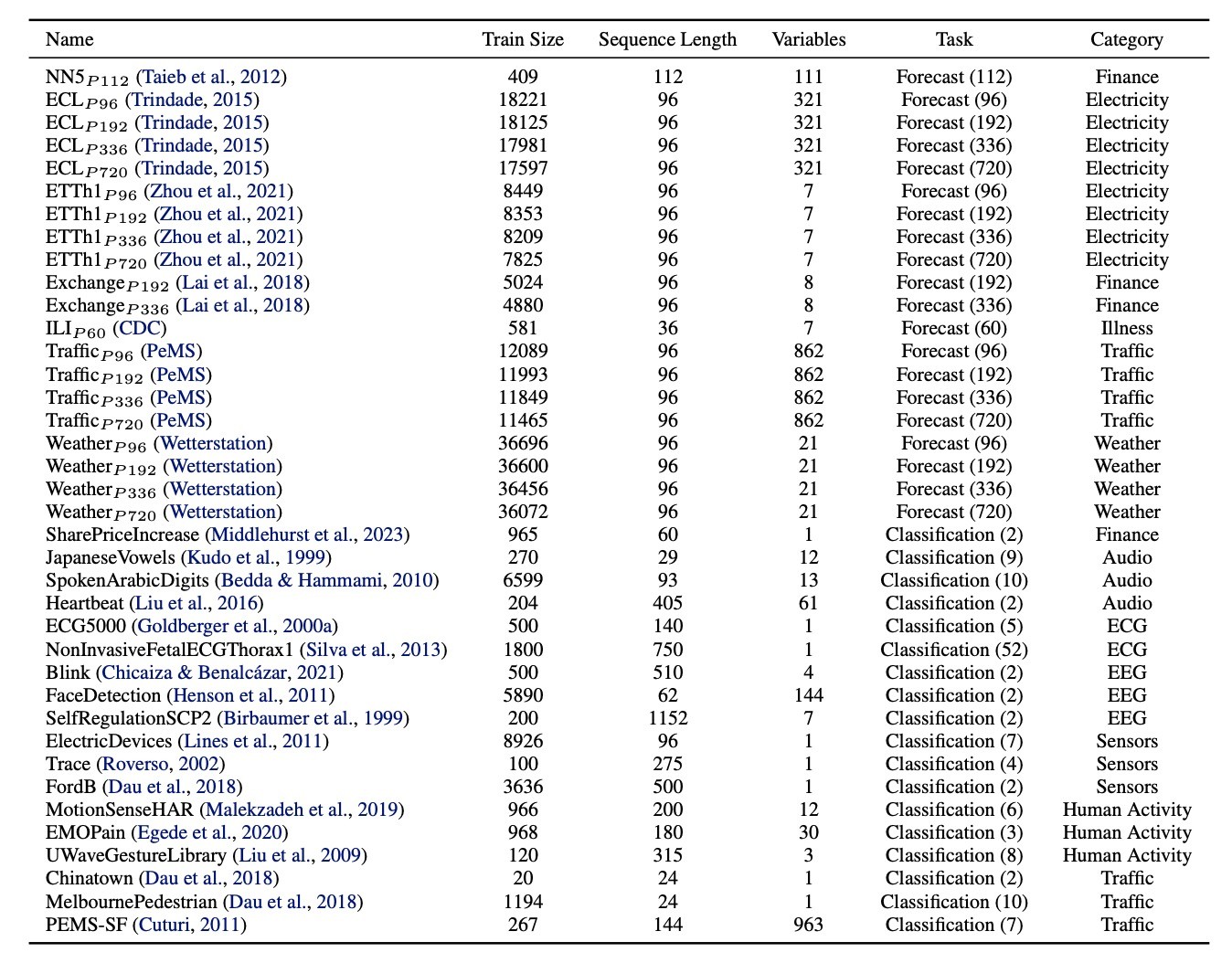
ベースライン
7つのベースラインを用意します. iTransformer, TimesNet, PatchTST, Pyraformer, Autoformer, GPT4TS, LLMTimeです.
LLMを使うようなものでは予測にしか対応していない場合がありますが, その場合は分類モジュールを追加して対応します.
結果: Multi-Task Learning
早速結果を示します.
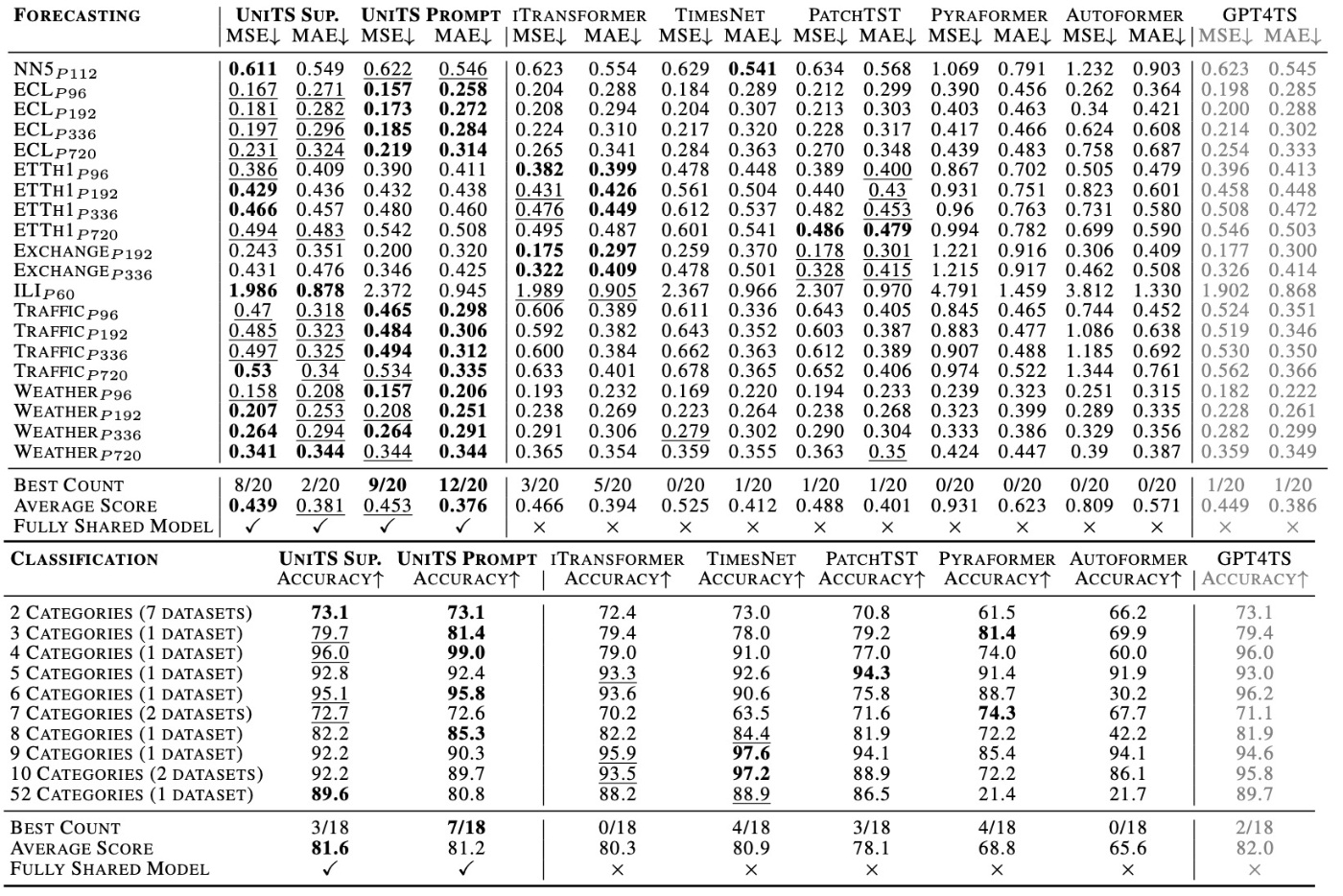
まず, UniTS Promptと書かれたmasked modelingを行った結果を見ます. 多くの場合でbestあるいはsecond bestの性能であることがわかります.
また, ベースラインは単一タスクのみで高性能で複数タスクには対応できていないことがわかります. 例えばTimesNetでは分類タスクの結果はいいですが, 予測タスクの結果は悪いです. 逆に, iTransformerは予測タスクはいいですが, 分類タスクは悪いです. それとは対照的に, UniTSは両方のタスクで高性能な結果です.
LLMを適用する例としてGPT4TSの結果が示されています. 訓練データの規模とモデルの規模の両方で大幅な差がありますが, 提案手法の方がcompetitiveあるいはoutperformであることがわかります.
一方で, 教師あり学習を行ったUniTS Supは教師なしで学習したUniTS Promptと同じくらいの性能にとどまっています. それどころか予測タスクのMAEではUniTS Promptの方がいい結果となっています. 著者らはそれを根拠にPrompt Learningがいいと主張しています. 個人的にはこれだけで主張するのは難しいと思います. 他にも論文には主張が書かれていますがそれらも説得力に欠けると思います.
結果: Zero-Shot New-Length Forecasting
これまでの手法での様々な系列長の予測は複数の予測器を訓練することによって達成されますが, これは未知の系列長の予測には対応できません. UniTSはmask tokenを繰り返すだけで訓練時にはない系列長の予測に対応できます. これを既存手法と比較したいのですが, 既存手法ではそのようなことはできないので新たに予測スキームを開発しています. モデルは固定されたwindowの長さで予測をし, そのwindowをずらすことによって新しい長さで予測します. 14のデータセットを用いて比較します.

この図から, ベースラインの三手法より性能が向上していることがわかります. One-step推論が可能なので最大の384系列を追加で予測したときはiTransformerより3倍ほどの高速化が達成されています.
結果: Zero-shot Forecasting on New Datasets
訓練データにはないデータでの実験をします. 以下の表に示す新しいデータを用いて予測を行います.

LLMTimeとの比較を行います.
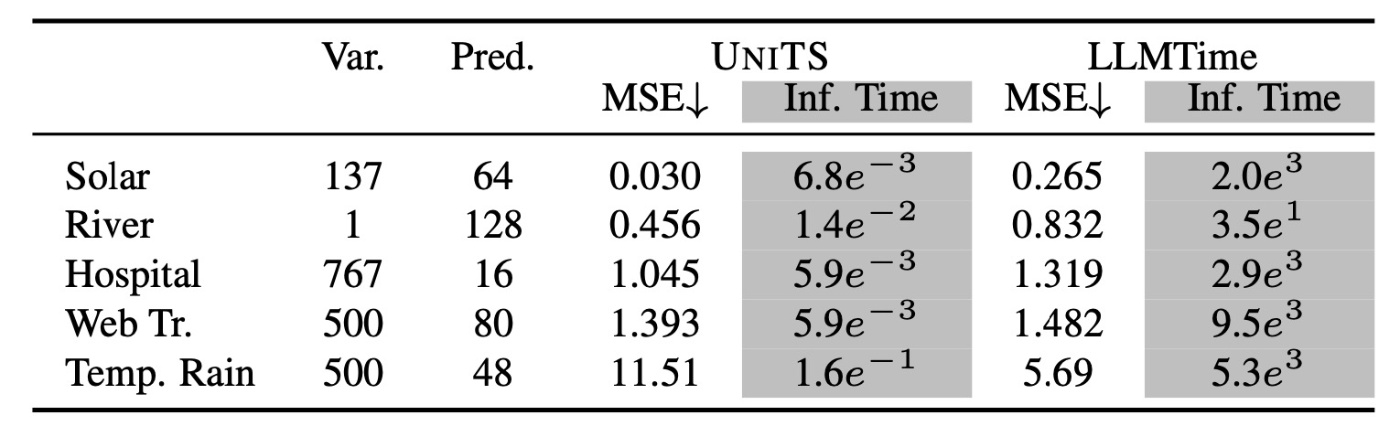
ほとんどのデータにおいてLLMTimeを上回る性能が得られています. また, 推論速度は100倍程度になり, 高速に高精度な推論がzero-shotで可能であることが示されています.
結果: Few-shot Classification and Forecasting
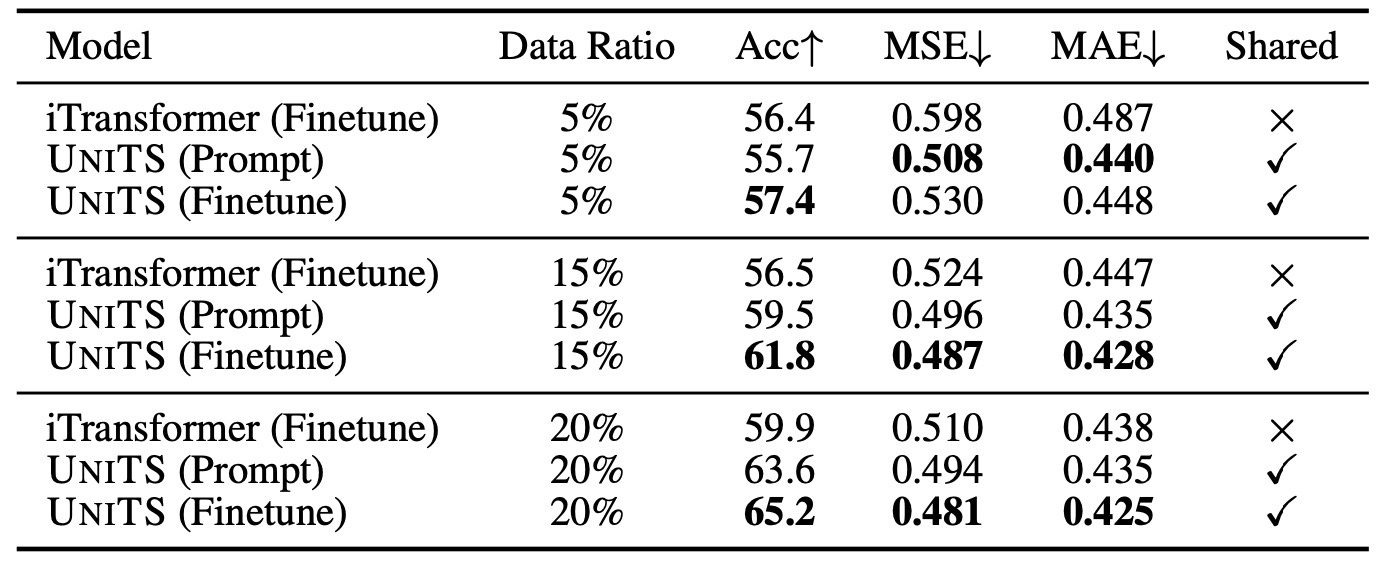
few-shot learningでの結果を見ます. 6つの分類データ, 9つの予測データから構成され, fine-tuningでは5%, 15%, 20%をそれぞれ訓練で用います. 比較手法はiTransformerです.
結果を確認します. 全ての状況においてUniTSはiTransformerを凌駕しています. 特に, データを増やすと性能はより向上しています. さらに, prompt learningのUniTSは完全な教師あり学習であるiTransformerを上回っており, さらにデータが5%の場合はMSEとMAEにおいてfine-tuningをも上回っています. few-shotではよりzero-shotに近い方が汎用的な能力を確認できるので, prompt learningがデータが少ない場合にも効果を発揮することが示唆されます.
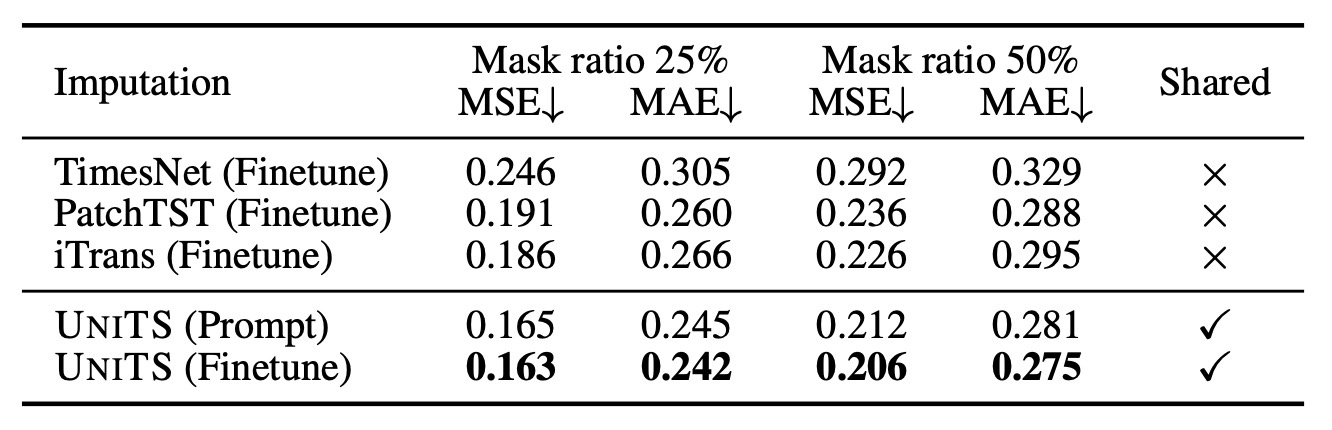
結果: Few-shot Imputation
imputation taskでの結果を確認します. TimesNetで用いられた6つのデータを使用します. データのうち10%のみを、用いてfine-tuningし, 25%および50%の欠損値を補間します.
この場合でもUniTSが高性能を発揮していることがわかります. 特筆すべき点として, prompt learningで行った場合に, ベースラインを上回るだけでなくfine-tuningと同等の性能になっています. これは, 適切なprompt tokenを選択するだけでimputationではUniTSを効果的に適応できることを示しています.
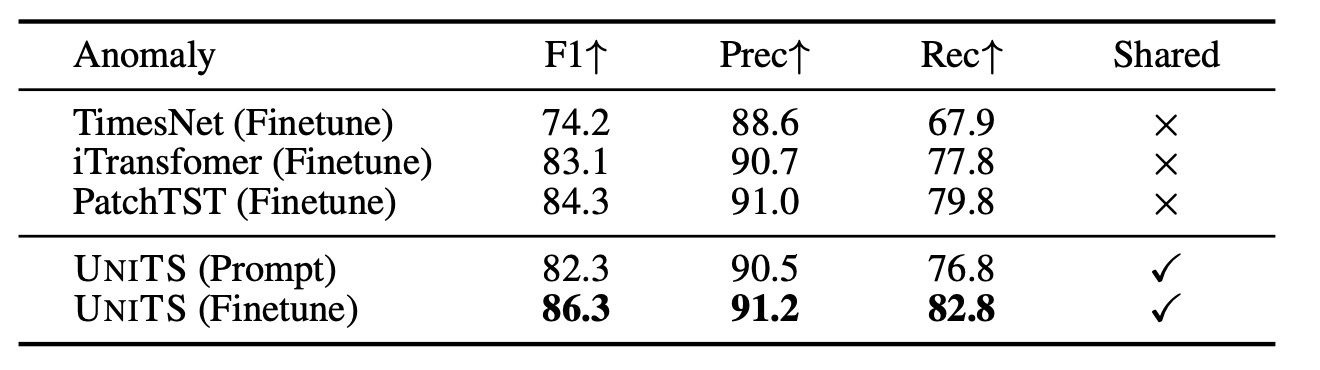
結果: Few-shot Anomaly Detection
Imputationと同じデータを用いて5%を訓練に用います.
全ての指標でベースラインを上回ることが確認できます. 他の実験と比較してこの実験は記述量が大幅に減少しており, もう書くことがありません.
まとめ
- unifiedな時系列モデルのUniTSを提案
- prompt learningでmasked modelingをして学習
- 既存の教師あり学習モデルより高性能かつzero-shotやfew-shotの設定でも未知データに適応可能
思ったこと
- MOMENTと比較してモデル構造などが練られた印象を受けました
- 学習済みモデルもGitHubのReleasesで公開されているのはいいと思いますが, huggingfaceの方が最近は主流なのでは?と思います
- 実験結果に対する分析が「xx%良くなりました」や「この指標でxxxとyyyなので〜」みたいなものが多く, もう少しそこから得られる考察を書いて欲しいと思いました
- few-shotのデータの比率は恣意的なものを感じます
参考文献
- Gao, S., Koker, T., Owen, Q., Thomas, H. Theodoros, T., and Marinka, Z. UniTS: Building a Unified Time Series Model. arXiv preprint arXiv:2403.00131, 2024.
Discussion