この記事は、Nowcast Advent Calendar 2025 の15日目の記事です。
はじめに
こんにちは。ナウキャストでデータエンジニア/LLMエンジニアとして頑張っているTakumiです。
最近、Semantic View(Cortex Analyst)でたくさん遊んでいて、2025年12月時点における
- Semantic Viewで設定する内容
- Semantic Viewをどう整備するか
- 筆者が考えるSemantic Viewに適したデータ構造
- どこまでコードで管理して、どこからGUIで整備していくか
あたりを実感できました。
なので、この先SnowflakeでCortex Analystを使う人が参考にしてくれると嬉しいなぁと思いながら書きます。
この記事でわかること
- Semantic Viewで設定する内容の具体的な解説
- Semantic Viewを整備する時の責任範囲
- 筆者が考えるSemantic Viewに適したデータ構造
Semantic Viewそのものの説明、どうやったら構築できるか、コスト管理については説明しません。
Semantic Viewの概要 : Snowflake公式ドキュメント
Cortex Analystのコストモニタリング : Cortex Analyst のリクエスト数を用途ごとにモニタリングしよう by Hiroki Yamagishi@SimpleForm Inc
あたりを見ておくと今回書かない部分を把握できそう。
Semantic Viewの設定内容の整理
まずは、Snowflakeで自動生成してくれる項目と自動生成しない項目を整理しましょう。(2025年12月時点)
自動生成する項目
- Logical Tables
- Logical table name
- Logical table description
- Synonyms
- Dimensions
- Time Dimensions
- Facts
自動生成しない項目
- Logical Tables
- Primary Key
- Unique Key
- Named Filters
- Metrics
- Derived Metrics
- Relationships(後述のPreview機能で自動生成できるけど、追記と修正してたので一旦ここに記載)
- Verified queries
修正した項目のそもそもの意味
自動生成後に手動で追加・修正を行う項目について、実際の経験を踏まえて解説します。
Logical Table
Synonyms
テーブルやカラムに対する”別名(シノニム)”です。
自動生成でもカラム名からある程度推測してくれますが、ここには現場のユーザーが使う用語を徹底的に登録します。
例えば、MT_PRODUCTというテーブルがあったとして、これを”商品マスタ"と呼ぶのか、”プロダクトマスタ”と呼ぶのかは揺れがありますし、このテーブルの中にproduct_category_nameというカラムがあるとするとそれをそのまま”商品カテゴリ名”として使うこともあれば、部署によっては”ブランド名”として暗黙的に使っているかもしれません。
この辺の呼称については、”どのロールの人が”、”何のテーブル、カラムを”、”普段どのように呼んでいるか”をヒアリングするのが良いでしょう。
Primary KeyとUnique Key
テーブル内の主キーとユニークキーを設定するカラムを指定します。Cortex Analystに対して、それらの制約が存在することを教えるのはもちろんですが、これらを設定しないと後述のRelationshipsを設定することができません(≒JOINができない)。
そのため、Semantic Viewに与えるテーブルが一つだけ、WHERE XXX_ID in (SELECT XXX_ID from YYY)をJOINの代わりに使う、のようなユースケースを想定しない限りは設定が必要になります。
Named Filters
Logical Table 単体のみで定義が可能なFilter条件をクエリで再利用するためにここで定義します。複数のテーブル間のカラムを使ったFilterは定義できません。
ここでは以下のようなサブスク契約のトランザクションテーブルを考えます
。
例:trn_subscription(サブスク契約を管理するトランザクションテーブル)
trn_subscription
- subscription_id (PK)
- customer_id (FK → mt_customer)
- plan_id (FK → mt_plan)
- start_date
- end_date (nullable)
- subscription_type(‘FREE’, ‘PRO’, 'ENTERPRISE')
- status(‘ACTIVE’, ‘CANCELED’, ‘PAUSED’)
- cancel_reason(nullable)
- billing_amount(請求額:割引込み)
このテーブルを使うと、
- エンタープライズプランのアクティブサブスクリプション(metric名:enterprise_active)
→status=‘ACTIVE’ AND subscription_type=‘ENTERPRISE’ - プロプランのアクティブサブスクリプション(metric名:pro_active)
→status=‘PAUSED’ AND subscription_type=‘PRO’
のように、よく使うフィルタリングをテーブルごとに設定することが可能です。
Metrics
Logical Table 単体のみで定義が可能なMetricsをここで定義します。先ほどと同様複数のテーブル間のカラムを使ったMetricsは定義できません。
例:trn_support_ticket(日々の問い合わせを管理するトランザクションテーブル)
trn_support_ticket
- ticket_id (PK)
- customer_id (FK → mt_customer)
- opened_date
- closed_date
- category(例: ‘DELIVERY’, ‘BILLING’, ‘APP_ISSUE’)
- resolution_status(‘OPEN’,‘CLOSED’)
- handling_cost(1件あたりの内部コスト(目安時間))
このテーブルを使うと、
チケットの個数(metric名:ticket_count) → COUNT(*)
合計の内部コスト(metric名:total_support_cost) → SUM(handling_cost)
のように、テーブルにおける評価指標を設定することができます。
ここでは、期間などによるFilteringは検討せずに、SELECT文で使う処理を書くイメージです。
Derived Metrics
Metricsで定義したものを組み合わせた指標を組み合わせて作るMetricsを定義します。
さっきのMetricsを使うと、
チケット当たりにかかった内部コスト(derived metrics名:support_cost_per_ticket) → total_support_cost / ticket_count
のようにMetricsを組み合わせたものを定義できます。
今回はたまたま1テーブルのMetricsを複数使っていますが、複数のテーブルでそれぞれ定義したものを組み合わせて定義することも可能です。
Relationships
テーブル同士をどのカラムでJOINするかを定義します。これを教えないとJOINしてくれないので、まずやりましょう。
Verified queries
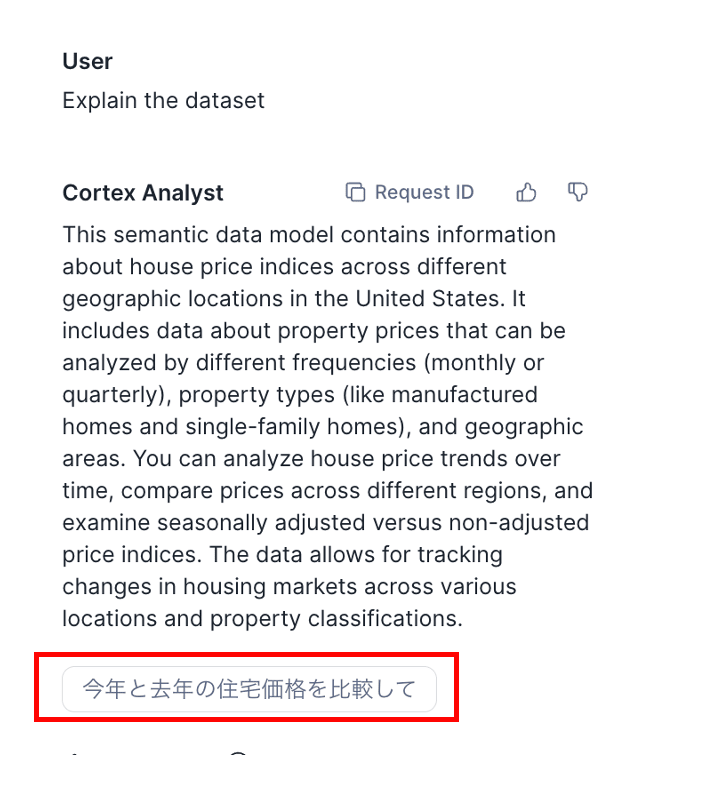
自然言語に対する正解のSQLを1対1で登録します。これを行うことで、
- 生成されるSQLの精度向上
だけではなく、 - ユーザーのサンプル質問
としても使えます。Verified Queryの登録時に、”Use as an on boarding question”とできて、初期質問の”Explain the dataset”をすると、Semantic Viewが取り扱うデータの説明に加えてサンプル質問として表示できます。

Custom Instruction
Cortex Analyst全体の振る舞いを制御する項目です。
Question categorization
ユーザーの質問に対してどう振る舞うかを指定します。特定の種類の質問に対して回答を拒絶させたり、曖昧なユーザーの質問に対してどのように条件を詳細化させるのかを定義させたりすることができます。
SQL generation
SQL生成時に考慮しなければいけないことを指定します。「”XXX”というカラムでJOINするときは、必ず前処理としてPADDINGしなきゃいけない」とか「出力する数値は必ず、小数第N位まで丸めなきゃいけない」などの質問に依らないSQL生成に関する指示を明確にできます。
筆者が考えるSemantic Viewに適したデータ
Cortex Analystを運用してみて感じた、「Cortex Analystに優しいデータ」についての私見です。
-
データの粒度は明細レベルを維持する
Semantic View(Cortex Analyst)としては明細粒度を残した状態が望ましいと感じました。
ユーザーとしては、”その時々に応じて分析の軸を変えたい”というのが普通の感情だと思います。
定点観測する指標であれば、データを集約した上でダッシュボードで見るような整理ができますがCortex Analystを使った柔軟なデータ分析についてはある程度明細を残した方が良さそうに感じました。 -
よく使う指標をテーブル構成に入れ込む
Semantic Viewにはテーブル数及びカラム数の推奨上限が存在します(テーブル数10個以下、カラム数50個以下)。
また、データ量が非常に多い場合(何億行とかの単位)にはJOINを一つ実行するだけでクエリ実行に対する待ち時間が非常に長いものになってしまいます。
それらの観点から、データマート(テーブルを事前にJOINしておく、よく使う指標は先に計算しておく等)の構築を行っておくことで、UX・運用コスト改善に繋がると感じました。(これは当然っちゃ当然) -
カラム名はビジネス用語にする
物理カラム名がcol_01のようなシステム的な名前だと、シノニムが増えすぎたり、SQLのたしからしさをユーザーが確かめる時にノイズになってしまいます。
元々のデータソースを変える必要はないですが、リネームとかの加工を施したテーブルを構築した上でSemantic Viewに与えるのが良いのだろうと思いました。
筆者が考えるSemantic Viewの整備方針
現状
自分が触った限りだと、現状のGUIではSemantic Viewのバージョン管理はできてなさそうでした。(あったらごめんなさい。)GUIでSemantic Viewを編集すると、裏ではSELECT SYSTEM$WRITE_SEMANTIC_MODEL_YAML()が動いていて、直接書き込んでいるようです。
全ての変更を細かく追える必要はないのですが、せめてSaveとかの単位でVersionを付与できると嬉しいなぁと思いました。SQL生成精度がデグレした時とか、誤って編集や削除をしてしまった時とかで、サクッと戻せる状態じゃないのはちょっときびしい。
じゃあどうするか?
現状を踏まえると、現実的な方針としては
- Semantic ViewのTerraform管理 (v2.11.0でリリースがあった)
- YamlファイルのGithub管理
- dbtの拡張パッケージ(dbt_semantic_view)を使った管理
あたりが良さそうと思っています。2は手動でやると辛いので、Yamlファイルの差分が発生したらPR作ってくれるbot的なの作らないとダメなんだろうなと思ってます。
コード管理とGUIの使い分け
では、どういう責務でコード管理とGUIによる編集を使い分けるのか。まず、前提としてSemantic Viewの項目は以下の2つに大別できると考えています。
- データモデリングを行うことで決まる項目
先に述べた項目で言うと、Logical Table, Derived Metrics, Relationshipsが当たります。 - Cortex Analystのチューニングを行うことで決まる項目
こちらはCustom InstructionとVQRですね。
結論としては、1の範囲はコードベースで管理、2の範囲はGUI上で編集してその内容を後からコードに反映する形が良いと思っています。
1. データモデリング関連はコード管理が適している理由
データモデリング関連の項目(Logical Table, Derived Metrics, Relationships)は、データ構造の変更と密接に連動します。”新しいテーブルの追加”、”既存のテーブルにカラムが追加”、”新たに評価指標を追加”などの際には、Semantic Viewの定義も同時に更新する必要があります。
このような変更は
- データパイプラインの変更と一緒にレビュー・デプロイが可能
- トライアンドエラーでやるべきではなく、チームで合意をとった上でモデリングをすべき
であるため、コードベース(Terraformやdbt)で管理するのが適していそう。
2. Cortex AnalystのチューニングはGUI管理が適している理由
一方、Custom InstructionやVerified queries(VQR)の更新は、Cortex Analystの回答精度を向上させるための試行錯誤によって発生します。
このようなチューニングは
- 質問に対する回答精度を確認しながら調整する必要がある
- 頻繁に微調整を繰り返すのでいちいちApproveもらうのが面倒(「この表現だと誤解されるから、もう少し詳しく書こう」などの修正でいちいち修正〜Approve〜適用までやるのは。。)
という理由から、GUI上で直接編集する方が効率的です。ただし、最終的にはコードに反映するルールで運用することで、再現性を担保することが重要です。
まとめ
まとめてみるとCortex Analystの活用を実現するために、エンジニアができることがたくさんありそうです。やりがいがありますね。
このドキュメントに記載の通り、VQRを登録することでFilterを足したり、Metricsを修正したりとかの機能はSnowflakeが出してくれています。ここからの進化を想像すると、クエリヒストリーから勝手にSemantic Viewを作ってくれるような機能を作ってくれるんでしょうが、そのときは自分は何してるんでしょうか,,,?
改めて、未来が楽しみです。(白目)

Discussion