ABC228 D - Linear Probing C++解答例



AtCoder Beginner Contest D - Linear ProbingをC++で解きます。
問題
問題文をAtCoderのページより引用します。
問題文
項からなる数列 N = 2^{20} があります。はじめ、全ての要素は-1です。 A = (A_0, A_1, \ldots, A_{N - 1})
個のクエリを順番に処理してください。 Q 個目のクエリは i(1 \leq i \leq Q) または t_i = 1 を満たす整数 t_i = 2 および整数 t_i で表され、内容は以下の通りです。 x_i
のとき、以下の処理を順番に行う。 t_i = 1
- 整数
を h で定める h = x_i である間、 A_{h \bmod N} \neq -1 の値を1増やすことを繰り返す。この問題の制約下でこの操作が有限回で終了することは証明できる。 h の値を A_{h \bmod N} で書き換える。 x_i のとき、その時点での t_i = 2 の値を出力する。 A_{x_i \bmod N} なお、整数
に対し、 a, b を a で割った余りを b と表します。 a \bmod b
制約
1 \leq Q \leq 2 \times 10^5 t_i \in \{1, 2\} (1 \leq i \leq Q) 0 \leq x_i \leq 10^{18} (1 \leq i \leq Q) であるような t_i = 2 が1つ以上存在する。 i(1 \leq i \leq Q) - 入力はすべて整数である。
解答例
計算量が大きいところ(高速化すべきところ)を見つける
クエリ処理の問題なので、問題文の通りに愚直に実装するとTLEになることは目に見えています。
高速化すべきところを探すところから始めます。
まず、
したがって、高速化すべきクエリは
クエリ1の処理内容を見てみます。問題文を要約すると、
- 配列
A x_i \bmod N -1なら、その要素の値をx_i - その要素の値が既に
-1でない値で埋まっていたら、配列A -1である要素のうち、インデックスがx_i \bmod N x_i
という操作であることがわかります。
このクエリの中で、「値がまだ-1であり、かつインデックスが
問題文の「
この処理を高速化することができれば問題を解くことができそうです。
値が確定していない要素のインデックスを集合で管理する
便宜上、配列-1)である要素のことを、「値が確定していない要素」と呼ぶことにします。
「値が確定していない要素のうち、インデックスがstd::setを使えば高速に処理することができます。
まだ値が確定していない要素のインデックスを集合の元として管理し、値が確定したら集合から削除します。
インデックスの検索処理は、std::setの二分探索メソッドであるlower_boundまたはupper_boundを用いることで高速に行うことができます。
インデックスを探すときの注意点
std::setの二分探索でインデックスを探す際の注意点として、
例えば図で表すとこんな感じです。
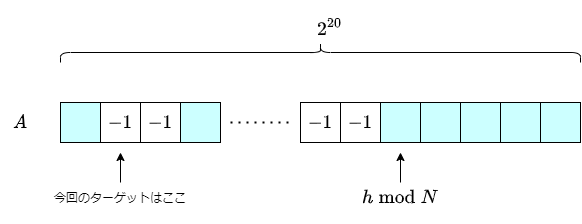
水色のマスは値が確定していることを表しています
あるクエリ
したがって、二分探索の結果、要素が見つからなかったとき(lower_boundがstd::set::end()を返したとき)は、値が確定していない要素のうち一番若いインデックスを持つ要素をターゲットとして、その要素の値を書き換える必要があるということになります。
std::setは順序付き集合なので、「値が確定していない要素のうち一番若いインデックス」は、std::setの先頭に格納されているため。std::set::beginでアクセスすることができます。これを利用しましょう。
実装例
C++の実装例を以下に示します。
#include <iostream>
#include <vector>
#include <algorithm>
#include <set>
int main() {
int64_t Q;
std::cin >> Q;
// クエリの受け取り
std::vector<std::pair<int64_t, int64_t>> query(Q);
for (int64_t i = 0; i < Q; i++) {
int64_t t, x;
std::cin >> t >> x;
query.at(i) = std::make_pair(t, x);
}
int64_t N = 1 << 20;
// 配列Aの各要素の初期値は-1
std::vector<int64_t> A(N, -1);
// 値が確定していない要素のインデックスを格納する集合
std::set<int64_t> indexes;
// 初期状態では全てのインデックスが集合に属している
for (int64_t i = 0; i < N; i++) {
indexes.insert(i);
}
// クエリ処理開始
for (int64_t i = 0; i < Q; i++) {
int64_t t = query.at(i).first;
int64_t x = query.at(i).second;
switch (t) {
case 1:
// A_{h mod N}の値が確定していないとき
if (A.at(x % N) == -1) {
// そのまま値をxで上書きする
A.at(x % N) = x;
// 値が確定した要素のインデックスは集合から削除する
indexes.erase(x % N);
} else {
// 二分探索によってターゲットのインデックスを探す
auto iter = indexes.lower_bound(x % N);
int64_t target_index;
// ターゲットが見つからなかったとき
if (iter == indexes.end()) {
// 一番若いインデックスをターゲットとする
target_index = *indexes.begin();
} else {
// 見つかったらそれをターゲットとする
target_index = *iter;
}
// 値をxで書き換える
A.at(target_index) = x;
// 値が確定したので集合から削除する
indexes.erase(target_index);
}
break;
case 2:
// 値の出力
std::cout << A.at(x % N) << std::endl;
break;
}
}
return 0;
}
実際に提出したコードはこちら。
Discussion