Stable Diffusionからの概念消去②:Concept Ablation



Ablating Concepts in Text-to-Image Diffusion Models (ICCV2023)
今回は, ESDと同じICCCV2023に採択されたConcept Ablationについてみていきます. ESDのように略称があるわけではなく, 後続の論文でも呼び方はマチマチのように思います.
図や表はことわりのない限り論文からの引用です.
書籍情報
Nupur Kumari, Bingliang Zhang, Sheng-Yu Wang, Eli Shechtman, Richard Zhang, and Jun-Yan Zhu. Ablating concepts in text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 22691–22702, 2023.
関連リンク
TL;DR
- Diffusion Modelsから特定の概念を消去する研究
- fine-tuningのみで概念の消去が可能
- パラメータを更新するので推論時の工夫がなくてもできる
- 暗黙的な概念の消去はできないが追加で明示的に概念をしていすることで消去可能
手法
この論文では, 概念を消去する際に3つの手法を実験しています.
- naive approach
- Model-based concept ablation
- Noise-based concept ablation
それぞれ順番に見ていきます.
naive approach
これは, 最も単純な手法で単純にlossを最大化させるものです. diffusion modelsのlossは
ですから, これを
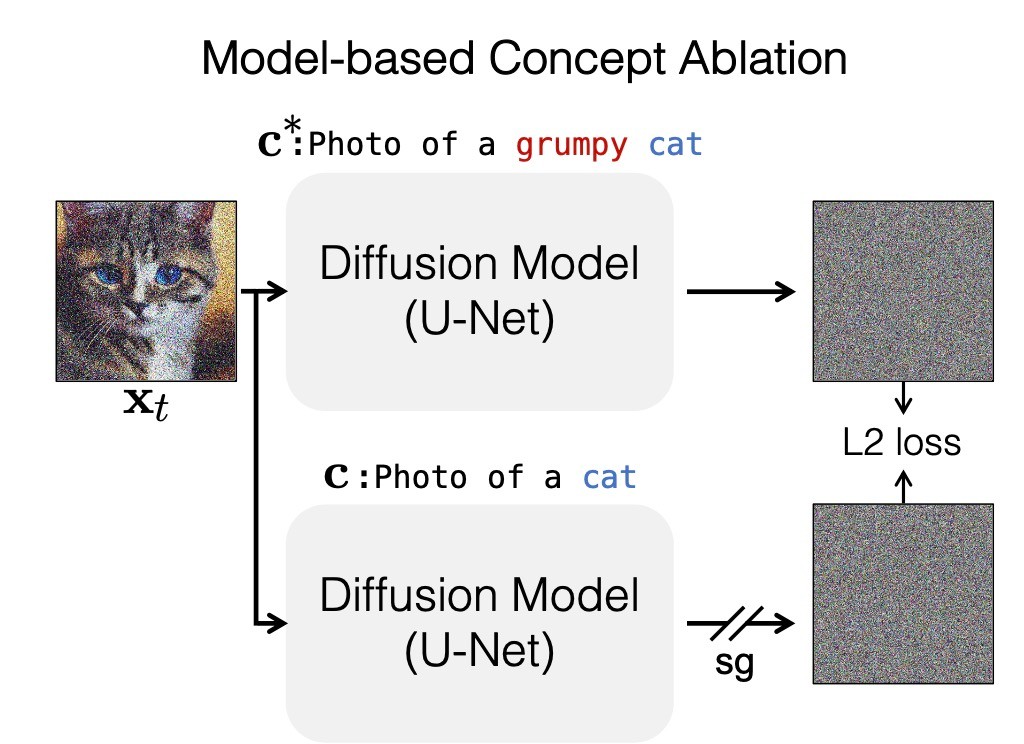
Model-based concept ablation
ここでは, 消したい概念
大まかに解釈すると, 消したい概念をその周辺概念に一致するようにします. 論文に簡単な例があるのでそれを確認します. いま, 消したい概念 Grumpy Catであるとします. このとき, catになります.
これは, 以下の目的関数によって学習されます.
Appendix Aでは, 2つの
ここで
Noise-based concept ablation
Model-based concept ablationとは少し異なる手法として, Grumpy Catをrandom Catの画像に一致するように学習する手法として, Noise-based concept ablationを提案しています.
以下のように定式化されます.
ここで,
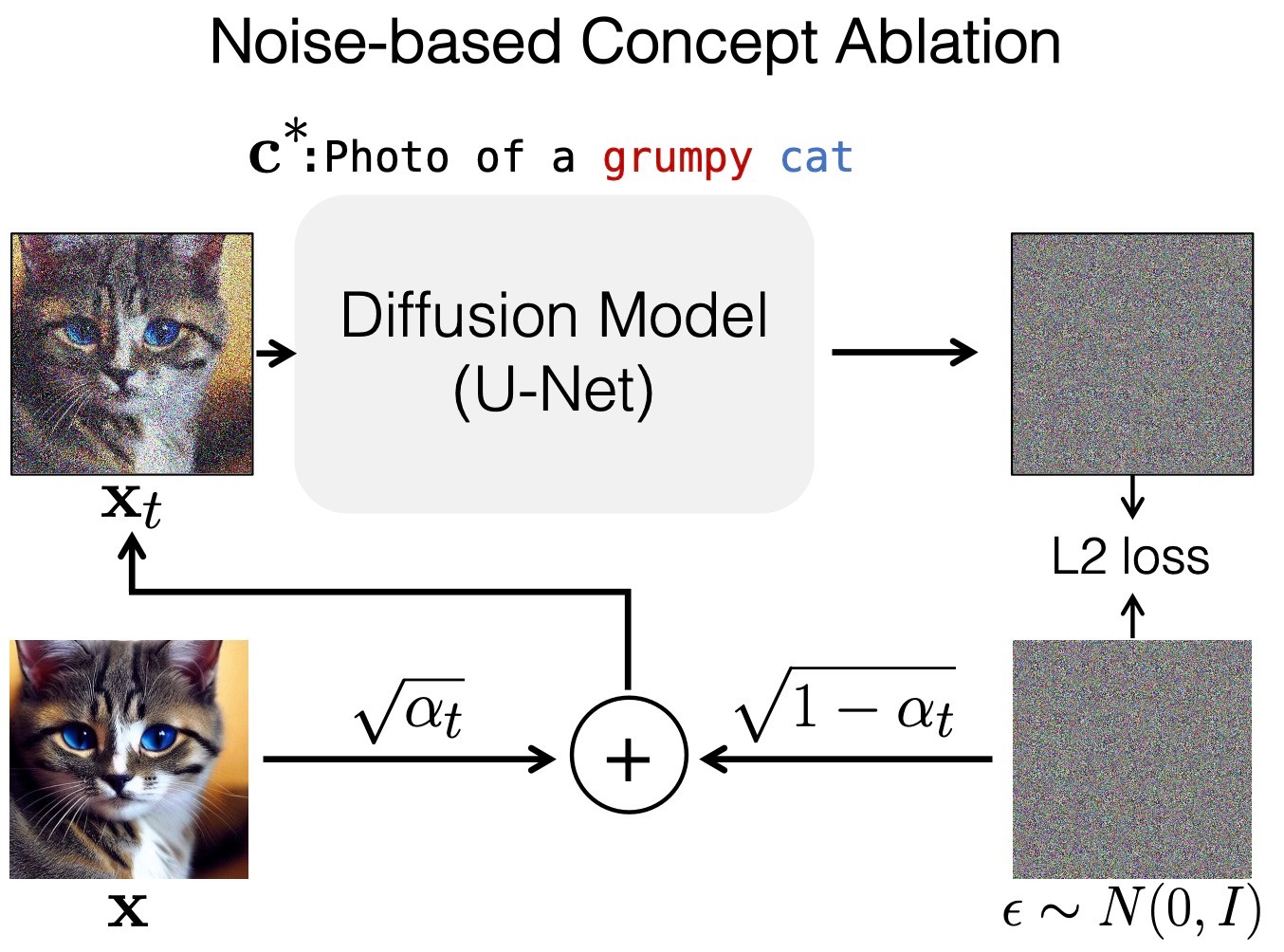
直感的には, 生成画像をデータセットにしたときの学習ということになります.
正則化
どちらの手法でも, 通常のlossを加えることで性能向上を図ります. すなわち,
です. 論文内では, 第1項の有無による比較が確認できませんでしたので, どのような効果があるのかは不明瞭です.
パラメータ
さて, lossが決まったのはいいですが, どのパラメータを更新するかという問題があります. 例えばESDではcross attentionかnon-cross attentionかという違いがありました. この論文では3つの手法を試しています.
- Cross Attention: U-Netのcroaa-attention部分の更新
- Embedding: Text Encoderから出力されるtext embedding
- Full Weights: U-Netのすべてのパラメータ
訓練の詳細
実験結果を見る前に, 訓練の詳細部分を確認します. どのようなものを消すかで異なっています.
Instance
いわゆるオブジェクトの消去です. 例が示されているのでそれに沿ってみます. まず, Grumpy Catという消したい概念とそのanchor conceptであるCatが与えられます. その後, ChatGPTを用いてanchor conceptを含むプロンプト CatをGrumpy Catに置き換えたプロンプトの集合
Style
スタイルを消す際は, 一般的なスタイルをanchor conceptとして採用します. clip-retrievalを用いて類似したプロンプト
Memorized Images
これは, 訓練画像と瓜二つの画像が出ないようにすることを目的にしています. 拡散モデルはGANと比較して訓練画像とは (ピクセルの値としては)若干異なるけど見た目は全く同じ画像を多く生成する傾向にあります[1].
この場合も同様の手順を踏んでデータセットを構築します. まずChatGPTを使用してanchor promptのいくつかのレーズを生成し, memorized imagesを頻繁に生成する3つのプロンプトをtarget promptとして, そしてmemorized imagesを最も生成しない10のプロンプトをanchor promptとして含めます. したがって、ターゲットのmemorized imagesのための
実験
さっそく結果を見ていきますが, その前にbaselineを確認します. baselineの手法 (naive approach)は以下の式で学習を行います.
定量評価ではCLIP ScoreやCLIP Accuracy, KIDやSSCDを時と場合に応じて使い分けます.
それでは定性評価をしていきます.
まず, Instanceです. この実験では
- Grmpy Cat
\longrightarrow - Snoopy
\longrightarrow - Nemo
\longrightarrow - R2D2
\longrightarrow
という消し方を行います. まずは, それぞれの手法の比較です. すべての場合でcross attentionのみを更新します. cross attentionではbatch sizeが8です. また, 初期学習率は
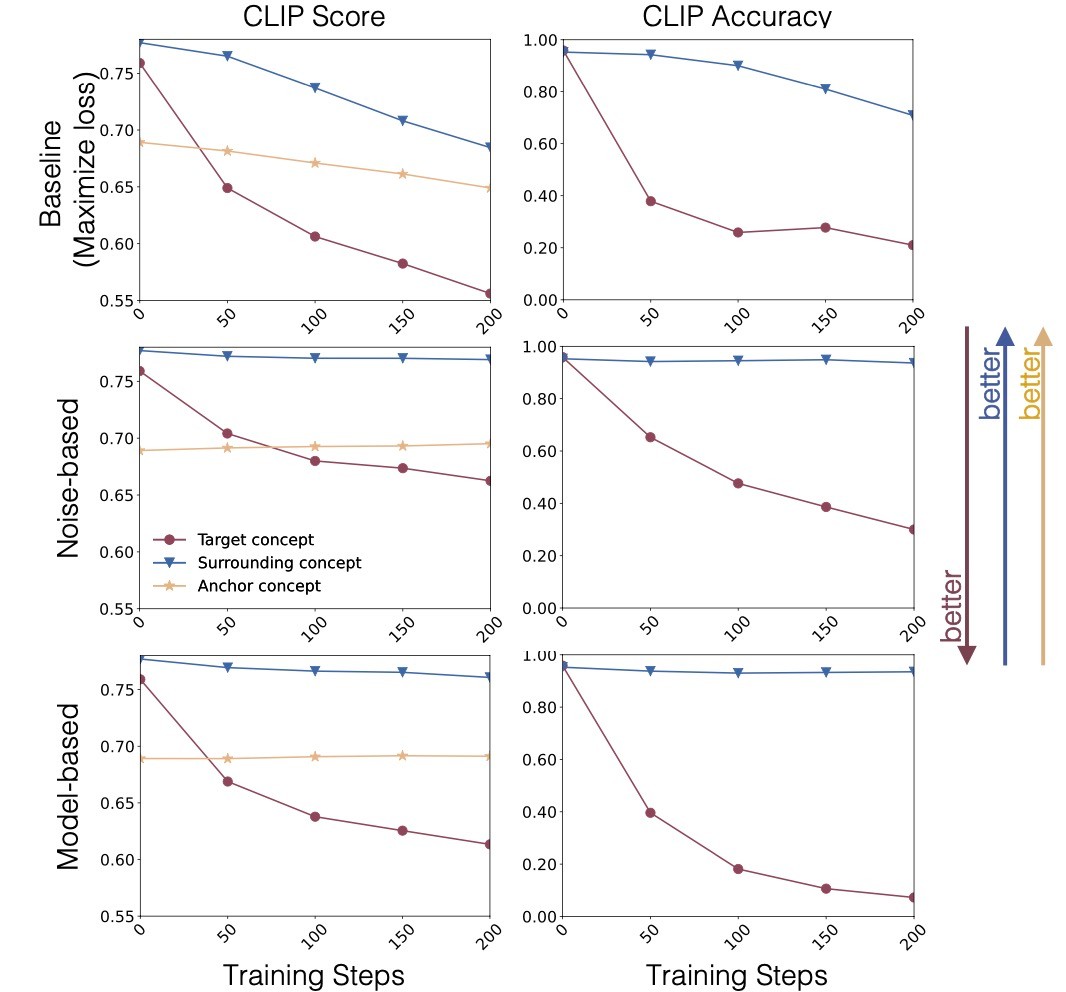
naive approachの手法ではtraining stepsが増えるにつれてノイズの多い画像を生成するようになり, anchor conpcetでの性能が大きく低下します.
定性的な比較も行います.

naive approachとmodel-based approachではどちらもR2D2を消去できていますが, naive approachは周辺概念であるBB8に大きく影響を与えてしまっています. これは他の例でも確認できます.

この結果からはmodel-basedとnoise-basedが同等の性能であることがわかります. しかし, 訓練時間に差があり, 以降では高速に訓練可能なmodel-based approachのみを実験しています.
下の3段は更新するパラメータの違いによる比較です. どの場合でも似たような結果になっていてここでは優劣を確定することは難しいです (論文ではembeddingが最も良いとしています). そのため, 定量評価を行います.
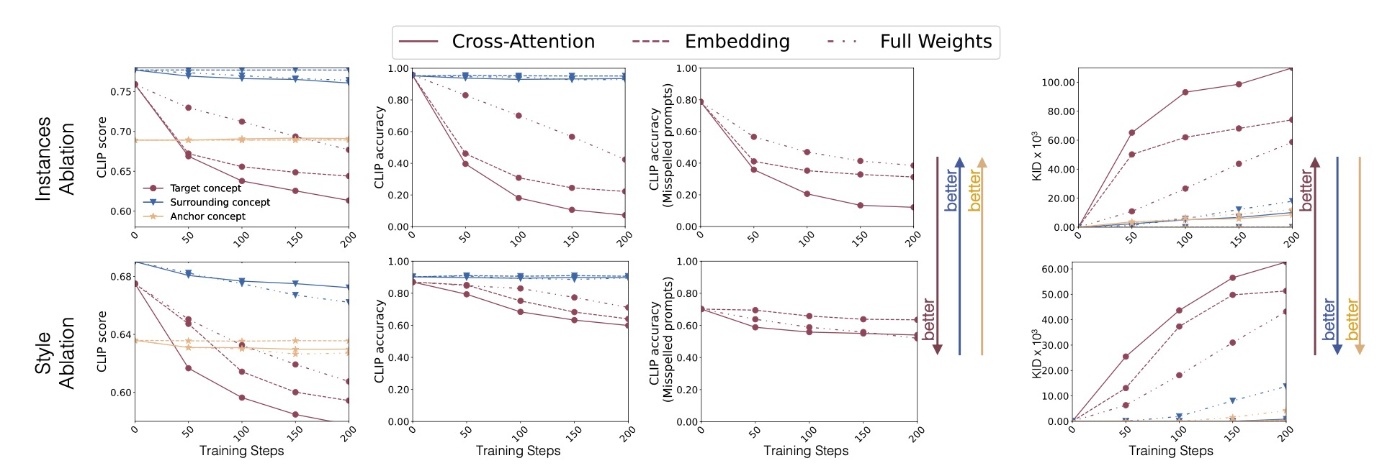
定量評価をしてみると, embeddingを更新する手法はスペルミスには対応しにくいことがわかります.
続いて, styleの結果をみます. 4つのstyleを消去していきます.
- Van Gogh
- Salvador Dali
- Claude Monet
- Greg Rutkowski
上の定量評価を見ると, styleを消した際もinstanceと同様のことが言えます.

実際の生成例を見てみてもstyleが消えていることがわかります.
続いて, memorized imagesについて確認します.

結果を見ると確かに実際の画像とは異なるものが生成されるようになっています.
追加実験
追加の実験として3つの検証がされています.
複数の概念消去
今までは, 1つのベースモデルからそれぞれ概念を消去していました. 例えばSnoopyとR2D2を消そうと思ったらSnoopyを消したモデルとR2D2を消したモデルができるという具合です. ここでは, 1つのモデルで不k数の概念を消去することを考えます. このときに, 消す概念の数だけtraining stepsを増やす必要があります. 結果を見てみます.

定性的結果ははっきりと消えていることがわかります. また, 定量的結果でも対象の概念を消去しつつ, 周辺概念への影響は軽微であることが確認できます.
anchor categoryの役割
anchor conceptは人間が選んでいるわけですが, これを変えるとどのように変化するかを調べます. ここではGrumpy CatをBritish Shorthair CatとFelidaeに変化させた場合の結果を確認します.

どちらの場合でもうまく動いていることがわかります. 個人的にはもっとanchor conceptが思いつかないもので実験した方がいいと思います (fruitsみたいな指すものが幅広い概念についてはどうなのでしょう).
reverse KL divergence
model-based approachでは以下の式で最適化を行なっていました.
これはtarget conceptとanchor conceptのKL divergenceを最小化するような学習です. このKL divergenceをreverse KL divergenceにするとどうなるのかというのがここでの興味です. すなわち, 以下の式で最適化を行います.
Goghを消去した際の生成例を見てみます.

確かにGogh styleが消えていることがわかります. 2つのdivergenceを定量的に比較します.
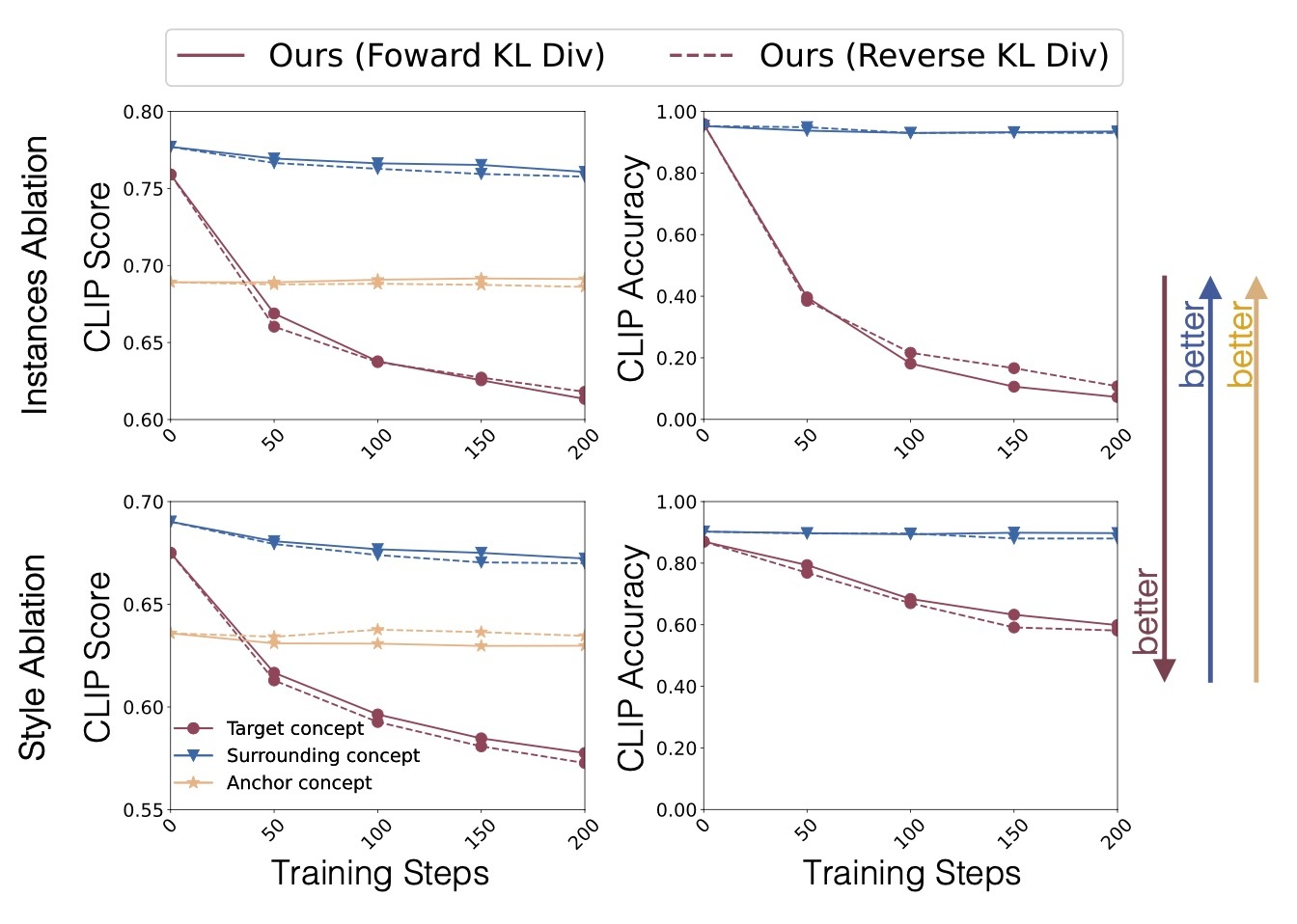
著者らはstyleでは性能がいいがinstanceでは悪いと述べていますが, 大きく異なるということではないと思います.
limitation
最後にlimitationを確認します. この手法は文字通り概念を上書きする手法と言えます. そのため, implicitな概念を消すことは難しいです. 下の図の (a)では, Van Gogh styleを消去したモデルでstarry nightと入力するとGogh styleのstarry nightが生成されていることがわかります.

これは, Van Gogh styleを消した後に明示的にstarry nightを消してあげることで解決できます.
次に, 消去が成功した場合でも周辺概念は変化する例が示されています.

個人的にはMonet styleが反映されているので問題ないと思いますが, 著者らはPretrained Modelをground truthとしているため, 問題であると考えているようです.
まとめ
- fine-tuningのみで概念の消去が可能
- パラメータを更新するので推論時の工夫がなくてもできる
- 消せてはいるが, 完璧な手法ではない
思ったこと
- まだこの分野は初期の段階で, どこを更新するかやどういったlossで更新するかなど試行錯誤が多いなと感じます. それだけ実験回数も増やさないといけないので大変だと思いました.
- 例として
Grump CatをCatになるように学習すると論文では示されていますが,Catの生成例があるといいなと思いました. - Original SDの生成例と乖離してしまった場合に性能が悪化したとする根拠がESDのときと同様薄いと思います.
- いわゆるコミュニティモデルではどうなるのか気になります. arXivの投稿は2023年3月ですので, Stable Diffusion2.0も登場していて検証がやや足りないのではと思います.
- 途中でも触れましたが, Anchor Conceptが思いつかなかった場合はどうするのでしょうか. ChatGPTなどのLLMに生成させるにしてもHallucinaltionsが発生しているかのチェックが必要に思えます.
参考文献
- Nupur Kumari, Bingliang Zhang, Sheng-Yu Wang, Eli Shechtman, Richard Zhang, and Jun-Yan Zhu. Ablating concepts in text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 22691–22702, 2023.
-
Extracting Training Data from Diffusion Modelsという論文で具体的に示されています. ↩︎
Discussion