Pythonで実装する非再帰抽象化セグメント木
競技プログラミングでよく使われるデータ構造「セグメント木」をPythonで実装し、仕組みや実装方法を理解します。
セグメント木の概要
セグメント木とは
区間に対するクエリを高速に処理できるデータ構造の1つです。各ノードが区間に対応付けられた完全二分木として表現されます。
根は区間全体を表し、各ノードの子は親の区間を二等分した区間を表現します。
具体的には、以下のようなクエリを
-
i -
i - 区間
[l, r)
セグメント木の構成要素
セグメント木は以下の要素から成ります。
- 区間の要素の型
S - 二項演算子
\bullet: S \times S \rightarrow S
例えば区間最小値を求めるRange Minimum Query問題では、要素の型はintで、二項演算子はmin()が当てはまります。
区間和を求める問題では、二項演算子は足し算になります。
どんな型と二項演算子でも適用できるわけではなく、これらはモノイドを成していなければなりません。
モノイドの定義は以下です:
集合
- 結合律:
S a, b, c \in S (a \bullet b) \bullet c = a \bullet (b \bullet c) - 単位元律:任意の
a \in S a \bullet e = e \bullet a = a e
ざっくり言い換えると、「演算の順番で結果が変わらない」「演算しても値が変わらないような値が存在する」を満たしていればセグメント木に乗せることができます。
例えば、整数同士の掛け算を考えると、
- 集合
S \mathbb{Z} - 二項演算子
\bullet \times - 単位元は
1
となり、組
競技プログラミングでは大抵の場合、集合
二項演算子としては以下のものをよく使います。
| 演算 | 単位元 | 対応するPython関数 |
|---|---|---|
| 和 | 0 | operator.add |
| 積 | 1 | operator.mul |
| 最小値 | min |
|
| 最大値 | max |
|
| 論理和 | 0 | operator.or_ |
| 論理積 | 1 | operator.and_ |
| 排他的論理和 | 0 | operator.xor |
| 最大公約数 | 0 | math.gcd |
| 最小公倍数 | 1 |
math.lcm(Python3.9以降) |
尚、二項演算の結果を積と呼びます。
実装
ここからはセグメント木の実装をするための仕様やデータ表現方法を決定します。
セグメント木に対する操作の定義
本記事で実装するセグメント木は、以下の操作を受け付けることを想定します。
- 構築:クエリの対象となるリスト
A = (a_0, a_1, \ldots, a_{N-1}) - 点取得:
k - 点更新:
k - 区間取得:区間
[l, r)
ここで、
セグメント木はクラスで実装するものとし、最初の操作はコンストラクタで、その他の操作はメソッドで行うものとします。
データの表現方法
セグメント木は完全二分木なので、1つのリストで表現することができます。
木を表現するリストの長さは、葉の数を
完全二分木であるので、葉の数は2のべき乗個である方が都合が良いです。
クエリ対象のリスト
また、セグメント木を表すリストは1-indexedで実装します[2]。つまり、根を表すノードはインデックスが1となります。
こうすることで、木のノードのインデックスに対する演算は以下のようになります。
- インデックス
k 2k - インデックス
k 2k + 1 - インデックス
k \lfloor \frac{k}{2} \rfloor - リスト
A a_i i + M (0 \leq i < N)
これらを踏まえ、各操作を行うための処理を実装していきます。
操作1:セグメント木の構築
二項演算子
二項演算子と単位元は関数オブジェクトとして扱います。例えば二項演算子が最小値minの場合、以下のような関数を受け取ることになります[3]。
# 二項演算子
def op(a: S, b: S) -> S:
return min(a, b)
# 単位元
def e() -> S:
# 十分大きい整数で+∞を代用する。
return 1 << 60
次に、リスト
葉の値はリスト
その他の要素は全て単位元
その後、
更新処理は後述します。
セグメント木の構築にかかる時間計算量は
操作2:点取得
点取得の処理は簡単で、インデックス
操作3:点更新
ここからはノードの更新処理を実装していきます。
点更新を実装するために、まずは「子ノードの値をもとにノードの値を計算する処理」を考えます。
これは単純に、左右の子ノードの値に対して二項演算子opを適用するだけで良いです。左右の子にアクセスするにはそれぞれ
D[k] = op(D[2 * k], D[2 * k + 1])
次に、ある葉の値を更新したときに、その値を各区間へ反映させることを考えます。
葉の値を更新したら、「その葉を含む区間」の値を更新しなければなりません。この区間は葉の親を順に辿っていくことで全て網羅することができます。
すなわち、値を更新した葉から根に向かって親へと辿って行き、各親について、子ノードの値を用いて値を更新していけばよいです。
このプロセスを図にすると、以下のようになります。
まず、葉の値を更新します。ここでは
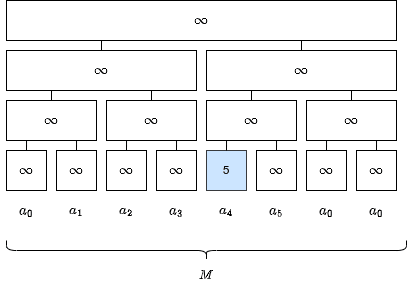
ここから、
これらを順に辿っていくには、インデックスを2で割り続ければよいです。
それぞれの親について値の更新処理をすることで、点更新処理を完了できます。
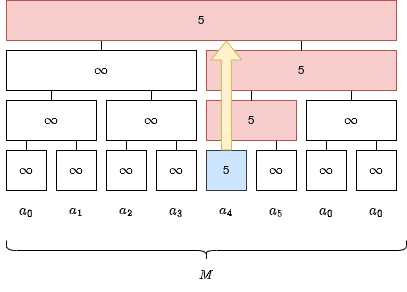
コードにすると以下のようになります。親を辿る際はビットシフトを用いると簡潔に書けます。
def update(k: int):
D[k] = op(D[2 * k], D[2 * k + 1])
# k: 更新する葉のインデックス(0-indexed, 0 <= key < N)
# value: 更新する値
# 葉に移動する
k += M
# 葉の値を更新する
D[k] = value
# H: セグメント木の高さ
# M = 2 ^ H が成り立つ。
for i in range(1, H + 1):
# k >> iとすることで、i世代前のkの親にアクセスできる
update(k >> i)
操作4:区間取得
最後に、区間
この処理では、「指定された区間をカバーする全てのノードを見つけ出し、それぞれの値を集約する」手順をボトムアップで行います。
例として、
構築後の時点では、セグメント木は以下のような状態になっています。
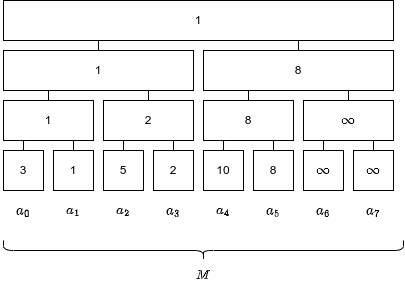
ここで、区間
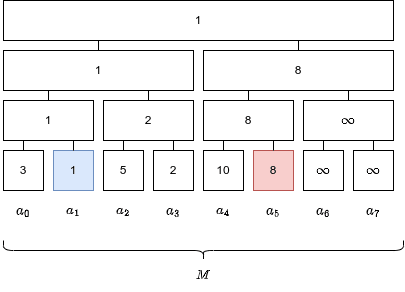
この区間
セグメント木を見ると、
二項演算子
が成り立ち、計算回数を減らすことができます。
適切なノードの組み合わせを選ぶことで、少ない計算回数で効率的に区間の積を求めることができるわけです。
では、このようなノードの組み合わせをどのように選択すればよいでしょうか?
結論から述べると、ノード
区間の左側のノード
- ノード
D_{M + l} D_{M + l} D_{M + l}
従って、ノードD_{M + l} - ノード
D_{M + l} D_{M + l} D_{M + l}
従って、ノードD_{M + l}
区間の右側のノード
- ノード
D_{M + r} D_{M + r}
従って、ノードD_{M + r} - ノード
D_{M + r} D_{M + r}
従って、ノードD_{M + r}
これらの条件分岐をしつつ、選択したノードの値について逐一積を計算しながら親へ親へと移動していきます。
全ての区間を網羅したときの積の結果が区間
ソースコード例
以上を踏まえて非再帰抽象化セグメント木を実装すると、以下のようになります。
Pythonクラスとして実装するにあたり、点取得・点更新は特殊メソッド__getitem__()、__setitem__()を使って実装するようにしています。
区間積の計算は、通常のメソッドとして実装した他、各括弧にスライスでアクセスしたときも同じ結果が返るようにしています。
使用例
セグメント木を用いていくつかの問題を解いてみます。
Aizu Online Judge DSL 2_A Range Minimum Query(RMQ)
典型的なセグメント木の使用例です。点更新と区間積を求める問題です。
from typing import (
List,
TypeVar,
Callable,
Generic,
Iterator,
Union,
)
# セグメント木のクラス実装は省略
def main():
N, Q = map(int, input().split())
query = [list(map(int, input().split())) for i in range(Q)]
seg = SegmentTree[int](
lambda a, b: min(a, b), lambda: (1 << 31) - 1, [(1 << 31) - 1] * N
)
for t, x, y in query:
if t == 0:
seg[x] = y
else:
print(seg[x : y + 1])
if __name__ == "__main__":
main()
実際の提出はこちら。
Aizu Online Judge DSL 2_B Range Sum Query(RSQ)
こちらも典型です。点取得、点更新、および区間積の操作が必要となります。
なぜか入力が1-indexedで与えられるので注意です。
from typing import (
List,
TypeVar,
Callable,
Generic,
Iterator,
Union,
)
# セグメント木のクラス実装は省略
def main():
N, Q = map(int, input().split())
query = [list(map(int, input().split())) for i in range(Q)]
seg = SegmentTree[int](lambda a, b: a + b, lambda: 0, [0] * N)
for t, x, y in query:
if t == 0:
x -= 1
seg[x] = seg[x] + y
else:
x -= 1
y -= 1
print(seg[x : y + 1])
if __name__ == "__main__":
main()
実際の提出はこちら。
2023/12/09 追記
- 「右側の結果を計算していく箇所、
right_result = self._op(right_result, self._data[r])では可換性を求められるのでは?」という指摘があり、確かにその通りだったのでコードを修正しました。 - 使用例も修正後の実装で提出したものに差し替えました。
参考文献
- セグメント木を徹底解説!0から遅延評価やモノイドまで - アルゴリズムロジック
- セグメント木を使う - Zenn
- セグメント木をソラで書きたいあなたに hogecoder
- セグメント木を一歩一歩実装して理解しようとする(python) - Qiita
- プログラミングコンテストでのデータ構造 - slideshare
- 競技プログラミングノート セグメント木 - Read the Docs
- モノイド - Wikipedia
Discussion