PythonでEDINETにある有価証券報告書のhtmからMD&A情報を抽出しcsv形式で保存する方法
この記事は10分程で読むことができます!
Pythonで有価証券報告書のテキスト情報の1つであるMD&A情報をcsvデータに保存する方法をレクチャーしていきます。
今回の記事は、筆者の実証分析のデータ収集の工程で行われたものです。
有価証券報告書に限らず様々なテキストデータの収集し分析を行う際の参考になれればと考えています。
この記事ではMD&A情報を収集するための、
- EDINETからhtmファイルを取得する
- 取得したデータを挿入し、Docker上でjupyternotebookを起動する
- MD&A部分を抽出し、csvデータにて保存する
といった、流れをみていきます。
それでは一緒に学んでいきましょう!
EDINETからhtmファイルを取得する
今回は手動で有価証券報告書のデータを取得していきます!
用語の解説
取得の前に、前提知識となる用語を先に説明していきます。
有価証券報告書とは
有価証券報告書(ゆうかしょうけんほうこくしょ)とは、金融商品取引法で規定されている、事業年度ごとに作成する企業内容の外部への開示資料である。略して有報(ゆうほう)と呼ばれることもある。
ウィキペディア: 有価証券報告書
有価証券報告書は企業の年単位での決算などの情報が記載されているものです。(四半期で公開されるものは四半期報告書です。)
余談ですが、企業分析の激推しのWebアプリケーションとしてバフェットコードがあリます。筆者も良く利用しています。
MD&Aとは
MD&AとはManagementDiscussion and Analysisの略称であり3)、企業の業績・財政状態から戦略に関する情報などを単純な数値ではなく、経営者の視点から見たナラティブな文章による記述情報をいう。
SEC基準採用企業のMD&A情報と株式市場の反応 伊藤(2016)
MD&Aは、企業の財政状態などの内容が記載されており財務以外の情報として重宝されます。
EDINETとは
EDINETは、金融商品取引法上で開示用電子情報処理組織と呼ばれる、内閣府の使用するホストコンピューター・提出会社の使用するコンピューター・金融商品取引所(及び金融商品取引業協会)のコンピューターを結んだ、同法に基づく開示文書に関する電子情報開示システムである。
ウィキペディア: EDINET
EDINETは有価証券報告書を管理するシステムです。
EDINETで検索する
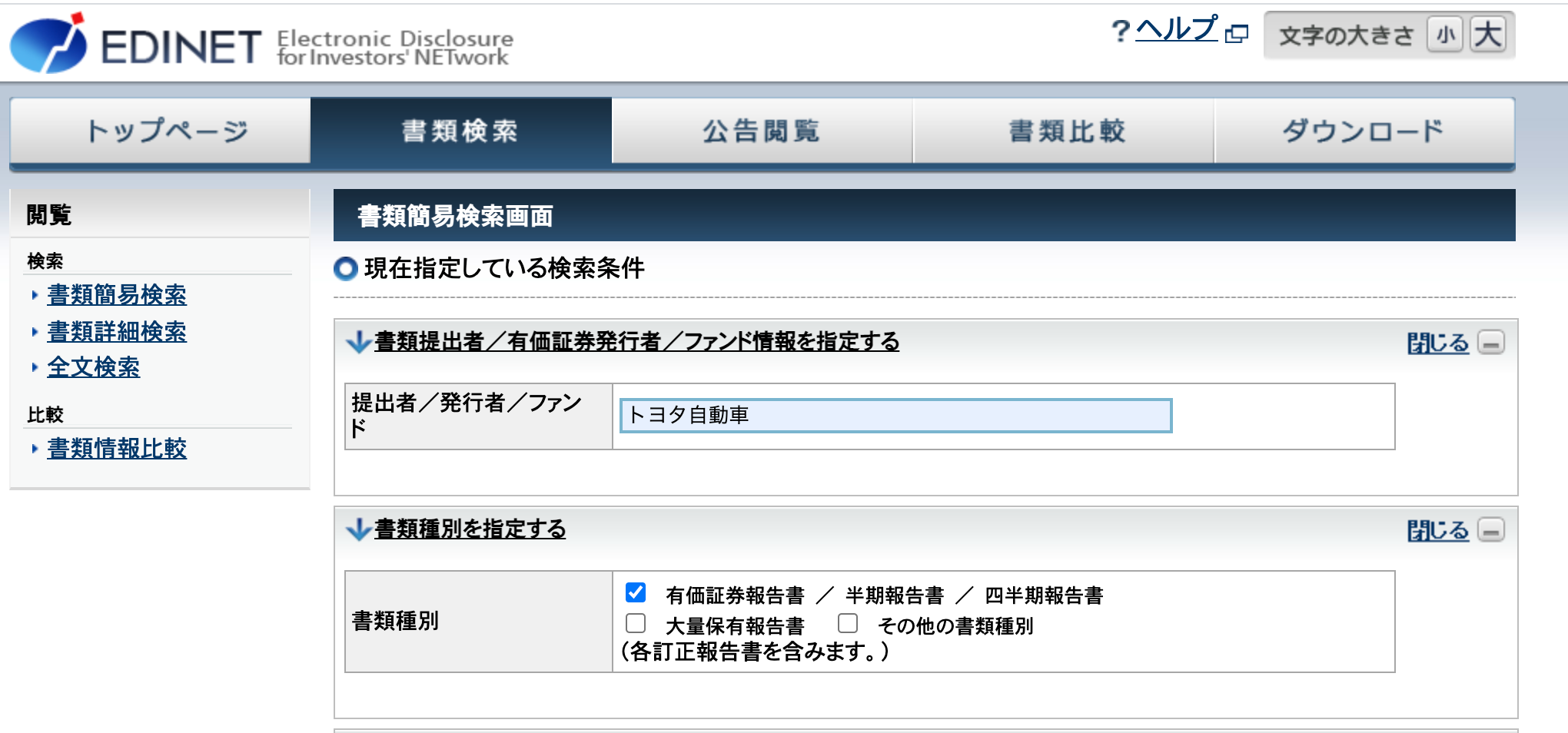
EDINET-書類検索に移動し、任意の企業名を選択します。
今回は「提出者/発行者/ファンド」という項目で"トヨタ自動車"と記入しました。
また、「書類種別」という項目で"有価証券報告書"を選択しました。
検索します。
データをダウンロードする
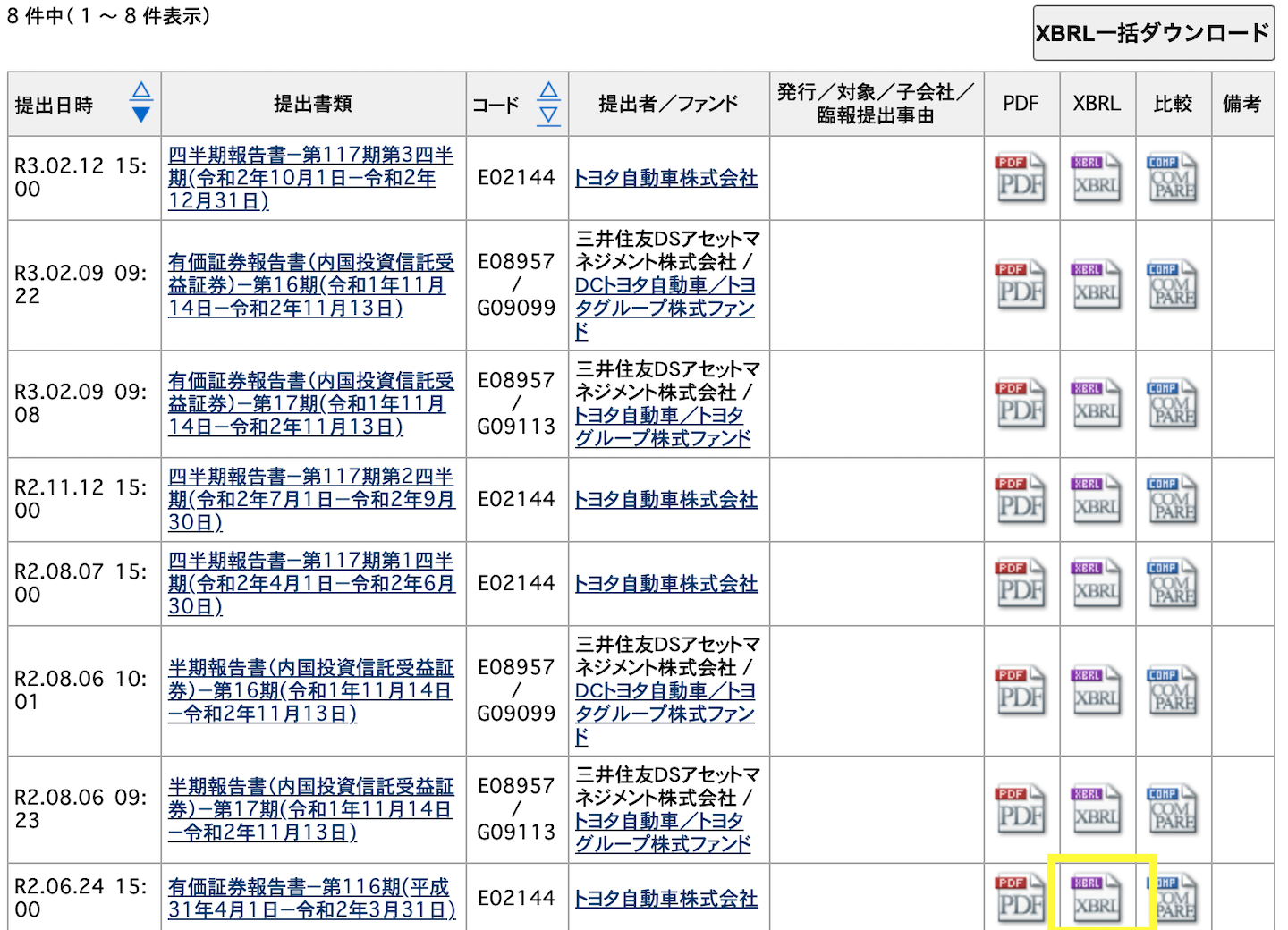
試しにひとつデータを取得しましょう。
今回は検索結果の一番下にあるXBRLというボタンをプッシュしダウンロードします。
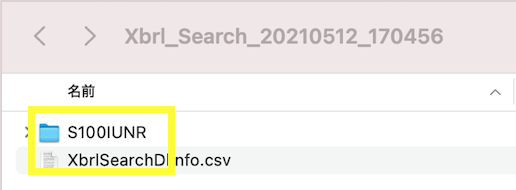
ダウンロード後、黄色で囲ったコードが振られているフォルダがあることを確認します。(振られているコードは取得したXBRLフォルダによって異なります。)
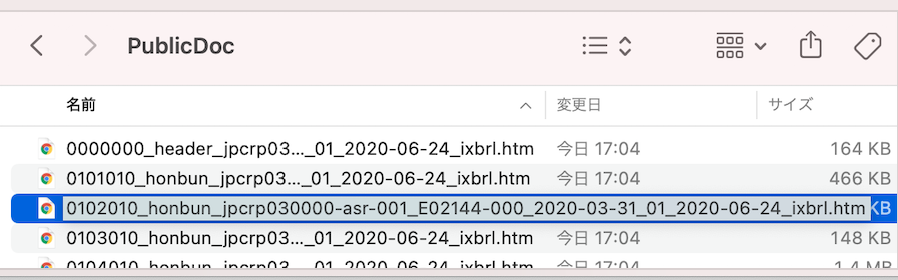
上記のフォルダの階層の下にいくとPublicDocというフォルダがあります。その中に有価証券報告書のデータがあります。
上から3番目にあるフォルダがMD&A情報が記載してあるhtmファイルです。
htmファイル懐かしいですね。
データを確認する
上記のhtmにアクセスするとこのような画面が表示されます。

MD&Aは事業の状況の項目内に記載されています。(後半の章で説明します)
取得したデータを挿入し、Docker上でjupyternotebookを起動する
試しにひとつデータを取得しましたので、このデータを元にテキスト情報のみを取得していきます。
jupyternotebookを起動させる準備をする
自分で好きな作業ディレクトリを作成し移動します。
その後、下記のようなファイル構成を作成し、jupyternotebookを起動できるようにします。
.
├── docker-compose.yml
└── src
└── data
└── 取得したhtm形式のMD&A情報が記載されたファイル
上から順番にdocker-compose.yml, src, data(以下のリソース)についてみていきます。
docker-compose.ymlに関しては、下記のようなコードを記載します。
version: "3"
services:
notebook:
image: jupyter/scipy-notebook
container_name: notebook
ports:
- "8888:8888"
volumes:
- "./src:/home/jovyan/work"
command: start-notebook.sh --NotebookApp.token=''
こちらは、ローカル環境でjupyternotebookを最低限起動させるためのコードです。
コンテナを起動後は"localhost:8888"でjupytenotebookrにアクセスすることができます。
また、volumesでsrc以下をコンテナにマウントさせています。
これを行うことで、dataフォルダにあるMD&Aファイルをjupyternotebookに読み込ませることができます。
srcに関しては、docker-compose.ymlと同じ階層に作成します。
先程の説明のようにマウント(jupyternotebookコンテナとローカル環境でファイルを共有)するフォルダとして利用します。
data(以下のリソース)に関しては、srcの下の階層で作成します。
jupyternotebook上でのファイルの読み込み元として利用します。
これにて、jupyternotebookの起動の準備ができました!
コンテナを立ち上げ、jupyternotebookを起動する
docker-composeコマンドでコンテナを起動させます。
今回はgolangベースの"docker compose up"を使用せずに普通のコマンドを打ちます。
docker-compose-up -d
起動に成功し、"localhost:8080"にアクセスすると、こちらの画面が表示されます。
dataフォルダと同じ階層にて、Python3が動くファイル(ipynb形式)を新規作成します。
その後、先程取得したhtmファイルを、BeautifulSoupライブラリにて取得します。
下記のようなコードをjuypyternotebookのセルに記載し実行します。
import os
from bs4 import BeautifulSoup
htm = open(os.getcwd()+'/data/<取得したhtmファイル>')
sp = BeautifulSoup(htm, "html.parser")
sp
実行すると、htmファイルがjupyternotebookにて出力されていることが確認できます!

こちらからMD&A情報部分の取得に取り掛かります!
MD&A部分を抽出し、csvデータにて保存する
MD&Aの部分の抽出に入ります!
冒頭の通り、今回はxbrlファイルではなくhtmからMD&Aの情報を抽出します。
取得にあたってどの部分をMD&A情報とするか検討する
取得にあたって、どの部分をMD&A情報とするか検討します。
MD&A取得は以下の部分がポイントになります。
- どの章をMD&Aの記述部分とみなすか
- 記述部分とみなした章の中でテキスト情報に当たるものはどれか
どの章をMD&Aの記述部分とみなすかに関して、今回は有価証券報告書のテキスト分析:経営者による将来見通しの開示と将来業績 加藤,五島(2020)を参考にします。
8ページの記載部分によると、
本稿では、章立て変更前後の同じ部分のテキストを分析対象とするため、( i ) 2017 年度以前の章立て変更前については、「1【業績等の概要】」、「2【生産・仕入、受注及び販売の状況】」、「3【対処すべき課題】」、「7【財政状態、経営成績及びキャッシュ・フローの状況の分析】」の 4 つの章のテキストを MD&A の記述とみなし、(ii) 2017 年度については上記 ( i ) の「3【対処すべき課題】」の代わりに「3【経営方針、経営環境及び対処すべき課題等】」を分析対象に含め、(iii) 2018 年度以降の章立て変更後については、「1【経営方針、経営環境及び対処すべき課題等】」と「3【経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析】」の 2 つの章のテキストを MD&Aの記述とみなして分析を行った。
引用: 有価証券報告書のテキスト分析:経営者による将来見通しの開示と将来業績 加藤,五島(2020)
と記載されていました。
こちらを軸に、取得したデータからMD&A情報となる章を指定します!
また、記述部分とみなした章の中でテキスト情報に当たるものはどれかに関しては、下記の画像の通り、smt_textという属性が含まれているタグ内の文章のみをテキスト情報とします!

2つのポイントを抑えたところでデータを抽出します!
BeautifulSoupでMD&A情報を取得する
BeautifulSoupでMD&A情報を抽出していきます。
今回私が収集したデータは2020年のものですので、「1【経営方針、経営環境及び対処すべき課題等】」と「3【経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析】」の 2 つの章を取得します。
新しいセルで下記のコードを書き、1【経営方針、経営環境及び対処すべき課題等】を取得します。
md_a_1 = sp.find('body').div.contents[3]
md_a_1
他の有価証券報告書のフォーマットが違う場合、3番目に番号指定をしても1【経営方針、経営環境及び対処すべき課題等】が取得されない可能性があります。一旦はこちらで進めます。
今回は、bodyタグの中のdivの子要素をリスト形式で呼び出しています。
そして、list型のcontentsプロパティの3番目を指定すると取得できます。
詳しい処理の動きに関しては Beautiful Soup 日本語訳を見ると理解できます。

同様に、3【経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析】も取得していきますが、1,3の章を一気に取得するために、新しいセルで下記のコードを書きます。
import bs4
def extract_md_a_contents(htm_contents: list) -> list:
#MD&A情報を持つ章を抽出
md_a_contents = []
for content in htm_contents :
#bs4.element.Tag型ではないとfindメソッドでtypeエラーを起こすため判定
if not isinstance(content, bs4.element.Tag) :
continue
found = content.find(class_=re.compile("smt_head"))
#findしたけどデータがない(s4.element.Tag型ではない)がない場合.textプロパティを呼び出す際にtypeエラーを起こすため判定
if not found :
continue
title = found.text
#md_aの章番号を指定
# "1【経営方針、経営環境及び対処すべき課題等】",
# "3【経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析】"
#企業によって全角と半角か別れる可能性があるためどちらも判定
if title[0] in ['1', '1','3', '3'] :
md_a_contents.append(content)
return md_a_contents
#list型でMD&Aの見出し以下を子要素にもつモノ
htm_contents = sp.find('body').div.contents
md_a_contents = extract_md_a_contents(htm_contents)
md_a_contents
今回は引用を元に if title[0] in ['1', '1','3', '3'] :と指定していますが、番号の変更に左右されないように、文字列のマッチで判定をしたほうがいいかもです。
必要な章のみを抽出することができました!

pandasでcsvデータとして保存をする
抽出したMD&Aの章の配列をpandas.DataFrame型に格納し、csvデータとして保存します。
新しいセルで下記のコードを書き、pandas.DataFrame型に格納します。
import re
import pandas as pd
def insert_df(md_a_contents: list) -> pd.DataFrame:
md_a_df = pd.DataFrame()
for content in md_a_contents :
# テキスト情報を持つbs4.element.Tag型のみ取得
found_values = content.find_all(class_=re.compile("smt_text"))
# テキストを取得
text_values = list(map(lambda val: val.text,found_values))
tmp_df = pd.DataFrame()
tmp_df['Text'] = text_values
#pandas.DataFrame型に入れる
md_a_df = pd.concat([md_a_df, tmp_df], axis=0)
return md_a_df
md_a_df = insert_df(md_a_contents)
md_a_df
格納することができました!

そして、csvデータとして保存します。
新しいセルで下記のコードを書き、csvに保存します。
import os
def save_md_a_df_to_csv(md_a_df: pd.DataFrame, ticker: int) -> None :
#Sampleフォルダの作成
filepath = os.getcwd() + "/Sample"
if not os.path.exists(filepath) :
os.mkdir(filepath)
md_a_df.to_csv(filepath + "/" + f'{ticker}.csv')
def read_md_a_csv(ticker: int) -> pd.DataFrame:
filepath = os.getcwd() + "/Sample"
return pd.read_csv(filepath+"/" + f'{ticker}.csv', index_col=0)
# #証券コード
ticker = 8364
save_md_a_df_to_csv(md_a_df, ticker)
df = read_md_a_csv(ticker)
df
データを保存し、読み込むことができました!

全体を通し、EDINETにある有価証券報告書のhtmからMD&A情報を抽出しcsv形式で保存するまでの流れをみていきました!
追加情報
追加情報として、より良いMD&A情報の取得をするために複数のファイル読み込みの方法を紹介します。
こちらは、今後forループなどでMD&A情報をcsvに保存を複数企業でまとめて一気におこないたい時に使います。
import os
# 読み込み
import glob
# パスで指定したファイルの一覧をリスト形式で取得. (ここでは一階層下のtestファイル以下)
htm_files = glob.glob(os.getcwd()+'/data/*htm')
htm_files
今後htmファイルを複数用いる時に便利です。
まとめ
この記事ではMD&A情報を収集するための、
- EDINETからhtmファイルを取得する
- 取得したデータを挿入し、Docker上でjupyternotebookを起動する
- MD&A部分を抽出し、csvデータにて保存する
といった、流れをみていきました。
csvデータの保存後は、形態素処理したり分類したり...と色々夢が広がりますね〜!
ここまで読んでくださりありがとうございました。
こちらが今回使用したサンプルのレポジトリです⇩⇩⇩
今後としては、EDINET APIを利用してhtmファイルを取得するまでの流れや、取得する際に決算月などによる企業の絞り込みの自動化などをしたいです!
データ収集が進み次第記事を更新していきます!💪
追記(2022/05/04)
今回の記事の分析フローの完全版を公開します!
元々のモチベーションだった実証分析の研究が終わりましたので、そちらで利用したコードを自身の論文とともに記載しました。
ぜひ使ってみてください!💪-> MDandAAnalysisFlow
Discussion