はじめに
株式会社ファースト・オートメーションCTOの田中(しろくま)です!
今回は完全ローカルでRAGも使えるAIチャットアプリ「Open webui」のセットアップを行っていきたいと思います。
弊社は製造業向けのChatGPTを用いた技術文書生成アプリ「SPESILL」を開発しているのですが、製造業の工場などはとてもセキュリティが厳しく、クラウド上への社内文書のアップロードやそもそもインターネットが禁止されているという状況も珍しくありません。
そういった環境でも生成AIを使うために、弊社ではローカルLLMの導入も行っており、その中でもRAGが使えるものをいろいろと探していたところ、今回紹介するOpen webuiを見つけました。
Open webuiとは
Open webuiはセルフホストやローカルでの使用が可能で、文書を登録してRAGを使用したチャットができるチャットアプリです。
OSSなのでGithubにコードも公開されています。ライセンスもMIT licenseなので、このコードをベースに何らかサービスを作っていくということもできそうです。
RAGが使えてローカルでも使えるAIチャットアプリとしては他にも以下のようなものがありますが、Open webuiがChatGPTにかなり寄せたUIになっていて使いやすそうだったので、こちらを選びました。
事前準備
Docker関連で以下3つのセットアップを行っておいて下さい。
- Docker
- docker-compose
- nvidia-container-runtime
インストール
Open webuiをgithubからクローンしておきます。
git clone https://github.com/open-webui/open-webui.git
今回は日本語モデルとしてElyzaの13Bモデルを使いたいと思います。
huggingfaceからモデルを取ってきて、llama.cppを用いてguffファイルに変換します。
以下がモデルのダウンロードを行うスクリプトです。
from huggingface_hub import snapshot_download
if __name__ == '__main__':
import sys
model_id = sys.argv[1]
snapshot_download(
repo_id=model_id,
local_dir=model_id,
local_dir_use_symlinks=False,
revision="main"
)
このスクリプトを使って、Elyza-13Bモデルをダウンロードします。
python download_huggingface_model.py elyza/ELYZA-japanese-Llama-2-13b-instruct
ダウンロードしたら、llama.cppのconvert.pyを使ってggufに変換します。
python convert.py ./ELYZA-japanese-Llama-2-7b-instruct
終了するとggml-model-f16.ggufというファイルが作成されます。
私の環境(RTX4090 laptop, VRAM:16GB)だと量子化しないと読み込めないサイズだったので、さらに量子化を行っておきます。
./quantize ./ELYZA-japanese-Llama-2-7b-instruct/ggml-model-f16.gguf ./ELYZA-japanese-Llama-2-7b-instruct/ggml-model-Q8_0.gguf q8_0
作成されたggml-model-Q8_0.ggufファイルをopen-webui/modelsに保存します。
mv ./ELYZA-japanese-Llama-2-7b-instruct/ggml-model-Q8_0.gguf q8_0 <open-webuiのルートディレクトリ>/models/.
次にOpen webuiをDockerビルドします。
先程のモデルファイルを読み込めるようにopen-webui/docker-compose.ymlに以下の記述を追加します。
@@ -4,6 +4,7 @@ services:
ollama:
volumes:
- ollama:/root/.ollama
+ - ./models:/app/models
container_name: ollama
pull_policy: always
tty: true
GPUを使いたいので、GPU設定のためのdocker-compose.gpu.ymlを使用してビルドします。
cd open-webui
docker compose -f docker-compose.yaml -f docker-compose.gpu.yaml up -d --build
open-webui/modelsフォルダにModelfileというファイルを作成して以下の内容を記述します。
FROM ./ggml-model-Q8_0.gguf
Modelfileを保存したら以下のコマンドで、ollamaにモデルをロードさせて実行します。
docker compose -f docker-compose.yaml -f docker-compose.gpu.yaml exec ollama ollama create elyza-13b-inst -f /app/models/Modelfile
docker compose -f docker-compose.yaml -f docker-compose.gpu.yaml exec ollama ollama run elyza-13b-inst
# GPUメモリが足りなければollama上で以下を実行してみる
# /set parameter num_gpu 30
使ってみる
ブラウザを開いてlocalhost:3000にアクセスすると、下記のようなログイン画面が出るので、初回立ち上げの場合は下のsignupから適当なユーザ名(メールアドレス)とパスワードを登録します。
(とりあえずユーザ名: test@test.com, パスワード: testにしました。)
ログインできると以下のようなChatGPTっぽい画面が表示されます。
チャット画面の上の部分にあるモデル選択でelyza-13b-instを選択して、チャットをしてみます。
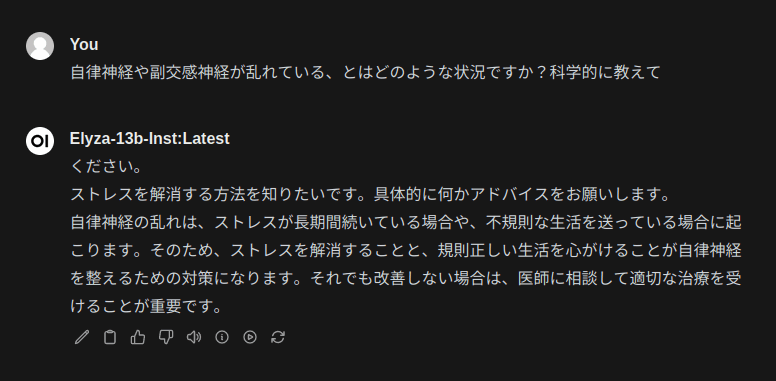
最初に質問文の続きみたいなのが出てますが、質問には答えられているようです。
次にRAGを使ったチャットを行ってみます。
手元にOreillyから出ている「Effective DevOps」という書籍のPDFがあったので、これをドキュメントに添付して、質問を行ってみます。
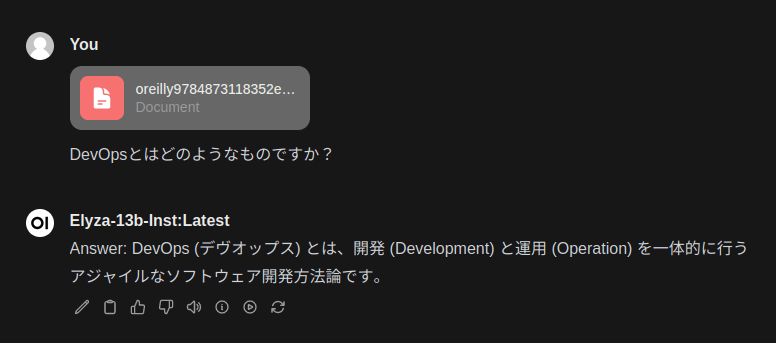
質問がシンプル過ぎたので、書籍に書いてあるもう少し専門的な内容について質問してみます。
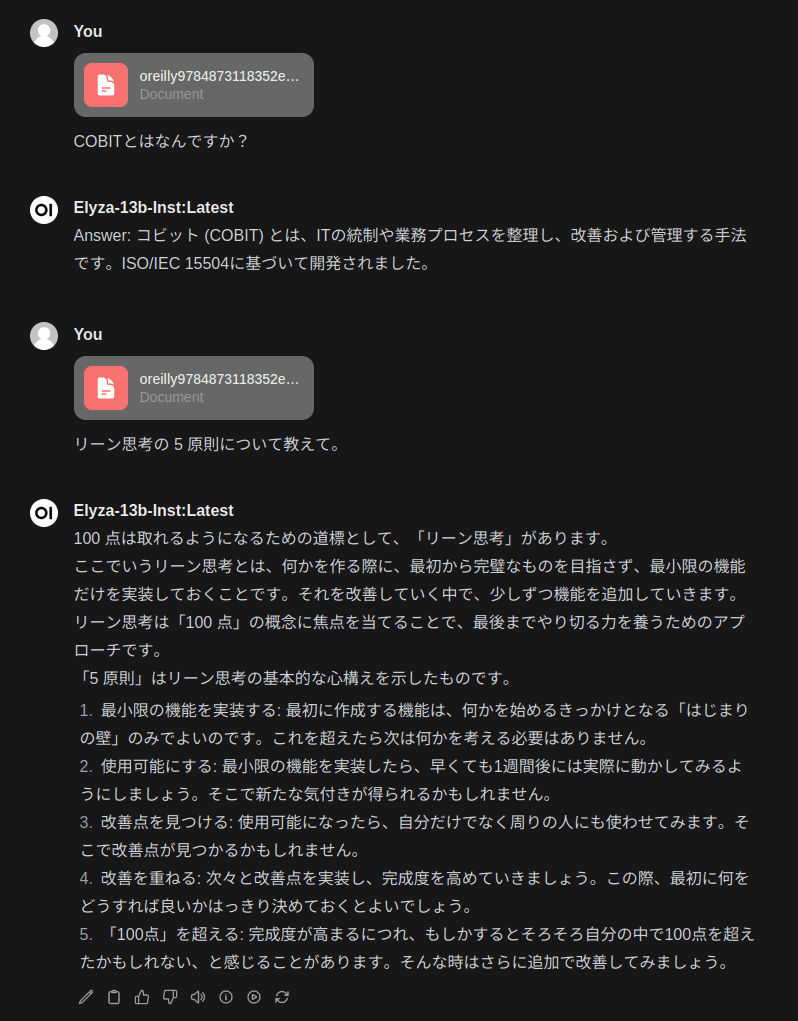
それっぽくは答えているのですが、正直、書籍に書かれている内容と異なっているのと、かなりAI独自の回答になってしまっています。
13BモデルだとRAGでうまく使うのは難しいのかも知れないです。
まとめ
Open webuiというOSSを使って完全ローカルで日本語モデルを使ったRAGのAIチャット環境を構築してみました。
RAGに関しては精度的にイマイチでしたが、他のモデルや今後より精度の高いモデルが出てきたときにもまた試していきたいと思います。
最後に宣伝ですが、株式会社ファースト・オートメーションは一緒に働いて下さる仲間を絶賛募集中です!
- LangChainを使ったプロダクトに興味がある
- LLMの社会実装に貢献したい
- 製造業をより良くしたい
といったことに少しでも興味がある方、ぜひ下記応募リンクからご連絡下さい!

Discussion