【LangGraphの教科書】OpenDeepResearchの実装がとても参考になります
ここから見てね
はじめに
はじめまして、ふっきーです。
最近話題のDeepResearchの中身が気になったので、LangChainのGitにあるOpenDeepResearchのコードを読んでみました。
こんな感じのやつ

DeepResearchの実現方法としては、ふーんという感じでしたが、
LangGraphの実装として見るとさまざまな要素があり、非常に勉強になりました。
AIワークフローを開発するうえで有益だなと思ったので、共有します。
LangGraphを使って、
- AIワークフローを実装したい
- Human-in-the-loopを実装したい
- サブグラフをもつStateGraphを実装したい
- ノードの並列実行を実装したい
これらの願いを全て叶えてくれる素敵なコードです。
そんなOpenDeepResearchの流れと実装を見つつ、ポイントを確認していきたいと思います。
OpenDeepResearchのワークフロー
最初に、ざっくりとですがOpenDeepResearchの全体のワークフローを確認します。
”ノードの主体:ノードの役割”といった書き方になっています。
- LLM:調査内容の章構成の決定
- 人間:章構成の確認・フィードバック
- LLM:章内容生成・フィードバックLang
- ロジック:章合成
- LLM:まとめ章生成
- ロジック:全体の調査結果の生成
といった流れになっています。
こうみるとOpenDeepResearchは、
”トピックに関するキーワードを決定・検索し、章構成を生成”と”それぞれの章に対して、キーワードを決定・検索し、章内容を生成”といったことしかしておらず、あまり複雑なフローにはなっていませんでした。
DeepResearchの実現方法を理解するのであれば、他のサービスを見た方が良いかもしれないです。
続いて、グラフ構成と実装を見ていきたいと思います。
メイングラフ
メイングラフのSTARTから順にノードの流れを追っていきます。
ほとんど一本道なので、複雑ではありません。
generate_report_planノード
ユーザーが指定したトピックを入力として、そのトピックをより深く知るための検索クエリを決定しています。
そのクエリを使って検索し、調査レポートの章構成を決定しています。
Stateの章構成を更新して、次のノードに渡します。
Stateを受け取って、StateのもつValueを更新して返す基本的なLangGraphのノードの実装になっているかと思います。
async def generate_report_plan(state: ReportState, config: RunnableConfig):
""" Generate the report plan """
# Inputs
topic = state["topic"]
feedback = state.get("feedback_on_report_plan", None)
# 略
# Generate queries
results = structured_llm.invoke([SystemMessage(content=system_instructions_query)]+[HumanMessage(content="Generate search queries that will help with planning the sections of the report.")])
# Web search
query_list = [query.search_query for query in results.queries]
# Get the search API
search_api = get_config_value(configurable.search_api)
# Search the web
if search_api == "tavily":
search_results = await tavily_search_async(query_list)
source_str = deduplicate_and_format_sources(search_results, max_tokens_per_source=1000, include_raw_content=False)
elif search_api == "perplexity":
search_results = perplexity_search(query_list)
source_str = deduplicate_and_format_sources(search_results, max_tokens_per_source=1000, include_raw_content=False)
else:
raise ValueError(f"Unsupported search API: {configurable.search_api}")
# Format system instructions
system_instructions_sections = report_planner_instructions.format(topic=topic, report_organization=report_structure, context=source_str, feedback=feedback)
# Set the planner model
if planner_model == "claude-3-7-sonnet-latest":
planner_llm = init_chat_model(model=planner_model, model_provider=planner_provider, max_tokens=20_000, thinking={"type": "enabled", "budget_tokens": 16_000})
# with_structured_output uses forced tool calling, which thinking mode with Claude 3.7 does not support. Use bind_tools to generate the report sections
structured_llm = planner_llm.bind_tools([Sections])
report_sections = structured_llm.invoke([SystemMessage(content=system_instructions_sections)]+[HumanMessage(content="Generate the sections of the report. Your response must include a 'sections' field containing a list of sections. Each section must have: name, description, plan, research, and content fields.")])
tool_call = report_sections.tool_calls[0]['args']
report_sections = Sections.model_validate(tool_call)
else:
planner_llm = init_chat_model(model=planner_model, model_provider=planner_provider)
structured_llm = planner_llm.with_structured_output(Sections)
report_sections = structured_llm.invoke([SystemMessage(content=system_instructions_sections)]+[HumanMessage(content="Generate the sections of the report. Your response must include a 'sections' field containing a list of sections. Each section must have: name, description, plan, research, and content fields.")])
# Get sections
sections = report_sections.sections
return {"sections": sections}
human_feedbackノード
generate_report_planノードが提案した章構成で問題ないかを人間が判断します。
章構成に問題がある場合は、人のフィードバックを踏まえて、再度generate_report_planノードを呼び出し、
問題がない場合は、トピックと章構成を次のノードに渡します。
ここがHuman-in-the-loopの実装ノードですね。
from langgraph.types import interrupt
でimportされているinterruptを使用すると、ノードがユーザーからの入力を受け付けるようになるそうです。もう少し調べてみると、公式ページに以下のような記載がありました。
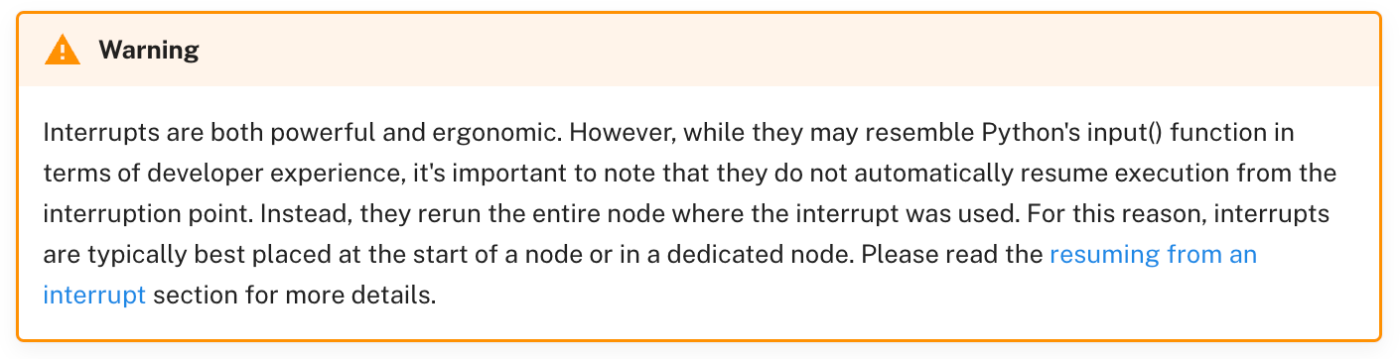
どうやら、ノード内にinterruptによってユーザーが入力を受け付けた後、
処理が再開されるのは、”interruptの処理後ではなく、nodeの先頭から”だそうです。
interruptを呼び出す場合は、それ専用のノードを作成するか、ノードの先頭に持ってこないといけないですね。
def human_feedback(state: ReportState, config: RunnableConfig) -> Command[Literal["generate_report_plan","build_section_with_web_research"]]:
""" Get feedback on the report plan """
# Get sections
topic = state["topic"]
sections = state['sections']
sections_str = "\n\n".join(
f"Section: {section.name}\n"
f"Description: {section.description}\n"
f"Research needed: {'Yes' if section.research else 'No'}\n"
for section in sections
)
# Get feedback on the report plan from interrupt
feedback = interrupt(f"Please provide feedback on the following report plan. \n\n{sections_str}\n\n Does the report plan meet your needs? Pass 'true' to approve the report plan or provide feedback to regenerate the report plan:")
# If the user approves the report plan, kick off section writing
# if isinstance(feedback, bool) and feedback is True:
if isinstance(feedback, bool):
# Treat this as approve and kick off section writing
return Command(goto=[
Send("build_section_with_web_research", {"topic": topic, "section": s, "search_iterations": 0})
for s in sections
if s.research
])
# If the user provides feedback, regenerate the report plan
elif isinstance(feedback, str):
# treat this as feedback
return Command(goto="generate_report_plan",
update={"feedback_on_report_plan": feedback})
else:
raise TypeError(f"Interrupt value of type {type(feedback)} is not supported.")
章の内容生成サブグラフ
章構成が決定したら、章の内容を生成します。
章の内容生成では、サブグラフをノードとして扱い、章ごとにノードを並列実行しています。
下図のnode_a, node_b, node_cがそれぞれサブグラフになっているイメージです。

先にメイングラフの流れを見てから、サブグラフの詳細を追っていきたいと思います。
write_final_sectionsノード
これまでの章の内容から、まとめの章を生成します。
基本的に章の生成ノードと役割は変わりませんが、プロンプトが若干違いました。
コードも特筆すべきポイントはないです。
def write_final_sections(state: SectionState, config: RunnableConfig):
""" Write final sections of the report, which do not require web search and use the completed sections as context """
# Get configuration
configurable = Configuration.from_runnable_config(config)
# Get state
topic = state["topic"]
section = state["section"]
completed_report_sections = state["report_sections_from_research"]
# Format system instructions
system_instructions = final_section_writer_instructions.format(topic=topic, section_title=section.name, section_topic=section.description, context=completed_report_sections)
# Generate section
writer_provider = get_config_value(configurable.writer_provider)
writer_model_name = get_config_value(configurable.writer_model)
writer_model = init_chat_model(model=writer_model_name, model_provider=writer_provider, temperature=0)
section_content = writer_model.invoke([SystemMessage(content=system_instructions)]+[HumanMessage(content="Generate a report section based on the provided sources.")])
# Write content to section
section.content = section_content.content
# Write the updated section to completed sections
return {"completed_sections": [section]}
gather_completed_sectionsノード
これまで生成された調査結果を文字列として整形しています。
このノードはLLMを使用していないロジックベースのノードです。
def gather_completed_sections(state: ReportState):
""" Gather completed sections from research and format them as context for writing the final sections """
# List of completed sections
completed_sections = state["completed_sections"]
# Format completed section to str to use as context for final sections
completed_report_sections = format_sections(completed_sections)
return {"report_sections_from_research": completed_report_sections}
compile_final_reportノード
各セクションを二重改行で連結し、1つの文章にまとめています。
ここも先ほど同様ロジックベースのノードです。
def compile_final_report(state: ReportState):
""" Compile the final report """
# Get sections
sections = state["sections"]
completed_sections = {s.name: s.content for s in state["completed_sections"]}
# Update sections with completed content while maintaining original order
for section in sections:
section.content = completed_sections[section.name]
# Compile final report
all_sections = "\n\n".join([s.content for s in sections])
return {"final_report": all_sections}
メイングラフに登場するノードの紹介は以上です。
続いて、サブグラフの紹介です。
章内容生成サブグラフ
サブグラフのワークフローは以下の通りです。
- LLM:トピックに関連するクエリの決定
- API:検索APIを使って、クエリを検索
- LLM:検索結果から、章内容を生成 & 章内容に問題あればStep2へ
最終的な成果物に情報の不足等問題があれば、検索クエリを追加して、Step2に戻るようなワークフローになっています。これによってより広い範囲で情報を拾うようになっています。
メイングラフのgenerate_report_planでは、"検索クエリの決定→検索API呼び出し→LLMによる章構成決定"という処理を1つのノードで完結させていましたが、サブグラフでは、このフィードバック&検索ループを実現するために、それらを3つのノードに分けています。
generate_queriesノード
ユーザーから指定されたトピックと章題から、検索用クエリを複数決定するノードです。
def generate_queries(state: SectionState, config: RunnableConfig):
""" Generate search queries for a report section """
# Get state
topic = state["topic"]
section = state["section"]
# 略
# Format system instructions
system_instructions = query_writer_instructions.format(topic=topic, section_topic=section.description, number_of_queries=number_of_queries)
# Generate queries
queries = structured_llm.invoke([SystemMessage(content=system_instructions)]+[HumanMessage(content="Generate search queries on the provided topic.")])
return {"search_queries": queries.queries}
search_webノード
検索クエリを複数受け取って、その検索結果をdeduplicate_and_format_sources()を使って整形しています。このノードでは、State内のsearch_iterationsをインクリメントしていて、検索回数をノード間で共有しています。これは、検索ループが無限に続かないように上限を設定するためです。
async def search_web(state: SectionState, config: RunnableConfig):
""" Search the web for each query, then return a list of raw sources and a formatted string of sources."""
# 略
# Search the web
if search_api == "tavily":
search_results = await tavily_search_async(query_list)
source_str = deduplicate_and_format_sources(search_results, max_tokens_per_source=5000, include_raw_content=True)
elif search_api == "perplexity":
search_results = perplexity_search(query_list)
source_str = deduplicate_and_format_sources(search_results, max_tokens_per_source=5000, include_raw_content=False)
else:
raise ValueError(f"Unsupported search API: {configurable.search_api}")
return {"source_str": source_str, "search_iterations": state["search_iterations"] + 1}
write_sectionノード
このノードでは、検索結果を用いて章の内容を生成しています。
このノードのポイントは、章の内容を生成するLLMと、内容を精査しフィードバックをするLLMの2つが含まれていることです。
章の内容に問題がある場合は、フィードバックを含めて再度サブグラフの最初からやり直しています。
これはCommandを使って実現しています。gotoで移行したいノードを指定していて、ENDに行くか、search_webにいくかをハンドリングしています。
if feedback.grade == "pass" or state["search_iterations"] >= configurable.max_search_depth:
# Publish the section to completed sections
return Command(
update={"completed_sections": [section]},
goto=END
)
else:
# Update the existing section with new content and update search queries
return Command(
update={"search_queries": feedback.follow_up_queries, "section": section},
goto="search_web"
)
グラフ構成
最後にエージェントグラフ全体の構成を見ていきます。
# Add nodes
section_builder = StateGraph(SectionState, output=SectionOutputState)
section_builder.add_node("generate_queries", generate_queries)
section_builder.add_node("search_web", search_web)
section_builder.add_node("write_section", write_section)
# Add edges
section_builder.add_edge(START, "generate_queries")
section_builder.add_edge("generate_queries", "search_web")
section_builder.add_edge("search_web", "write_section")
# Outer graph --
# Add nodes
builder = StateGraph(ReportState, input=ReportStateInput, output=ReportStateOutput, config_schema=Configuration)
builder.add_node("generate_report_plan", generate_report_plan)
builder.add_node("human_feedback", human_feedback)
builder.add_node("build_section_with_web_research", section_builder.compile())
builder.add_node("gather_completed_sections", gather_completed_sections)
builder.add_node("write_final_sections", write_final_sections)
builder.add_node("compile_final_report", compile_final_report)
# Add edges
builder.add_edge(START, "generate_report_plan")
builder.add_edge("generate_report_plan", "human_feedback")
builder.add_edge("build_section_with_web_research", "gather_completed_sections")
builder.add_conditional_edges("gather_completed_sections", initiate_final_section_writing, ["write_final_sections"])
builder.add_edge("write_final_sections", "compile_final_report")
builder.add_edge("compile_final_report", END)
graph = builder.compile()
サブグラフの実装
メイングラフ、サブグラフそれぞれStateGraphで作られています。
それぞれadd_nodeを作り、add_edgeでノードどうしを直列でつないでいるのがわかります。
メイングラフからサブグラフを呼び出す時は、コンパイルされたサブグラフをedgeに渡しているのがわかります。意外と単純な実装ですね。
builder.add_node("build_section_with_web_research", section_builder.compile())
ちなみにサブグラフからメイングラフに戻る時は、サブグラフの最終ノードでgotoにENDを指定していますが、以下の実装のようにCommandの引数にgraph=Command.Parentを渡すことで、親グラフのノードを遷移先として明示的に指定することもできます。
if feedback.grade == "pass" or state["search_iterations"] >= configurable.max_search_depth:
# Publish the section to completed sections
return Command(
graph=Command.PARENT,
goto='gather_completed_sections',
update={"completed_sections": [section]},
)
複数ノードの並列実行の実装
1つだけ条件付きedgeが使用されていることがわかります。
builder.add_conditional_edges("gather_completed_sections", initiate_final_section_writing, ["write_final_sections"])
initiate_final_section_writingの中身を見てみると、
def initiate_final_section_writing(state: ReportState):
""" Write any final sections using the Send API to parallelize the process """
# Kick off section writing in parallel via Send() API for any sections that do not require research
return [
Send("write_final_sections", {"topic": state["topic"], "section": s, "report_sections_from_research": state["report_sections_from_research"]})
for s in state["sections"]
if not s.research
]
となっています。
ここが複数ノードの並列実行を実現している実装です。
公式ドキュメントをみると、Sendクラスは並列実行したノードの数が動的に変化する場合に有効だそうです。add_conditional_edgesの第二引数で渡す関数の返り値として使います。Sendクラスの第一引数は次のノード名、第二引数はそのノードに渡すStateです。
ちなみに、add_conditionial_edgesの第三引数(Optional)は、path_mapを指定しています。このEdgeから遷移するノードをマッピングするためのパラメータのようです。これを指定しないと遷移先ノード決定関数の返り値が1つ以上のノード名に限定されます。
def add_conditional_edges(
self,
source: str,
path: Union[
Callable[..., Union[Hashable, list[Hashable]]],
Callable[..., Awaitable[Union[Hashable, list[Hashable]]]],
Runnable[Any, Union[Hashable, list[Hashable]]],
],
path_map: Optional[Union[dict[Hashable, str], list[str]]] = None,
then: Optional[str] = None,
) -> Self:
"""Add a conditional edge from the starting node to any number of destination nodes.
Args:
source (str): The starting node. This conditional edge will run when
exiting this node.
path (Union[Callable, Runnable]): The callable that determines the next
node or nodes. If not specifying `path_map` it should return one or
more nodes. If it returns END, the graph will stop execution.
path_map (Optional[dict[Hashable, str]]): Optional mapping of paths to node
names. If omitted the paths returned by `path` should be node names.
then (Optional[str]): The name of a node to execute after the nodes
selected by `path`.
Returns:
Self: The instance of the graph, allowing for method chaining.
Note: Without typehints on the `path` function's return value (e.g., `-> Literal["foo", "__end__"]:`)
or a path_map, the graph visualization assumes the edge could transition to any node in the graph.
"""
OpenDeepResearchのAIワークフローの流れと、実装ポイントは以上になります。
この実装をベースにすれば、いろいろなカスタムワークフローが実装できそうですね。
最後に
間違っている点あるかと思いますので、ご指摘・コメントいただけたら嬉しいです。
最後まで読んでいただきありがとうございました!
コメントください!!
Discussion