拡散モデルと表データ生成④:【論文】TabSyn
Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space (ICLR2024)
ICLR2024のoral採択の論文です. 自分の知る限りでは, アーキテクチャなどのレベルで拡散モデルを使って表データ生成をする論文はこれで最後になります (2024/03/18現在).
今回はarXivのversion 1を読んだまとめですが, 一部ICLRの査読やcamera-readyの内容も反映しています. 断りのない限り, 図や表は論文からの引用になります.
関連情報
arXiv OpenReview 公式実装
書籍情報
Hengrui Zhang and Jiani Zhang and Zhengyuan Shen and Balasubramaniam Srinivasan and Xiao Qin and Christos Faloutsos and Huzefa Rangwala and George Karypis. Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space. The Twelfth International Conference on Learning Representations, 2024
TL;DR
- Latent Diffusion Modelsを使用した表データ生成手法のTabSynの提案
- 生成品質, 汎用性, スピードの3つの面で既存手法を上回る結果
- 追加訓練なしで欠損値補完にも適用し, XGBoostと同等の性能を達成
さまざまな指標で既存手法を上回ることがわかります.
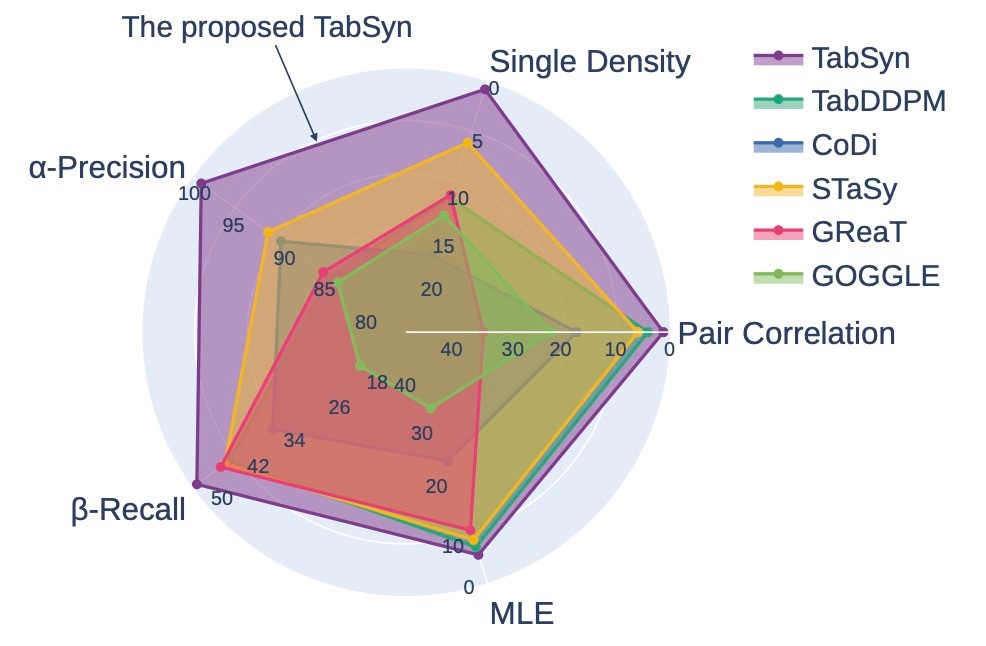
提案手法: TabSyn
まずはモデルの概要図を示します. これを見ると一目瞭然です.
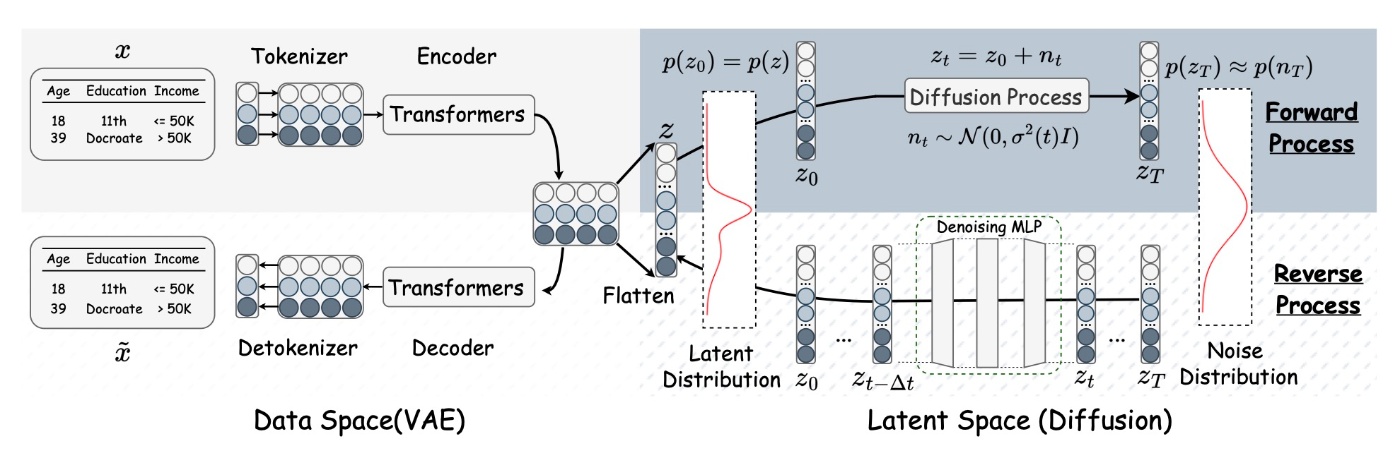
画像生成ではLatent Diffusion Models (LDM)が台頭して久しいです. Stable Diffusionの登場により多くの人が触れるようになりました.
LDMの概要自体は様々な解説記事があるので省略します. Stable Diffusionとは異なり, 基盤モデルではないのでデータセット毎に訓練する必要がある点には注意が必要です.
問題定義
TabSynの中身に入る前に記号の定義などを行います. まず,
この論文では条件無し生成に着目します. 表データ
AutoEncoder
さて, TabSynの構成要素に注目していきます. LDMはAutoEncoderとdiffusion modelsの2つから主に成り立っていますが, まずはAutoEncoderについて触れます.
表データは非常に構造化されたデータで, 各値に意味があります. 例えば画像ではピクセル値が1違っても大きな問題ありませんが, 自然言語ではトークンの値が1違うと意味が大きく変化する場合があります. また, 各カラムが密接に関連しているだけでなく, その関連度合いも異なります. 例えば都道府県と県庁所在地は一対一対応しています. しかし, 体重と身長などという場合は大まかな関連は考えられますが, この2つを明確に対応づけることは難しいです. これらの特性を加味してAutoEncoderの設計が必要になります. ここではTransformerを用いた表データ分析での成功例に倣って2つのステップを踏むことにします.
- 各カラムに対してunique tokenizerを学習する
- token (column)-wiseな関係を学習する
Feature Tokenizer
Feature Tokenizerは各カラムを
です. ここで,
これによって
Transformer Encoding and Decoding
通常のVAEと同様に潜在変数の平均と分散を取得します. 次に, 再パラメータ化トリックを使用して潜在埋め込みを取得します. その後, decoderに通して再構成トークン行列 Transformerクラスの中で2層作るようになっています.
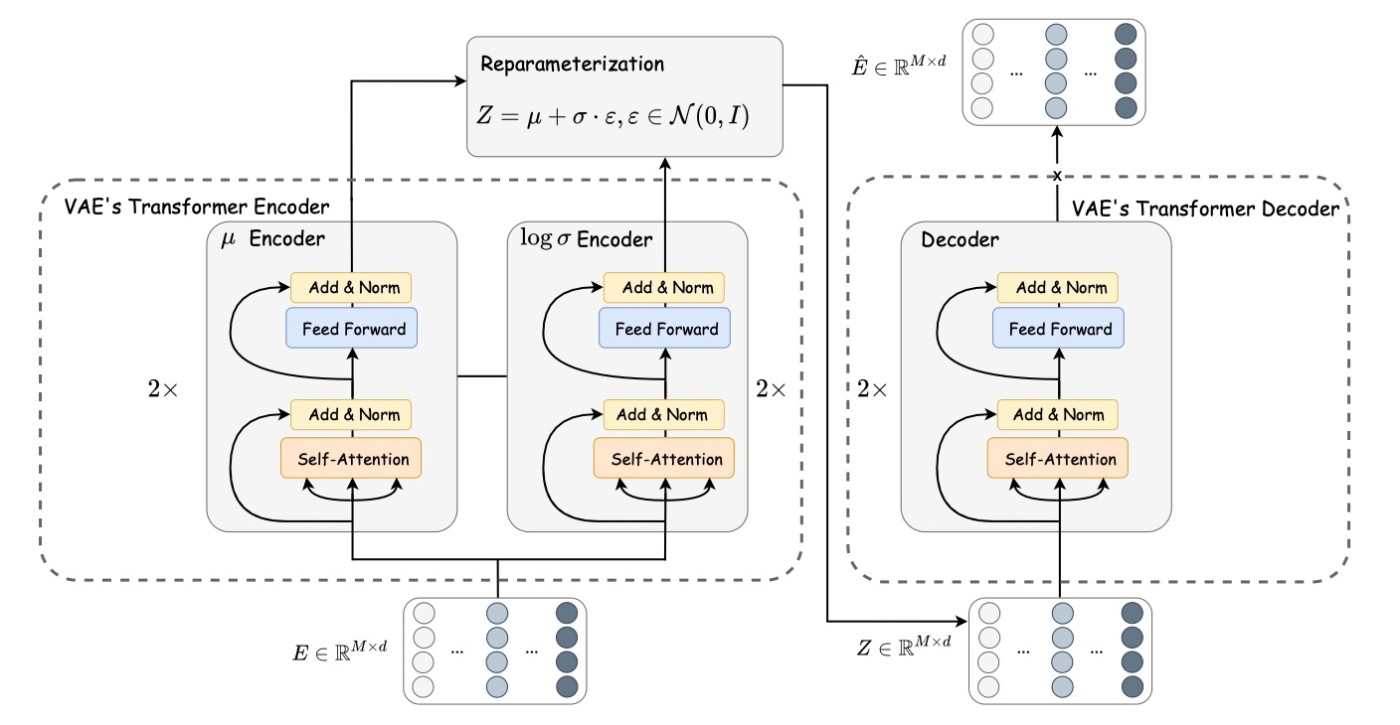
Detokenizer
最後に, token embeddingから実際の値に戻します. tokenizerと対称的な設計にします. すなわち,
となります. ここでも,
Training
定式化が終わったところで, 訓練の詳細です. ここでは効率的な訓練を行うために改良されたVAEの学習方法を用いています. 通常のVAEはELBO損失関数を用いますが,
スケジューリングの戦略は以下の通りになります.
- 初期値
\beta=\beta_{\max} \ell_{\mathrm{recon}} -
\ell_{\mathrm{recon}} \ell_{\mathrm{KL}} \beta=\lambda\beta \lambda<1 \lambda=0.7 \beta - 訓練が終了するまで続ける. ただし,
\beta_{\min} <\beta \beta
公式実装および論文内の実験では,
Score-based Generative Modeling
さて, VAEの学習が終わると次はメインとなる拡散モデルの学習が始まります. 先ほどの概要図を再掲します.
真ん中にFlattenと書かれている通り, 埋め込み行列をまずはフラット化してベクトルとして表します.
その後, 埋め込みの分布
これはスコアベースの式になっています. スコアは
そのため, 拡散モデルの学習は以下のように行われます.
ここまでの中で登場していた
これで拡散モデルのパートは終わりですが, 最後にアーキテクチャを確認します.
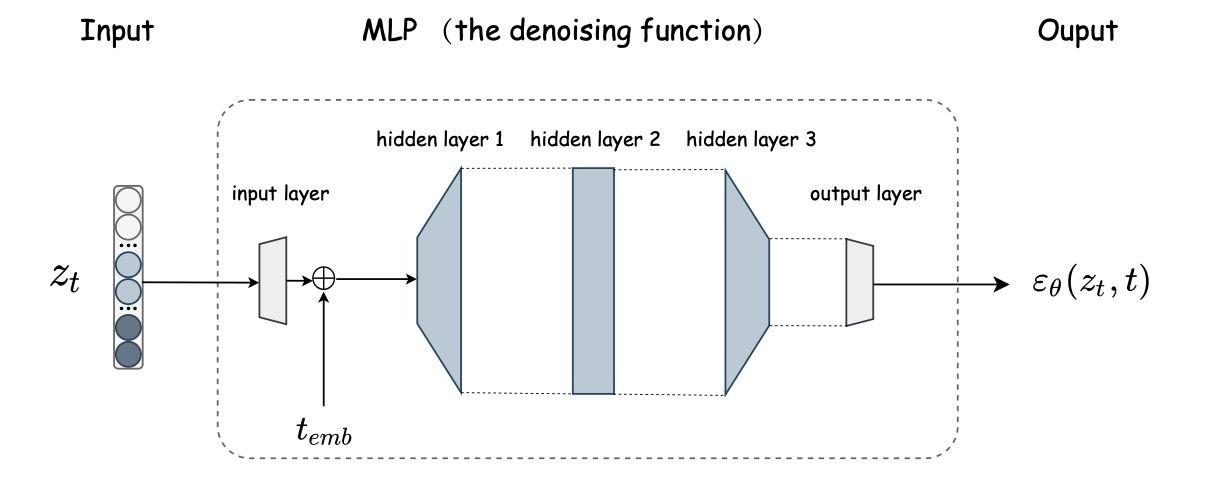
TabDDPM同様非常にシンプルなMLPが使われています. まず最初に入力を射影します. その後, 時間埋め込みを加えてから拡散モデルのパートに移ります. hidden layer1の入力は
です. 全ての実験で
実験と結果
Adult, Default, Shoppers, Magic, Faults, Beijing, Newsの6つのデータセットを用います. ベースラインはTVAE, CTGANに加えてグラフベースのGOGGLE, LLMを用いるGReaTと拡散モデル手法であるTabDDPM, CoDi, STaSyの全部で7つです. これまで拡散モデルを用いた手法は統一的な比較がされていなかったのでこの論文は初めて統一的な比較を行うことになります.
評価方法
結果を見る前に評価方法を確認します. この論文では3つの観点で評価します.
- 低次元統計: column-wise density estimationとpair-wise column correlationを用いてカラム間の相関を確認します.
- 高次元統計:
\alpha \beta - 下流タスク: machine learning efficiencyとmissing value imputaionで下流タスクの性能を確認します.
結果は全て20回のランダムサンプリングの結果の平均が示されます.
Low-Order Statics
合成データが単一の列の密度を推定し, および列のペア間の相関を評価することから始めます。
まず, 列の密度を調べます. 数値データに対してはコルモゴロフ-スミルノフ検定 (Kolmogorov-Smirnov Test、KST), カテゴリカルデータに対しては全変動距離 (Total Variation Distance、TVD)を用います.
結果を見てみます. 提案手法がどのデータでも最良の結果を示していることがわかります. 拡散モデルのSTaSyとTabDDPMも性能がいいですが, それを上回る形になります.
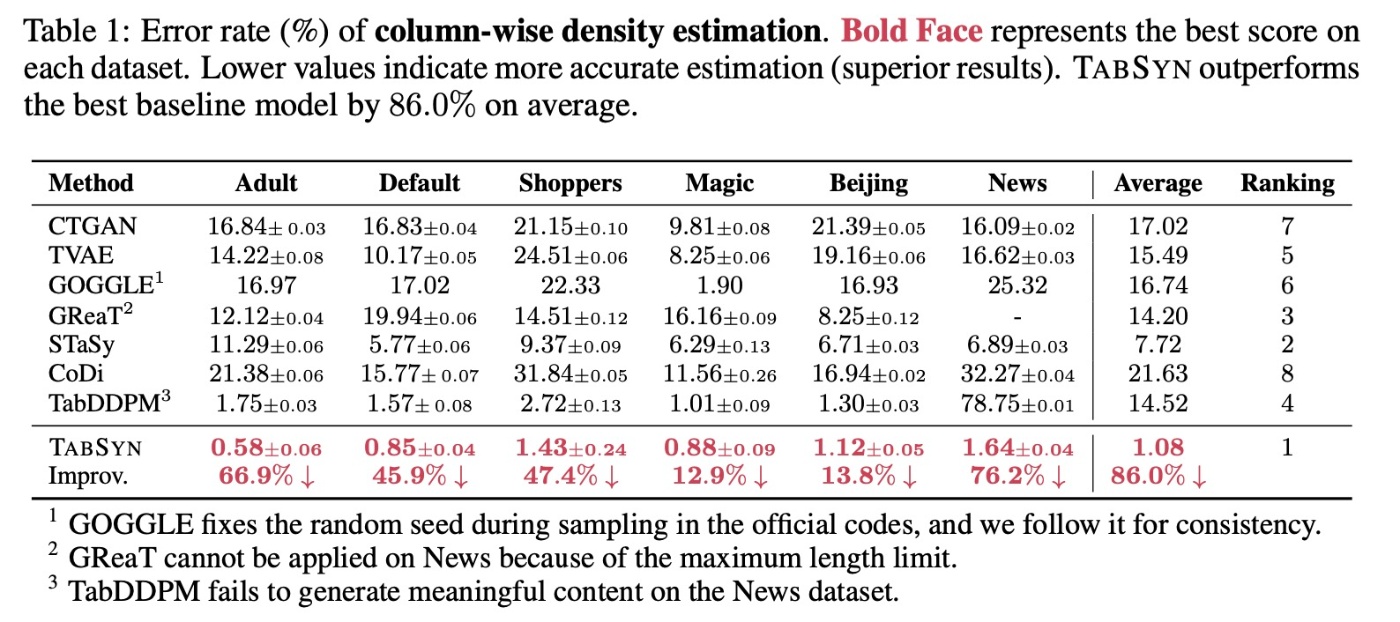
注釈3にもあるように, TabDDPMは意味のある生成ができなかったようです. これについて論文では書かれていませんが, OpenReviewで詳しい話が書かれています. ここでは詳述しませんが, 簡単に述べるとモード崩壊が発生しているようです.
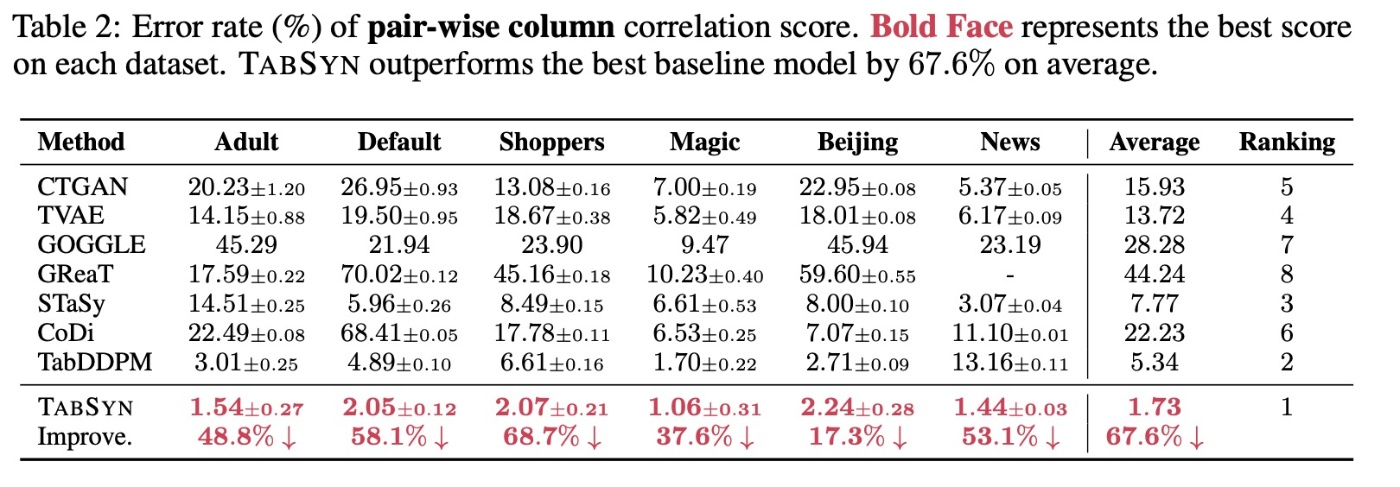
続いてカラムごとの相関を見てみます. 数値データ同士ではピアソン相関, カテゴリデータ同士はcontingency similarityを用います. 数値データとカテゴリデータの相関は, まず数値データをバケット分割してカテゴリ値にグループ化し, contingency similarityを計算します.
では, 結果を確認します. これを見ると先ほどと同様の結果になります. ただし, 先ほどは3番目のrankを誇っていたGReaTが8位に落ちていることがわかります. これは自己回帰言語モデルがカラム間の相関を捉えることができていないことを示しています.
High-Order Statics
main paperの部分で触れられていないので著者らがメインで主張したいことではなさそうですが, こちらもみていきます.
詳しくは提案論文をご覧ください.
結果を見ていきます. 2つの指標は併用するもので, 特に
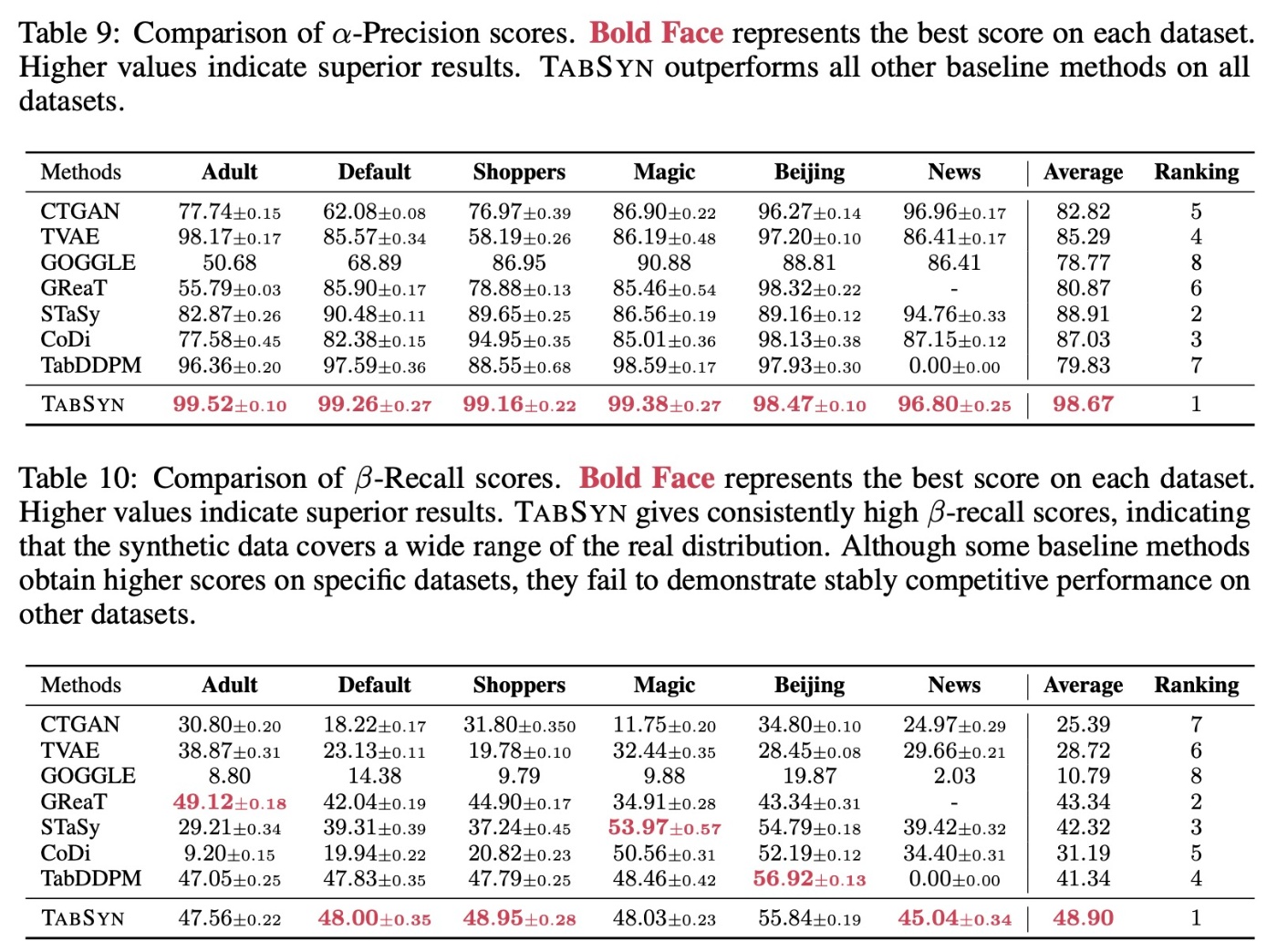
個人的な意見ですが, この指標での性能比較と下流タスクの性能比較は一致していないのでAppendixになったのではないかと思います.
下流タスクでの結果
実世界のデータは金融データや医療データなどが代表例に挙げられるように, 非常にセンシティブです. そのため, 本物の表データを使うのではなく生成データを使うモチベーションが非常に大きいです. 論文ではプライバシーの話をここでしていますが, なおさら (arXiv版ではあったこの内容の話がICLRのcamera-readyでは消えていました. 査読者のコメントでも同様の指摘がありました. 査読を見てみるとDCRを用いてプライバシーの比較をしており, 他の拡散モデルの手法と同程度であることがわかります.)
まず, Machine Learning Efficiencyの結果を見ます. この論文ではXGBoostを用いています. こちらの結果でも非常に高性能な結果が示されています. 一方でこれまでの統計的比較と比べると手法間の差は縮まっています. これは表データは余分な情報が多いために, そこはGBDTの評価に大きな影響を与えないためと考察されています.
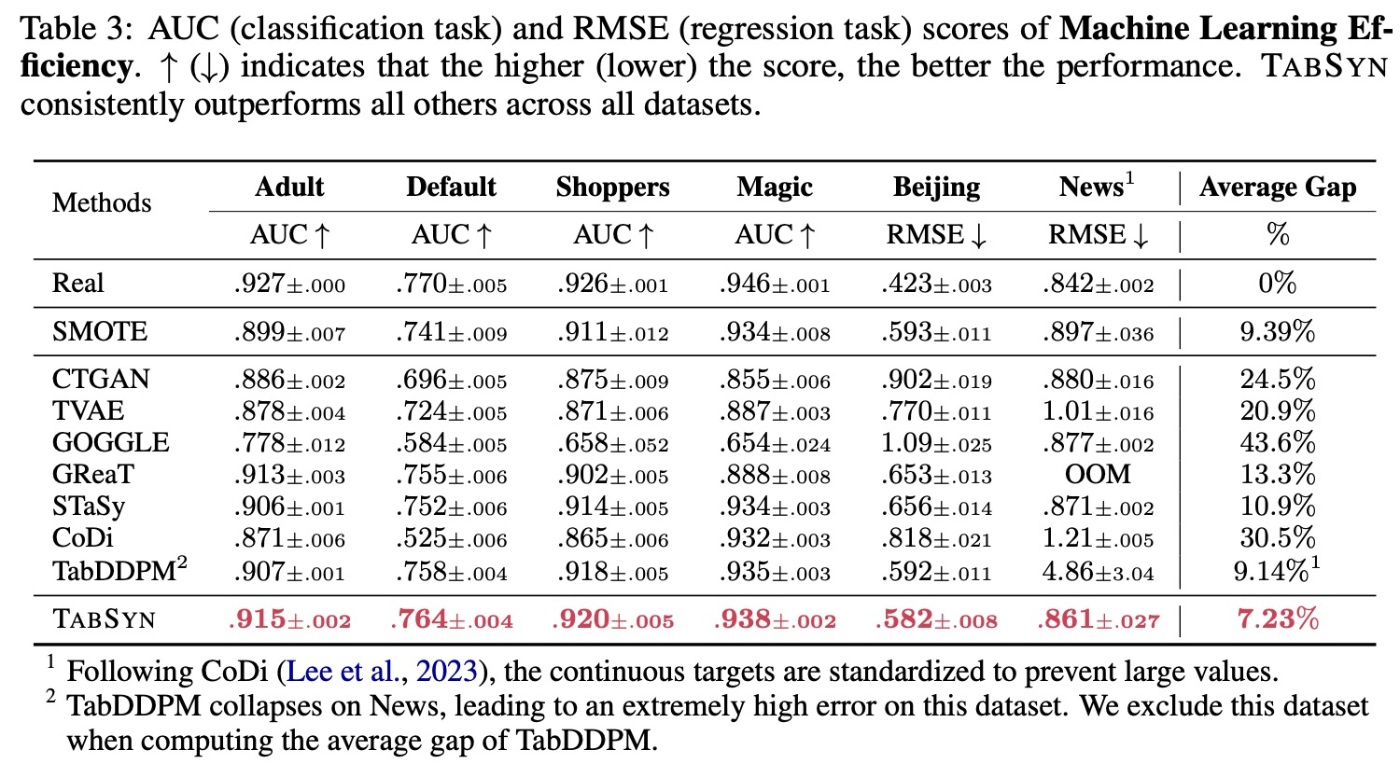
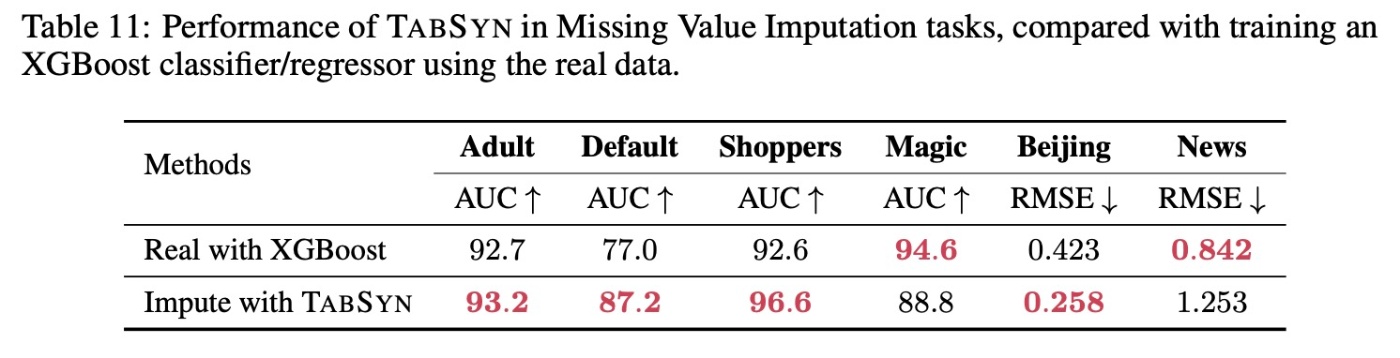
続いて, 欠損値補完についてみます. 拡散モデルの特徴として, 追加訓練なしで欠損値補完ができることが挙げられます (画像データではimage inpaintingが相当します). 簡単に手法を紹介すると, RePaintと同様の手法になります. すなわち, マスクされていない部分は元のデータの値を用いて, maskされた部分にのみモデルの予測結果を適用するという手法です. 目的変数をmaskして, 通常のclassificationやregressionと同等の状況に設定します.
RePaintについては以下の論文を参照ください.
ここではXGBoostとの比較を行います. unconditional generationな拡散モデルが使えるという話だったのにXGBoostとのみ比較というのは気になりますが, Appendixに結果が載っている以上, あまり主張のメインではないのではと思います. 結果を簡単にみます. 多くのデータでXGBoostと比較して競争力のある結果とわかります.
Ablation Study
最後にablation studyを見ます. ここでみるのは以下の3つです.
- スケジューリング
\beta - 線形ノイズ強度の効果
- encoding/decodingの手法の比較
スケジューリング \beta
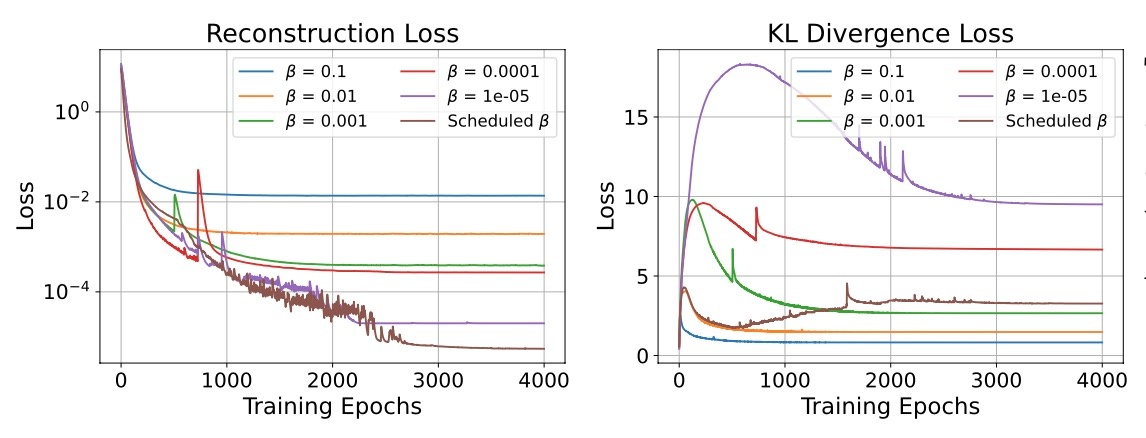
再構成誤差は
論文には書かれていませんが,
線形ノイズ強度の効果
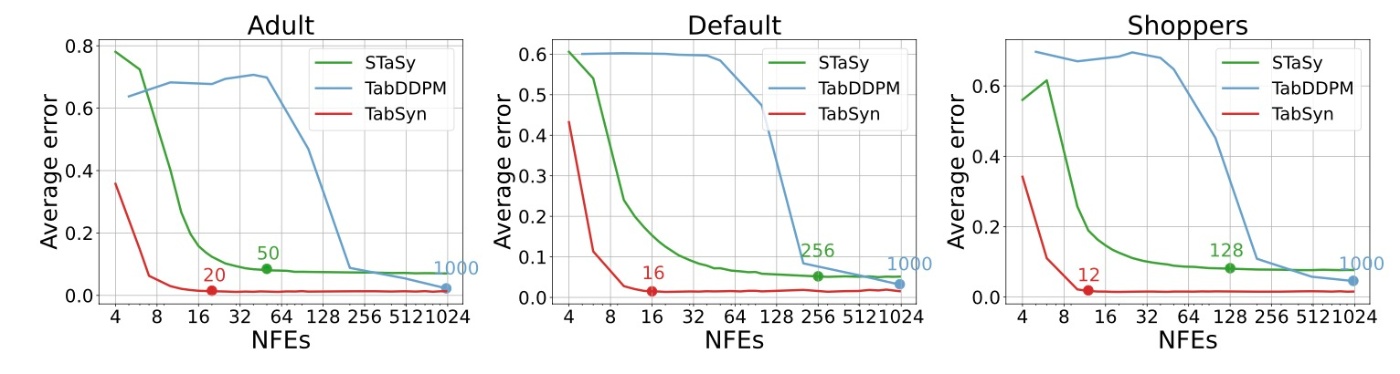
TabDDPMやSTaSyと比較すると少ないステップ数で高品質な生成を行えていることがわかります.
encoding/decodingの手法の比較
提案手法ではVAEでデータを射影していました. これを別の方式にするとどうなるかを調べています. 以下の2つの手法での実験を行っています.
- TabSyn-OneHot: VAEをone-hotに置き換える. すなわちカテゴリデータをone-hotで表して, それらも数値データとして扱う手法
- TabSyn-DDPM: SDE-basedでモデリングされていたものをDDPMに置き換える
Adultデータを用いた結果を見てみます. ここではlow-order staticsのみを見ます.
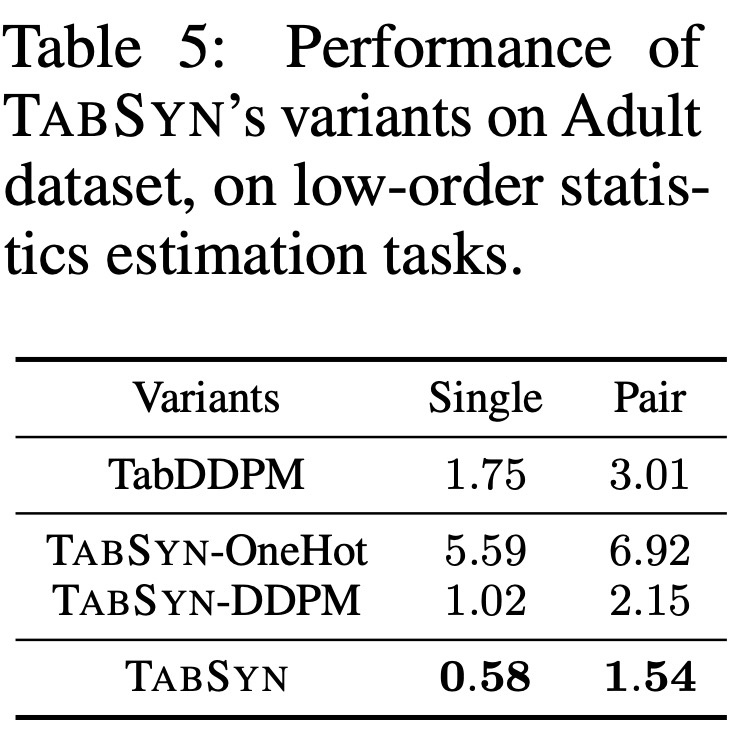
まず, one-hot vectorをそのまま数値データとして扱うと, 大幅に精度が低下します. この考察はされていませんでした. また, 潜在空間でのDDPMはデータ空間でのDDPMを上回る結果を得ており, データ空間より潜在空間でのモデリングが適していることがわかります. これは画像生成とは異なる結果なので興味深いです. さらに, 提案手法はそれらを上回る結果です.
Speed
最後に, 訓練時間と生成時間の比較をしておきます. 論文のIntroductionではspeedを利点として挙げながらもmain paperでは言及がありませんが, Appendixに少しあります. 詳しい比較の設定は書かれていませんが, Adultデータで確認します.
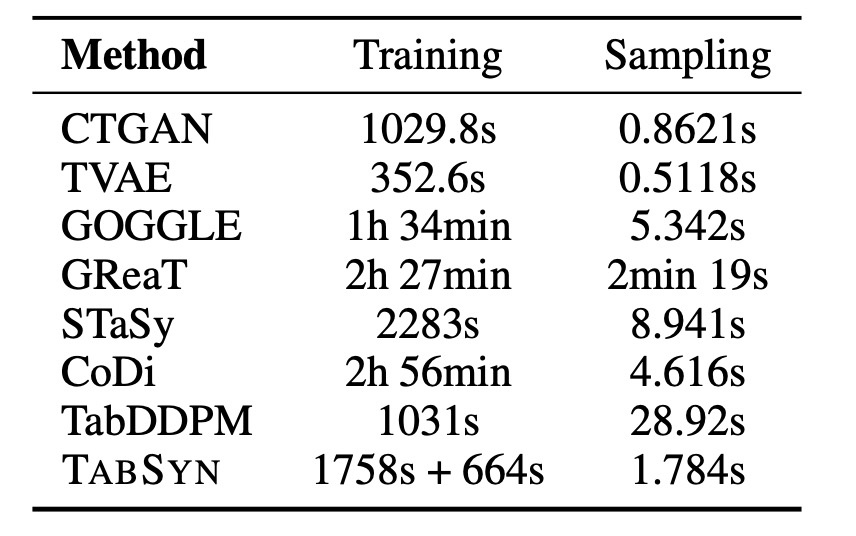
提案手法は2つのモデルを訓練する必要があります. そのため, それなりに時間がかかりますが, 40分程度でできることがわかります. 一方で, 生成速度は非常に高速で, 1ステップ生成のGANやVAEに迫る勢いです. なお, 公式実装を確認すると拡散モデルの部分はearly stoppingが実装されていますが, 論文ではそれについての言及がありませんでした. デフォルトのエポック数をちゃんと訓練させようとするともう少し時間がかかりそうです.
まとめ
- データを潜在空間に射影してそこで拡散モデルを学習するTabSynの提案
- 既存手法と比較して性能向上を確認
- 欠損値補完にも適用可能で, XGBoostと同等の性能を達成
思ったこと
- OpenReviewをみると査読のコメントに対して非常に的確な返答がされているなと思いました. 追加の実験量も多く, これが口頭発表になるのも納得です.
- LDMを使うことは誰でも考えつきそうですが, 表データの特性を踏まえた設計などの工夫がすごいと思いました.
- Metareviewでも書かれていますが, コードも整理されていて, 見習うべき点が多いと思いました.
- shoppersだけ
\beta_{\max} - また, TabDDPMやCoDi, STaSyと比較して, 使用しているデータの種類が少なく, 効果が限定的に見えてしまいます.
- GANベースの手法は表データでも優位性が失われつつあるように思える結果です.
- TabDDPMの論文が恐らくきっかけとなって, SMOTEをベースラインに採用する事例が増えているように思います. この論文でもICLRのcamera-readyではSMOTEが追加されています.
- まだ表データドメインでは基盤モデルが登場していませんが, そろそろ登場しそうな気配があります (特に, TabSynが分類器と同等のパフォーマンスを出した点は特筆すべきで, これを任意のデータに拡張することで構築できそうです). ただ, 表はデータごとに特性がかなり異なるのでかなり難しそうです.
- 査読に対する反論ではMLPの代わりにResidual ConnectionやTransformerを用いた結果が示されていますが, MLPの方が性能がいいことがわかっています. シンプルなのに複雑なアーキテクチャより高性能であることは驚きです. 一方でVAEのパートはTransformerを用いているのでかなりのエポック数を要します (公式実装は4000エポック). この改善が今後の課題になりそうです.
- VAEでは
M\times d M
参考文献
- Hengrui Zhang and Jiani Zhang and Zhengyuan Shen and Balasubramaniam Srinivasan and Xiao Qin and Christos Faloutsos and Huzefa Rangwala and George Karypis. Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space. The Twelfth International Conference on Learning Representations, 2024 (https://openreview.net/forum?id=4Ay23yeuz0)
- Ahmed Alaa, Boris Van Breugel, Evgeny S Saveliev, and Mihaela van der Schaar. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. In International Conference on Machine Learning, pp. 290–306. PMLR,2022. (https://proceedings.mlr.press/v162/alaa22a.html)
- Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11461–11471, 2022. (https://openaccess.thecvf.com/content/CVPR2022/html/Lugmayr_RePaint_Inpainting_Using_Denoising_Diffusion_Probabilistic_Models_CVPR_2022_paper.html)
Discussion