Sentryを使ったLLM監視
はじめに
大規模言語モデル (LLM) は膨大なテキストデータをもとに学習される技術で、自然言語を巧みに処理できる点が特長です。
近年では、あらゆる分野でLLMの導入が進み、モデルのパフォーマンスを常に確認するモニタリングが非常に重要になっています。
モニタリングを行うことで、ユーザーの求める回答が返っているかを評価し、運用ミスによるリスクを低減することが可能です。
本記事では、LLMモニタリングの概要と、Sentryを活用したLLMの監視について解説します。
LLMモニタリングとは
LLMモニタリングとは、大規模言語モデルの動作や成果物をモニタリングし、モデルが本来の目的を満たしているかを評価する行為を指します。
以下のような点を中心に監視を行うのが一般的です:
- 応答の品質 (正確性や一貫性)
- レイテンシ (推論にかかる時間)
- コスト (APIの呼び出しやリソース利用の費用)
- セキュリティや倫理面における不備
LLMモニタリングを通じて性能の最適化や誤回答の検知などを行い、ビジネスやサービスに適した安全かつ正確なモデル運用を実現します。
参考: What is LLM Observability and LLM Monitoring?
SentryのLLMモニタリング機能
Sentryは、主にアプリケーションのエラー追跡やパフォーマンス監視に用いられてきましたが、LLMを対象とした機能も提供しています。
具体的には、LLMやAIパイプラインの呼び出し状況やパフォーマンスを記録・可視化し、コストが想定以上に膨らんだ際にアラートを出すといった仕組みが利用可能です。
主な機能としては:
- プロンプトやトークンの使用状況のトラッキング
- リアルタイムアラート (コスト上限超過時など)
- 監視データのダッシュボードでの可視化
があります。
ユースケース例
- ユーザーから「LLMを使ったワークフローで問題がある」と報告があり、実際にどこで不具合が起きているのかをLLMのレスポンスを含めてチェックしたい。
- 毎日の使用料金が特定の金額を超えた場合に、担当者がすぐに知るためのアラートを設定したい。
- ユーザーから「LLMを使った処理が遅い」と報告された際に、ワークフローのどの部分に遅延が発生しているのか特定したい。
参考: Sentry LLM Monitoring - UseCase
利用料金
- Teamプラン: 月額26ドル (データ保持期間は7日)
- Businessプラン: 月額80ドル (データ保持期間は90日)
使用方法
セットアップ
今回は、Python SDKを使ってSentryのLLMモニタリングを実装します。
1. プロジェクトの作成
公式ドキュメントの手順に沿って、PythonのSentryプロジェクトを作成します。
2. AIパイプラインを設定
今回はLangChainなどのフレームワークを使わず、OpenAIのライブラリを直接呼び出します。
以下のようにコードを用意し、SentryのLLMモニタリング機能を有効化しましょう。
import os
from dotenv import load_dotenv
import sentry_sdk
from openai import OpenAI
from sentry_sdk.ai.monitoring import ai_track
from sentry_sdk.integrations.openai import OpenAIIntegration
# .envファイルから環境変数を読み込み
load_dotenv()
# Sentryの初期化
sentry_sdk.init(
dsn=os.getenv("SENTRY_DSN"),
enable_tracing=True, # トレースの有効化
# ref: https://docs.sentry.io/platforms/python/data-management/data-collected/#llm-inputs-and-responses
send_default_pii=True, # LLMの入力や応答データ収集を許可
)
@ai_track("GPT-3.5 Pipeline")
def generate_response(prompt: str) -> str:
"""GPT-3.5を使用してレスポンスを生成する"""
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
)
return completion.choices[0].message.content
def main():
prompt = "AIとは何ですか?簡単に説明してください。"
with sentry_sdk.start_transaction(op="ai-inference", name=f"GPT-3.5 Inference"):
response = generate_response(prompt)
print(f"回答: {response[:100]}...\n")
print("-" * 50)
if __name__ == "__main__":
main()
上記で注目すべき設定は次の4点です:
- enable_tracing: トレースを有効化
- send_default_pii: LLMのログを収集できるようにする
- start_transaction: 1つの大きな処理のまとまりをトレース可能にする
- ai_track: AI関連の関数を記録するためのデコレータ
LangChainのような専用フレームワークを導入する場合は、ai_trackの設定を省略しても自動的にトラッキングしてくれるそうです。
参考:
実際のLLMモニタリングの確認
コードを実行した結果をSentryの画面から確認します。
ダッシュボード
ここでは、期間内に使用したトークン数、コスト、推論時間、処理実行回数などが一目で把握できます。

トレースデータ
SPAN IDをクリックすると、詳細なトレースデータを参照できます。
各ステップにかかった時間や処理の内容などが分かるため、ボトルネックの特定や使用状況の分析に役立ちます。

ざっくりですが、以下のような構成になっています。
- ai.inference: 推論全体を管理する大枠の処理
- ai.pipeline: 実際のAIパイプライン処理
- ai.chat_completions.create.openai: OpenAIへのHTTPリクエスト
ai.inference
全体の実行時間と各ステップの実行時間が確認できます。

全体の実行時間は2.07秒で、各処理の内訳としてhttp.clientが2.04秒(49%)、ai.chat_completions.create.openaiが13.75ms(9%)、ai.pipelineが10.41ms(0%)、subprocess関連の処理が合計7.67ms(0%)となっています。
ai.pipeline
使用されたトークン数等が確認できます。
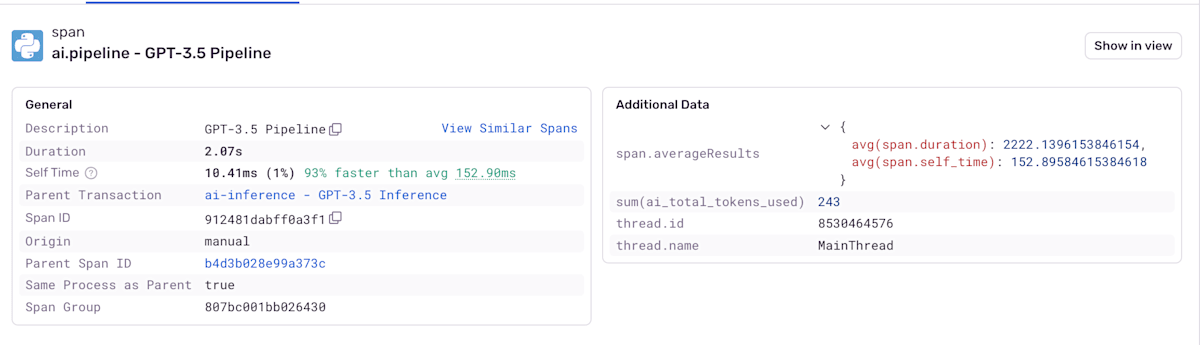
ここでは、GPT-3.5 Pipelineの実行状況が確認できます。処理時間は2.07秒で、平均より93%高速でした。
また、使用された合計トークン数は243、スレッドはMainThreadとして実行されています。
ai.chat_completions.create.openai
OpenAI APIとのやり取りの詳細が確認できます:

-
インプットメッセージ:
- ユーザーからの質問「AIとは何ですか?簡単に説明してください。」
- メッセージのロール(user)とコンテンツが記録されています
-
レスポンス:
- アシスタントからの詳細な説明
- AIの定義、機械学習やディープラーニングについての説明
- ロール(assistant)とコンテンツが記録されています
-
トークン使用の内訳:
- プロンプトトークン:26トークン
- 補完トークン:217トークン
- 合計:243トークン
-
コスト:
- 0.0003385ドル(約0.05円)
これらのデータは、APIの使用状況を監視し、コストを追跡する上で非常に重要な指標となります。
まとめ
SentryのLLMモニタリング機能を利用することで、LLMがどのように動いているかを俯瞰的に把握し、必要に応じて改善を行う仕組みを整えやすくなります。
特に、コスト管理やトークン使用量をリアルタイムでトラッキングする機能は、ビジネス上の予算管理にも大いに有用です。
ぜひSentryを活用し、LLMの安定稼働と品質向上を実現してください!
Discussion