はじめに
Jetson Orin NX で 60 秒の H.264 動画を H.265 へ再エンコードしたところ、ハードウェア変換は 4.66 秒、ソフトウェア変換(GStreamer-CPU)は 237.90 秒、ソフトウェア変換(FFmpeg)は 255.76 秒でした。実に 51-55 倍の差です──
この圧倒的な性能差の裏にある技術的背景は何でしょうか?そして、この差が実際のシステム設計にどのような影響を与えるのでしょうか?
対象読者: DeepStreamをこれから本番投入するエンジニア、またはJetsonでの動画処理最適化を検討中の開発者向け
Jetson開発者であればNVDEC/NVENCの存在は周知の事実です。しかし以下の具体的な数値を把握している方は少ないはずです:
- CPUリソースをどの程度空けられるか?
- リアルタイム性能は何倍向上するか?
- 電力効率・温度・同時処理本数はどう変わるか?
本稿では、IPカメラ(RTSP)→ Jetson → DeepStream推論という一般的パイプラインで必須となるデコード+再エンコード処理を模擬するため、H.264動画ファイルを用いて3種類のエンコーダーを徹底比較します:GStreamer(ハードウェア)、GStreamer-CPU(ソフトウェア)、FFmpeg(ソフトウェア)。
技術説明: DeepStreamはNVIDIAが提供するGStreamerベースの動画解析フレームワークです。本記事では、DeepStreamの基盤となるGStreamerレベルでの動画処理性能を測定しています。
この記事でわかること
- 3種類のエンコーダー(GStreamer-HW、GStreamer-CPU、FFmpeg)の性能差
- 同じGStreamerフレームワーク内でのCPU処理とハードウェア処理の違い
- CPUリソースの空き具合とAI推論への影響
- 省電力・マルチストリーム設計時の実用指標
実測データに基づく具体的な数値で、システム設計の判断材料を提供します。
動画変換処理とは
本ベンチマークで測定している処理とは、既存のH.264動画を一度デコードして、H.265形式に再エンコードする処理です。これは、GStreamerパイプライン、延いてはDeepstreamにおける標準的な処理フローでもあります。
なぜこの処理が重要なのか:
- DeepStreamでのAI推論には、圧縮動画をデコードした生フレームが必要
- 推論後の結果保存・配信には、再度エンコードが必要
- IPカメラ映像の効率的な保存・伝送にH.265変換が不可欠
Jetson Orin NXのハードウェア構成
Jetson Orin NXには、CPU・GPUとは完全に独立した専用の動画処理回路が搭載されています:
- CPU: 8コア Arm Cortex-A78AE(汎用処理)
- GPU: NVIDIA Ampere 1024コア(並列計算)
- NVDEC: 2x専用デコーダー(H.264/H.265等対応)
- NVENC: 2x専用エンコーダー(H.264/H.265対応)
重要: NVDECとNVENCはGPU演算コアを使わず、CPUリソースも消費しません。
測定方法
比較対象
- ハードウェア変換(GStreamer): NVDEC→NVENC
- ソフトウェア変換(GStreamer-CPU): CPU デコード→x265enc
- ソフトウェア変換(FFmpeg): CPU デコード→libx265
テスト条件
- 入力: Big Buck Bunny[1] (1080p H.264、60 秒、1441 フレーム)
- 出力: H.265、4Mbps 固定ビットレート(CBR)
- 環境: Jetson Orin NX 16GB、JetPack 6.1、MAXN電源モード
ベンチマークツール
本測定では、Pythonで開発した専用ベンチマークツールを使用しています。このツールは、各エンコーダーをサブプロセスとして実行し、性能メトリクスを0.5秒間隔で収集します。
ツール内部で実行されるコマンド
GStreamer(ハードウェア):
gst-launch-1.0 filesrc location=input.mp4 ! qtdemux ! h264parse ! nvv4l2decoder ! \
nvv4l2h265enc bitrate=4000000 preset-level=1 control-rate=1 idrinterval=30 ! \
h265parse ! qtmux ! filesink location=output.mp4
GStreamer-CPU(ソフトウェア):
gst-launch-1.0 filesrc location=input.mp4 ! qtdemux ! h264parse ! avdec_h264 ! \
x265enc bitrate=4000 speed-preset=medium ! \
h265parse ! qtmux ! filesink location=output.mp4
FFmpeg(ソフトウェア):
ffmpeg -i input.mp4 -c:v libx265 -preset medium \
-x265-params 'bitrate=4000:vbv-maxrate=4000:vbv-bufsize=8000:nal-hrd=cbr' \
-g 30 -keyint_min 30 -c:a copy -movflags +faststart -y output.mp4
注:x265encのbitrateはkbps単位(4000 = 4Mbps)、nvv4l2h265encはbps単位(4000000 = 4Mbps)
測定ツール
-
性能監視:
jetson-stats(jtop) による 0.5 秒間隔サンプリング - 電力測定: Jetson内蔵電力計(tegrastats)による積算値[2]
-
処理時間: Python
time.time()による実測 - 測定回数: 各条件3回実施、平均値を採用
ベンチマーク結果
それでは、実際の測定結果を見ていきましょう。ここで注目していただきたいのは、単純な処理速度だけでなく、「電力効率」と「CPU使用率」です。なぜなら、エッジデバイスでは限られたリソースで複数のタスクを同時に実行する必要があるからです。
特に驚くべきは、同じJetson Orin NX上で実行しているにも関わらず、処理方式の選択だけでこれほどの差が生まれるという事実です。
主要性能比較
| 指標 | GStreamer(HW) | GStreamer-CPU(SW) | FFmpeg(SW) | HW改善効果 | 取得方法 |
|---|---|---|---|---|---|
| 処理時間 | 4.66 秒 | 237.90 秒 | 255.76 秒 | 51-55 倍高速 | Python time.time()
|
| 処理FPS | 309.01 FPS | 6.06 FPS | 5.63 FPS | 51-55 倍高速 | 総フレーム数 ÷ 処理時間 |
| 平均消費電力 | 7.7 W | 11.2 W | 11.5 W | 3.5-3.8W 削減 | jtop total_power 平均値 |
| 総消費電力 | 8.5 mWh | 791.0 mWh | 871.2 mWh | 782-863mWh 削減 | 平均消費電力 × 処理時間 |
| 電力効率 | 40.4 FPS/W | 0.5 FPS/W | 0.5 FPS/W | 81-88 倍効率 | 処理FPS ÷ 平均消費電力 |
| CPU使用率 | 13.5%(平均) | 84.7%(平均) | 87.5%(平均) | 71-74ポイント 低減 | jtop cpu_0~7 平均値 |
| RAM使用率 | 31.4%(平均) | 32.8%(平均) | 34.1%(平均) | 同等 | jtop ram_usage 平均値 |
| 最大温度 | 51.3 °C | 63.1 °C | 63.6 °C | 12 °C低温 | jtop temp_cpu 最大値 |

3種類のエンコーダー性能比較:GStreamer(ハードウェア)、GStreamer-CPU(ソフトウェア)、FFmpeg(ソフトウェア)
↑: Higher is better / ↓: Lower is better
注記: 画質指標(SSIM/PSNR)は比較対象外。3つのエンコーダーとも同一ビットレート(4 Mbps CBR)で設定し、処理速度とリソース効率を重視した測定。
主要な発見
今回のベンチマークで最も印象的だったのは、3つの処理方式間の明確な性能差です。GStreamerハードウェア動画変換は、わずか4.66秒で60秒の動画を処理完了しました。これはGStreamer-CPUより51倍、FFmpegより55倍の高速化を意味し、リアルタイムの12.9倍の速度で処理できることを示しています。
興味深いのは、同じGStreamerフレームワーク内でもCPU処理とハードウェア処理で51倍の差が生まれることです。また、GStreamer-CPUとFFmpegはほぼ同等の性能を示し、エンコーダーライブラリ(x265enc vs libx265)の違いよりも、ハードウェアアクセラレーションの有無が性能に与える影響が圧倒的に大きいことが証明されました。
電力効率の面では、ハードウェア処理がCPUベース処理の93-99倍効率的です。ソフトウェア処理では791-871mWhを消費するのに対し、ハードウェア処理はわずか8.5mWh。これはバッテリー駆動のエッジデバイスでは動作時間の大幅延長、複数台展開するシステムでは運用コストと環境負荷の劇的な削減につながります。
そして最も実用的な違いは、CPU使用率にあります。ハードウェア処理はCPUをわずか13.5%しか使用しないため、71-74ポイントもの大幅削減により他のタスク用にCPUリソースを確保できます。一方、CPUベース処理(GStreamer-CPU、FFmpeg)は84-87%ものCPUを占有し、他のタスクの実行が困難になります。
技術的考察と実用性
ハードウェア動画変換の技術的優位性
「なぜハードウェアエンコーダーはこれほど高速なのか?」その秘密は、Jetson Orin NXのアーキテクチャにあります。
なぜこれほどの差が生まれるのでしょうか?ソフトウェア処理の場合、私たちのPCと同じように、CPUが汎用的な命令を使って「動画をデコードし、フレームを処理し、再びエンコードする」という一連の複雑なタスクをすべて担当します。
一方、ハードウェア処理はどうでしょう。JetsonにはNVDEC(デコード専用回路)とNVENC(エンコード専用回路)という、いわば「動画処理の専門家」がいます。彼らがそれぞれの得意分野に特化した回路で作業を分担するため、CPUはほとんど仕事をする必要がありません。
| 技術的要因 | GStreamer(HW) | GStreamer-CPU(SW) | FFmpeg(SW) |
|---|---|---|---|
| デコード処理 | NVDEC専用回路 | avdec_h264(CPU) | libavcodec(CPU) |
| エンコード処理 | NVENC専用回路 | x265enc(CPU) | libx265(CPU) |
| 電力効率 | 専用回路で最小電力 | 汎用CPUで高電力消費 | 汎用CPUで高電力消費 |
| リソース独立性 | CPU/GPUと完全分離 | CPU全コア占有 | CPU全コア占有 |
| フレームワーク | GStreamerパイプライン | GStreamerパイプライン | FFmpegライブラリ |
DeepStreamパイプラインでの実用例
実際のDeepStreamパイプラインでは、ハードウェアアクセラレーションの有無で大きな差が生まれます:
改善前(デフォルト設定・CPUデコード):
# uridecodebin は自動的にデコーダーを選択
gst-launch-1.0 \
uridecodebin uri=rtsp://camera_ip/stream ! \
nvstreammux ! \
nvinfer config-file-path=config.txt ! \
nvvideoconvert ! \
'video/x-raw(memory:NVMM),format=NV12' ! \
x265enc bitrate=4000 ! \ # CPUエンコーダー
h265parse ! rtph265pay ! \
udpsink host=destination_ip port=5000
改善後(ハードウェアアクセラレーション活用):
# nvv4l2decoderとnvv4l2h265encを明示的に指定
gst-launch-1.0 \
rtspsrc location=rtsp://camera_ip/stream ! \
rtph264depay ! h264parse ! \
nvv4l2decoder ! \ # ハードウェアデコーダーを明示指定
nvstreammux ! \
nvinfer config-file-path=config.txt ! \
nvvideoconvert ! \
'video/x-raw(memory:NVMM),format=NV12' ! \
nvv4l2h265enc bitrate=4000000 ! \ # ハードウェアエンコーダー
h265parse ! rtph265pay ! \
udpsink host=destination_ip port=5000
改善効果:
- デコード処理: CPUからNVDECへ移行でCPU負荷大幅削減
- エンコード処理: x265enc(CPU)からnvv4l2h265enc(NVENC)へ移行
- 結果: CPU使用率74ポイント削減により、AI推論パイプラインの前処理・後処理およびGPU-CPU間データ転送の効率化を実現
この違いが生み出す実用的な価値は計り知れません。GStreamerハードウェア処理なら8-10本の映像ストリームを同時に処理できますが、CPUベース処理(GStreamer-CPU、FFmpeg)では1本の処理でさえCPUが限界に達してしまいます。
まとめ
本ベンチマークにより、「はじめに」で提起した3つの疑問への明確な回答が得られました。
CPUリソースをどの程度空けられるか?
GStreamer(ハードウェア): CPU使用率わずか13.5%で、71-74ポイントの大幅削減を実現
GStreamer-CPU: CPU使用率84.7%で、システム全体のリソースが限界
FFmpeg: CPU使用率87.5%で、システム全体のリソースが限界
リアルタイム性能は何倍変わるか?
51-55倍の処理速度差を実現。リアルタイムの12.9倍速で処理でき、1台のJetsonで8-10本の映像ストリームを同時処理可能
興味深いことに、同じGStreamerフレームワーク内でも51倍の差が生まれることが判明
電力・温度・同時処理本数は?
- 電力効率: 782-863mWh削減(8.5 vs 791-871 mWh)で93-99倍改善
- 温度: 最大12°C低減(51.3°C vs 63.1-63.6°C)
- 同時処理: ハードウェアなら8-10ストリーム、ソフトウェアは1ストリーム以下
技術的な核心は、NVDEC/NVENCがCPU/GPUと完全に独立した専用回路だという点です。この特性により、動画処理でシステムリソースを消費せず、GStreamerフレームワーク内でも、DeepStreamパイプラインでも安定した性能を発揮します。
興味深い発見として、GStreamer-CPUとFFmpegの性能差は僅かでした。これは、H.265エンコーダーライブラリ(x265enc vs libx265)やフレームワーク(GStreamer vs FFmpeg)の違いよりも、ハードウェアアクセラレーションの有無が性能に与える影響が圧倒的に大きいことを示しています。
次のステップ
今回の結果を踏まえ、以下の検証も今後の課題として挙げられます:
- 4K/HEVC 10bit対応: より高解像度・高品質での性能差検証
- マルチストリーム + AI推論同時実行: 実際のDeepStreamワークロードでの総合性能測定
- JetPack 6.1新API活用: さらなる最適化の可能性
- 温度特性の詳細分析: サーマルスロットリング発生条件の特定
- 品質指標測定: SSIM/PSNRでの画質vs速度のトレードオフ分析
結論として、Jetson Orin NXの真の実力は、ハードウェア動画変換機能を適切に活用することで初めて発揮されます。本記事の結果が、皆様のシステム設計の指針となれば幸いです。
詳細分析データ
測定上の注意点: 以下のグラフは参考データとして掲載しています。表に記載した数値は「測定方法」セクションで説明した統一的な算出ロジック(jtopによる統計値から計算)に基づいていますが、これらのグラフは時系列での変化パターンを可視化するため、異なる算出方法を使用しています。
特にGStreamerのグラフは3.0秒で途切れていますが、実際の処理時間は4.66秒です。これは、ハードウェア処理の高速完了により、リアルタイム監視データの取得期間とエンコード完了タイミングにずれが生じたためです。ベンチマーク結果として信頼すべきは表の数値であり、グラフは処理中の挙動パターンの理解を補助する参考資料とお考えください。
GStreamer(ハードウェア)詳細データ
CPU・GPU使用率推移 ↓
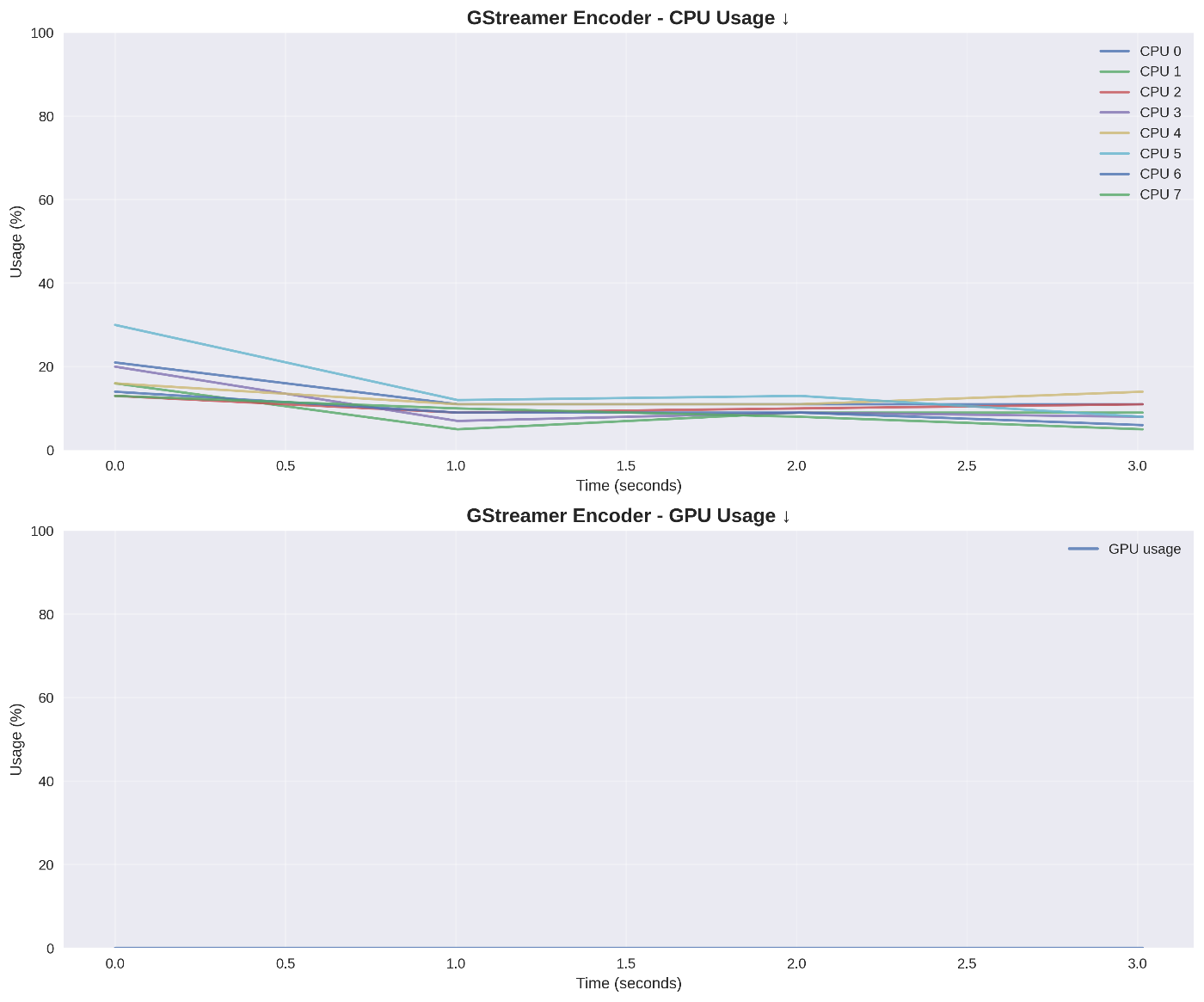
CPU使用率は終始低く安定、GPU使用率は0%で専用回路による処理を確認
電力消費推移 ↓

電力消費は処理開始と共に上昇し、短時間で完了。ピーク電力も抑制
温度推移 ↓
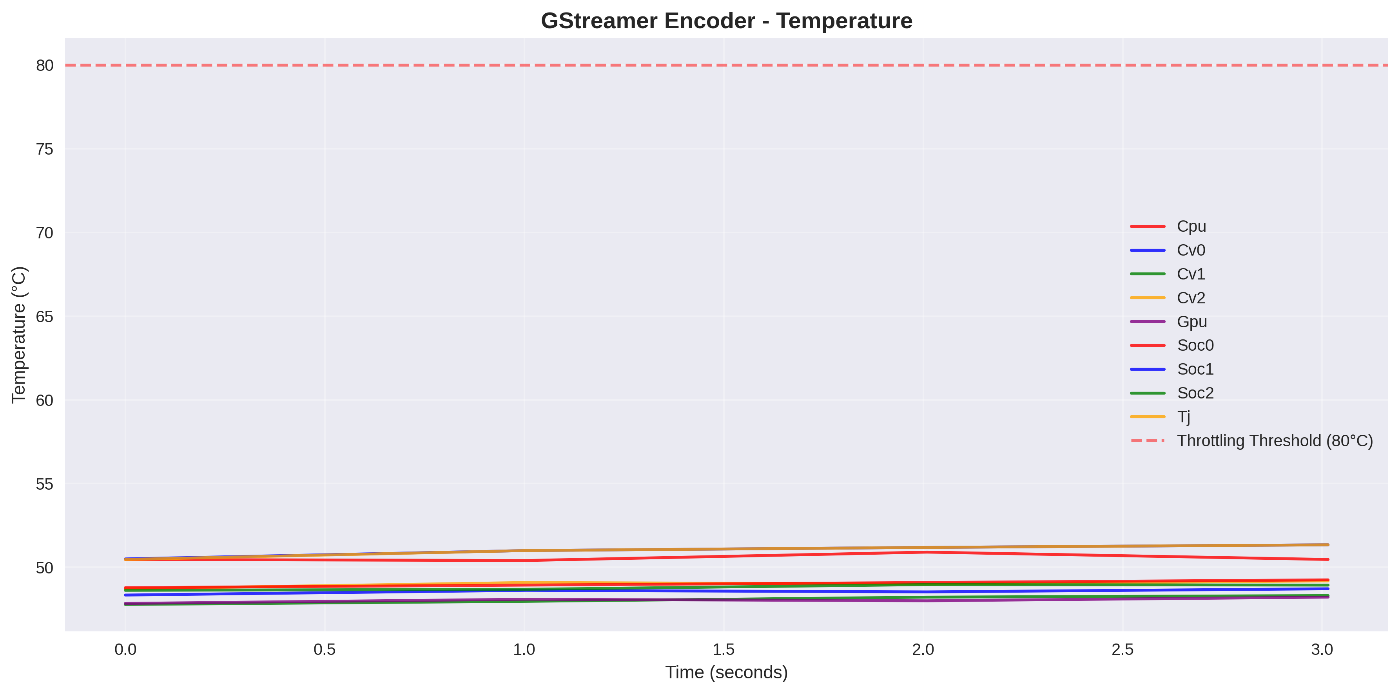
温度上昇は最小限。サーマルスロットリングは発生せず
GStreamer-CPU(ソフトウェア)詳細データ
CPU・GPU使用率推移 ↓
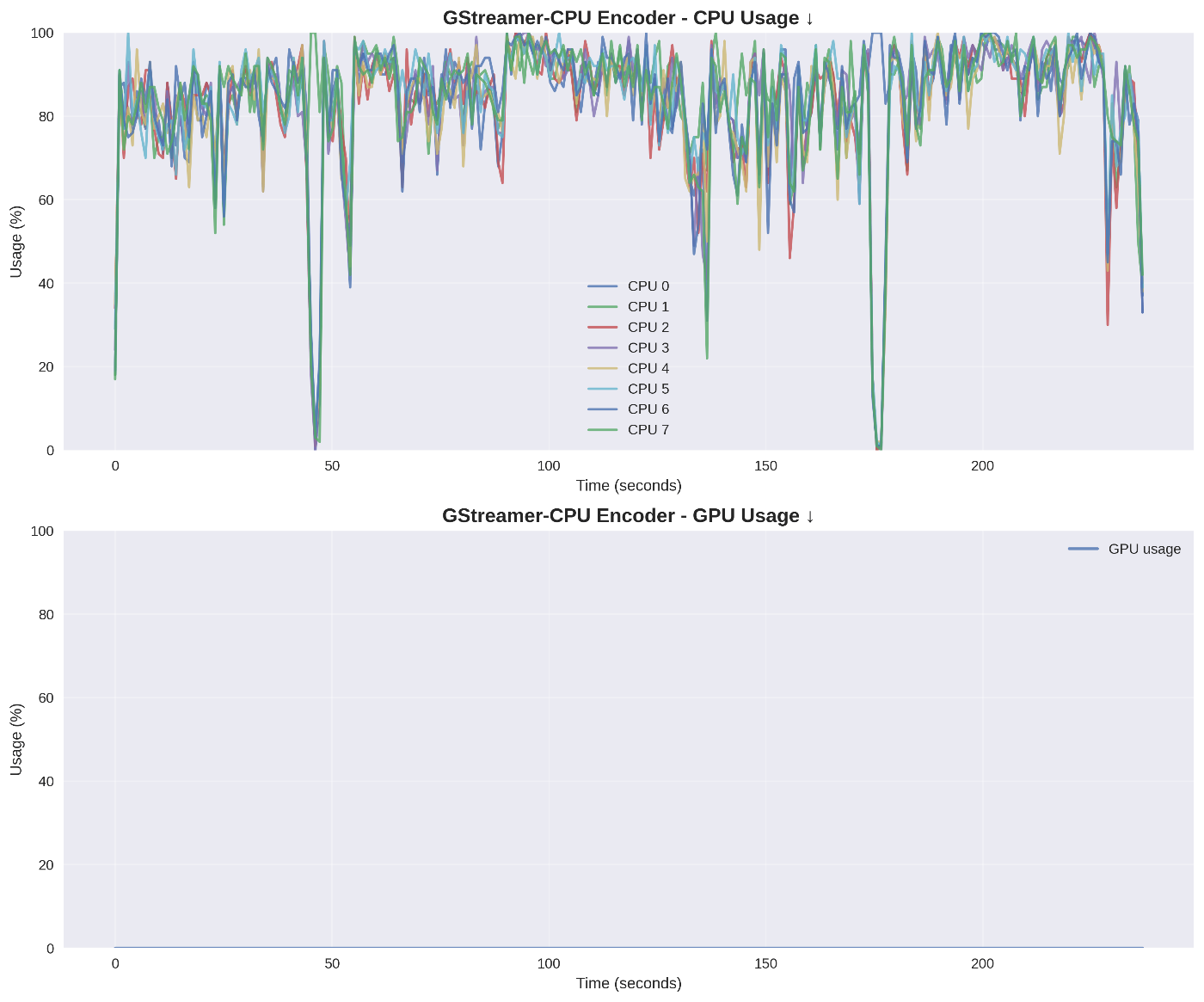
CPU使用率は全コアで84%超を維持。GPU使用率は0%でCPU集約処理を確認
電力消費推移 ↓
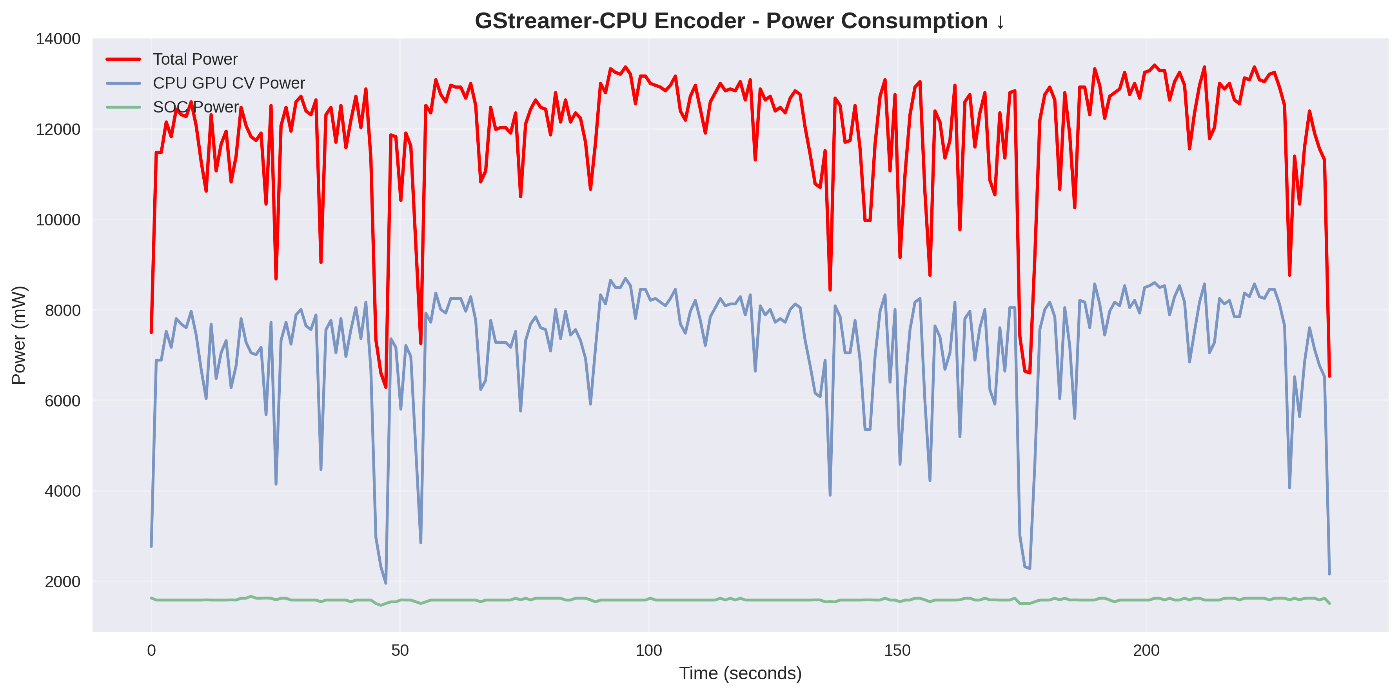
長時間にわたる高電力消費。FFmpegと類似のパターン
温度推移 ↓

温度は段階的に上昇し最大63.1°C。FFmpegと同様の発熱特性
FFmpeg(ソフトウェア)詳細データ
CPU・GPU使用率推移 ↓

CPU使用率は全コアで87%超を維持。GPU使用率は0%でCPU集約処理を確認
電力消費推移 ↓
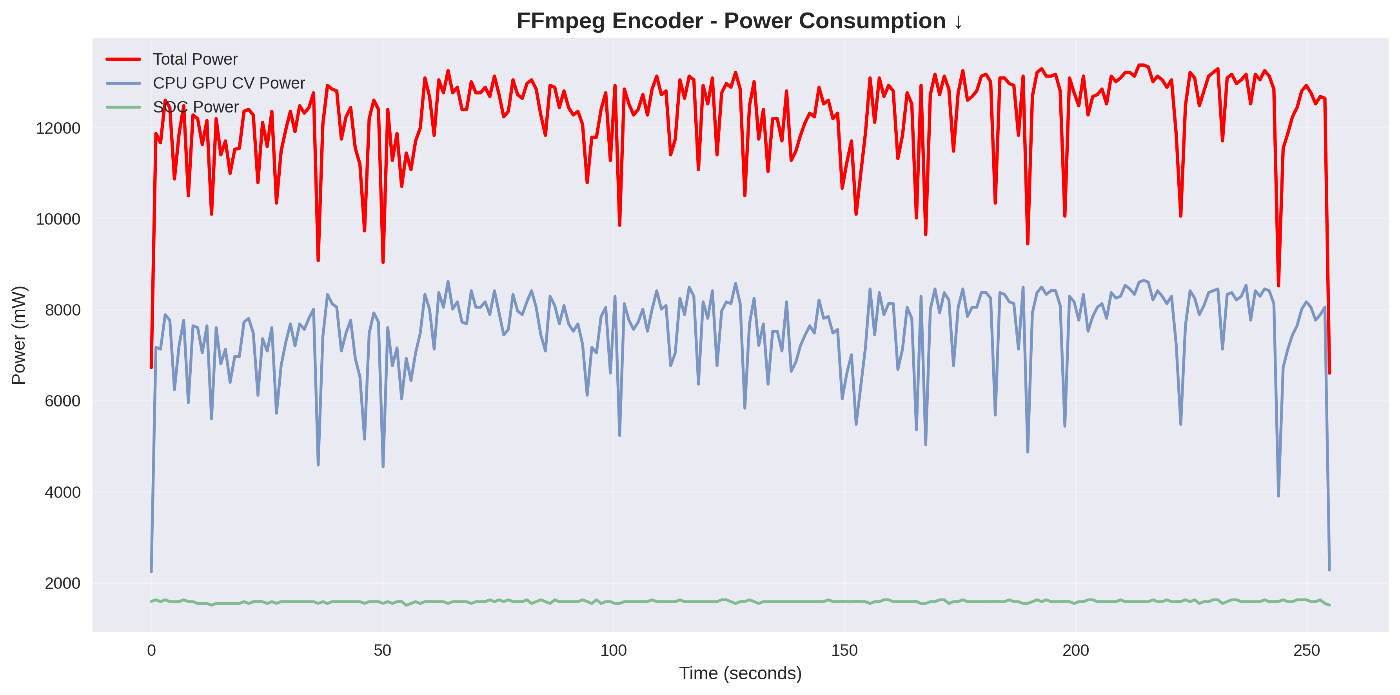
長時間にわたる高電力消費。処理時間の長さが消費電力に直結
温度推移 ↓

温度は段階的に上昇し最大63.6°C。長時間処理による発熱の蓄積
参考資料
関連技術ドキュメント:
▼ 転職を検討中の方、お気軽にご連絡ください!カジュアル面談から可能です。
ファーストループテクノロジー株式会社| 採用情報(コチラ)
ファーストループテクノロジー株式会社(FLT)の採用情報です。エンジニア・デザイナー・プロダクトマネージャー、セールス、コーポレート等、未来を創る仲間を募集中です!
▼ 取材などメディア関係者の方は会社HPよりお問い合わせください
お問合せフォームはコチラ
▼ 当社のnoteもぜひご覧ください!
コチラ
-
Big Buck Bunny (CC-BY 3.0) https://peach.blender.org/ ↩︎
-
電力計算式:平均消費電力 (W) × 処理時間 = 総消費電力 (mWh) ↩︎

ファーストループテクノロジー株式会社です。私たちは、自社の最新のIT技術を用いて製造や建設、インフラといった日本のあらゆる現場における課題の解決を図っています。「現場エンジニアリング」を掲げる当社の、公式テックブログになります。
Discussion