フロントエンド学び直し
DOCKTYPE
TML文書の最初に記述するもので、その文書がどのバージョンのHTML(またはXHTML)で書かれているかをブラウザに伝える役割を持ちます。具体的には、ブラウザがそのHTMLを適切にレンダリングできるよう、ドキュメントのモード(標準モードや互換モードなど)を決定します
ブラウザへのヒント: HTML文書がどの規格に基づいているかをブラウザに伝えます。
表示モードの選択: ブラウザが標準モードでHTMLを解釈するために必要です。もしDOCTYPE宣言がない場合、ブラウザは互換モードに入り、古いHTMLの解釈をします
多言語サイトの作成
-
lang属性を使用し、ブラウザにページの言語を教える
- アクセシビリティ向上: スクリーンリーダーは、lang属性に基づいて適切な発音やイントネーションを設定
- SEO向上: 検索エンジンはlang属性を参照してページの言語を認識し、その言語に適した検索結果としてインデックスに登録し
-
lang属性にはISO 639-1 Language CodesもしくはISO 3166-1 Country Codesも付け加えたものを指定
- lang属性に指定する言語コードは、国際標準のISO 639-1の2文字の言語コードです。
- 場合によっては、国コード(ISO 3166-1 Country Codes)も追加して、特定の国における言語のバリエーションを示すことができます。
<html lang="en-US"> <!-- アメリカ英語 -->
<html lang="fr-CA"> <!-- カナダのフランス語 -->
- dir属性を使用し、right-to-leftの言語(アラビア語等)に対応する
- dir属性はテキストの読み方向(LTR: left-to-right または RTL: right-to-left)を指定します
- dir="ltr": テキストが左から右に表示されます(例:英語、日本語)。
- dir="rtl": テキストが右から左に表示されます(例:アラビア語、ヘブライ語)。
- dir属性はテキストの読み方向(LTR: left-to-right または RTL: right-to-left)を指定します
<html lang="ar" dir="rtl"> <!-- アラビア語は右から左に読む -->
-
フォントと文字セット: 多言語対応の際は、適切な文字セット(UTF-8など)を指定することが必要です。これにより、特殊な文字や異なる言語のスクリプトが正しく表示されます
-
翻訳やローカリゼーションの注意点: 単なる翻訳だけでなく、文化的な意味やニュアンスにも配慮したコンテンツ
セマンティックHTML
セマンティック要素は、そのタグが持つ意味が明確で、ブラウザや他のツールがその内容を理解しやすくするために使われます
一方、<div>や<span>のような要素は非セマンティック要素と呼ばれます。これらはコンテンツの意味を持たず、単にレイアウトを制御するために使われます。例えば、CSSでスタイルを適用したい部分を囲むのに使われますが、その内容が何を表しているかはタグ自体からはわかりません。
- セマンティックなHTMLのメリット
- SEO(検索エンジン最適化)への効果: セマンティックHTMLを使うと、検索エンジンがページのコンテンツをより正確に理解できるようになります。
- アクセシビリティ(スクリーンリーダー)への効果
スクリーンリーダーなどの支援技術は、セマンティック要素を利用してWebページをユーザーに正確に読み上げます - コードの可読性とメンテナンス性: セマンティックHTMLを使うことで、開発者はコードをより直感的に理解できます。
Open Graph (OG) タグの設定
WebページのリンクをSNSで共有したときに、画像やタイトル、説明が正しく表示するために、ページの<head>内にSNSが認識できるメタタグを追加する必要がある。
- Open Graph (OG) タグを設定する: Open Graphプロトコルは、FacebookやLinkedIn、TwitterなどのSNSで共有されたときに、ページのタイトル、説明、画像を正しく表示するためのメタデータフォーマットです
<head>
<!-- ページのタイトル -->
<meta property="og:title" content="ページのタイトル" />
<!-- ページの説明 -->
<meta property="og:description" content="ページの説明文" />
<!-- サイトのURL -->
<meta property="og:url" content="https://www.example.com" />
<!-- サイトの画像(推奨サイズ:1200x630ピクセル) -->
<meta property="og:image" content="https://www.example.com/image.jpg" />
<!-- コンテンツのタイプ(ウェブサイトや記事など) -->
<meta property="og:type" content="website" />
<!-- サイト名 -->
<meta property="og:site_name" content="サイト名" />
</head>
- Twitter Card タグを設定する
Twitterは独自のメタタグ形式であるTwitter Cardsをサポートしています。Twitter Cardsタグを追加すると、ツイートにリンクが共有された際に、視覚的にリッチなメディアが表示されます
<head>
<!-- Twitter Cardの種類(通常はsummary_large_imageが推奨される)-->
<meta name="twitter:card" content="summary_large_image" />
<!-- Twitterに表示させたいタイトル -->
<meta name="twitter:title" content="ページのタイトル" />
<!-- Twitterに表示させたい説明 -->
<meta name="twitter:description" content="ページの説明文" />
<!-- Twitterに表示させたい画像 -->
<meta name="twitter:image" content="https://www.example.com/image.jpg" />
<!-- サイトのURL -->
<meta name="twitter:url" content="https://www.example.com" />
<!-- Twitterアカウントのハンドル名(オプション) -->
<meta name="twitter:site" content="@your_twitter_handle" />
</head>
Webアクセシビリティ
様々なユーザーがWebサイトを快適に利用できるようにする工夫が必要です。特に、視覚や聴覚に障害があるユーザー、キーボードのみを使用するユーザー、高齢者、あるいは一時的に手が使えないユーザーにも配慮することが重要です。
- 画像などの代替えテキスト(Alt)を設定する
- スクリーンリーダーを使う視覚障害者にとって非常に重要
- ラベルを用いてフォームコントロールと関連付け
- フォーム入力欄やボタンなどのUIコントロールには、対応する<label>タグを使って明確なラベルを関連付けます。これにより、スクリーンリーダーがそのフォーム要素の目的を説明でき、視覚障害者が適切にフォームを利用できるようになります。
<label for="email">メールアドレス:</label>
<input type="email" id="email" name="email" />
- HTMLセマンティック要素を正しく使う
- HTMLのセマンティック要素を正しく使用することは、アクセシビリティの向上につながります。<header>, <nav>, <main>, <article>, <footer>などの要素を適切に使うことで、ページの構造が明確になり、支援技術(スクリーンリーダーなど)がコンテンツを適切にナビゲートできます
- 全ての機能がキーボードで操作できるようにする
- 全てのインタラクティブな要素(リンク、ボタン、フォームなど)がキーボードでアクセスできるようにする必要がある
- キーボードナビゲーションに対応したフォーカス管理や、キーボード操作でのスムーズな移動が含まれます。例えば、tabキーでフォーカスが正しく移動できるか、enterキーやspaceキーでボタンが操作できるか確認する
- コントラスト比に気をつける
- 一般的に、WCAG(Web Content Accessibility Guidelines)では、通常のテキストには少なくとも4.5:1、拡大テキストでは3:1のコントラスト比が推奨
- リンクのテキストをわかりやすくする
- リンクには、「こちらをクリック」などの曖昧な表現を避け、リンク先の内容がわかるように明確なテキストを設定
<a href="example.com">製品の詳細情報</a>
- リンクには、「こちらをクリック」などの曖昧な表現を避け、リンク先の内容がわかるように明確なテキストを設定
script、script async、script defer違い
ブラウザがJavaScriptファイルを読み込んで実行するタイミングを制御するための方法。
-
<script>(通常のスクリプト): <script>タグは、JavaScriptファイルを同期的に読み込み、即座に実行します。
- ブラウザがHTMLをパースしている途中で<script>タグに出会うと、その場でHTMLのパースを一時停止します。
- スクリプトがダウンロードされ、読み込みが完了するとすぐに実行されます。
- スクリプトの実行が完了するまでHTMLのパースは再開されません。
メリット:
JavaScriptがHTMLのパース中にすぐに必要な場合や、DOMが完全に読み込まれる前に実行する必要がある場合に有効です。
デメリット:
スクリプトの読み込みや実行が遅い場合、ページの表示が遅延することがあります
-
<script async>: 属性を持つスクリプトは、HTMLのパースとは独立して非同期に読み込まれます。読み込みが完了した時点でスクリプトがすぐに実行されますが、その際にはHTMLのパースが一時停止します。
- ブラウザはスクリプトを非同期で読み込みます。
- スクリプトの読み込みが完了したら、HTMLのパースを一時停止してスクリプトを実行します。
- 実行が完了した後に、HTMLのパースが再開されます。
メリット:
ページの読み込みパフォーマンスを向上させることができます。スクリプトが読み込まれる間もHTMLのパースが続行されるため、ページがより早く表示されます。
デメリット:
スクリプトがいつ実行されるかは、他のスクリプトやHTMLのパースとのタイミングに依存します。そのため、DOMに依存するスクリプトの実行が適切に行えない可能性があります。
-
<script defer>: 属性を持つスクリプトは、HTMLのパースが完了するまで実行が遅延されます。読み込み自体は非同期に行われますが、実行はHTML全体のパースが終わった後になります
- ブラウザはスクリプトを非同期で読み込みます。
- HTMLのパースが完了した後に、スクリプトが順番通りに実行されます。メリット:
HTMLが完全に読み込まれた後にスクリプトを実行するため、DOM操作を行うスクリプトでも安心して利用できます。
スクリプトがHTMLのレンダリングに影響を与えないため、ページのパフォーマンスが向上します。
デメリット:
スクリプトの実行がHTMLのパース完了まで遅れるため、即座に実行されるスクリプトが必要な場合には不適切です。
next/scriptでスクリプトの読み込みを制御
Next.jsはnext/scriptコンポーネントを提供しており、スクリプトのロードタイミングをより細かく制御できます。例えば、strategyプロパティを使ってスクリプトの読み込み方法を指定できます。
strategy="afterInteractive": ページがインタラクティブになった後にスクリプトを実行
strategy="lazyOnload": ページ全体が読み込まれた後にスクリプトを実行
strategy="beforeInteractive": すべての他のスクリプトの前に実行
import Script from 'next/script';
export default function MyPage() {
return (
<>
<Script src="https://example.com/script.js" strategy="lazyOnload" />
<div>ページのコンテンツ</div>
</>
);
}
SSRとCSRのバランス
Next.jsでは、サーバーサイドでHTMLを生成するSSRやクライアント側で動的にレンダリングするCSRのバランスを考慮してスクリプトの読み込み順序を最適化することが大切です。SSRで生成されたHTMLがブラウザに送信された後、必要に応じて非同期でJavaScriptをロードすることで、パフォーマンスとインタラクティブ性の両方を高められます。
SSRのメリット: 初期表示が速く、検索エンジンにとっても最適です。
CSRのメリット: クライアントサイドでの動的な更新が容易になります。
image tag srcset属性
異なるデバイスや画面サイズ、解像度に応じて適切な画像を表示。デバイスの特性に合わせて最適な画像が選択され、ユーザーエクスペリエンスの向上やページのパフォーマンス改善が期待できます。
現代のWebデザインでは、スマートフォンやタブレット、4Kモニターなど、多様な解像度や画面サイズのデバイスが使用されています。srcset属性を使うと、同じ画像でも異なる解像度やサイズを指定でき、デバイスに適した画像が自動的に選ばれます。
<img src="image-1x.jpg"
srcset="image-1x.jpg 1x, image-2x.jpg 2x, image-3x.jpg 3x"
alt="デバイスに応じた最適な画像" />
Next.jsのnext/imageコンポーネントが自動で行う最適化
自動的なsrcset生成: next/imageは、デバイスの解像度や画面サイズに応じて複数の画像サイズを生成し、srcsetを自動的に生成します。これにより、高解像度ディスプレイ(Retinaディスプレイなど)に適した画像や、低解像度のデバイスに最適なサイズの画像が自動的に選択されます。
画像のレスポンシブ対応: next/imageを使用すると、ブラウザが自動的に画面サイズに応じて最適な画像サイズを選択します。例えば、モバイルデバイス向けには小さい画像、デスクトップ向けには大きい画像が提供されます。
画像の遅延読み込み(Lazy Loading): 画像がビューポートに表示されるまでロードを遅延させる「遅延読み込み(Lazy Loading)」がデフォルトで有効です。これにより、ページの初期ロード速度が向上し、ユーザーが画像を閲覧するタイミングに合わせて最適化されます。
画像の圧縮とフォーマットの最適化: Next.jsは画像を自動的に圧縮し、最適なフォーマット(WebPなど)に変換します。これにより、画像のファイルサイズが減少し、読み込み速度が改善されます。
CSSのCSSの詳細度 - Specificity
複数のCSSルールが同じ要素に適用される際に、どのルールが優先されるかを決定する仕組み
基本的な構造: CSSの詳細度は、IDセレクタ > クラスセレクタ > タイプセレクタの順で優先順位が決まる
- タイプセレクタ(要素セレクタ)や擬似要素
例:div, h1, p, ::before
詳細度: 1
スコア: 最も低い - クラスセレクタ、属性セレクタ、擬似クラス
例:.container, [type="text"], :hover
詳細度: 10
スコア: タイプセレクタより高いが、IDセレクタより低い - IDセレクタ
例:#header, #main
詳細度: 100
スコア: クラスセレクタやタイプセレクタよりも高い - インラインスタイル
例:<div style="color: red;">
詳細度: 1000
スコア: 通常のCSSセレクタよりも優先される - !important
!importantを使うと、そのスタイルが他のどのスタイルよりも強く適用されます。!importantは通常の詳細度計算を無視し、強制的に適用されるスタイルを定義しますが、同じプロパティで複数の!importantがある場合は、通常の詳細度計算が適用されます。
CSSボックスモデル
全てのHTML要素は、1つの「ボックス」として扱われ、このボックスがページのレイアウトやデザインを決定する基盤となる
- ボックスモデルの構成要素
- Content(コンテンツ領域)
定義: 要素の実際の内容(テキストや画像など)が表示される領域。
サイズ: widthやheightプロパティを使って指定される。
役割: 要素のコンテンツそのものが表示される範囲です。 - Padding(内側の余白)
定義: コンテンツとボーダーの間にある余白部分。
サイズ: paddingプロパティを使って指定される。paddingはすべての方向(上、右、下、左)に個別に設定可能です。
役割: コンテンツとボーダー(枠線)を分離するためのスペースです。 - Border(ボーダー / 枠線)
定義: 要素のコンテンツとパディングを囲む境界線。
サイズ: border-widthやborder-style、border-colorなどで設定でき、borderプロパティで一括して設定することも可能です。
役割: 要素を視覚的に区切るための枠線を定義します。borderを指定しない場合は枠線は表示されませんが、要素自体の領域は存在します。 - Margin(外側の余白)
定義: 要素とその周りの他の要素との間の外側の余白部分。
サイズ: marginプロパティを使って設定します。paddingと同様に、各方向(上、右、下、左)に個別に設定できます。
役割: 要素同士の間隔を設定し、ページ上でのレイアウトを調整します。marginは他の要素との距離を確保するために使われ、要素同士のスペースを保ちます。
ボックスサイズの計算
- 要素の全体の幅 = width + padding-left + padding-right + border-left + border-right + margin-left + margin-right
要素の全体の高さ = height + padding-top + padding-bottom + border-top + border-bottom + margin-top + margin-bottom
- div {
width: 200px;
padding: 20px;
border: 5px solid black;
margin: 10px;
}
要素の実際の幅は以下のようになります:
width: 200px
padding: 20px * 2(左右) = 40px
border: 5px * 2(左右) = 10px
margin: 10px * 2(左右) = 20px
合計幅 = 200 + 40 + 10 + 20 = 270px
box-sizingプロパティ
通常、widthやheightはコンテンツ領域のみを指定しますが、box-sizingプロパティを使うことで、paddingやborderを含めたサイズを指定することができます。これにより、要素の最終的なサイズを意図通りに制御しやすくなります。
例 box-sizing: border-box;
div {
width: 200px;
padding: 20px;
border: 5px solid black;
margin: 10px;
box-sizing: border-box;
}
この場合、box-sizing: border-box;を使用することで、指定したwidth(200px)にpaddingとborderが含まれるため、要素の最終的な幅は200pxに固定されます
CSSのblockとinlineとinline-block
- block
block要素は、ページ内で全幅を占有し、常に新しい行に表示される要素です。次に続く要素はその下に表示されます。block要素には、widthやheightなどのプロパティを指定することができます。
例: div, p, h1など
-
inline
inline要素は、行内に配置され、他の要素と同じ行に表示されます。inline要素は、要素の内容(テキストや画像)の幅だけを占有し、ブロック要素のように新しい行に配置されません。inline要素には、widthやheightを直接指定することはできません。 -
inline-block
inline-block要素は、inline要素のように同じ行に表示されますが、ブロック要素の特性も持つため、widthやheightを指定することができます。これにより、同じ行内に複数の要素を並べつつ、それぞれの要素に明示的なサイズを指定することが可能です。
特徴:
行内に表示される: inline要素のように他の要素と同じ行に並べて表示される。
サイズ変更が可能: widthやheightを指定できる。
マージンやパディングも指定可能: block要素と同様に、上下左右の余白を設定できる。
Flexboxの特徴(一次元レイアウト)
子要素(flex item)を横または縦の方向に整列させ、自由に配置を調整できます。要素を均等に分配したり、整列を柔軟に制御できるので、コンポーネント単位のレイアウト(ナビゲーションバーやカード、ヘッダーなど)に非常に適しています。
一次元の制御: 要素を1つの軸(行または列)に基づいて並べます。
スペースの自動調整: 子要素のサイズに応じて、余白を自動的に計算し、要素を等間隔に配置できます。
柔軟な整列: justify-contentやalign-itemsを使って、要素を中央揃え、左寄せ、右寄せなど自由に整列可能。
方向の制御: flex-directionを使って、要素を横(row)または縦(column)に並べることができます。
ナビゲーションバー: メニュー項目を横に並べたい場合。
カードのレイアウト: 各カードを同じ高さや幅に調整し、横方向に並べたい場合。
grid
Flexboxが一方向(横または縦)に特化しているのに対して、Gridは行と列の両方を同時に制御でき、要素を正確な位置に配置することができます。
二次元の制御: 行と列を指定し、要素をその交差点に配置できます。
明確なレイアウト: grid-template-rowsやgrid-template-columnsで行と列のサイズを指定できるため、正確なレイアウトが可能です。
グリッドラインの活用: グリッドラインを使って、要素を特定の位置に配置することができます。
より複雑なレイアウト: コンポーネントの内側だけでなく、ページ全体のレイアウトを定義する場合に便利です。
ウェブページ全体のレイアウト: 例えば、ヘッダー、メインコンテンツ、サイドバー、フッターなどをページ上で整列させる際に有効。
ダッシュボードレイアウト: カードやグラフ、リストを行と列に基づいて配置するダッシュボードのレイアウト。
-
横に並べる (flex-direction: row;)
flex-direction: row;はデフォルトの値で、Flexアイテムが横方向(左から右)に並びます。主軸が水平方向となり、各アイテムが横に配置されます。 -
縦に並べる (flex-direction: column;)
flex-direction: column;を使用すると、Flexアイテムが縦方向(上から下)に並びます。主軸が垂直方向に変わり、各アイテムが縦に配置されます。
flex-flow
flex-directionとflex-wrapの2つを組み合わせて1つのプロパティで設定できる便利なプロパティです。
flex-directionで並びの方向(横や縦)を指定し、flex-wrapでコンテナを超えた時に折り返すかどうかを指定します。
これにより、アイテムのレイアウトを効率的にコントロールでき、より柔軟なレイアウトが可能です。
flex-grow
アイテムの拡張比率を決定します。この値が大きいほど、そのアイテムは余白を多く占有します。
デフォルト値は0で、これにより、アイテムは成長せず、指定されたサイズのまま表示されます。
値を1以上に設定すると、Flexアイテムは親要素内の余白を他のアイテムと比例して分割し、伸びることができます。
具体例での動作
コンテナの幅が600pxで、各アイテムに設定した基本の幅が100pxだと仮定します。
Flexコンテナ全体の余白: 600px(コンテナの幅) - 200px(アイテムの合計基本幅) = 400pxの余白
flex-growの比率に従って、アイテム1がこの余白の1/4(100px)、アイテム2が3/4(300px)を占めます。
flex-basis
flex-basisは、Flexboxレイアウトにおいて、各Flexアイテムの初期の基準サイズを指定するプロパティです。この値は、flex-growやflex-shrinkの前に適用され、Flexアイテムが配置される際の基本的なサイズを決定します。
flex-basisは、アイテムがどのくらいのサイズで開始されるべきかを指定します。widthやheightと似ていますが、flex-basisはFlexboxコンテナ内の主軸におけるサイズのみを制御します。
flex-basisとwidth/heightの違い:
widthやheightは通常のCSSレイアウトにおけるサイズ指定。
flex-basisは、Flexboxコンテナ内でのレイアウト時に適用される基準サイズを指定し、これを基にして他のFlexboxプロパティ(flex-growやflex-shrink)が動作します。
emとrem
em:
略語: "em" は元々活字印刷で使われていた単位 "em square" に由来します。これは文字の幅を表す単位でした。
現代のウェブデザインでは、親要素のフォントサイズを基準とした相対的な単位として使用されます。
rem:
略語: "root em" の略です。
ルート要素(通常は<html>要素)のフォントサイズを基準とした相対的な単位です。
主な違い:
参照する要素:
em: 直接の親要素のフォントサイズを参照します。
rem: ルート要素(<html>)のフォントサイズを参照します。
計算方法:
em: 親要素のフォントサイズに対して相対的に計算されます。例えば、親要素が16pxで1.5emと指定すると、実際のサイズは24px(16px * 1.5)になります。
rem: ルート要素のフォントサイズに対して相対的に計算されます。例えば、ルート要素が16pxで1.5remと指定すると、常に24pxになります。
一貫性:
em: ネストされた要素で使用すると、計算が複雑になる可能性があります。親要素のサイズが変わると、子要素のサイズも連鎖的に変化します。
rem: ページ全体で一貫したサイズ設定が可能です。ルート要素のサイズだけを変更することで、全体のスケールを簡単に調整できます。
使用場面:
em: コンポーネント内部での相対的なサイジングに適しています。
rem: ページ全体の一貫したレイアウトやタイポグラフィの設定に適しています。
**:nth-child と :nth-of-type **
:nth-child(n)
親要素内のすべての子要素を対象とします。
n番目の子要素が指定したセレクタと一致する場合にのみスタイルが適用されます。
順序は要素の種類に関係なく、単純に出現順で数えます。
:nth-of-type(n)
親要素内の特定の種類の要素のみを対象とします。
指定した要素タイプのn番目の要素にスタイルが適用されます。
同じタイプの要素間でのみ順序を数えます。
Pseudo-element
CSS疑似要素は、既存のHTML要素の特定の部分やある状況下での要素の外観をスタイリングするための特別なセレクタです。これにより、マークアップを変更せずに要素に装飾を加えたり、仮想的な要素を追加したりすることができます。
主な特徴:
記法: ダブルコロン(::)を使用して記述します。例: p::first-line
(互換性のため、シングルコロン(:)も多くのブラウザでサポートされていますが、新しいコードではダブルコロンを使用することが推奨されています)
要素の一部分のスタイリング: 要素の特定の部分(最初の行、最初の文字など)にスタイルを適用できます。
仮想的な要素の追加: ::before や ::after を使用して、要素の前後に内容を追加できます
Responsive Web Design
様々な画面サイズやデバイスに対して最適な表示を行うウェブデザインの手法です。デバイスの種類や画面サイズに応じて、ウェブサイトのレイアウトやデザインが自動的に調整される仕組みを指します。
実装の考慮点:
モバイルファースト:
モバイルデバイス向けのデザインを基本とし、より大きな画面サイズに対応していく方法です。
コンテンツの優先順位付け:
画面サイズに応じて、重要なコンテンツを優先的に表示します。
パフォーマンス最適化:
画像の最適化やリソースの効率的な読み込みを考慮します。
タッチインターフェース:
モバイルデバイスでのタッチ操作に配慮したデザインを心がけます。
BEM
BEMは、CSSクラス名を構造化するための命名規則であり、コンポーネントベースのアプローチを採用しています。この方法は、大規模なプロジェクトでのCSS管理を容易にし、コードの可読性と再利用性を高めることを目的としています。
BEMの構成要素:
Block(ブロック):
独立して存在可能な、それ自体で意味を持つコンポーネントです。
例:header, menu, search-form
Element(要素):
Blockの一部であり、それ単独では使用できない部分です。
Blockに属する小さな構成要素を表します。
例:menu__item, search-form__input
Modifier(修飾子):
BlockやElementの外観や状態、振る舞いを変更します。
例:menu--hidden, search-form__input--disabled
命名規則:
Block:.block
Element:.block__element
Modifier:.block--modifier または .block__element--modifier
衝突を気にしなくて良い環境で CSS を書いているので BEM (Block/Element/Modifier) で言うところの Element あたりはあまり気にならなくなりましたが、Modifier の扱いに関しては引き続き現役というか、むしろコンポーネントの Props などでより意識をする機会が多くなったように感じます。
Modifierは3パターン
モディファイアは概ね3つのパターンに分けられます。
見た目 - どんなサイズか?どの色か?どのテーマに属するか?
例: small(小さい)、caution(警告)
状態 - 他のBlockまたはElementと比べて何が違うか?
例: disable(使用不可)、active(アクティブな状態)
振る舞い - それがどのように振る舞うか(動作するか)?
例: bottom-right(右下に位置する)
DOMとは
DOM(Document Object Model) は、ウェブページの構造をプログラムから操作可能なオブジェクトの階層構造として表現したものです。具体的には、HTMLやXMLドキュメントをツリー構造のオブジェクトとしてモデル化し、JavaScriptなどのプログラミング言語からアクセス・操作できるようにします。
主な特徴
ツリー構造(階層構造):
DOMはドキュメントをツリー状に表現します。最上位には「ドキュメントノード(Document)」があり、その下に「要素ノード(Element)」、「テキストノード(Text)」などが階層的に配置されます。
オブジェクト指向:
各ノードはオブジェクトとして扱われ、プロパティやメソッドを持ちます。これにより、プログラムからドキュメントの内容や構造を動的に変更できます。
プラットフォーム・言語非依存:
DOM自体は仕様であり、特定のプログラミング言語やプラットフォームに依存しません。主にJavaScriptと組み合わせて使用されますが、他の言語からもアクセス可能です。
var, let, const
var:
関数スコープ
再代入・再宣言可能
ホイスティングされ、undefinedで初期化
let:
ブロックスコープ
再代入可能、再宣言不可
ホイスティングされるが、初期化前のアクセスはエラー
const:
ブロックスコープ
再代入不可、再宣言不可
ホイスティングされるが、初期化前のアクセスはエラー
オブジェクトや配列のプロパティ・要素は変更可能
varのトップレベル宣言によるグローバルスコープの問題
ES6以前では、varをトップレベルで宣言すると、その変数がグローバルオブジェクト(ブラウザ環境ではwindowオブジェクト)に追加されます。これにより、以下のような問題が発生します。
名前の衝突: 異なるスクリプト間で同じ名前の変数をvarで宣言すると、後から宣言された変数が前の変数を上書きする可能性があります。
グローバル名前空間の汚染: 多数のグローバル変数が存在すると、コードの可読性が低下し、管理が難しくなります。
予期しない副作用: グローバル変数はどこからでも変更可能なため、予期しない箇所で変数が変更され、バグの原因となります。
ES6以降の改善点
ES6で導入されたletとconstはブロックスコープを持ち、トップレベルで宣言してもグローバルオブジェクトに変数が追加されません。これにより、上述の問題を効果的に回避できます。
"use strict"/strict mode
"use strict"; は、JavaScriptにおける**厳格モード(Strict Mode)**を有効にするためのディレクティブ(指示文)です。
厳格モードは、JavaScriptの実行をより厳密に制御し、エラーの検出を強化するモードです。ECMAScript 5(ES5)で導入され、従来のJavaScriptの曖昧な部分や非推奨の機能を排除することを目的としています。
プロトタイプチェーン
プロトタイプチェーン(Prototype Chain)は、JavaScriptにおけるオブジェクトの継承メカニズムを実現するための仕組みです。
これは、オブジェクト同士が連鎖的に結びつき、プロパティやメソッドを共有・継承することを可能にします。
JavaScriptでは、すべてのオブジェクトは他のオブジェクトを参照する内部プロパティ(通常は [[Prototype]] と呼ばれる)を持っています。この参照先のオブジェクトを「プロトタイプ」と呼びます。プロトタイプは、オブジェクトが持つプロパティやメソッドを継承する元となります。
各オブジェクトは、自身のプロトタイプオブジェクトを参照し、そのプロトタイプオブジェクトもさらに別のプロトタイプを持つ、という形で連鎖が形成されます。最終的に、プロトタイプが null を指すオブジェクト(通常は Object.prototype)に到達するまで、このチェーンは続きます。
// オブジェクトCを作成
const objC = {
greet: function() {
console.log("こんにちは、オブジェクトCです。");
}
};
// オブジェクトBを作成し、objCをプロトタイプに設定
const objB = Object.create(objC);
objB.sayHello = function() {
console.log("オブジェクトBからこんにちは!");
};
// オブジェクトAを作成し、objBをプロトタイプに設定
const objA = Object.create(objB);
objA.introduce = function() {
console.log("オブジェクトAです。");
};
// プロトタイプチェーンの確認
console.log(Object.getPrototypeOf(objA) === objB); // true
console.log(Object.getPrototypeOf(objB) === objC); // true
console.log(Object.getPrototypeOf(objC) === Object.prototype); // true
console.log(Object.getPrototypeOf(Object.prototype) === null); // true
// メソッドの呼び出し
objA.introduce(); // "オブジェクトAです。"
objA.sayHello(); // "オブジェクトBからこんにちは!"
objA.greet(); // "こんにちは、オブジェクトCです。"
objA.toString(); // Object.prototypeのtoStringメソッドが呼ばれる
JavaScriptでは、コンストラクタ関数を用いてオブジェクトを生成し、そのプロトタイプを設定することでプロトタイプチェーンを構築します。
// コンストラクタ関数Personを定義
function Person(name) {
this.name = name;
}
// Personのプロトタイプにgreetメソッドを追加
Person.prototype.greet = function() {
console.log(`こんにちは、${this.name}です。`);
};
// Personを基に新しいオブジェクトを作成
const alice = new Person("アリス");
const bob = new Person("ボブ");
// メソッドの呼び出し
alice.greet(); // "こんにちは、アリスです。"
bob.greet(); // "こんにちは、ボブです。"
ES6(ECMAScript 2015)では、クラス構文が導入され、プロトタイプベースの継承をより直感的に記述できるようになりました。しかし、背後では依然としてプロトタイプチェーンが使用されています。
// クラスPersonを定義
class Person {
constructor(name) {
this.name = name;
}
greet() {
console.log(`こんにちは、${this.name}です。`);
}
}
// クラスStudentを定義し、Personを継承
class Student extends Person {
constructor(name, studentId) {
super(name);
this.studentId = studentId;
}
showId() {
console.log(`学生ID: ${this.studentId}`);
}
}
// オブジェクトの生成
const charlie = new Student("チャーリー", "S12345");
// メソッドの呼び出し
charlie.greet(); // "こんにちは、チャーリーです。"
charlie.showId(); // "学生ID: S12345"
この例では、Student クラスが Person クラスを継承しています。Student のインスタンス charlie は、greet メソッドを Person クラスから継承し、showId メソッドを自身で持っています。これはプロトタイプチェーンを通じて実現されています。
- プロトタイプチェーンのメリットとデメリット
メリット
メモリ効率の向上:
同じメソッドを各オブジェクトに個別に持たせるのではなく、プロトタイプに共有することでメモリ使用量を削減できます。
コードの再利用性:
プロトタイプにメソッドやプロパティを定義することで、複数のオブジェクト間で共通の機能を共有できます。
動的な継承:
プロトタイプを動的に変更することで、既存のオブジェクトにも新しい機能を追加できます。
デメリット
予期しない副作用:
プロトタイプを変更すると、それを継承しているすべてのオブジェクトに影響を与えるため、意図しない動作を引き起こす可能性があります。
パフォーマンスの問題:
深いプロトタイプチェーンでは、プロパティやメソッドの検索に時間がかかることがあります。
理解の難しさ:
プロトタイプチェーンの動作原理を正しく理解していないと、バグの原因となることがあります。
DOMとは、Document Object Modelの略で、 HTML(またXML)をツリー状のデータ構造として、JavaScriptなど外部プログラムから操作する方法を定義したインターフェイス(API) になります
クリティカルレンダリングパス
クリティカルレンダリングパス(Critical Rendering Path)とは、ブラウザがHTML、CSS、JavaScriptを処理し、最終的に画面にピクセルとして表示するための一連のステップです。このパスを最適化することで、ページの初期表示速度が大幅に向上します。
HTML を解析して、DOM を構築する
CSS を解析して、ページのスタイルを定義する CSSOM を構築する
JavaScript がページの DOM や CSSOM を変更するとき、ブラウザはそれを適用する
DOM と CSSOM を組み合わせて、表示する要素とスタイルを持つレンダリングツリーを構築する
各要素がどこに適合するかを決定するために、ページにスタイルとレイアウトの操作を適用する
要素の各ピクセルをメモリ上に描画する
重なり合うピクセルがあるとき、ブラウザはこれらのピクセルを合成する
結果として得られるピクセルを画面に描画する
リティカルレンダリングパスの最適化方法
クリティカルリソースの数を減らす:
重要でないリソースの遅延:JavaScriptやスタイルシートの中で、ページの初期表示に不要なものは読み込みを遅延させることができます。これにより、クリティカルなリソースが優先的に読み込まれます。
非同期読み込み:JavaScriptファイルはdeferまたはasync属性を使用して、レンダリングをブロックしないようにします。
クリティカルパスの長さを短縮:
優先度の高いリソースを先にロード:重要なCSSやJavaScriptをHTMLのヘッダーで指定し、できるだけ早くロードされるようにします。
リソースの読み込みを最適化:リソースをCDNから提供する、キャッシュを活用するなど、リソースのロードを高速化します。
クリティカルバイトの最小化:
ファイルの圧縮と最適化:HTML、CSS、JavaScriptファイルを圧縮し、ファイルサイズを小さくします。例えば、GzipやBrotliなどの圧縮技術を使用できます。
不要なリソースを排除:使用されていないCSSやJavaScriptを削除することで、転送バイト数を減らし、ページの読み込み時間を短縮します。
Core Web Vitalsの3つの主要な指標
LCP(Largest Contentful Paint):
説明:ページが読み込まれてから、最大のコンテンツ(画像やテキストなど)が表示されるまでの時間を測定します。LCPはユーザーが「ページがほぼ読み込まれた」と感じるタイミングを示します。
理想的な値:2.5秒以内が良好とされています。
改善方法:
画像や動画の遅延読み込み(lazy loading)の実装。
CSSやJavaScriptの最適化、不要なリソースの削除。
高速なサーバーレスポンス時間の確保。
FID(First Input Delay):
説明:ユーザーが初めてページに対して操作を行った時(クリック、タップなど)、その操作がブラウザによって実際に反応されるまでの時間を測定します。これにより、ページの初期インタラクティブ性を評価できます。
理想的な値:100ミリ秒以内が良好です。
改善方法:
JavaScriptの実行時間を短縮。
サードパーティスクリプトの最適化。
メインスレッドのブロッキングを減らす。
CLS(Cumulative Layout Shift):
説明:ページが読み込まれている最中に、レイアウトが意図せずにずれる量を測定します。CLSが高いと、ユーザーが読んでいるコンテンツやボタンが突然移動することがあり、これが視覚的な不安定性を生み出します。
理想的な値:0.1以下が良好です。
改善方法:
画像や広告、埋め込み要素に明示的なサイズを指定。
動的コンテンツの読み込み後にレイアウトがシフトしないように工夫する。
フォントの遅延読み込みによるジャンプを防止。
FIDに代わる指標:INP(Interaction to Next Paint)
**INP(Interaction to Next Paint)**は、FIDをさらに進化させた指標です。FIDは「初回の操作遅延」にフォーカスしていましたが、INPはより包括的に「全体的なインタラクションの遅延」を測定します。つまり、ページが完全にインタラクティブであるかどうかを、ユーザーが複数回の操作を行う状況において評価します。
改善方法:
JavaScriptの最適化と非同期処理の実装。
メインスレッドの負荷を減らすため、Web Workersやリソースの遅延読み込みを活用。
RAILモデル
、Webアプリケーションのパフォーマンスをユーザー中心に評価するためのモデルで、Googleが提唱しています。このモデルは、ユーザーがアプリケーションを操作する際の体験を最適化することを目的としており、各アクションに対して明確なパフォーマンス目標を設定します。RAILは、Response(応答)、Animation(アニメーション)、Idle(アイドル)、Load(読み込み)の頭文字を取ったもので、これらの要素に分けてWebのパフォーマンスを管理します。
RAILモデルの4つの要素
Response(応答):
説明:ユーザーの操作(タップ、クリック、スクロールなど)に対する応答速度を指します。ユーザーが操作した瞬間にブラウザが反応し、フィードバックを提供することで、スムーズな操作感を提供します。
目標:ユーザーのアクションに100ミリ秒以内に反応することを目指します。100ミリ秒を超えると、ユーザーは遅延を感じやすくなります。
Animation(アニメーション):
説明:スクロールやドラッグ、その他のアニメーション(ページ遷移、リッチメディアなど)をスムーズに実行するためのパフォーマンスです。ここでの目標は、アニメーションが視覚的に滑らかであることです。
目標:アニメーションは60FPS(フレーム毎秒)で動作することを目指します。つまり、16ミリ秒ごとに1フレームを描画する必要があります。これにより、ユーザーはスムーズなアニメーションを体感できます。
Idle(アイドル):
説明:ユーザーがアクションをしていない「アイドル」状態で、アプリケーションがバックグラウンドでタスクを処理する時間です。この時間を活用して、非緊急の作業を処理し、次のユーザーアクションに備えます。
目標:アイドル状態の間、ユーザーが再び操作を開始した際には100ミリ秒以内に反応できるように、余分なタスクを小分けにして行うことが推奨されます。
Load(読み込み):
説明:ページが最初に読み込まれる際のパフォーマンスを指します。ユーザーがページを開いた瞬間から、コンテンツが表示されて操作できるまでの時間を最適化することが重要です。
目標:1秒以内に主要コンテンツを表示し、5秒以内にインタラクションが可能な状態にすることが理想です。特にモバイルデバイスでは、これが重要な指標となります。
リアルユーザモニタリング(RUM) vs 合成モニタリング
リアルユーザーモニタリングは、その名の通り、ウェブサイトやウェブアプリケーションと実際のユーザーのインタラクションを測定します。これは一般的にパッシブ(受動的)・フロントエンド・モニタリングとも呼ばれています。このソリューションは、メトリクスを収集するために実際のユーザーのトラフィックを使います。
一般的に、リアルユーザーのモニタリングは、サイト所有者がアプリケーションに関して意思決定を行う際に、様々な時間軸において効果を発揮します。
短期的な意思決定の例:
- 最近のデプロイの影響で、パフォーマンスに問題が起こっている?
- どのJSエラーを優先して修正すべき?
- ブラウザやデバイスやアクセス回線が、ウェブサイトのパフォーマンスを悪化させる原因になっていないか?
長期的な意思決定の例:
- 商品の購入につなげるためには、どの程度ページレンダリングの速度があればよいのか?
- 離脱を減らすためのページデザインとは?
- エンドユーザー体験のための組織「センターオブエクセレンス」を設立すべき?
RUMと比較して、合成モニタリングは「アクティブ(積極的)・モニタリング」とも呼ばれています。総合的なモニタリングは、顧客が気づく前にサイトの問題をプロアクティブに特定し、解決するのが理想です。合成モニタリングは、ユーザーのアクティビティをシミュレートし、シミュレートされたインタラクションの結果を追跡・分析することで、フロントエンドのパフォーマンスを測定します。
webアプリのページのレンダーのパフォーマンス改善
Webアプリケーションのページ表示速度やUIの操作が遅い場合、以下のようなステップでパフォーマンス改善を図ることが有効です。これらは、ユーザー体験を向上させ、Webアプリケーションの効率的な動作を保証するための具体的な手法です。
1. パフォーマンスの分析
- Google Lighthouse や Chrome DevTools、WebPageTest などのツールを使用して、アプリケーションのボトルネックを特定します。
- Chrome DevToolsでネットワークの速度やCPUをエミュレートして、遅い状況下での動作を確認し、改善点を洗い出します。
2. 画像の最適化
- 画像ファイルは大きなデータ転送の一因です。WebP や AVIF 形式に変換し、圧縮してサイズを削減します。
- 遅延ロード(Lazy Loading) を実装し、スクロールして表示されるまではオフスクリーンの画像をロードしないようにします。
3. アセットの最小化・圧縮
- HTML、CSS、JavaScriptのファイルをミニファイ(不要なスペースやコメントの削除)してサイズを小さくします。
- GZIP または Brotli 圧縮をサーバーで有効化して、転送データ量を減らします。
4. JavaScriptの最適化
- Tree Shaking を使用して未使用のJavaScriptコードを削除し、ファイルサイズを縮小します。
- クリティカルでないJavaScriptを遅延ロードし、大きなファイルは動的インポートなどを活用して分割します。
5. CSSの最適化
- 未使用のCSSを削除し、最小限のスタイルだけを含むようにします。
- クリティカルCSS はHTMLの中にインラインで埋め込み、初期レンダリングを高速化します。
6. HTTP/2の導入
- HTTP/2 は1つのTCPコネクションで複数のリクエストを並列に処理できるため、パフォーマンスが向上します。ヘッダー圧縮も行われるため、通信のオーバーヘッドが軽減されます。
7. ブラウザキャッシングの活用
- 静的アセットにキャッシュヘッダーを設定し、次回以降のロード時間を短縮します。
- Service Worker を使用して、オフラインでの利用やキャッシュ戦略を高度に制御します。
8. CDN(Content Delivery Network)の活用
- CDNを利用して、ユーザーの地理的な位置に最も近いサーバーからコンテンツを配信することで、待ち時間を短縮します。
9. Resource Hintsおよび103 Early Hintsの活用
-
Resource Hints(
<link rel="preload">など)を使って、必要になる前に重要なリソースを事前に取得することで、読み込みを最適化します。 - 103 Early Hints は、レスポンスの早期段階でブラウザにリソースの取得を指示し、ロード時間を短縮します。
10. UIの簡素化
- 不要なUI要素や複雑なアニメーションを減らし、CSSアニメーション を使用することで、DOMのリフローや過度なレンダリング負荷を抑えます。
11. 仮想化またはページネーションを使用したリスト管理
- 大量のリストやテーブルを表示する場合、仮想化(必要な部分だけをレンダリングする技術)を実装し、ブラウザのメモリやレンダリング負荷を軽減します。また、必要に応じてページネーションを実装し、一度に表示するデータ量を制限します。
これらの対策を順次実行することで、Webアプリケーションのパフォーマンスは大幅に向上し、ユーザーにとって快適な体験を提供できるようになります。最も効果的な手法はアプリケーションの特性やボトルネックに依存するため、継続的にパフォーマンス分析ツールを使用し、最適化を進めることが重要です。
クロスサイトスクリプティング(XSS)
反射型XSS:攻撃者が送信したスクリプトが、リクエストに含まれ、レスポンスでそのまま反映される場合に発生します。たとえば、検索クエリやフォーム入力がそのままページに表示されるケースです。
格納型XSS:悪意のスクリプトがデータベースなどに保存され、複数のユーザーに対して持続的に実行される場合に発生します。たとえば、攻撃者が掲示板やコメント欄に悪意のあるスクリプトを投稿し、他のユーザーがそのページを閲覧した際にスクリプトが実行されます。
DOMベースXSS:スクリプトの操作がクライアント側で行われ、DOM(Document Object Model)を通じて悪意のあるスクリプトが挿入されるタイプのXSSです。
対策:
- 出力エンコード
ユーザーからの入力をHTMLに出力する際、エスケープ処理を行うことで、悪意のあるスクリプトの実行を防ぎます。特にHTML内に挿入される動的なデータはそのまま信頼せず、安全な形で表示します。
JavaScript では、テキストコンテンツを設定する際に .textContent や .innerText を使用し、直接HTMLに挿入しないようにします。たとえば、以下のようにすることで安全な出力が可能です。
- HTMLサニタイズ
HTMLエンコードが難しい場合や、WYSIWYGエディタのようにHTMLコンテンツをそのまま出力する必要がある場合、サニタイズが重要です。サニタイズとは、ユーザーが入力したHTMLの中から悪意のあるタグや属性を取り除くことを指します。
OWASP(オワスプ)は、HTMLサニタイズに「DOMPurify」というライブラリを推奨しています。DOMPurifyは、入力されたHTMLコンテンツをサニタイズして、悪意のある要素を取り除きます。
**CORS(Cross-Origin Resource Sharing)**は、異なるオリジン間でリソースを共有するためのセキュリティ機構です。通常、Webブラウザは同一オリジンポリシー(SOP: Same-Origin Policy)に従い、異なるオリジン間でのリソース共有を制限しています。CORSは、この制限を緩和し、安全に異なるオリジン間でリソースを共有できるようにする仕組みです。
オリジンとは?
オリジンとは、URLのプロトコル(HTTP/HTTPS)、ドメイン名、ポート番号の3つの組み合わせで定義されます。例えば、以下の2つのURLはオリジンが異なります:
-
https://example.com:443(HTTPSのデフォルトポート) -
http://example.com:80(HTTPのデフォルトポート)
ブラウザは、オリジンが異なる場合、JavaScriptなどを通じてリソースを取得することを通常許可しませんが、CORSが適切に設定されていれば、異なるオリジンからのリクエストが許可されます。
CORSの動作の仕組み
クライアント(ブラウザ)がサーバーにリクエストを送信したとき、サーバーがCORSを許可するかどうかを判断します。許可されると、ブラウザがそのリクエストを続行します。具体的には、以下のHTTPヘッダーをサーバーが返すことでCORSを設定します。
-
Access-Control-Allow-Origin:
- このヘッダーは、どのオリジンからのリクエストが許可されるかを指定します。
- 例:
Access-Control-Allow-Origin: https://example.com - 全てのオリジンを許可する場合は、ワイルドカード
*を使用します。 - 例:
Access-Control-Allow-Origin: *
-
Access-Control-Allow-Methods:
- このヘッダーは、サーバーが許可するHTTPメソッド(GET, POST, PUT, DELETEなど)を指定します。
- 例:
Access-Control-Allow-Methods: GET, POST, PUT
-
Access-Control-Allow-Headers:
- クライアントが送信できるカスタムHTTPヘッダーを指定します。
- 例:
Access-Control-Allow-Headers: Content-Type, Authorization
-
Access-Control-Allow-Credentials:
- クレデンシャル(Cookieや認証情報)を含むリクエストを許可するかどうかを指定します。
- 例:
Access-Control-Allow-Credentials: true
-
Access-Control-Max-Age:
- プリフライトリクエスト(後述)の結果をブラウザにキャッシュする期間(秒)を指定します。
- 例:
Access-Control-Max-Age: 600(10分)
プリフライトリクエスト(Preflight Request)
特定のHTTPメソッド(POST, PUT, DELETEなど)やカスタムヘッダーを使用する際、ブラウザはサーバーに対して「このリクエストを送っても大丈夫か?」という確認のために、OPTIONSメソッドを使った「プリフライトリクエスト」を先に送信します。サーバーがこれに対して許可を返すと、ブラウザは実際のリクエストを送信します。
CORS対策の設定方法
サーバー側でCORSを有効にするために、必要なヘッダーを適切に設定する必要があります。以下に、CORSの設定例を示します。
例:Node.js(Expressフレームワーク)でのCORS設定
const express = require('express');
const cors = require('cors');
const app = express();
// 特定のオリジンだけを許可する場合
app.use(cors({ origin: 'https://example.com' }));
// 全てのオリジンを許可する場合
app.use(cors());
app.get('/data', (req, res) => {
res.json({ message: 'CORSが有効です' });
});
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
例:ApacheでのCORS設定
httpd.conf または .htaccess ファイルでCORSヘッダーを設定します。
<IfModule mod_headers.c>
Header set Access-Control-Allow-Origin "https://example.com"
Header set Access-Control-Allow-Methods "GET, POST, PUT"
Header set Access-Control-Allow-Headers "Content-Type"
</IfModule>
まとめ
CORSは、Webセキュリティの重要な要素であり、異なるオリジン間で安全にリソースを共有するための仕組みです。サーバー側で適切なHTTPヘッダーを設定することで、特定のオリジンからのリクエストを許可し、ブラウザの同一オリジンポリシーによる制限を安全に緩和できます。また、CORS設定をミスすると、リソースが期待通りに共有できなくなることがあるため、ヘッダーの設定は慎重に行う必要があります。
JavaScriptにおける == 演算子と === 演算子
==(等価)演算子
型変換を行う: == 演算子は比較する前にオペランドの型を自動的に変換します(型強制)。
値の比較: 型変換後に値を比較します。
===(厳密等価)演算子
型変換を行わない: === 演算子はオペランドの型を変換せず、そのまま比較します。
型と値の両方を比較: データ型と値の両方が同じ場合にのみ true を返します。
JavaScriptにおけるプリミティブ型とオブジェクト型
プリミティブ型(Primitive Types):
特徴
イミュータブル(不変):
一度作成されたプリミティブ型の値は変更できません。
例えば、文字列や数値を操作すると新しい値が生成されます。
値そのものを格納:
変数には値そのものが直接格納されます。
メモリ上で直接値が保持されるため、操作が高速です。
主なプリミティブ型
文字列(String)
数値(Number)
真偽値(Boolean)
null
undefined
シンボル(Symbol)
ビッグイント(BigInt)
特徴
ミュータブル(可変):
オブジェクトのプロパティは後から変更可能です。
新しいプロパティの追加や既存プロパティの変更が可能です。
参照を格納:
変数にはオブジェクト自体ではなく、その**参照(メモリアドレス)**が格納されます。
複数の変数が同じオブジェクトを参照することができます。
主なオブジェクト型
オブジェクト(Object)
配列(Array)
関数(Function)
日付(Date)
その他の組み込みオブジェクト
第一級関数(First-class Function)
プログラミング言語において関数が他のデータ型と同様に扱われる特性を指します。具体的には、関数を以下のように自由に操作できることを意味します:
変数に代入できる
他の関数の引数として渡せる
他の関数から返すことができる
データ構造(配列やオブジェクト)に格納できる
高階関数の活用
高階関数は、他の関数を引数に取ったり、関数を返したりする関数です。第一級関数の特性を活かして、さまざまな操作を抽象化できます。
カリー化(Currying)
カリー化とは、複数の引数を取る関数を、単一の引数を取る複数の関数に順次変換する手法です。これにより、関数の再利用性や柔軟性が向上します。
カリー化の利点
再利用性の向上: カリー化により、特定の引数を事前に固定した関数を作成できるため、コードの再利用性が高まります。
関数の組み合わせが容易に: 小さな関数を組み合わせて複雑な処理を構築することが容易になります。これにより、コードの可読性と保守性が向上します。
遅延評価の実現: 必要な引数が揃った時点で計算を実行するため、効率的な処理が可能になります。
純粋関数(Pure Function)
純粋関数は、以下の2つの特性を持つ関数です:
副作用がない(No Side Effects):
関数の実行が外部の状態やデータに影響を与えないこと。
グローバル変数の変更、I/O操作(例:コンソールへの出力、ファイルの読み書き)、データベースの更新などを行わない。
入力に対して常に同じ出力を返す(Deterministic):
同じ引数を与えられた場合、常に同じ結果を返すこと。
内部で乱数を生成したり、現在の日時を取得したりしない。
クロージャ(Closures)
クロージャとは、関数とその関数が定義されたスコープ(環境)との組み合わせのことを指します。具体的には、ある関数が他の関数の内部で定義され、その内部関数が外部関数の変数にアクセスできる状態を指します。
undefined/null
意味: 変数が宣言されたが、まだ値が割り当てられていない状態を示します。また、関数が何も返さなかった場合やオブジェクトのプロパティが存在しない場合にも undefined になります。
発生の仕方: 自然に発生します。たとえば、変数が宣言されたが値が代入されていない場合に自動的に undefined が設定されます。
意味: 値が存在しないことを意図的に示すために使用します。つまり、開発者が「ここには何もない」ということを明示するために null を代入します。
発生の仕方: null は自然には発生せず、開発者が手動で設定します。
NaN
"Not-a-Number" の略で、数値として解釈できない演算結果を表す特殊な値です。NaN はグローバルオブジェクトのプロパティとして存在。
NaN の主な特徴:
意味: 数値の演算結果が数値ではない場合に返されます。例えば、文字列を数値に変換できない場合や、不正な数学的演算(0除算以外の無効な演算)などが行われたときに発生します。
NaN は JavaScript では特殊な値で、どんな値とも等しくならないという特徴があります。驚くべきことに、NaN 自身とも等しくありません。
伝播の停止
イベントハンドラは、イベントオブジェクトを唯一の引数として受け取ります。慣習的に、それは “event” を意味する e と呼ばれています。このオブジェクトを使用して、イベントに関する情報を読み取ることができます。
このイベントオブジェクトを使い、伝播を止めることもできます。イベントが親コンポーネントに伝わらないようにしたい場合、以下の Button コンポーネントのようにして e.stopPropagation() を呼び出す必要があります:
デフォルト動作を防ぐ
ブラウザのイベントには、デフォルトの動作が関連付けられているものがあります。例えば、<form> の submit イベントは、その中のボタンがクリックされると、デフォルトではページ全体がリロードされます。
イベントバブリングの詳細
**イベントバブリング(Event Bubbling)**は、DOMツリーにおけるイベントの伝播(Propagation)の一つの方式です。イベントが発生した際、そのイベントは最も内側の要素(ターゲット)から始まり、親要素へと順次伝播していきます。
イベントの伝播フェーズ
イベントの伝播には主に3つのフェーズがあります:
-
キャプチャリングフェーズ(Capturing Phase):
- イベントがドキュメントのルート(例えば
<html>)からターゲット要素に向かって伝播します。 - キャプチャリングフェーズでは、
addEventListenerメソッドの第三引数にtrueを指定することで、キャプチャリング時にイベントハンドラを実行できます。
- イベントがドキュメントのルート(例えば
-
ターゲットフェーズ(Target Phase):
- イベントが実際に発生したターゲット要素でイベントハンドラが実行されます。
-
バブリングフェーズ(Bubbling Phase):
- イベントがターゲット要素から親要素へと逆方向に伝播し、各親要素で設定されたイベントハンドラが順次実行されます。
- デフォルトでは、
addEventListenerの第三引数はfalseとなっており、バブリングフェーズでイベントハンドラが実行されます。
イベント伝播の制御
イベント伝播を制御するための主なメソッドには以下があります:
-
event.stopPropagation():- イベントの伝播を停止します。これにより、現在のフェーズでのイベントハンドラの実行は継続されますが、それ以降の親要素への伝播は停止します。
-
event.stopImmediatePropagation():- 現在の要素でのイベントハンドラの実行を停止し、同一要素内の他のイベントハンドラの実行も停止します。また、伝播も停止されます。
-
event.preventDefault():- イベントのデフォルトの動作(例えば、リンクの遷移やフォームの送信)をキャンセルします。これは伝播の制御とは異なりますが、イベントハンドリングにおいてよく使用されます。
実際の例
以下に具体的な例を示します:
<!DOCTYPE html>
<html>
<head>
<title>イベントバブリングの例</title>
<script>
document.addEventListener('DOMContentLoaded', () => {
document.getElementById('form').addEventListener('click', () => {
console.log('formのクリックイベント');
});
document.getElementById('div').addEventListener('click', () => {
console.log('divのクリックイベント');
});
document.getElementById('p').addEventListener('click', (event) => {
console.log('pのクリックイベント');
// イベントの伝播を停止
// event.stopPropagation();
});
});
</script>
</head>
<body>
<form id="form">
<div id="div">
<p id="p">クリックしてください</p>
</div>
</form>
</body>
</html>
この例では、<p> 要素をクリックすると、以下の順番でコンソールにメッセージが表示されます:
pのクリックイベントdivのクリックイベントformのクリックイベント
もし p のイベントハンドラ内で event.stopPropagation() を呼び出すと、div や form のイベントハンドラは実行されなくなります。
まとめ
イベントバブリングは、DOMツリー内でのイベントの伝播を理解する上で非常に重要な概念です。これを適切に活用することで、効率的なイベントハンドリングや意図しない動作の防止が可能になります。また、キャプチャリングフェーズとの組み合わせにより、より細かいイベント制御が可能となります。
.call() と .apply() の基本的な違い
.call()
構文: function.call(thisArg, arg1, arg2, ...)
引数の渡し方: カンマ区切りで個別の引数を渡します。
.apply()
構文: function.apply(thisArg, [argsArray])
引数の渡し方: 第二引数として引数の配列または配列風オブジェクトを渡します。
共通点:
両方とも関数の this を指定して呼び出すことができます。
主な違い:
.call() は引数を個別に渡すのに対し、.apply() は引数を配列として渡します。
使用シーン:
引数が動的で配列として存在する場合は .apply()。
引数が固定されている、または個別に渡したい場合は .call()。
thisキーワード
JavaScriptでは、thisキーワードはオブジェクトの事を指す。
どのオブジェクトを指すかは、thisがどのように呼び出されるかに依存。
- オブジェクトメソッド: obj.method() では、オブジェクト obj のこと
- グローバルコンテキスト: グローバルオブジェクトを指します。ブラウザ上では window
- 関数コンテキスト: グローバルオブジェクトがデフォルトでバインディングされます。ブラウザ上では windowを指します。なお、Strictモードでは undefinedとなります。
- イベンドハンドラの中: イベントを受け取った HTML 要素(HTMLElement)を指します。
- apply, call, bind : 関数(例えばfunc.call(obj))を呼ぶと、引数として渡されるオブジェクト obj
アロー関数は、以下のようなさまざまなユースケースで非常に有用です:
短くシンプルな関数の記述: コードの可読性を向上させる。
コールバック関数や高階関数での使用: ネストを浅くし、簡潔な記述を可能にする。
thisのレキシカルバインディング: オブジェクト内やクラス内でのメソッド定義でthisの参照を簡単に管理。
イベントハンドラ内での使用: DOM要素のイベント処理でthisを正しく参照。
即時実行関数(IIFE)の簡潔な記述: アロー関数で即時実行関数を簡単に定義。
Promiseチェーンや非同期処理での使用: コールバック関数を簡潔に記述し、可読性を向上。
高階関数や関数合成: 関数型プログラミングスタイルでの使用に適している。
bindが不要になるケース: thisのバインディングを簡素化。
デフォルト引数やパラメータ展開との併用: 柔軟な関数定義が可能。
モジュールやライブラリ内でのユーティリティ関数の定義: 明確で簡潔な関数定義が可能。
JavaScriptのイベントループについてのご説明、ありがとうございます。以下に、さらに詳しくイベントループの仕組みや動作について解説します。
JavaScriptのイベントループとは
JavaScriptはシングルスレッドで動作する言語ですが、非同期処理を効率的に扱うために「イベントループ」という仕組みを利用しています。イベントループは、以下の主要なコンポーネントと連携して動作し、非同期タスクの実行順序を管理します。
主要なコンポーネント
-
コールスタック (Call Stack)
- 役割: 実行中の関数を管理するデータ構造です。新しい関数が呼び出されるとスタックにプッシュされ、関数の実行が完了するとスタックからポップされます。
- 特徴: シングルスレッドであるため、同時に1つの関数しか実行できません。
-
ヒープ (Heap)
- 役割: オブジェクトや関数などのメモリが動的に確保される領域です。
- 特徴: コールスタックとは異なり、大きなデータや複雑なオブジェクトを格納します。ガベージコレクションによって不要なメモリが自動的に解放されます。
-
タスクキュー (Task Queue)
- 役割: 非同期処理が完了した際に、そのコールバック関数がここに追加されます。イベントループがコールスタックを監視し、空になったタイミングでタスクキューからタスクを取り出してコールスタックにプッシュします。
-
例:
setTimeout、setInterval、DOMイベントハンドラーなど。
-
マイクロタスクキュー (Microtask Queue)
-
役割: Promiseの
thenやcatch、finally、async/awaitの後続処理など、マイクロタスクがここに追加されます。 - 特徴: マイクロタスクはタスクキューよりも優先的に処理されます。イベントループはタスクキューのタスクを処理する前に、マイクロタスクキューのすべてのタスクを処理します。
-
役割: Promiseの
-
Web APIs
-
役割: ブラウザが提供する非同期API(例:DOM操作、
setTimeout、fetch、addEventListenerなど)を指します。非同期処理はこれらのAPIによって実行され、完了後にコールバックがタスクキューやマイクロタスクキューに送られます。
-
役割: ブラウザが提供する非同期API(例:DOM操作、
イベントループの動作フロー
-
コールスタックの確認
- イベントループは、コールスタックが空になるのを待ちます。コールスタックが空でない場合、スタック内の関数の実行が完了するまで待機します。
-
マイクロタスクキューの処理
- コールスタックが空になると、イベントループはマイクロタスクキューをチェックします。マイクロタスクキューにタスクが存在する場合、すべてのマイクロタスクを順番に実行します。
-
タスクキューの処理
- マイクロタスクキューが空になった後、イベントループはタスクキューから最初のタスクを取り出し、コールスタックにプッシュして実行します。
-
再びコールスタックの確認
- タスクの実行が終わったら、再度コールスタックが空か確認し、上記の手順を繰り返します。
具体的な例
以下に、イベントループの動作を示す簡単なコード例を紹介します。
console.log('Start');
setTimeout(() => {
console.log('Timeout');
}, 0);
Promise.resolve().then(() => {
console.log('Promise');
});
console.log('End');
実行順序と理由:
-
console.log('Start')がコールスタックにプッシュされ、"Start"が出力されます。 -
setTimeoutのコールバックがWeb APIsに渡され、タイマーが設定されます。このコールバックはタスクキューに追加されます。 -
Promise.resolve().then(...)のthenコールバックがマイクロタスクキューに追加されます。 -
console.log('End')が実行され、"End"が出力されます。 - コールスタックが空になると、イベントループはまずマイクロタスクキューを確認し、
thenのコールバックが実行されて"Promise"が出力されます。 - その後、タスクキューから
setTimeoutのコールバックが取り出され、"Timeout"が出力されます。
出力順序:
Start
End
Promise
Timeout
ポイントのまとめ
- シングルスレッドであること: JavaScriptは基本的にシングルスレッドで動作しますが、イベントループを利用することで非同期処理を効率的に管理できます。
-
マイクロタスクとタスクの優先順位: マイクロタスクキューはタスクキューよりも優先されるため、Promiseの
thenなどの処理が先に実行されます。 - 非同期APIの活用: Web APIsを利用することで、非同期処理を行い、その結果を適切なキューに追加することが可能です。
Symbol
一意の識別子としての利用: Symbolはユニークなプロパティキーとして使用でき、オブジェクトのプロパティ名の衝突を防ぎます。
プライベートプロパティの擬似実現: Symbolを使用することで、外部からのアクセスを難しくし、プライベートなプロパティとして扱うことができます。ただし、完全なプライバシーを保証するものではありません。
const uniqueKey = Symbol('uniqueKey');
const user = {
name: 'Alice',
[uniqueKey]: 'secretData'
};
console.log(user.name); // 'Alice'
console.log(user[uniqueKey]); // 'secretData'
// 通常の列挙ではシンボルプロパティは表示されない
for (let key in user) {
console.log(key); // 'name'のみ
}
console.log(Object.keys(user)); // ['name']
console.log(Object.getOwnPropertySymbols(user)); // [ Symbol(uniqueKey) ]
DOMContentLoaded イベントと load イベントは、ウェブページの読み込み過程における異なるタイミングで発生する重要なイベントです。これらのイベントの違いを理解することで、効率的なスクリプトの実行やユーザー体験の向上に役立てることができます。以下に、それぞれのイベントの詳細と違いについて解説します。
1. 概要
-
DOMContentLoadedイベント
HTMLドキュメントの構造(DOMツリー)が完全に構築された時点で発生します。この段階では、画像やスタイルシート、サブフレームなどのリソースはまだ完全に読み込まれていない可能性があります。 -
loadイベント
ページ全体、すなわちHTML、スタイルシート、画像、スクリプト、その他のサブリソースがすべて完全に読み込まれた時点で発生します。
2. DOMContentLoaded イベント
発生タイミング
- ブラウザがHTMLドキュメントを完全に解析し、DOMツリーを構築し終えた時点で発生します。
- 画像やスタイルシート、外部スクリプトの読み込み完了を待ちません。
特徴
- スクリプトの実行が早く開始できるため、ユーザーインターフェースの初期化やDOM操作を迅速に行いたい場合に適しています。
- 外部リソースの読み込みを待たないため、ページのインタラクティブ性を早く提供できます。
使用例
document.addEventListener('DOMContentLoaded', function() {
// DOMが構築された後に実行したい処理
const header = document.querySelector('header');
header.style.backgroundColor = 'blue';
});
3. load イベント
発生タイミング
- ページに含まれるすべてのリソース(画像、スタイルシート、サブフレームなど)が完全に読み込まれた後に発生します。
特徴
- ページ全体の読み込みが完了してから実行されるため、ページの完全な表示やリソースの依存関係がある処理に適しています。
- 画像のサイズ取得やキャンバスへの描画など、すべてのリソースが必要な場合に有用です。
使用例
window.addEventListener('load', function() {
// ページ全体が読み込まれた後に実行したい処理
const images = document.querySelectorAll('img');
images.forEach(img => {
console.log(`${img.src} の読み込みが完了しました`);
});
});
4. 主な違い
| 特徴 | DOMContentLoaded |
load |
|---|---|---|
| 発生タイミング | DOMの構築完了 | ページ全体の読み込み完了 |
| 待機するリソース | DOMに必要なリソースのみ(画像やスタイルシートは不問) | すべてのリソース |
| 主な用途 | DOM操作や初期化処理 | 画像の読み込み確認や完全なページ表示後の処理 |
5. 使用例と適用シーン
-
DOMContentLoadedを使用する場合
ページのレイアウト調整、インタラクティブな要素の初期化、フォームのバリデーション設定など、DOMが利用可能になった時点で実行したい処理。 -
loadを使用する場合
すべての画像が読み込まれてから実行したいギャラリーの表示、スライドショーの開始、外部リソースに依存するスクリプトの実行。
6. 注意点
-
非同期スクリプトの影響
<script>タグにasync属性を付与すると、スクリプトの実行タイミングが不確定になり、DOMContentLoadedイベントのタイミングに影響を与える可能性があります。スクリプトの依存関係に注意が必要です。 -
シングルページアプリケーション(SPA)での扱い
SPAではページ遷移が動的に行われるため、これらのイベントの扱い方が異なる場合があります。フレームワークのライフサイクルフックを利用することが一般的です。
7. まとめ
DOMContentLoaded イベントと load イベントは、ウェブページの読み込みプロセスにおける異なるタイミングで発生し、それぞれ異なる用途に適しています。DOM操作や初期化処理には DOMContentLoaded を、ページ全体のリソースに依存する処理には load を適切に使い分けることで、効率的なスクリプト実行と優れたユーザー体験を実現できます。
コールバックの代わりにPromiseを使用することには、多くの利点といくつかの欠点があります。以下に、それぞれの詳細を解説します。
利点
-
コールバック地獄を回避できる
-
説明: 多層にネストされたコールバック(通称「コールバック地獄」)は、コードの可読性を低下させ、保守性を悪化させます。Promiseを使用すると、
.then()や.catch()をチェーンさせることで、ネストを平坦化し、コードが整理されます。 -
例:
// コールバック地獄の例 asyncOperation1(function(result1) { asyncOperation2(result1, function(result2) { asyncOperation3(result2, function(result3) { // 処理 }); }); }); // Promiseを使用した例 asyncOperation1() .then(result1 => asyncOperation2(result1)) .then(result2 => asyncOperation3(result2)) .then(result3 => { // 処理 }) .catch(error => { // エラーハンドリング });
-
説明: 多層にネストされたコールバック(通称「コールバック地獄」)は、コードの可読性を低下させ、保守性を悪化させます。Promiseを使用すると、
-
非同期処理を読みやすい形で書ける
-
説明: Promiseは非同期処理の流れを直線的に記述できるため、理解しやすくなります。また、
async/await構文を使用することで、さらに同期的なコードスタイルに近づけることができます。 -
例:
// Promiseを使用した非同期処理 async function fetchData() { try { const response = await fetch('https://api.example.com/data'); const data = await response.json(); console.log(data); } catch (error) { console.error('エラーが発生しました:', error); } } fetchData();
-
説明: Promiseは非同期処理の流れを直線的に記述できるため、理解しやすくなります。また、
-
Promise.allにより並列な非同期処理を書ける-
説明:
Promise.allを使用すると、複数の非同期操作を並列で実行し、すべての操作が完了したときに結果を取得できます。これにより、パフォーマンスの向上が期待できます。 -
例:
const promise1 = fetch('https://api.example.com/data1').then(res => res.json()); const promise2 = fetch('https://api.example.com/data2').then(res => res.json()); Promise.all([promise1, promise2]) .then(([data1, data2]) => { console.log('データ1:', data1); console.log('データ2:', data2); }) .catch(error => { console.error('エラーが発生しました:', error); });
-
説明:
-
エラーハンドリングが容易
-
説明: Promiseでは、
.catch()メソッドを使用して一箇所でエラーをキャッチできるため、エラーハンドリングがシンプルになります。また、async/awaitと組み合わせることで、try/catchブロックを使用して直感的にエラー処理が可能です。 -
例:
async function fetchData() { try { const response = await fetch('https://api.example.com/data'); if (!response.ok) { throw new Error('ネットワークエラー'); } const data = await response.json(); console.log(data); } catch (error) { console.error('エラーが発生しました:', error); } } fetchData();
-
説明: Promiseでは、
-
状態管理が明確
- 説明: Promiseは「pending(保留)」、「fulfilled(成功)」、「rejected(失敗)」の3つの状態を持つため、非同期処理の状態を明確に管理できます。これにより、状態に応じた処理を簡単に実装できます。
-
再利用性と組み合わせやすさ
-
説明: Promiseは他のPromiseと簡単に組み合わせることができ、再利用性が高まります。例えば、
Promise.raceやPromise.anyなどのメソッドを活用することで、さまざまな非同期パターンを実現できます。
-
説明: Promiseは他のPromiseと簡単に組み合わせることができ、再利用性が高まります。例えば、
-
async/awaitとの相性が良い-
説明: PromiseベースのAPIは
async/await構文と組み合わせることで、さらに直感的で読みやすい非同期コードを書くことができます。これにより、同期的なコードスタイルに近づけることができます。
-
説明: PromiseベースのAPIは
欠点
-
ES2015をサポートしていない古いブラウザではpolyfillが必要
- 説明: PromiseはES2015(ES6)で導入された機能であるため、古いブラウザ(例えば、Internet Explorer)ではネイティブサポートされていません。そのため、Promiseを使用する場合はpolyfill(ポリフィル)を導入する必要があります。これにより、バンドルサイズが増加する可能性があります。
-
初心者にとって理解が難しい場合がある
- 説明: Promiseの概念や動作を理解するには、コールバックに比べて少し複雑に感じることがあります。特に、非同期処理のフローやエラーハンドリングの仕組みを理解するには、一定の学習が必要です。
-
ネストが完全に解消されるわけではない
- 説明: Promiseチェーンを適切に使用しないと、依然としてネストが深くなる場合があります。特に、複数の非同期操作が依存関係を持つ場合、チェーンが長くなりがちです。
-
デバッグが難しい場合がある
-
説明: Promiseチェーンでエラーが発生した場合、スタックトレースが分かりにくくなることがあります。特に、
async/awaitを使用すると、非同期の呼び出しスタックが断片化されるため、デバッグが難しくなることがあります。
-
説明: Promiseチェーンでエラーが発生した場合、スタックトレースが分かりにくくなることがあります。特に、
-
実行タイミングの制御が難しい場合がある
- 説明: Promiseは即時に実行されるため、必要に応じて非同期処理の開始を遅延させたり、キャンセルしたりするのが難しい場合があります。これに対して、コールバックは実行タイミングを柔軟に制御できます。
-
メモリ消費が増える可能性
- 説明: 大量のPromiseを生成すると、メモリ消費が増加する可能性があります。特に、長時間にわたって多くのPromiseが保持される場合、メモリリークのリスクが高まります。
-
複雑なフロー管理が必要な場合
-
説明: 非同期処理が複雑なフロー(例えば、条件分岐やループを含む場合)では、Promiseチェーンや
async/awaitを適切に管理するのが難しくなることがあります。このような場合、別の非同期制御ライブラリ(例えば、RxJS)を検討する必要があります。
-
説明: 非同期処理が複雑なフロー(例えば、条件分岐やループを含む場合)では、Promiseチェーンや
まとめ
Promiseはコールバックに比べて多くの利点を提供し、特に非同期処理の可読性やエラーハンドリングの面で優れています。しかし、古いブラウザのサポートや概念の理解の難しさ、特定の状況下でのデバッグの困難さなど、いくつかの欠点も存在します。プロジェクトの要件や対象環境に応じて、Promiseとコールバックの適切な使い分けを検討することが重要です。
また、現代のJavaScript開発では、async/awaitを活用することでPromiseの利点を最大限に活かしつつ、コードの可読性と保守性を向上させることが一般的です。適切な非同期処理の設計と実装を行うことで、より効率的で信頼性の高いアプリケーションを構築できます。
**debounce(デバウンス)とthrottle(スロットル)**は、フロントエンド開発において頻繁に発生するイベント(例えば、ユーザーの入力やスクロールイベントなど)の実行頻度を制御するためのテクニックです。これらはパフォーマンスの最適化や不要な処理の削減に役立ちますが、動作の仕組みが異なります。以下に、それぞれの詳細と違いについて解説します。
1. debounce(デバウンス)とは
debounceは、連続して発生するイベントに対して、特定の待機時間(ウェイトタイム)の間に新たなイベントが発生しなければ関数を実行する仕組みです。待機時間中にイベントが再度発生すると、タイマーがリセットされ、待機時間が再度開始されます。最終的に、イベントが一定期間発生しなくなった時点で関数が一度だけ実行されます。
特徴
- 遅延実行: イベントが止まるまで関数の実行を遅延させる。
- 最後のイベントのみ実行: 連続するイベントの中で最後のイベントに対してのみ関数が実行される。
使用例
- テキスト入力の自動補完: ユーザーが入力を完了するまでリクエストを送信しない。
- ウィンドウのリサイズイベント: リサイズが完了した後にレイアウトを再計算する。
コード例
function debounce(func, wait) {
let timeout;
return function(...args) {
const context = this;
clearTimeout(timeout);
timeout = setTimeout(() => func.apply(context, args), wait);
};
}
// 使用例: ウィンドウリサイズ時に実行
window.addEventListener('resize', debounce(() => {
console.log('ウィンドウサイズが変更されました');
}, 300));
2. throttle(スロットル)とは
throttleは、特定の時間間隔(例えば、100msや200ms)ごとに関数の実行を許可する仕組みです。指定された間隔内に複数のイベントが発生しても、最初のイベントのみ関数が実行され、それ以降のイベントは無視されます。間隔が経過すると再び関数の実行が許可されます。
特徴
- 一定間隔で実行: 指定された時間間隔ごとに関数を実行する。
- 連続的なイベント処理: スクロールやマウス移動など、連続的に発生するイベントを効率的に処理する。
使用例
- スクロールイベント: スクロール位置の監視や無限スクロールの実装。
- マウスの移動イベント: マウス位置に基づくUIの更新。
コード例
function throttle(func, limit) {
let lastFunc;
let lastRan;
return function(...args) {
const context = this;
if (!lastRan) {
func.apply(context, args);
lastRan = Date.now();
} else {
clearTimeout(lastFunc);
lastFunc = setTimeout(function() {
if ((Date.now() - lastRan) >= limit) {
func.apply(context, args);
lastRan = Date.now();
}
}, limit - (Date.now() - lastRan));
}
};
}
// 使用例: スクロール時に実行
window.addEventListener('scroll', throttle(() => {
console.log('スクロール位置を取得');
}, 200));
3. debounceとthrottleの主な違い
| 特徴 | debounce(デバウンス) | throttle(スロットル) |
|---|---|---|
| 実行タイミング | 最後のイベント発生後、指定時間が経過してから実行 | 最初のイベント発生時に即実行し、指定間隔ごとに実行 |
| イベントの扱い方 | 連続するイベントの中で最後のイベントのみ処理 | 指定間隔内で発生した複数のイベントを一定回数だけ処理 |
| 主な用途 | 入力の最適化(例:検索バーの自動補完)、ウィンドウリサイズ | スクロールイベントの処理、マウス移動イベントの監視 |
| 実行回数 | イベントが止まるまで実行されないため、1回のみ実行 | 一定間隔ごとに継続的に実行 |
4. 使い分けのポイント
debounceを使用する場合
-
ユーザーのアクションが完了した後に実行したい処理
- 例: テキスト入力の完了後に検索クエリを送信する。
-
連続するイベントの中で最後のイベントだけを処理したい場合
- 例: ウィンドウリサイズ後のレイアウト調整。
throttleを使用する場合
-
イベントが継続的に発生している間、一定間隔ごとに処理を実行したい場合
- 例: スクロール位置の定期的な取得。
-
リアルタイムでの更新が必要な場合
- 例: マウスの動きに合わせてUIを更新する。
5. 実装上の注意点
debounce
- 待機時間の設定: 適切な待機時間を設定することが重要。短すぎると効果が薄れ、長すぎるとレスポンスが遅くなる。
- キャンセル機能: 必要に応じて、待機中の関数実行をキャンセルする機能を実装する。
throttle
- 間隔の選定: 実行間隔を適切に設定し、パフォーマンスとリアルタイム性のバランスを取る。
-
コンテキストの保持: 関数内で
thisや引数を正しく保持するための工夫が必要。
6. ライブラリの活用
手動でdebounceやthrottleを実装することも可能ですが、信頼性と効率性を高めるために、以下のようなライブラリを利用することが一般的です。
-
Lodash
-
_.debounceと_.throttleの関数が提供されており、簡単に利用可能。 - Lodash Documentation
-
-
Underscore.js
- Lodashと同様にdebounceとthrottleの機能を提供。
- Underscore.js Documentation
Lodashの例
import _ from 'lodash';
// debounceの使用例
const debouncedFunction = _.debounce(() => {
console.log('デバウンス実行');
}, 300);
window.addEventListener('resize', debouncedFunction);
// throttleの使用例
const throttledFunction = _.throttle(() => {
console.log('スロットル実行');
}, 200);
window.addEventListener('scroll', throttledFunction);
7. まとめ
debounceとthrottleは、頻繁に発生するイベントの処理を効率的に制御するための強力なツールです。
-
debounceは、イベントが止まった後に一度だけ処理を実行したい場合に適しています。主に、ユーザーの入力やウィンドウのリサイズなど、連続するイベントの最後の一回のみを処理するシナリオで有効です。
-
throttleは、一定間隔ごとに処理を実行したい場合に適しています。主に、スクロールやマウスの動きなど、連続して発生するイベントを定期的に処理するシナリオで有効です。
適切な状況でこれらのテクニックを活用することで、アプリケーションのパフォーマンスを向上させ、ユーザー体験を最適化することができます。具体的な要件やイベントの特性に応じて、debounceとthrottleを使い分けることが重要です。
Cookie、sessionStorage、localStorageは、ウェブアプリケーションにおいてデータをクライアント側に保存するための主要な手段です。それぞれの特徴や用途、利点・欠点について詳しく解説します。
1. Cookie(クッキー)とは
概要
Cookieは、ユーザーのブラウザに小さなデータを保存する仕組みで、主にセッション管理、ユーザー認証、トラッキングなどに使用されます。サーバーとクライアント間でデータをやり取りする際にも利用されます。
特徴
- データサイズ: 一般的に1つのCookieあたり約4KBまで。
-
有効期限:
ExpiresまたはMax-Age属性で指定。セッションCookie(ブラウザ終了時に削除)と永続Cookie(指定した期限まで保存)がある。 - 送信方法: クライアントからサーバーへ自動的に送信される(HTTPリクエストのヘッダーに含まれる)。
- スコープ: ドメインやパスで制限可能。
利点
- サーバーとの自動連携: サーバーはクライアントから送信されるCookieを自動的に受け取れるため、セッション管理が容易。
- 広範なサポート: ほぼ全てのブラウザでサポートされている。
欠点
- セキュリティリスク: クロスサイトスクリプティング(XSS)やクロスサイトリクエストフォージェリ(CSRF)などの攻撃に対して脆弱。
- データサイズ制限: 大量のデータを保存するには不向き。
- パフォーマンスへの影響: 各リクエストごとに自動送信されるため、通信量が増加する可能性がある。
使用例
- ユーザー認証: ログインセッションの管理。
- トラッキング: ユーザーの行動追跡や分析。
コード例
// Cookieの設定
document.cookie = "username=JohnDoe; expires=Fri, 31 Dec 2024 23:59:59 GMT; path=/";
// Cookieの取得
const getCookie = (name) => {
const value = `; ${document.cookie}`;
const parts = value.split(`; ${name}=`);
if (parts.length === 2) return parts.pop().split(';').shift();
};
console.log(getCookie("username")); // "JohnDoe"
// Cookieの削除
document.cookie = "username=; expires=Thu, 01 Jan 1970 00:00:00 GMT; path=/";
2. sessionStorage(セッションストレージ)とは
概要
sessionStorageは、ブラウザのセッション単位でデータを保存するWebストレージAPIです。データはブラウザタブごとに保存され、タブを閉じると自動的に削除されます。
特徴
- データサイズ: 約5MBまで(ブラウザによって異なる)。
- 有効期限: セッション(ブラウザタブ)単位。タブを閉じるとデータは削除される。
- 送信方法: サーバーには自動的に送信されない。
- スコープ: 同一タブ内でのみアクセス可能。異なるタブやウィンドウでは共有されない。
利点
- セッション単位でのデータ管理: ユーザーのセッション中のみデータを保持する場合に適している。
- セキュリティ: サーバーに自動送信されないため、Cookieに比べてセキュリティリスクが低い。
- パフォーマンス: 自動送信されないため、通信量を増やさずにデータを保持できる。
欠点
- データの持続性: タブを閉じるとデータが消えるため、長期間のデータ保持には不向き。
- スコープの制限: 同じブラウザ内の他のタブやウィンドウからアクセスできない。
使用例
- 一時的なデータ保持: フォーム入力の一時保存や、マルチステップフォームの状態管理。
- セッション中の設定: ユーザーのセッション中にのみ必要な設定情報の保存。
コード例
// sessionStorageへのデータ保存
sessionStorage.setItem('sessionKey', 'sessionValue');
// sessionStorageからのデータ取得
const value = sessionStorage.getItem('sessionKey');
console.log(value); // "sessionValue"
// sessionStorageのデータ削除
sessionStorage.removeItem('sessionKey');
// sessionStorageの全データ削除
sessionStorage.clear();
3. localStorage(ローカルストレージ)とは
概要
localStorageもWebストレージAPIの一つで、クライアント側にデータを永続的に保存します。データはブラウザを閉じても保持され、明示的に削除するまで残ります。
特徴
- データサイズ: 約5MBまで(ブラウザによって異なる)。
- 有効期限: 無期限。ユーザーが手動で削除するか、スクリプトによって削除されるまで保持される。
- 送信方法: サーバーには自動的に送信されない。
- スコープ: 同一オリジン内の全てのタブやウィンドウで共有される。
利点
- 永続的なデータ保存: ユーザーの設定やキャッシュデータなど、長期間保持したいデータに適している。
- パフォーマンス: サーバーへのデータ送信が不要なため、クライアント側で迅速にアクセス可能。
- セキュリティ: サーバーに自動送信されないため、Cookieに比べてセキュリティリスクが低い。
欠点
- セキュリティリスク: XSS攻撃により、悪意のあるスクリプトがデータにアクセスする可能性がある。
- ストレージ容量の制限: 大量のデータを保存するには不向き。
- データの同期: 複数タブ間でデータの同期を手動で行う必要がある。
使用例
- ユーザー設定の保存: テーマ選択や言語設定など、ユーザーの好みに基づく設定情報の保存。
- キャッシュデータ: 一度取得したデータをローカルに保存し、再利用することでパフォーマンスを向上。
- オフラインデータ: オフライン時でも利用可能なデータの保存。
コード例
// localStorageへのデータ保存
localStorage.setItem('localKey', 'localValue');
// localStorageからのデータ取得
const value = localStorage.getItem('localKey');
console.log(value); // "localValue"
// localStorageのデータ削除
localStorage.removeItem('localKey');
// localStorageの全データ削除
localStorage.clear();
4. Cookie、sessionStorage、localStorageの比較
| 特徴 | Cookie | sessionStorage | localStorage |
|---|---|---|---|
| データサイズ | 約4KB/個 | 約5MB | 約5MB |
| 有効期限 | セッションまたは指定期限 | ブラウザセッション | 無期限(手動削除まで) |
| 送信方法 | サーバーに自動送信 | サーバーに送信されない | サーバーに送信されない |
| スコープ | ドメインとパスで制限 | タブ/ウィンドウ単位 | オリジン単位 |
| 用途 | セッション管理、認証、トラッキング | 一時的なデータ保存、セッション中の状態管理 | 永続的なデータ保存、ユーザー設定、キャッシュ |
| セキュリティ | XSS、CSRFのリスク | 比較的低い(サーバーに送信されない) | XSSのリスク |
| アクセス方法 | クライアントサイド(JavaScript)とサーバーサイド | クライアントサイドのみ | クライアントサイドのみ |
5. 適切な選択方法
Cookieを選ぶべき場合
- ユーザー認証情報の保持: ログインセッションの管理など、サーバーとの連携が必要な場合。
- サーバーとのデータ共有: クライアントとサーバー間でデータを自動的に共有したい場合。
- トラッキング: ユーザーの行動を追跡する必要がある場合。
sessionStorageを選ぶべき場合
- 一時的なデータの保持: ユーザーがブラウザタブを閉じるまでの間だけデータを保持したい場合。
- セッション中の状態管理: マルチステップフォームや、一時的なアプリケーション状態の管理。
localStorageを選ぶべき場合
- 永続的なデータ保存: ユーザーの設定やキャッシュデータなど、長期間保持したいデータ。
- オフラインサポート: アプリケーションがオフラインでも動作するために必要なデータの保存。
- パフォーマンス向上: サーバーへの不要なリクエストを減らすためにキャッシュデータを保存。
6. セキュリティに関する注意点
共通の注意点
-
XSS対策:
sessionStorageやlocalStorageはJavaScriptから容易にアクセスできるため、XSS攻撃によってデータが盗まれるリスクがあります。適切なコンテンツセキュリティポリシー(CSP)の設定や、入力のサニタイズを行うことが重要です。
Cookie特有の注意点
- HttpOnly属性: JavaScriptからアクセスできないようにする属性。セキュリティを強化するために重要。
- Secure属性: HTTPS接続時のみCookieを送信する属性。中間者攻撃を防ぐために有効。
-
SameSite属性: CSRF攻撃を防ぐために、Cookieの送信を制限する属性。
StrictやLaxなどの設定が可能。
セキュリティ強化のベストプラクティス
- データの暗号化: 保存するデータに敏感な情報が含まれる場合、暗号化を検討する。
- 最小限のデータ保存: 必要最低限のデータのみを保存し、不要な情報は避ける。
- 適切なアクセス制御: クライアント側でのデータアクセスを制限し、不要なスクリプトからのアクセスを防ぐ。
7. 実装上のベストプラクティス
Cookie
-
セキュアな属性の設定:
HttpOnly、Secure、SameSite属性を適切に設定する。 - データの最小化: 必要な情報のみを保存し、機密情報は避ける。
- 有効期限の設定: 必要に応じて適切な有効期限を設定する。
sessionStorage
- データのクリア: セッション終了時に不要なデータをクリアする。
- 一時的なデータ管理: フォームの一時保存や一時的なアプリケーション状態の管理に使用する。
localStorage
- データの管理: 定期的に不要なデータを削除し、ストレージの容量を管理する。
-
データの同期: 複数タブ間でデータを同期する場合、
storageイベントを活用する。 - データの圧縮: 大量のデータを保存する場合、データを圧縮してストレージ容量を節約する。
8. まとめ
| 特徴 | Cookie | sessionStorage | localStorage |
|---|---|---|---|
| データサイズ | 約4KB/個 | 約5MB | 約5MB |
| 有効期限 | セッションまたは指定期限 | セッション(タブ) | 無期限 |
| 送信方法 | サーバーに自動送信 | サーバーに送信されない | サーバーに送信されない |
| スコープ | ドメインとパス | タブ/ウィンドウ単位 | オリジン単位 |
| 用途 | セッション管理、認証、トラッキング | 一時的なデータ保存、セッション中の状態管理 | 永続的なデータ保存、ユーザー設定、キャッシュ |
| セキュリティ | XSS、CSRFリスク(適切な属性設定で軽減) | 比較的低い(サーバーに送信されない) | XSSリスク |
それぞれのストレージ機構は、用途や要件に応じて適切に選択することが重要です。セキュリティやパフォーマンスを考慮しながら、最適なデータ保存方法を選びましょう。
参考資料
**CommonJS(コモンJS)とES Modules(ESM、ECMAScript Modules)**は、JavaScriptにおけるモジュールシステムの2つの主要な規格です。これらは、コードの再利用性や保守性を向上させるためにモジュール化を可能にしますが、設計思想や使用方法においていくつかの重要な違いがあります。以下に、CommonJSとES Modulesの違いについて詳細に解説します。
1. 基本概要
CommonJS
- 登場時期: 主にNode.jsで使用されるモジュールシステムとして、2009年頃から普及。
- 目的: サーバーサイドJavaScript環境(特にNode.js)でのモジュール管理を容易にするために設計。
-
特徴: 同期的なモジュール読み込み、
require関数とmodule.exportsを使用。
ES Modules(ESM)
- 登場時期: ECMAScript 2015(ES6)で標準化され、ブラウザおよび最新のJavaScript環境でサポート。
- 目的: クライアントサイドとサーバーサイドの両方で一貫したモジュールシステムを提供。
-
特徴: 非同期的なモジュール読み込み(ブラウザ環境)、
importとexportキーワードを使用。
2. シンタックス(構文)の違い
CommonJS
モジュールのエクスポート
// math.js
const add = (a, b) => a + b;
const subtract = (a, b) => a - b;
module.exports = {
add,
subtract
};
モジュールのインポート
// app.js
const math = require('./math');
console.log(math.add(2, 3)); // 5
console.log(math.subtract(5, 2)); // 3
ES Modules(ESM)
モジュールのエクスポート
// math.mjs または math.js(package.jsonで"type": "module"を指定)
export const add = (a, b) => a + b;
export const subtract = (a, b) => a - b;
// またはデフォルトエクスポート
const multiply = (a, b) => a * b;
export default multiply;
モジュールのインポート
// app.mjs または app.js
import { add, subtract } from './math.mjs';
console.log(add(2, 3)); // 5
console.log(subtract(5, 2)); // 3
// デフォルトエクスポートのインポート
import multiply from './math.mjs';
console.log(multiply(2, 3)); // 6
3. 主な違い
モジュールの読み込みタイミング
-
CommonJS: モジュールは同期的に読み込まれます。これは主にサーバーサイド環境(Node.js)での利用に適しています。モジュールは実行時に読み込まれ、ブロッキングを引き起こす可能性があります。
const fs = require('fs'); // 同期的に読み込まれる -
ES Modules: モジュールは非同期的に読み込まれます。これはブラウザ環境でのパフォーマンス向上に寄与します。ESMはネットワークの遅延を考慮して設計されています。
import { fetchData } from './api.js'; // 非同期的に読み込まれる
デフォルトエクスポートと名前付きエクスポート
-
CommonJS: モジュールは単一のエクスポート(オブジェクトや関数)をサポート。
module.exportsを使用してエクスポートし、requireでインポートします。 -
ES Modules: デフォルトエクスポートと名前付きエクスポートの両方をサポート。
export defaultでデフォルトエクスポートを、exportで名前付きエクスポートを行います。import時に必要なものを選択的にインポート可能です。
循環依存性の取り扱い
-
CommonJS: 循環依存性がある場合、モジュールの実行順序や初期化タイミングにより未定義の値が返される可能性があります。
-
ES Modules: 静的な解析に基づいて依存関係が解決されるため、循環依存性があっても一貫した動作を提供します。ただし、循環依存性は避けるべき設計です。
ツリーシェイキングのサポート
-
CommonJS: 動的なモジュール読み込みの特性上、ツリーシェイキング(未使用のコードを削除する最適化)が難しい。
-
ES Modules: 静的な構文により、未使用のエクスポートを容易に検出し、ツリーシェイキングが可能。これにより、バンドルサイズの削減が期待できます。
ファイル拡張子の違い
-
CommonJS: 通常
.js拡張子を使用。 -
ES Modules:
.mjs拡張子を使用することが多いが、package.jsonで"type": "module"を指定することで、.jsファイルもESMとして扱うことが可能。
4. 実行環境でのサポート状況
CommonJS
-
Node.js: デフォルトのモジュールシステムとして広くサポート。
requireとmodule.exportsが使用可能。 - ブラウザ: ネイティブではサポートされていない。ブラウザで使用する場合、WebpackやBrowserifyなどのモジュールバンドラが必要。
ES Modules
-
Node.js: バージョン12以降で実験的にサポートされ、バージョン14以降で安定化。
.mjs拡張子または"type": "module"設定が必要。 -
ブラウザ: 主要なモダンブラウザでネイティブにサポート。
<script type="module">を使用して読み込むことが可能。 - その他の環境: Denoなど、ES Modulesをデフォルトでサポートする新しいJavaScriptランタイムが登場。
5. 互換性と移行
CommonJSからES Modulesへの移行
-
注意点:
- ES Modulesは静的な構文解析を前提としているため、動的な
requireやmodule.exportsの使用は制限される。 - デフォルトエクスポートと名前付きエクスポートの違いに注意。
- 循環依存性がある場合、挙動が変わる可能性がある。
- ES Modulesは静的な構文解析を前提としているため、動的な
-
手順:
-
ファイル拡張子の変更:
.jsから.mjsに変更するか、package.jsonで"type": "module"を指定。 -
エクスポートの書き換え:
module.exportsをexportまたはexport defaultに置き換える。 -
インポートの書き換え:
requireをimportに置き換える。 - 依存関係の確認: 循環依存性や動的なモジュール読み込みがないか確認。
-
ファイル拡張子の変更:
ES ModulesからCommonJSへの移行
- 一般的には推奨されない。ES Modulesはモダンな機能を提供しており、可能な限りESMを使用することが推奨されます。
6. パフォーマンスと最適化
ES Modules
- ブラウザの最適化: ネイティブサポートにより、ブラウザが効率的にモジュールをキャッシュおよびプリロード可能。
- 並列読み込み: モジュールが独立している場合、並列に読み込むことが可能。
CommonJS
- 同期的な読み込み: サーバーサイドでは問題ないが、クライアントサイドではパフォーマンスに影響。
- キャッシュの制御: Node.jsはモジュールを一度読み込むとキャッシュするため、再読み込みのオーバーヘッドが少ない。
7. 実際の使用例
CommonJS
math.js
// math.js
const add = (a, b) => a + b;
const subtract = (a, b) => a - b;
module.exports = {
add,
subtract
};
app.js
// app.js
const math = require('./math');
console.log(math.add(5, 3)); // 8
console.log(math.subtract(5, 3)); // 2
ES Modules(ESM)
math.mjs
// math.mjs
export const add = (a, b) => a + b;
export const subtract = (a, b) => a - b;
// またはデフォルトエクスポート
// const multiply = (a, b) => a * b;
// export default multiply;
app.mjs
// app.mjs
import { add, subtract } from './math.mjs';
// デフォルトエクスポートの場合
// import multiply from './math.mjs';
console.log(add(5, 3)); // 8
console.log(subtract(5, 3)); // 2
// console.log(multiply(5, 3)); // 15
ブラウザでの使用例
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>ES Modules Example</title>
</head>
<body>
<script type="module">
import { add, subtract } from './math.js';
console.log(add(10, 5)); // 15
console.log(subtract(10, 5)); // 5
</script>
</body>
</html>
8. ツールとサポート
バンドラーのサポート
- Webpack: CommonJSとES Modulesの両方をサポート。ES Modulesを使用することで、より高度な最適化やツリーシェイキングが可能。
- Rollup: 主にES Modulesを前提としたバンドラー。ツリーシェイキングやコード分割に強み。
- Parcel: 自動的にCommonJSとES Modulesを検出し、適切にバンドル。
Node.jsの対応
-
Node.js 12以降: ES Modulesをサポート。ただし、
.mjs拡張子の使用やpackage.jsonでの設定が必要。 - 相互運用性: CommonJSとES Modulesは相互にインポート・エクスポートが可能だが、制約や注意点が存在。
9. まとめ
| 特徴 | CommonJS | ES Modules(ESM) |
|---|---|---|
| 導入時期 | Node.js中心に2009年頃から | ECMAScript 2015(ES6)で標準化 |
| エクスポート方法 | module.exports |
export / export default
|
| インポート方法 | require() |
import |
| 読み込みタイミング | 同期的 | 非同期的(ブラウザでは) |
| ファイル拡張子 | .js |
.mjs または package.jsonで"type": "module"指定 |
| ツリーシェイキング | 難しい | 容易 |
| 主な使用環境 | Node.js | ブラウザ、Node.js(最新) |
| パフォーマンス最適化 | サーバーサイドでの効率的なキャッシュ | ブラウザでの並列読み込みとキャッシュ |
| 相互運用性 | Node.js内部で広く使用 | 他のモジュールシステムと互換性が必要な場合の設定が必要 |
選択のポイント
-
プロジェクトの環境:
- サーバーサイドのみで動作する場合は、CommonJSが依然として広く使用されています。
- クライアントサイドや最新のNode.js環境では、ES Modulesが推奨されます。
-
ツールのサポート:
- モジュールバンドラーやトランスパイラーの設定がES Modulesに最適化されている場合、ESMの採用が容易です。
-
将来性:
- ECMAScriptの標準としてES Modulesが推進されており、将来的な互換性や機能拡張を考慮すると、ESMへの移行が望ましいです。
-
既存のコードベース:
- 既にCommonJSで構築された大規模なプロジェクトでは、段階的な移行が必要です。全てを一度に変更するのは困難な場合が多いため、互換性を保ちながら徐々にESMを導入する方法が現実的です。
今後の動向
ES Modulesは、モダンなJavaScript開発において標準的なモジュールシステムとなりつつあります。特に、フロントエンド開発においては、ブラウザのネイティブサポートが進んでいるため、ツリーシェイキングや動的インポートなどの高度な機能を活用できます。また、Node.jsでもES Modulesのサポートが強化されており、サーバーサイドとクライアントサイドで一貫したモジュール管理が可能になっています。
参考資料
V8エンジンは、Googleによって開発されたオープンソースのJavaScriptおよびWebAssemblyエンジンで、主にGoogle ChromeブラウザやNode.jsなどの環境で使用されています。V8は、高速なJavaScriptの実行と効率的なパフォーマンスを提供することを目的として設計されており、現代のウェブアプリケーションやサーバーサイドアプリケーションにおいて不可欠なコンポーネントとなっています。以下では、V8エンジンの概要とその動作プロセスについて詳しく解説します。
1. V8エンジンとは?
概要
V8エンジンは、JavaScriptのコードをネイティブマシンコードにコンパイルし、高速に実行するためのエンジンです。C++で実装されており、高いパフォーマンスと効率性を誇ります。V8は、以下のような特徴を持っています:
- 高速な実行速度: Just-In-Time(JIT)コンパイル技術を使用して、JavaScriptコードを最適化されたネイティブコードに変換します。
- メモリ効率: 効率的なメモリ管理とガベージコレクションにより、メモリ使用量を最適化します。
- モダンな機能サポート: ECMAScriptの最新仕様をサポートし、最新のJavaScript機能を提供します。
- クロスプラットフォーム対応: Windows、macOS、Linuxなど、多くのプラットフォームで動作します。
利用される環境
- Google Chrome: ウェブブラウザ内でJavaScriptを実行するために使用。
- Node.js: サーバーサイドJavaScriptの実行環境として使用。
- Electron: デスクトップアプリケーションの構築に使用されるフレームワーク。
- Deno: 新しいJavaScript/TypeScriptランタイムとして使用。
2. V8エンジンの動作プロセス
V8エンジンは、JavaScriptのソースコードを効率的に実行するために、以下のステップを踏んで処理を行います。ユーザーが提供したステップに基づき、各段階を詳しく説明します。
ステップ1: JavaScriptソースコードの提供
V8エンジンにJavaScriptのソースコードが提供されます。このソースコードは、ウェブページ内のスクリプトタグやNode.jsアプリケーションの実行時に渡されます。
// example.js
function greet(name) {
return `Hello, ${name}!`;
}
console.log(greet("World"));
ステップ2: パース(Parse it)
ソースコードがV8のパーサーによって解析され、トークンに分解されます。パーサーは、コードを構文的に正しいかどうかを検証し、構文エラーがないかをチェックします。
- トークナイゼーション: ソースコードを意味のある最小単位(トークン)に分割します。例: キーワード、識別子、演算子、リテラルなど。
- 構文解析: トークンを基に構文木(パースツリー)を構築します。
// トークン例
function, greet, (, name, ), {, return, `Hello, ${name}!`, ;, }, console, ., log, (, greet, (, "World", ), ), ;
ステップ3: 抽象構文木(AST: Abstract Syntax Tree)の生成
パーサーは、トークンを基に抽象構文木(AST)を生成します。ASTは、ソースコードの構造をツリー状に表現したもので、各ノードは構文要素(関数、変数、式など)を表します。
Program
└── FunctionDeclaration (greet)
├── Identifier (name)
└── BlockStatement
└── ReturnStatement
└── TemplateLiteral
├── "Hello, "
└── Identifier (name)
└── ExpressionStatement
└── CallExpression (console.log)
└── CallExpression (greet("World"))
ステップ4: バイトコードの生成(Generate Bytecode)
V8のインタープリターであるIgnitionがASTを低レベルのバイトコードに変換します。バイトコードは、仮想マシン向けの命令セットであり、中間言語として機能します。
// Ignitionが生成するバイトコードの一例(擬似コード)
LOAD_GLOBAL console
LOAD_METHOD log
LOAD_CONST "Hello, World!"
CALL_METHOD 1
RETURN
ステップ5: プロファイリング(Get feedback: Profiling)
バイトコードが実行される際に、V8は実行時情報を収集します。この情報には、関数の呼び出し頻度や変数の型情報などが含まれます。これにより、どの部分が「ホットスポット」(頻繁に実行される部分)であるかを特定し、最適化の対象を決定します。
- ヒートマップ: 実行回数や実行時間に基づいてコードのどの部分が最も使用されているかを視覚化。
- 型推論: 変数の型情報を収集し、最適化に役立てる。
ステップ6: 最適化とコンパイル(Optimize and Compile it)
収集された実行時情報を基に、V8のJITコンパイラであるTurboFanがコードの最適化を行います。TurboFanは、ホットスポットと特定されたコードをさらに最適化されたネイティブマシンコードにコンパイルします。これにより、パフォーマンスが向上します。
- インライン化: 頻繁に呼び出される関数をインライン展開し、関数呼び出しのオーバーヘッドを削減。
- デッドコードの削除: 実行されないコードを除去。
- ループ最適化: ループの実行効率を向上。
// TurboFanが生成するネイティブマシンコードの一例(擬似コード)
MOV R1, "Hello, World!"
CALL console.log, R1
RET
デオプティマイズ(Deoptimize)
最適化されたコードが実行中に、予期せぬ型の変数やその他の最適化仮定が破られた場合、V8はデオプティマイズを行います。これにより、最適化されたコードを元のバイトコードまたはインタープリターによる実行に戻し、正確な動作を保証します。
3. V8エンジンの内部コンポーネント
V8エンジンは、以下の主要なコンポーネントから構成されています:
a. Ignition(インタープリター)
Ignitionは、V8のインタープリターであり、ASTをバイトコードに変換し、即時に実行します。インタープリターは、初期の実行フェーズで迅速にコードを実行するために使用されます。
b. TurboFan(JITコンパイラ)
TurboFanは、V8のJITコンパイラであり、Ignitionによって生成されたバイトコードを最適化されたネイティブマシンコードに変換します。TurboFanは、パフォーマンスを最大化するために高度な最適化技術を採用しています。
c. Orinoco(ガベージコレクタ)
Orinocoは、V8のガベージコレクタであり、不要になったメモリを自動的に回収します。V8は、効率的なメモリ管理を実現するために、世代別ガベージコレクションやインクリメンタルガベージコレクションを採用しています。
d. Liftoff(AOTコンパイラ)
Liftoffは、V8のAhead-Of-Time(AOT)コンパイラであり、特定の条件下でバイトコードを事前にネイティブマシンコードに変換します。これにより、初期の実行時の遅延を削減します。
4. V8エンジンの特徴と利点
高性能な実行速度
V8エンジンは、IgnitionとTurboFanを組み合わせることで、高速なJavaScriptの実行を実現しています。インタープリターとJITコンパイラの協調動作により、初期の実行速度と最適化後の高性能を両立しています。
効率的なメモリ管理
Orinocoガベージコレクタにより、不要なメモリを効率的に回収し、メモリリークを防ぎます。世代別ガベージコレクションにより、頻繁に使用されるオブジェクトとそうでないオブジェクトを分離し、効率的なメモリ管理を実現しています。
モダンなJavaScript機能のサポート
V8は、最新のECMAScript仕様を迅速に取り入れ、新しいJavaScript機能をサポートします。これにより、開発者は最新の言語機能を活用したモダンなコードを書くことができます。
クロスプラットフォーム対応
V8は、Windows、macOS、Linuxなどの主要なプラットフォームで動作し、広範な環境で利用可能です。これにより、さまざまなデバイスやシステム上で一貫したパフォーマンスを提供します。
5. V8エンジンの具体的な動作例
以下に、V8エンジンがどのようにJavaScriptコードを処理し、実行するかの具体的な例を示します。
例: シンプルなJavaScriptコードの実行
// example.js
function factorial(n) {
if (n === 0) return 1;
return n * factorial(n - 1);
}
console.log(factorial(5));
動作プロセスの詳細
-
ソースコードの提供
-
example.jsがV8エンジンに提供されます。
-
-
パース
- V8のパーサーがソースコードを解析し、トークンに分解します。
- トークンからASTが生成されます。
-
バイトコードの生成
- IgnitionがASTをバイトコードに変換します。
-
初期実行とプロファイリング
- バイトコードが実行され、関数
factorialが呼び出されます。 - V8は関数
factorialの実行頻度や変数nの型情報を収集します。
- バイトコードが実行され、関数
-
最適化
-
factorial関数がホットスポットと判断されると、TurboFanが関数を最適化されたネイティブマシンコードにコンパイルします。 - 以降の
factorialの呼び出しは、最適化されたネイティブコードが実行され、高速化されます。
-
-
結果の出力
-
console.log(factorial(5))が実行され、結果120がコンソールに出力されます。
-
6. V8エンジンの最適化技術
V8エンジンは、パフォーマンスを最大化するためにさまざまな最適化技術を採用しています。以下に主な技術を紹介します。
a. Just-In-Time(JIT)コンパイル
V8は、コードを実行時にネイティブマシンコードにコンパイルするJITコンパイルを採用しています。これにより、実行中のコードに対して最適化が可能となり、高速なパフォーマンスを実現します。
b. インライン化
頻繁に呼び出される関数や小さな関数を呼び出し元に直接埋め込む(インライン化)ことで、関数呼び出しのオーバーヘッドを削減します。
c. 型推論と最適化
V8は、実行時に変数の型情報を収集し、その情報を基に最適化を行います。例えば、変数が常に整数型である場合、その特性を利用して高速な命令を生成します。
d. デッドコードの削除
実行されないコードや不要なコードを除去することで、バイトコードやネイティブマシンコードのサイズを削減し、パフォーマンスを向上させます。
e. メモリ管理の最適化
効率的なガベージコレクションとメモリ管理により、メモリ使用量を最適化し、パフォーマンスを維持します。
7. V8エンジンの最新機能と今後の展望
V8エンジンは、継続的なアップデートと改良が行われており、最新のJavaScript機能や最適化技術が取り入れられています。以下に、最近の機能と将来の展望を紹介します。
a. WebAssemblyのサポート
V8は、WebAssembly(Wasm)のネイティブサポートを提供しています。これにより、高性能なバイナリ形式のコードをJavaScript環境で実行することが可能となり、より高度なアプリケーションの開発が可能です。
b. Top-Level Awaitのサポート
ECMAScriptの最新仕様に基づき、トップレベルでのawaitの使用が可能となりました。これにより、モジュールのロード時に非同期処理を簡単に扱うことができます。
// top-level-await.mjs
const response = await fetch('https://api.example.com/data');
const data = await response.json();
console.log(data);
c. パフォーマンスの継続的な向上
V8は、常にパフォーマンスの向上を目指して最適化が行われています。新しい最適化アルゴリズムや改善されたJITコンパイラ技術により、JavaScriptコードの実行速度が向上しています。
d. ECMAScriptの最新機能の迅速な採用
V8は、ECMAScriptの最新機能を迅速に取り入れ、開発者が最新の言語機能を活用できるようにしています。これにより、モダンなJavaScript開発がより効率的に行えます。
8. V8エンジンの開発とコミュニティ
V8エンジンは、Googleのオープンソースプロジェクトとして開発されており、世界中の開発者コミュニティによってサポートされています。以下に、V8の開発に関するポイントを紹介します。
a. オープンソース
V8はGitHub上で公開されており、誰でもソースコードを閲覧・修正・貢献することができます。これにより、透明性が高まり、コミュニティによる継続的な改善が促進されています。
- リポジトリ: V8 GitHub Repository
b. 継続的なアップデート
Googleは、V8エンジンを定期的にアップデートし、バグ修正や新機能の追加、パフォーマンスの向上を行っています。これにより、V8は常に最新の技術と仕様に対応しています。
c. コミュニティの貢献
世界中の開発者がV8の改善に貢献しており、バグ報告や機能提案、コードのプルリクエストなどを通じてプロジェクトに参加しています。これにより、多様な視点と専門知識がV8の品質向上に寄与しています。
9. まとめ
V8エンジンは、高速で効率的なJavaScriptの実行を可能にする強力なエンジンです。以下に、V8の主要なポイントをまとめます:
- V8とは: Googleが開発したオープンソースのJavaScriptエンジンで、ChromeやNode.jsなどで使用。
-
動作プロセス:
- JavaScriptソースコードの提供
- パース(解析)
- ASTの生成
- バイトコードの生成(Ignition)
- プロファイリング(実行時情報の収集)
- 最適化とコンパイル(TurboFan)
- 内部コンポーネント: Ignition、TurboFan、Orinoco、Liftoffなど。
- 最適化技術: JITコンパイル、インライン化、型推論、デッドコードの削除、効率的なメモリ管理など。
- 最新機能と展望: WebAssemblyのサポート、トップレベルawait、継続的なパフォーマンス向上、ECMAScriptの最新機能の迅速な採用。
- 開発とコミュニティ: オープンソースプロジェクトとして、世界中の開発者が貢献。
V8エンジンは、モダンなJavaScript開発において欠かせない基盤であり、その高速な実行性能と継続的な進化により、ウェブやサーバーサイドアプリケーションのパフォーマンスとユーザー体験を大幅に向上させています。
参考資料
JSX
Thought for a couple of seconds
**JSX(JavaScript XML)**は、JavaScript内でXMLやHTMLのような構文を使用できる拡張構文であり、主にReactライブラリとともに使用されます。JSXを使用することで、UIコンポーネントを宣言的かつ直感的に記述することが可能となり、コードの可読性と保守性が向上します。以下では、JSXの詳細、特徴、利点、使用方法、およびReactとの関係について詳しく解説します。
- JSXとは?
概要
JSX(JavaScript XML)は、JavaScriptにXMLやHTMLに似た構文を導入するための構文拡張です。Reactでは、JSXを使用してUIコンポーネントを定義し、ビューの構造を直感的に記述します。JSX自体はブラウザやJavaScriptエンジンによって直接理解されるものではなく、ビルドプロセス中に通常Babelなどのトランスパイラを使用して標準的なJavaScriptに変換されます。
主な特徴
宣言的なUI記述: UIの構造をHTMLのような構文で記述できるため、視覚的に理解しやすい。
JavaScriptとの統合: JavaScriptの中に直接埋め込むことができ、動的なコンテンツやロジックを簡単に組み込める。
コンポーネントベース: 再利用可能なUIコンポーネントを作成しやすく、複雑なUIを効率的に構築可能。
JSXの動作原理
トランスパイル
JSXはブラウザが直接理解できるものではないため、Babelなどのトランスパイラを使用して標準的なJavaScriptに変換(トランスパイル)する必要があります。変換後のコードは、ReactのReact.createElement関数を使用して、仮想DOM(Virtual DOM)を構築します。
JSXコード例
const element = <h1 className="greeting">Hello, World!</h1>;
トランスパイル後のJavaScriptコード
const element = React.createElement(
'h1',
{ className: 'greeting' },
'Hello, World!'
);
仮想DOMとの関係
JSXを使用して定義されたUIは、仮想DOMとして表現されます。Reactはこの仮想DOMを実際のDOMと比較し、差分を検出して効率的に更新します。このプロセスにより、パフォーマンスの向上とスムーズなユーザー体験が実現されます
Reactの仮想DOMは、効率的なUIの更新と高パフォーマンスを実現するための中核的な技術です。以下に、主要なポイントをまとめます:
仮想DOMの役割:
UIの軽量なコピーをメモリ上に保持し、差分検出を通じて効率的に実際のDOMを更新。
差分検出(Reconciliation):
新旧の仮想DOMを比較し、最小限の変更を実際のDOMに適用するプロセス。
React Fiber:
仮想DOMの差分検出と更新をインクリメンタルに行う新しいレンダリングエンジン。高パフォーマンスと柔軟性を提供。
利点:
高速なUI更新、宣言的なUI記述、開発体験の向上。
デメリット:
メモリ消費の増加、学習コスト、特定のケースでの追加最適化の必要性。
実際の動作例:
状態管理と仮想DOMを通じて、効率的にUIを更新するReactコンポーネントの例。
Reactの仮想DOMとFiberの仕組みを理解することで、より高度なReactアプリケーションの開発やパフォーマンス最適化が可能になります。これらの概念は、Reactが提供する強力なツールセットの一部であり、モダンなウェブ開発において欠かせない要素です。
keyプロパティは、Reactでリストをレンダリングする際に各要素を一意に識別するために不可欠な属性です。適切にkeyを設定することで、以下の利点を享受できます:
効率的な再レンダリング: 必要な部分のみを更新し、パフォーマンスを最適化。
正確な要素の識別: 変更、追加、削除された要素を正確に特定。
スムーズなアニメーション: 要素の入れ替えや削除時にアニメーションを効果的に適用。
ベストプラクティスとしては、一意なIDをkeyとして使用し、インデックスを避けることが推奨されます。これにより、Reactが仮想DOM内の要素を正確に追跡し、効率的なUI更新を実現できます。
**Reactにおいて、クラスコンポーネント(Class Component)ではなく関数コンポーネント(Functional Component)を使用する利点は多岐にわたります。以下に主要な利点を詳しく解説します。
1. thisキーワードを使わなくてもよい
利点
-
簡潔で直感的なコード: クラスコンポーネントでは、
thisキーワードを使用して状態やメソッドにアクセスする必要があります。これは初心者にとって混乱を招くことがありますが、関数コンポーネントではthisを使用しないため、コードがよりシンプルで理解しやすくなります。クラスコンポーネントの例
class Greeting extends React.Component { constructor(props) { super(props); this.state = { name: 'John' }; this.handleChange = this.handleChange.bind(this); } handleChange(event) { this.setState({ name: event.target.value }); } render() { return ( <div> <h1>Hello, {this.state.name}!</h1> <input type="text" onChange={this.handleChange} /> </div> ); } }関数コンポーネントの例
import React, { useState } from 'react'; function Greeting() { const [name, setName] = useState('John'); const handleChange = (event) => { setName(event.target.value); }; return ( <div> <h1>Hello, {name}!</h1> <input type="text" onChange={handleChange} /> </div> ); }
2. 記述量が少なくなる
利点
-
コードの簡素化: 関数コンポーネントはクラスコンポーネントに比べて記述が少なく、冗長なコードを減らすことができます。これにより、コードベースがクリーンになり、メンテナンスが容易になります。
クラスコンポーネントの冗長さ
class Counter extends React.Component { constructor(props) { super(props); this.state = { count: 0 }; this.increment = this.increment.bind(this); } increment() { this.setState({ count: this.state.count + 1 }); } render() { return ( <div> <p>Count: {this.state.count}</p> <button onClick={this.increment}>Increment</button> </div> ); } }関数コンポーネントの簡潔さ
import React, { useState } from 'react'; function Counter() { const [count, setCount] = useState(0); const increment = () => setCount(count + 1); return ( <div> <p>Count: {count}</p> <button onClick={increment}>Increment</button> </div> ); }
3. カスタムフックを用いることでロジックとプレゼンテーションを分離しやすくなる
利点
-
ロジックの再利用: カスタムフックを使用することで、状態管理や副作用処理などのロジックをコンポーネントから分離し、再利用可能な形で抽出できます。これにより、コードの重複を避け、テストもしやすくなります。
カスタムフックの例
// useForm.js import { useState } from 'react'; function useForm(initialValues) { const [values, setValues] = useState(initialValues); const handleChange = (event) => { const { name, value } = event.target; setValues({ ...values, [name]: value, }); }; return [values, handleChange]; } export default useForm;// FormComponent.jsx import React from 'react'; import useForm from './useForm'; function FormComponent() { const [formValues, handleChange] = useForm({ username: '', email: '' }); const handleSubmit = (event) => { event.preventDefault(); console.log(formValues); }; return ( <form onSubmit={handleSubmit}> <input type="text" name="username" value={formValues.username} onChange={handleChange} /> <input type="email" name="email" value={formValues.email} onChange={handleChange} /> <button type="submit">Submit</button> </form> ); } export default FormComponent;
4. フック(Hooks)の利用による強力な機能
利点
-
状態管理と副作用の簡素化: フック(特に
useStateやuseEffect)を使用することで、状態管理や副作用の処理が容易になります。クラスコンポーネントでは複雑になりがちなこれらの機能を、関数コンポーネントではシンプルに実装できます。状態管理の例
import React, { useState } from 'react'; function Toggle() { const [isOn, setIsOn] = useState(false); return ( <button onClick={() => setIsOn(!isOn)}> {isOn ? 'ON' : 'OFF'} </button> ); }副作用の例
import React, { useState, useEffect } from 'react'; function Timer() { const [seconds, setSeconds] = useState(0); useEffect(() => { const interval = setInterval(() => { setSeconds((prev) => prev + 1); }, 1000); return () => clearInterval(interval); }, []); return <div>Seconds: {seconds}</div>; }
5. パフォーマンスの向上
利点
-
メモ化の容易さ:
React.memoやuseMemo、useCallbackといったフックを使用することで、コンポーネントのレンダリングを最適化し、不要な再レンダリングを防ぐことができます。クラスコンポーネントではこれらの最適化がやや複雑になります。メモ化の例
import React, { useState, useMemo } from 'react'; function ExpensiveComponent({ number }) { const computeFactorial = (n) => { console.log('Computing factorial'); return n <= 1 ? 1 : n * computeFactorial(n - 1); }; const factorial = useMemo(() => computeFactorial(number), [number]); return <div>Factorial of {number} is {factorial}</div>; } function App() { const [count, setCount] = useState(1); const [other, setOther] = useState(false); return ( <div> <button onClick={() => setCount(count + 1)}>Increment Count</button> <button onClick={() => setOther(!other)}>Toggle Other</button> <ExpensiveComponent number={count} /> </div> ); } export default App;
React Hook
Hooksは、Reactの関数コンポーネント内で状態(state)や副作用(side effects)を管理するための関数です。従来、状態管理やライフサイクルメソッドを使用するにはクラスコンポーネントを利用する必要がありましたが、Hooksの導入により、関数コンポーネントでもこれらの機能を簡単に実装できるようになりました。
主な目的
状態管理の簡素化: useStateフックを使用して、関数コンポーネント内で状態を管理できます。
副作用の管理: useEffectフックを使用して、データの取得や購読、DOMの操作などの副作用を処理できます。
ロジックの再利用: カスタムフック(Custom Hooks)を作成することで、複数のコンポーネント間でロジックを共有できます。
コードの可読性と保守性の向上: クラスコンポーネントに比べて、関数コンポーネントはシンプルで理解しやすくなります。
Thought for a second
useCallbackは、Reactにおけるパフォーマンス最適化のためのフック(Hook)の一つです。主に関数コンポーネント内で関数をメモ化(キャッシュ)し、不要な再生成を防ぐことで、再レンダリング時のパフォーマンス向上や子コンポーネントへの不要な再レンダリングを防ぐために使用されます。
useCallbackとは
useCallbackは、特定の依存関係が変化しない限り、同じ関数インスタンスを再利用するためのReactフックです。これにより、関数が再生成される頻度を減らし、パフォーマンスの最適化やメモリ使用量の削減に寄与します。
基本的な構文
javascript
Copy code
const memoizedCallback = useCallback(
() => {
// 関数の処理内容
},
[依存関係]
);
第一引数: メモ化したい関数
第二引数: 依存関係の配列。配列内の値が変更された場合にのみ関数が再生成されます。
useCallbackの使用目的
パフォーマンスの最適化
関数が頻繁に再生成されることで、不要な再レンダリングやメモリ消費が発生するのを防ぎます。
子コンポーネントへの最適化
子コンポーネントがReact.memoなどでメモ化されている場合、親コンポーネントから渡されるコールバック関数が毎回新しい関数として渡されると、子コンポーネントが不要に再レンダリングされる可能性があります。useCallbackを使用することで、関数が同一のインスタンスとして渡され、子コンポーネントの再レンダリングを防ぐことができます。
使用例
例1: シンプルなカウンター
javascript
Copy code
import React, { useState, useCallback } from 'react';
const Counter = () => {
const [count, setCount] = useState(0);
// useCallbackを使用しない場合
const increment = () => {
setCount(prevCount => prevCount + 1);
};
return (
<div>
<p>カウント: {count}</p>
<button onClick={increment}>増加</button>
</div>
);
};
export default Counter;
この例では、useCallbackを使用していません。Counterコンポーネントが再レンダリングされるたびに、increment関数が新しく生成されます。
例2: useCallbackを使用したカウンター
javascript
Copy code
import React, { useState, useCallback } from 'react';
const Counter = () => {
const [count, setCount] = useState(0);
// useCallbackを使用して関数をメモ化
const increment = useCallback(() => {
setCount(prevCount => prevCount + 1);
}, []);
return (
<div>
<p>カウント: {count}</p>
<button onClick={increment}>増加</button>
</div>
);
};
export default Counter;
この例では、useCallbackを使用してincrement関数をメモ化しています。依存関係の配列が空であるため、increment関数はコンポーネントのマウント時に一度だけ生成され、以降の再レンダリングでも同じ関数インスタンスが使用されます。
例3: 子コンポーネントへのコールバック関数の渡し
javascript
Copy code
import React, { useState, useCallback } from 'react';
import ChildComponent from './ChildComponent';
const ParentComponent = () => {
const [count, setCount] = useState(0);
// useCallbackを使用して関数をメモ化
const handleClick = useCallback(() => {
setCount(prevCount => prevCount + 1);
}, []);
return (
<div>
<p>カウント: {count}</p>
<ChildComponent onClick={handleClick} />
</div>
);
};
export default ParentComponent;
javascript
Copy code
// ChildComponent.js
import React from 'react';
const ChildComponent = React.memo(({ onClick }) => {
console.log('ChildComponentが再レンダリングされました');
return <button onClick={onClick}>子コンポーネントのボタン</button>;
});
export default ChildComponent;
説明:
ParentComponentからChildComponentにhandleClick関数をpropsとして渡しています。
ChildComponentはReact.memoでメモ化されているため、propsが変わらない限り再レンダリングされません。
useCallbackを使用してhandleClickをメモ化することで、ParentComponentが再レンダリングされてもhandleClick関数が同じインスタンスとして渡されるため、ChildComponentの再レンダリングを防ぎます。
useCallbackとuseMemoの違い
useCallback
目的: 関数のメモ化
使用方法: useCallback(() => { /* 関数 */ }, [依存関係])
返り値: メモ化された関数
useMemo
目的: 計算結果のメモ化
使用方法: useMemo(() => { /* 計算 */ }, [依存関係])
返り値: メモ化された計算結果
useCallbackを使うべきケース
子コンポーネントへのコールバック関数の渡し
親コンポーネントが再レンダリングされるたびに新しい関数インスタンスが生成されるのを防ぎ、子コンポーネントの不要な再レンダリングを防ぐため。
依存関係が少ない関数のメモ化
依存関係が頻繁に変わらない関数や、高頻度で再生成される関数の最適化に有効です。
パフォーマンスが重要な場面
大規模なアプリケーションや複雑なコンポーネント構造において、パフォーマンスを向上させたい場合。
useCallbackを使うべきでないケース
関数が軽量で頻繁に再生成されても問題ない場合
小規模なアプリケーションやパフォーマンスに大きな影響を与えない場合、useCallbackを使用することでコードが複雑になる可能性があります。
依存関係が多い関数
依存関係が多いと、useCallbackを使用することで逆にパフォーマンスが低下することがあります。依存関係の配列が頻繁に変わると、関数の再生成が頻繁に行われるためです。
メモ化のオーバーヘッドが大きい場合
関数自体が軽量であり、メモ化による利益がオーバーヘッドを上回らない場合。
useRefと他のフックとの比較
useRef vs useState
再レンダリングのトリガー:
useStateは状態が更新されるとコンポーネントが再レンダリングされます。
useRefは値の更新があっても再レンダリングを引き起こしません。
用途の違い:
useStateはユーザーインターフェースに影響を与える状態管理に適しています。
useRefはDOMへのアクセスやレンダリング間での値の保持など、直接的にUIに影響を与えない用途に適しています。
useRef vs useMemo
目的の違い:
useRefはミューテート可能なオブジェクトを保持するために使用されます。
useMemoは計算結果をメモ化し、依存関係が変わらない限り再計算を避けるために使用されます。
Hydrationは、Next.jsにおけるサーバーサイドレンダリングとクライアントサイドのインタラクティブな機能を結びつける重要なプロセスです。これにより、ユーザーは初期表示の高速化とインタラクティブな操作を同時に享受できます。しかし、サーバーとクライアントでのレンダリング結果の一致や、適切なデータフェッチの管理など、いくつかの課題も存在します。
主なポイント
Hydrationの役割:
サーバー側で生成された静的HTMLに対して、クライアントサイドで動的な機能を追加するプロセス。
Hydrationの利点:
初期表示の高速化。
インタラクティブなユーザー体験の提供。
SEOの向上。
Hydrationの課題:
レンダリング結果の不一致によるエラー。
パフォーマンスの最適化。
環境依存のコードの取り扱い。
Hydrationエラーの対策:
サーバーとクライアントでのレンダリング結果の一致を確保。
環境依存のコードはクライアントサイドでのみ実行。
適切なデータフェッチとステート管理。
Next.jsの機能活用:
自動コードスプリッティング。
動的インポート。
イメージ最適化。
SSRを実行する場合、クライアント側でJavaScriptが全てのレンダリングを行うのではなく、サーバー側で事前に静的なHTMLを生成してクライアントに送信します。これにより初期表示を高速化できますが、HTMLだけを送信した段階ではまだインタラクションができません(クリックしても、、何も起きない、、!)
HTMLをレンダリングした後、クライアント側でJavaScriptをダウンロードし、すでに表示されているHTMLに結びつけます。これによりインタラクションが可能になります。
この静的な HTML に Javascript を結びつけてインタラクティブにするプロセスを Hydration といいます。
マージンが不可解な挙動をする
相殺が起こるのは縦方向のみというのも、個人的には直感的でないと思っています。
コンポーネントとして使い回しずらい
「コンポーネント自体が周りからどのくらい離れたいか」という意思をコンポーネント自体に付与していることが原因で起きています。
先程までは、「各エレメントが周りからどのくらい離れたいか」という視点でマージンを使っていました。親エレメントにパディングを持たせることで、各エレメントが「どのくらい離れたいのか」気にする必要がなくなりました。
また、「カードエレメントの画像部分の空白を無くしたい」という変更依頼がきても柔軟に対応することができるようになりました。(図の右)
同様に、flexboxやgridのgapを用いてエレメント同士を離すこともできます。こうすることにより、レスポンシブデザインにも柔軟に適用できるようになります。
エレメント間を離したい際は、「そのエレメント自体がどのくらい離れたいか」という視点ではなく、なるべく親がレイアウトの責務を負う設計にすると良いと感じました。
コンポーネント志向![]
→ コンポーネントを組み立て制御する
→ コンポーネントの変更で再レンダリングを子をを含めてやる
→ シンプル
(https://storage.googleapis.com/zenn-user-upload/7693d9451aec-20241006.png)
更新時のレンダリングを意識しなくても良いので宣言的
入力フィールドと非制御コンポーネント
use memo 使い所

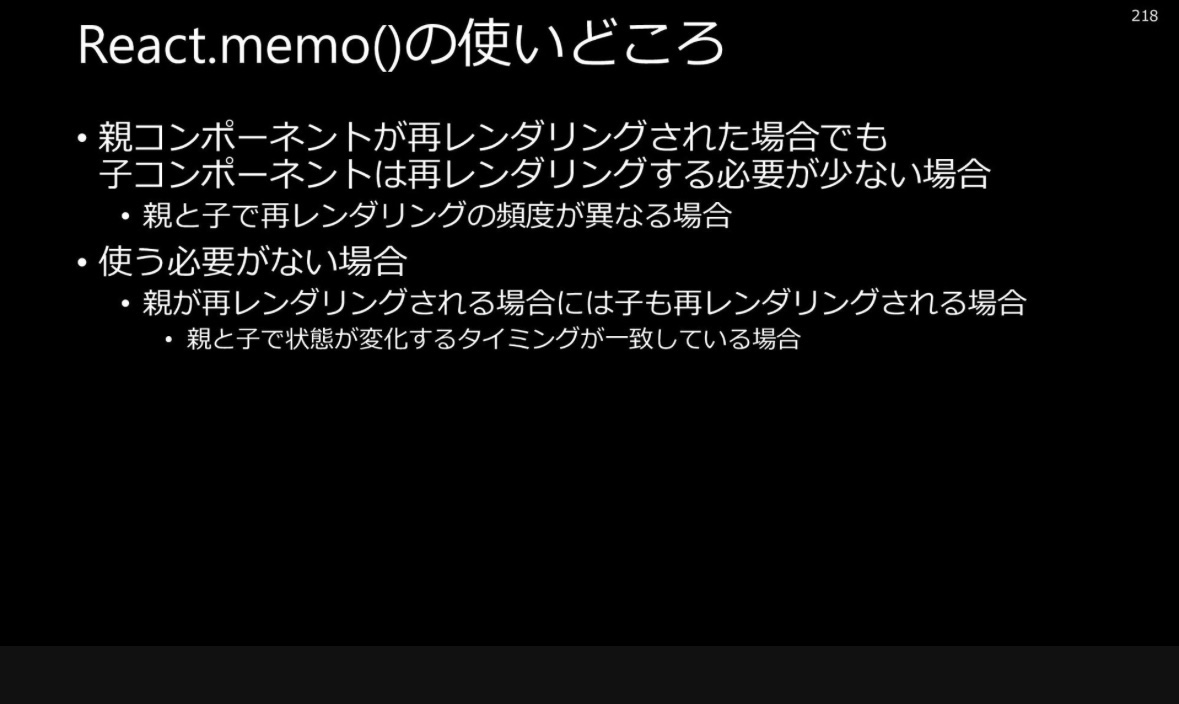

ARIA(a-ria)
WAI-ARIA(Web Accessibility Initiative – Accessible Rich Internet Applications)をReactで活用することで、ウェブアプリケーションのアクセシビリティを向上させ、障害を持つユーザーにも使いやすいインターフェースを提供することが可能になります。以下に、ReactでWAI-ARIAを活用する際の主なポイントや利点、ベストプラクティスについて説明します。
1. WAI-ARIAとは?
WAI-ARIAは、ウェブコンテンツやウェブアプリケーションのアクセシビリティを向上させるための技術仕様です。特に、ダイナミックなコンテンツやリッチインタラクティブなUIコンポーネントに対して、支援技術(スクリーンリーダーなど)が正しく理解・操作できるように役割や状態、プロパティを定義します。
2. ReactでのWAI-ARIAの活用方法
a. ARIA属性の追加
Reactでは、JSXを使用してHTML要素をレンダリングする際に、直接ARIA属性を追加することができます。例えば、ボタンに対してaria-pressed属性を追加する場合:
<button aria-pressed={isPressed} onClick={togglePress}>
{isPressed ? '押されました' : '押してください'}
</button>
b. ロール(role)の設定
特定のUIコンポーネントに適切なロールを設定することで、支援技術にその要素の役割を伝えることができます。例えば、カスタムのモーダルダイアログを作成する際:
<div role="dialog" aria-modal="true" aria-labelledby="dialog-title">
<h2 id="dialog-title">モーダルタイトル</h2>
<p>モーダルの内容...</p>
<button onClick={closeModal}>閉じる</button>
</div>
c. 状態とプロパティの管理
ARIA属性には、コンポーネントの状態やプロパティを反映させるものがあります。例えば、タブインターフェースで現在のタブを示す場合:
<ul role="tablist">
<li role="presentation">
<button
role="tab"
aria-selected={isSelected}
aria-controls={`panel-${id}`}
id={`tab-${id}`}
onClick={() => selectTab(id)}
>
タブ {id}
</button>
</li>
{/* 他のタブ */}
</ul>
<div
role="tabpanel"
id={`panel-${id}`}
aria-labelledby={`tab-${id}`}
hidden={!isSelected}
>
{/* パネル内容 */}
</div>
3. 利点
a. アクセシビリティの向上
WAI-ARIAを適切に使用することで、キーボード操作やスクリーンリーダーのユーザーに対して、インターフェースの意図や状態を明確に伝えることができます。
b. ユーザーエクスペリエンスの改善
アクセシブルなコンポーネントは、すべてのユーザーにとって使いやすく、直感的な操作を提供します。これにより、ユーザーエクスペリエンス全体が向上します。
c. 法令遵守
多くの国や地域では、ウェブアクセシビリティに関する法規制があります。WAI-ARIAを活用することで、これらの規制に準拠したウェブアプリケーションを構築できます。
4. ベストプラクティス
a. 必要最低限のARIA使用
ネイティブHTML要素には、既にアクセシビリティが備わっているものが多いため、必要な場合のみARIA属性を追加します。過剰なARIAの使用は、逆にアクセシビリティを損なう可能性があります。
b. ARIAの正しい使用
各ARIA属性の役割や使い方を理解し、正しく適用することが重要です。誤った使用は、支援技術に誤解を与える可能性があります。
c. アクセシビリティツールの活用
開発中にアクセシビリティツール(例:axe、Lighthouse)を使用して、ARIAの適用状況やアクセシビリティの問題をチェックします。
d. ユーザーのフィードバックを取り入れる
実際のユーザーからのフィードバックを基に、アクセシビリティの改善を継続的に行います。
5. ライブラリとツールの活用
Reactエコシステムには、WAI-ARIAの実装を支援するライブラリが存在します。例えば:
- React Aria: Adobeが提供する、アクセシブルなUIコンポーネントを構築するためのフックライブラリ。
- Reach UI: アクセシビリティを重視したReactコンポーネントライブラリ。
- Downshift: アクセシブルなドロップダウンやオートコンプリートコンポーネントを構築するためのライブラリ。
これらのライブラリを活用することで、WAI-ARIAの実装が容易になり、アクセシブルなコンポーネントを効率的に構築できます。
まとめ
ReactでWAI-ARIAを活用することは、ウェブアプリケーションのアクセシビリティを大幅に向上させる強力な手段です。適切なARIA属性の追加やロールの設定、状態管理を行うことで、すべてのユーザーにとって使いやすいインターフェースを提供できます。さらに、アクセシビリティに特化したライブラリやツールを活用することで、効率的かつ効果的にアクセシブルなReactアプリケーションを構築することが可能です。





関数型のステート更新(prevUser => ({ ...prevUser, email: newEmail }))は、ステートが前の状態に依存して更新される場合に安全で信頼性が高い方法です。
直接スプレッド構文を使用する方法(setUser({ ...user, email: newEmail }))は、ステートが前の状態に依存しない単純な更新の場合に適しています。
ベストプラクティスとして、ステート更新が前の状態に依存する場合は関数型の更新を使用し、必要に応じて一貫性を保つために常に関数型の更新を使用することを検討してください。
ステートの一部を更新する場合でも、その更新が前のステートに依存している場合は、関数型のステート更新(prevState => newState)を使用することが推奨されます。
関数型のステート更新を使用することで、非同期でバッチ処理されるステート更新に対しても、常に最新のステートに基づいた正確な更新が可能になります。
依存しない更新の場合でも、一貫性を保つために関数型のステート更新を使用することがベストプラクティスです。
**ref(Reference)**は、Reactで特定のDOM要素やコンポーネントに直接アクセスするための仕組みです。これにより、以下のような操作が可能になります。
DOM要素への直接アクセス: フォーカスの設定、テキストの選択、メディアの再生・一時停止など。
子コンポーネントのインスタンスメソッドへのアクセス: 子コンポーネントが公開しているメソッドを呼び出す。
アプリケーションがデカくなった時に、useReducer側で更新の管理を行う方が良い場合がある
seContextは強力なフックですが、適切に使用しないとパフォーマンスの問題や予期せぬ動作を引き起こす可能性があります。ここでは、useContextを使用する際の主要な注意点とベストプラクティスについて解説します。
4.1 パフォーマンスへの影響
再レンダリングのトリガー:
コンテキストの値が更新されると、そのコンテキストを消費しているすべてのコンポーネントが再レンダリングされます。
対策:
コンテキストの値をできるだけ安定させる。
状態の分割(必要な部分だけをコンテキストで共有)を行う。
React.memoやuseMemoを活用して再レンダリングを最適化する。
useEffect:
実行タイミング: ブラウザが画面の描画を完了した後に非同期で実行されます。
用途: データのフェッチ、購読の設定、DOMの更新など、レンダリング後に行う副作用に適しています。
レンダリングのブロック: 画面の描画をブロックしません。
useLayoutEffect:
実行タイミング: DOMの更新が行われた直後、ブラウザが画面を再描画する前に同期的に実行されます。
用途: DOMのレイアウトを読み取ったり、DOMの変形を行ったりする必要がある場合に適しています。
レンダリングのブロック: ブラウザの描画をブロックするため、パフォーマンスに影響を与える可能性があります。
Mainコンポーネントのステートが変わり、オブジェクトが更新されることで、子コンポーネントが再度レンダリングされる
ので、useMemoでオブジェクトを持っておいて、更新させない

はい、その理解で問題ありません。
• 関数をpropsに渡すとき: useCallbackを使用します。
• 関数をメモ化することで、依存配列の値が変わらない限り、同じ関数インスタンスが再利用されます。
• これにより、子コンポーネントへの再レンダリングを防ぐことができます。
• 値をメモ化したいとき: useMemoを使用します。
• 計算結果やオブジェクトなどの「値」をメモ化します。
• 計算コストの高い処理結果を再利用する際に有効です。
まとめると、関数をプロップスとして渡す際にはuseCallback、値をメモ化したい場合にはuseMemoを使用すれば大丈夫です。
ご質問や不明点があれば、遠慮なくお知らせください。
はい、そのとおりです。
React.memo
• 目的: コンポーネントをメモ化し、同じプロパティ(props)が渡された場合に再レンダリングを防ぐために使用します。
• 使い方: 関数コンポーネントを React.memo でラップします。
• 例:
const MyComponent = React.memo(function(props) {
// コンポーネントの実装
return <div>{props.value}</div>;
});
• 使用タイミング: コンポーネントが同じプロパティで再レンダリングされる際に、パフォーマンス最適化のために使用します。
ポイント
• 浅い比較: React.memo はデフォルトで props の浅い比較を行います。オブジェクトや配列などの複雑なデータを props として渡す場合、それらが新しい参照を持つと再レンダリングされます。
• カスタム比較関数: 必要に応じて、カスタムの比較関数を第二引数として渡すことができます。
const MyComponent = React.memo(function(props) {
// コンポーネントの実装
}, (prevProps, nextProps) => {
// カスタム比較ロジック
return prevProps.value === nextProps.value;
});
useMemoとの違い
• React.memo:
• コンポーネント全体をメモ化します。
• 主に関数コンポーネントの再レンダリングを最適化するために使用します。
• useMemo:
• コンポーネント内で計算された「値」をメモ化します。
• 再レンダリング時に不要な再計算を避けるために使用します。
まとめ
• コンポーネントのメモ化: 再レンダリングを最適化するためにReact.memoを使用できます。
• 値や関数のメモ化:
• 値: useMemoを使用。
• 関数: useCallbackを使用。
ご質問やさらに詳しい説明が必要であれば、お気軽にお知らせください。
Storybookをコンポーネントのテストライブラリと捉える
CSP
具体的には、a.comがレスポンスヘッダーにCSPポリシーを含めている場合、そのポリシーに基づいてブラウザがb.comからのスクリプトを拒否する仕組みです。たとえHTMLの一部に<script src="http://b.com/evil-script.js">のようなタグが含まれていても、CSPによって制御され、ブラウザがそのスクリプトのロードをブロックします。
実際の動きの流れを簡単にまとめると:
-
ユーザーが
a.comにアクセスすると、a.comのサーバーからレスポンスが返ってきます。このレスポンスに、CSPヘッダー(例:Content-Security-Policy: script-src 'self';)が含まれているとします。 -
ブラウザは、このCSPヘッダーを読み取り、「スクリプトは
a.com(= self)のみから許可される」というポリシーを認識します。 -
ページのHTMLに
<script src="http://b.com/evil-script.js">が含まれている場合でも、ブラウザはCSPポリシーに基づき、b.comからのスクリプトはロードしません。 -
結果として、
b.comからのスクリプト実行がブロックされ、ページ上でのXSS攻撃のリスクが軽減されます。
ポイント
- CSPはブラウザが解釈するポリシーであり、サーバーから設定されたポリシーに従って、ブラウザ側で動作を制限します。
-
script-src 'self'という設定により、a.com以外からのスクリプトがロードされることを防ぎ、他のドメインからの悪意のあるコード実行を防止します。
このように、CSPを利用することで、外部の不正なスクリプトが埋め込まれていても、それを実行させないようにすることができるのです。
CSRFの基本的な仕組み
1. ユーザーの認証状態の利用:
- ユーザーがあるウェブサイト(例えば銀行サイト)にログインしていると、ブラウザは通常クッキーにセッション情報を保存しています。
- この状態で、ユーザーが別の悪意のあるサイト(攻撃者が用意したサイト)を訪れると、そのサイトからターゲットサイトに対してリクエストが送信されます。
2. リクエストの自動送信:
- 悪意のあるサイトは、ユーザーのブラウザを介してターゲットサイトにリクエストを送信します。
- 例えば、フォームの自動送信や画像リクエストなどの手法を使って、ユーザーが意図しない操作を実行させます。
- ブラウザは自動的にクッキーを添付するため、ターゲットサイトは正当なユーザーからのリクエストと認識して処理します。
重要なポイントの補足
1. クッキーの「抜き取り」ではない:
- CSRF攻撃は、ユーザーのクッキー情報を直接「抜き取る」ものではありません。代わりに、ユーザーの認証セッションを悪用して不正なリクエストを実行させる手法です。
- クッキー自体は攻撃者に送信されるわけではなく、ブラウザが自動的にリクエストに添付します。
2. 実行可能な操作:
- おっしゃる通り、CSRF攻撃によってユーザーの意図しない重要な操作(アカウントの変更、決済、個人情報へのアクセスなど)が実行される可能性があります。
- これにより、攻撃者はユーザーの権限を不正に利用して、さまざまな不正行為を行うことができます。
CSRF攻撃の具体例
例えば、ユーザーが銀行サイトにログインしている状態で、攻撃者が用意した悪意のあるサイトを訪れたとします。そのサイトには以下のような仕組みが組み込まれているかもしれません:
<img src="https://bank.example.com/transfer?amount=1000&to=attacker_account" style="display:none;">
この画像リクエストにより、ユーザーのブラウザは自動的にクッキーを添付して銀行サイトにリクエストを送信します。銀行サイトは認証済みのセッションとしてこれを処理し、意図しない送金が実行されてしまいます。
CSRF対策
CSRF攻撃を防ぐための主な対策として、以下の方法が挙げられます:
-
CSRFトークンの利用:
- サーバー側で一意のトークンを生成し、フォームやリクエストに含めます。
- サーバーは受信したリクエストのトークンを検証し、一致しない場合はリクエストを拒否します。
-
SameSite属性のクッキー設定:
- クッキーに
SameSite属性を設定することで、クロスサイトからのリクエストにクッキーを添付しないように制限します。
- クッキーに
-
Refererヘッダーの検証:
- リクエストの
Refererヘッダーを検証し、正当なサイトからのリクエストであることを確認します。
- リクエストの
-
ユーザー操作の確認:
- 重要な操作を行う際に、ユーザーに再認証を求めるなどの追加確認を行います。
まとめ
CSRF攻撃は、ユーザーの認証セッションを悪用して意図しない操作を実行させる攻撃手法です。ユーザーのクッキー情報を直接盗むものではありませんが、認証状態を利用して不正なリクエストを実行させる点で非常に危険です。適切な対策を講じることで、CSRF攻撃のリスクを大幅に低減することが可能です。
[classNameとインラインstyleの使い分け]
- 基本的にはCSS Modulesを使用してまとめる
- 適用するプロパティが1〜2程度 であればインラインstyle or tailwindで対応
(メソッドの抽出 と メソッドのインライン化 のようなものをイメージ)
- Vite
- esbuild
- Vitest
- Playwright
はい、role属性に指定できるロール名は、**WAI-ARIA(Accessible Rich Internet Applications)**の仕様で定義された特定のものに限られています。
ロール名の規則と使用法:
-
定義されたロールのみを使用:
role属性には、WAI-ARIAで定義されたロール名のみを指定できます。カスタムのロール名を作成することはできません。 - ロールの目的:これらのロールは、要素の機能や目的を支援技術(例:スクリーンリーダー)に伝えるために使用されます。
-
例:
-
role="button":要素をボタンとして扱います。 -
role="navigation":ナビゲーション領域を示します。 -
role="dialog":ダイアログボックスを表します。
-
主なロールの一覧:
-
ランドマークロール(ページ全体の構造を示す)
bannernavigationmaincomplementarycontentinfo
-
ウィジェットロール(インタラクティブな要素を示す)
buttoncheckboxradioslidertabtabpanel
-
構造ロール(コンテンツの構造を示す)
articleheadinglistlistitemtablerowcell
注意点:
-
セマンティックなタグを優先する:可能であれば、
<button>や<nav>などのセマンティックなHTMLタグを使用し、role属性の使用を最小限に抑えます。これにより、アクセシビリティが自動的に向上します。 - 適切なロールを選択する:要素の機能や目的に最も適したロールを選ぶことで、支援技術が正しく要素を解釈できます。
- 無効なロール名は使用しない:定義されていないロール名を指定すると、支援技術が要素を正しく解釈できず、アクセシビリティが低下する可能性があります。
参考資料:
- WAI-ARIA 1.1 ロールの一覧:W3C公式ドキュメント
まとめ:
role属性に指定できるロール名は、WAI-ARIAで定義された特定のものに限られています。これらのロールを正しく使用することで、支援技術が要素の機能や目的を正確に理解し、アクセシビリティを向上させることができます。
role属性:
要素の役割を指定します。
セマンティックなタグが使えない場合に、その要素を特定の機能として認識させるために使用します。
aria-label属性:
要素のラベルや説明を提供します。
視覚的なテキストが存在しない、または補足情報が必要な場合に使用します。
コアの変更でテストがないものは、viewに変更かないかのチェックをする
→ viewのテストツール入れると良さそう
重要な2つの原則
- フォーム実装はreact-hook-formで統一する
- 選択モーダルは1つのフォームとして扱う
1. フォーム実装はreact-hook-formで統一する
統一された設計思想が維持できないと、大幅な手戻りにつながる可能性がある
2. 選択モーダルは1つのフォームとして扱う
フォーム内の選択モーダルには、いくつかの仕様パターンが考えられます。
- 保存ボタンを押さないとフォームに反映されない
- 保存ボタンを押さないとフォームに反映されないが
- 保存ボタンでしかモーダルを閉じられない
入力が即時にフォームに反映される
1が良い。
ここで、画面内に複数のフォームを持つことについて考えてみましょう。これは「フォームとは何か」という問いと同義です。筆者は、フォームはトランザクションに近いと考えています。ここでのトランザクションとは、SQLのトランザクションと同様に、入力を保持し、commitかrollbackされるまで反映されない一連の処理を指します。
選択モーダルとは何か?
この記事で言う「選択モーダル」とは、フォーム内で特定の入力や選択を行うために表示されるモーダルウィンドウのことを指します。例えば、ユーザーが「変更」ボタンをクリックすると表示されるクレジットカード情報の入力モーダルが該当します。
Homeと選択モーダルの関係
- Homeコンポーネント:これはReactで作成されたページ全体を表すコンポーネントです。この中にメインのフォームが含まれています。
- 選択モーダル(CreditModalコンポーネント):これはHomeコンポーネント内で使用されるモーダルウィンドウのコンポーネントです。ユーザーが特定の操作(例えば「クレジットカード情報の変更」)を行う際に表示されます。
つまり、Homeというページコンポーネントの中に、選択モーダル(CreditModal)が含まれている構造になっています。
フォームを分ける理由
この記事で強調しているのは、フォーム実装をreact-hook-formで統一し、選択モーダルを1つのフォームとして扱うことです。
なぜフォームを分けて実装するのか?
-
データの独立性を保つため:
- モーダル内の入力データは、メインのフォームに即時反映させたくない場合があります。例えば、ユーザーがモーダルで入力した内容を「保存」ボタンを押すまでメインのフォームに反映させたくない場合です。
- そのため、モーダル内で独立したフォームを作成し、入力データを一時的に保持します。
-
react-hook-formのメリットを活かすため:
- フォームをreact-hook-formで統一することで、バリデーションやパフォーマンスの最適化など、ライブラリの機能を最大限に活用できます。
- もしモーダル内で
useStateやRecoilを使ってデータを管理すると、react-hook-formのメリットを享受できなくなります。
-
トランザクション的な処理を可能にするため:
- モーダル内のフォームを1つのトランザクションと見なし、「保存」ボタンを押したときにのみデータをメインのフォームに反映(コミット)します。
- これにより、ユーザーはモーダル内での入力をキャンセル(ロールバック)することも可能になります。
まとめ
- 選択モーダルとは:フォーム内で追加の入力や選択を行うためのモーダルウィンドウ。
- Homeと選択モーダルの関係:Homeページの中に選択モーダルが組み込まれており、ユーザーはメインのフォームとモーダル内のフォームでそれぞれ入力を行います。
-
フォームを分ける理由:
- データの管理を明確にし、不要なデータの反映を防ぐため。
- react-hook-formの機能を活かし、バリデーションやパフォーマンスの最適化を図るため。
- モーダル内の操作を独立したトランザクションとして扱い、ユーザー体験を向上させるため。
要点:
- フォーム実装の統一性:全てのフォームをreact-hook-formで実装することで、チーム内での設計思想を統一し、コードの一貫性とメンテナンス性を高めます。
- 選択モーダルの扱い:モーダル内のフォームを独立させることで、入力データの管理が容易になり、ユーザーが保存を確定するまでメインのフォームに影響を与えない設計が可能になります。
この記事では、フォームの設計をシンプルかつ統一的に保つことの重要性が述べられています。特に、複雑になりがちなフォームの実装において、react-hook-formを活用し、モーダル内のフォームを独立させることで、チーム開発における混乱や手戻りを防ぐことができます。
理由の説明
データの即時反映を避けるため:
要件:モーダル内で入力したデータを、ユーザーが「保存」ボタンを押すまで親フォームに反映させたくない。
問題点:親フォームのregisterをモーダル内の入力フィールドに適用すると、モーダル内での入力変更が即座に親フォームの状態に反映されてしまいます。これは、ユーザーが「保存」を押す前からデータが親フォームに入ってしまうことを意味し、要件に反します。
フォーム状態の独立性を保つため:
モーダルを独立したフォームとして扱うことで、モーダル内の入力値を独自に管理できます。これにより、モーダル内のバリデーションやエラーメッセージも独立して扱えます。
親フォームとモーダルのフォームが混在すると、状態管理が複雑になり、バリデーションやエラーハンドリングも一貫性を失う可能性があります。
ユーザー体験の向上:
ユーザーがモーダル内で入力をキャンセルしたい場合、モーダルを閉じるだけで親フォームへの影響を避けられます。
モーダル内の操作を完了(「保存」をクリック)するまで、親フォームは変更されないため、ユーザーにとって予期せぬデータの変更が起こりません。
具体的なシナリオでの問題点
親フォームのregisterをモーダルに渡すと:
モーダル内の入力フィールドは親フォームの状態と直接連携します。
ユーザーがモーダル内で入力を始めると、その値は即座に親フォームのwatchやgetValuesで取得可能になります。
これは、「保存」ボタンを押す前にデータが反映されることになり、要件と矛盾します。
独立したuseFormをモーダル内で使用すると:
モーダル内の入力値はモーダル内のフォーム状態にのみ保持されます。
ユーザーが「保存」を押したときに、onSubmitハンドラーで親フォームのsetValueを使用して、必要なデータだけを親フォームに渡します。
これにより、データの反映タイミングを明確に制御できます。
技術的なポイント
react-hook-formの特性:
registerはフォームフィールドをreact-hook-formの状態に登録します。
フォームフィールドの値が変更されると、その値は即座にreact-hook-formの内部状態に反映されます。
setValueの活用:
モーダル内で独立したフォームを使用し、handleSubmitでデータを受け取ります。
親フォームのsetValueを使って、必要なデータを親フォームの状態に設定します。
Thought for 13 seconds
ご質問ありがとうございます。
結論から言うと、親フォームのregisterをモーダルに渡すことは技術的には可能ですが、この場合は適切ではありません。
理由の説明
データの即時反映を避けるため:
要件:モーダル内で入力したデータを、ユーザーが「保存」ボタンを押すまで親フォームに反映させたくない。
問題点:親フォームのregisterをモーダル内の入力フィールドに適用すると、モーダル内での入力変更が即座に親フォームの状態に反映されてしまいます。これは、ユーザーが「保存」を押す前からデータが親フォームに入ってしまうことを意味し、要件に反します。
フォーム状態の独立性を保つため:
モーダルを独立したフォームとして扱うことで、モーダル内の入力値を独自に管理できます。これにより、モーダル内のバリデーションやエラーメッセージも独立して扱えます。
親フォームとモーダルのフォームが混在すると、状態管理が複雑になり、バリデーションやエラーハンドリングも一貫性を失う可能性があります。
ユーザー体験の向上:
ユーザーがモーダル内で入力をキャンセルしたい場合、モーダルを閉じるだけで親フォームへの影響を避けられます。
モーダル内の操作を完了(「保存」をクリック)するまで、親フォームは変更されないため、ユーザーにとって予期せぬデータの変更が起こりません。
具体的なシナリオでの問題点
親フォームのregisterをモーダルに渡すと:
モーダル内の入力フィールドは親フォームの状態と直接連携します。
ユーザーがモーダル内で入力を始めると、その値は即座に親フォームのwatchやgetValuesで取得可能になります。
これは、「保存」ボタンを押す前にデータが反映されることになり、要件と矛盾します。
独立したuseFormをモーダル内で使用すると:
モーダル内の入力値はモーダル内のフォーム状態にのみ保持されます。
ユーザーが「保存」を押したときに、onSubmitハンドラーで親フォームのsetValueを使用して、必要なデータだけを親フォームに渡します。
これにより、データの反映タイミングを明確に制御できます。
技術的なポイント
react-hook-formの特性:
registerはフォームフィールドをreact-hook-formの状態に登録します。
フォームフィールドの値が変更されると、その値は即座にreact-hook-formの内部状態に反映されます。
setValueの活用:
モーダル内で独立したフォームを使用し、handleSubmitでデータを受け取ります。
親フォームのsetValueを使って、必要なデータを親フォームの状態に設定します。
まとめ
親フォームのregisterをモーダルに渡すことは可能ですが、要件に適していません。
モーダルを独立したフォームとして扱うことで、データの反映タイミングや状態管理を明確に制御できます。
これにより、ユーザーが「保存」ボタンを押すまでデータが親フォームに反映されないという要件を満たせます。