Snowflake Summit 2025 : DE107 ハンズオンで SQL と Python によるデータオーケストレーションを学ぶ
こんにちは、株式会社ナウキャストでデータエンジニアをしている Bigmegaphone です。サンフランシスコで絶賛開催中の Snowflake Summit 2025 に参加しています!
本記事では、ハンズオンセッション「DE107 - Orchestrating Data Analytics Workloads with SQL and Python」に参加してきた模様を速報でお届けします。
この記事を読んで欲しい人
- 普段 Snowflake を SQL メインで使っていて、Python 連携(UDF、Procedure など)の可能性を知りたい方
- Snowpark for Python や External Access Integration といった Snowflake の機能に興味があるデータエンジニア、アナリストの方
- Python を組み込むことで、データ処理の workflow を Snowflake 内でより柔軟に構築したいと考えている方
- Snowflake Summit のハンズオンの雰囲気を知りたい方
はじめに: なぜこのハンズオンに参加したのか
近年、Snowflake は data に加えて AI/ML 分野への取り組みを強化し、Python サポートを急速に拡大しています。データロード、変換、分析といった従来の SQL 中心のワークフローに加え、Python UDF (User Defined Function)や Procedure、Snowpark API を通じた高度なデータ処理が可能になってきました。
一方、私は普段 Snowflake の SQL 機能を中心に利用しており、Python UDF や Procedure といった機能に触れる機会がありませんでした。
このハンズオンでは、Snowflake の Python サポートをフル活用して、外部 API 連携を含む実践的なデータパイプラインを構築するとのことで、SQL 中心の既存ワークフローを Python との連携によってどのように拡張・高度化できるのか、その具体的な手法と可能性を学ぶことを期待して参加しました。
ハンズオン「DE107」の概要
セッション情報
- 講演タイトル: DE107 - Orchestrating Data Analytics Workloads with SQL and Python
-
スピーカー:
- Doris Lee (Senior Product Manager, Snowflake)
- Jason Freeberg (Senior Product Manager, Snowflake)
- セッショントラック: Data Engineering & Streaming
- 講演日時: Tuesday, Jun 3, 1:30 PM - 3:00 PM PDT
セッションで学んだこと
このハンズオンラボでは、主に以下の内容を学ぶことができました。
- SQL と Python の融合: Python UDF、Snowpark DataFrame、Procedure を作成し、それらを SQL クエリにシームレスに統合する具体的な手法。
- External Access Integration: Snowflake から外部 API(このハンズオンでは OpenWeatherMap.org)にアクセスし、データを取得・活用する方法。
- 実践的な運用ノウハウ: Python コードの監視方法やトラブルシューティング戦略。
事前準備: OpenWeatherMap のアカウント作成
ハンズオン参加にあたり、事前に以下の準備を行うよう指示がありました。
OpenWeatherMap.org のアカウント作成: https://home.openweathermap.org/users/sign_up から無料アカウントを作成。 - このアカウントで取得できる API キーをハンズオン中に使用しました。
これだけで、Snowflake のアカウントや認証情報はハンズオン当日に提供されるとのことでした。実際に会場では、参加者用の sandbox が用意されていました。
ハンズオン当日の様子と体験したこと
会場は広く、かなりの人数を収容できそうでした。

ハンズオンはスピーカーの声がヘッドホンから聞こえてくる形式になっていました。ヘッドホンは青く光っていてカッコよかったです ✨
有線 LAN も USB Type-C 変換アダプタ付きで置いてあるので、通信も多少安定していました。

セッションのアジェンダはこのようになっていました。

デモは大きく 3 つに分かれており、3 つのワークシートを実行しながら、徐々に理解を深めていく形式となっていました。
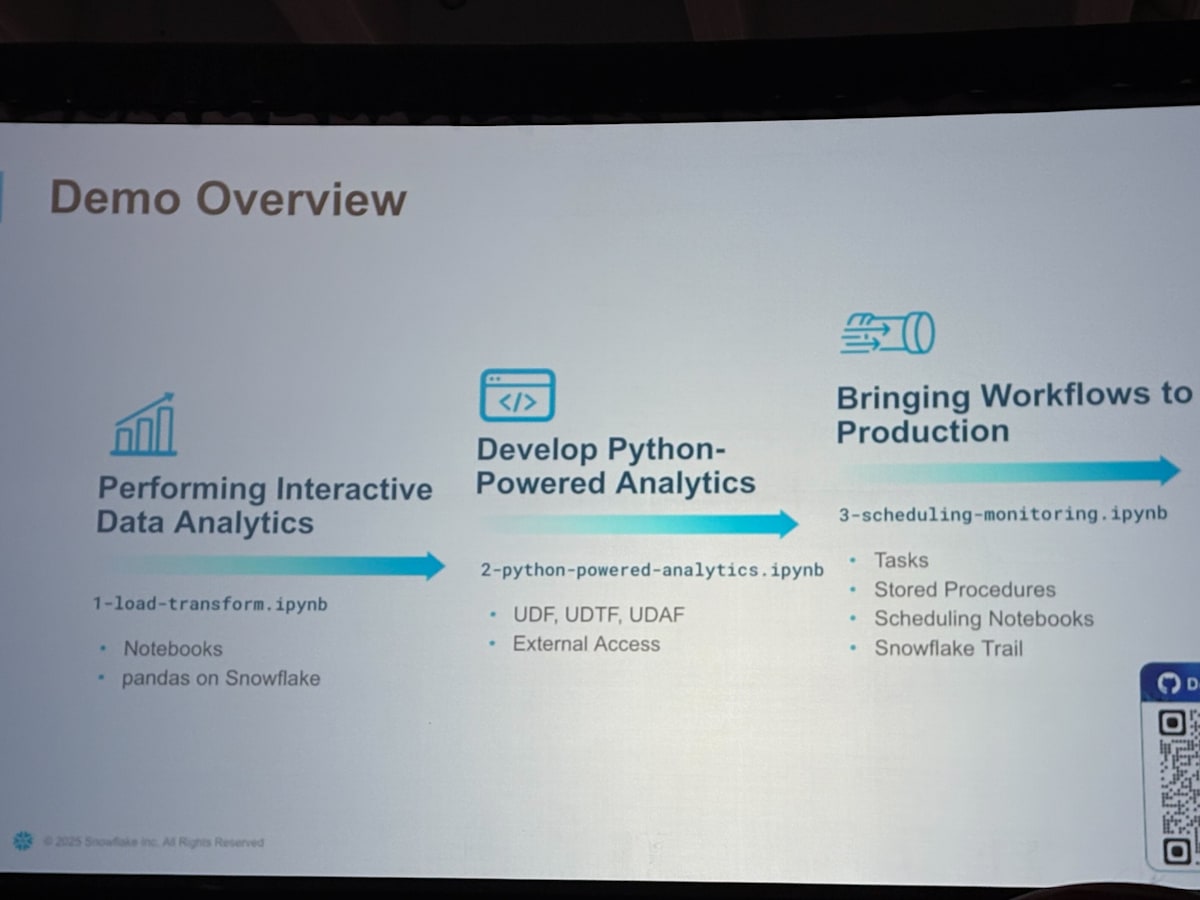
このハンズオンで使用したワークシート(Jupyter Notebook 形式)は、以下の GitHub リポジトリに公開されているため、Snowflake 環境を作成すれば、ご自身で試すことができます。
それでは、各ワークシートの内容を詳しく見ていきましょう。
ワークシート 1: Interactive Data Analytics (1-load-transform.ipynb)
このワークシートでは、主に Snowflake Notebook 環境で pandas on Snowflake (modin) を利用したインタラクティブなデータ分析を行いました。S3 上の公開データセットをロードし、データ変換や集計を行い、結果を Snowflake のテーブルに保存するまでの一連の流れを学びました。
-
データのロードと環境設定:
まず、提供された Snowflake ユーザー情報で Snowflake にログインし、Notebook から1-load-transform.ipynbを開きました。このノートブックでは、pandas on Snowflake を利用して S3 上の公開データセットからメニューアイテムの集計データをロードしました。Notebook で package を読み込みたい場合は、UI から選択する必要があります。
外部ステージを作成し、そこから CSV ファイルを読み込み、DataFrame として基本的な統計情報を確認しました。- 外部ステージの作成例:
CREATE OR REPLACE STAGE FROSTBYTES URL = 's3://sfquickstarts/frostbyte_tastybytes/'; - CSV ファイルの読み込み例 (Python):
import modin.pandas as pd # session は事前に取得済みとする menu_item = pd.read_csv("@frostbytes/analytics/menu_item_aggregate_v.csv") menu_item.head()
- 外部ステージの作成例:
-
SQL による基本的なデータ操作 (pandas on Snowflake):
次に、ロードしたデータを pandas on Snowflake の DataFrame API を使って操作しました。日付型の変換や、売上金額のような新しい列の計算、特定条件下でのデータフィルタリングや集計を行いました。最終的に加工したデータは Snowflake の新しいテーブルに保存しました。初めて python のセルを使いましたが、使い勝手は Jupyter Notebook や Google Colab と似たイメージでした。- データ変換と新しい列の作成例 (Python):
menu_item["DATE"] = pd.to_datetime(menu_item["DATE"]) menu_item["REVENUE"] = menu_item["PRICE"] * menu_item["TOTAL_QUANTITY_SOLD"] - Snowflake テーブルへの保存例 (Python):
menu_item.to_snowflake("MENU_ITEM_AGGREGATE_PYTHON", if_exists="replace")
- データ変換と新しい列の作成例 (Python):
ワークシート 2: Python Powered Analytics (2-python-powered-analytics.ipynb)
このワークシートでは、Python をさらに活用し、Python UDF の作成、Snowpark DataFrame API によるデータ操作、そして External Access Integration を利用した外部 API 連携といった、一歩進んだ内容に触れました。
-
Python UDF の作成と利用:
2-python-powered-analytics.ipynbに移り、Python UDF の作成に取り組みました。まず、顧客のメールアドレスからドメインがフリーメールプロバイダのものか企業のものかを判定する簡単な UDF を作成し、SQL クエリから呼び出しました。SQL と Python、それぞれの言語の強みを活かして目的の処理に適した方を選択できる柔軟性は魅力的だと感じました。-
Python UDF のコード例:
from snowflake.snowpark.functions import udf @udf def email_provider_type(email: str) -> str: if not email: return 'UNKNOWN' domain = email.split('@')[-1].lower() if domain in ['gmail.com', 'yahoo.com', 'hotmail.com', 'outlook.com']: return 'FREE' else: return 'CORPORATE' -
UDF を呼び出す SQL の例:
SELECT E_MAIL, email_provider_type(E_MAIL) FROM HOL_DB.PUBLIC.TASTY_BYTES_ORDERS WHERE E_MAIL != '' LIMIT 10;
-
-
Snowpark DataFrame の活用:
引き続き2-python-powered-analytics.ipynbで、Snowpark DataFrame API を本格的に活用しました。pandas ライクなメソッドチェーンでデータのフィルタリング、変換、集計などを行いました。特に、複数のテーブルを結合 (join) したり、ウィンドウ関数を使った複雑な分析も pandas を用いて行うことができることがわかりました。-
Snowpark DataFrame を使った Python コードの例:
from snowflake.snowpark.functions import col # ordersテーブルをSnowpark DataFrameとしてロード orders_df = session.table("HOL_DB.PUBLIC.TASTY_BYTES_ORDERS") # E_MAILが空でないもので、特定のメールプロバイダタイプを持つ注文をフィルタリング filtered_df = orders_df.filter(col("E_MAIL") != '').filter(email_provider_type(col("E_MAIL")) == 'CORPORATE') filtered_df.show()
-
-
External Access Integration と API 連携:
このハンズオンのハイライトの一つが、External Access Integration 機能です。2-python-powered-analytics.ipynbでは、Snowflake の外部から API を呼び出すための設定(Network Rule, Secret, External Access Integration の作成)を行い、OpenWeatherMap API から天気情報を取得する Python UDF を作成しました。これにより、Snowflake 内部のデータと外部サービスからのリアルタイムデータを簡単に組み合わせることができました。API コールは SQL では不可能なため、SQL 以外の言語が組み込まれたことにより、ワークシートが明確に拡張されたと感じました。- External Access Integration と API 連携の Python UDF 例:
# UDF内でrequestsライブラリ等を使いAPIを呼び出すイメージ # 実際のコードでは、Network RuleやSecretとの連携設定が重要 @udf(packages=['snowflake-snowpark-python', 'requests'], external_access_integrations=['MY_EXTERNAL_ACCESS_INTEGRATION'], secrets={'api_key_secret': 'MY_API_KEY_SECRET'}) def get_weather_data(city_name: str) -> str: import requests # SECRETからAPIキーを取得 api_key = _snowflake_ext_libs.get_secret('api_key_secret') # APIリクエスト (実際のURLやパラメータはAPI仕様による) response = requests.get(f"http://api.openweathermap.org/data/2.5/weather?q={city_name}&appid={api_key}") if response.status_code == 200: return response.json() else: return f"Error: {response.status_code}"
- External Access Integration と API 連携の Python UDF 例:
ワークシート 3: Bringing Workflows to Production (3-scheduling-monitoring.ipynb)
最後のワークシートでは、作成した Python ベースの処理を運用に乗せるためのステップとして、Stored Procedure の作成、タスクによるスケジューリング、そして実行される Python コードの監視方法について学びました。
-
automation of workflows using Stored Procedure:
3-scheduling-monitoring.ipynbに進み、一連のデータ処理を Stored Procedure としてまとめる方法を学びました。ここでは、顧客のロイヤルティスコアを計算する Python Stored Procedure を作成し、SQL から呼び出しました。さらに、この Stored Procedure を定期的に実行するためのタスクも作成し、データパイプラインの自動化を体験しました。-
Python Stored Procedure の作成例 (一部抜粋):
# calc_loyalty_scores という名前のPython関数を定義 (内容はノートブック参照) # session.sproc.register で登録 loyalty_sproc = session.sproc.register( calc_loyalty_scores, name='calculate_loyalty_scores', is_permanent=True, # ... 他のパラメータ ) -
Stored Procedure の呼び出し例:
CALL CALCULATE_LOYALTY_SCORES(); -
タスクによる定期実行の例 (Python API):
from snowflake.core import Root from snowflake.core.task import Cron, Task root = Root(session) tasks_collection = root.databases["HOL_DB"].schemas["PUBLIC"].tasks # 5分ごとに実行するスケジュール schedule = Cron("*/5 * * * *", "America/Los_Angeles") task = tasks_collection.create( Task( name="loyalty_score_task", definition="CALL HOL_DB.PUBLIC.CALCULATE_LOYALTY_SCORES();", schedule=schedule, warehouse="MY_WH" # 適切なウェアハウス名を指定 ), mode="orreplace" ) task.resume() # タスクを開始
-
-
Python コードの監視とトラブルシューティング:
最後に、3-scheduling-monitoring.ipynbで、Snowflake 上で実行される Python コード(UDF や Stored Procedure)の監視方法について学びました。イベントテーブルをセットアップし、ログレベルを設定することで、Python コードからのログ出力を Snowflake のログエクスプローラーで確認できることを体験しました。これにより、実行状況の把握や問題発生時のトラブルシューティングが容易になることを理解しました。- イベントテーブルとログレベルの設定例 (SQL):
ALTER ACCOUNT SET EVENT_TABLE = snowflake.telemetry.events; ALTER ACCOUNT SET LOG_LEVEL = 'INFO'; -- 必要に応じて METRIC_LEVEL や TRACE_LEVEL も設定
- イベントテーブルとログレベルの設定例 (SQL):
特に印象的だった点・学び
今回のハンズオンを通じて、特に印象に残った点や、個人的な学びをいくつか挙げます。
-
SQL と Python のシームレスな連携: Snowflake が SQL だけでなく Python も第一級の言語として扱おうとしている強い意志を感じました。UDF や Snowpark DataFrame を使うことで、それぞれの言語の得意な部分を活かしたハイブリッドな開発が可能になります。

これはハンズオン中に登場したスライドです。この図のように、SQL の堅牢性と Python の柔軟性を組み合わせることで、Snowflake はエンタープライズの多様なワークロードに対応する意思があると思いました。 -
External Access Integration の衝撃: これまで外部 API 連携は、別途 ETL ツールや Lambda などの外部サービスを準備する必要があるケースが多かったですが、Snowflake 内で完結できるようになったのは大きな進歩だと感じました。
-
「何でも Snowflake で」の現実味: データ基盤としてだけでなく、データ処理・分析アプリケーションの実行環境としても Snowflake の守備範囲が格段に広がっていることを実感しました。
まとめと今後の展望
今回の DE107 ハンズオンは、Python と SQL を併用した Notebook の今後の可能性を感じることができる時間でした。SQL の知識をベースにしつつ、Python のパワーをアドオンすることで、これまで以上に複雑で高度なデータ分析ワークフローを Snowflake 上で構築・運用できるという確信を得ました。
一方で、課題も残っていると思いました。Notebook 単体の機能は素晴らしいものの、Notebook を実行する Task 機能については、既存のクラウドベンダーが提供するオーケストレーションツールを代替しうるほどの性能や安定性がなければ、PoC での利用に限定され、本番環境での運用は難しいかもしれません。
とはいえ、本日の Keynote のように、Snowflake はさまざまな機能を開発・発表しています。これらの課題もだんだんと解消されていくと思っているので、今後の Snowflake の進化に期待が高まりますね!
Snowflake Summit も半分が終わりましたが、残りの期間も頑張ってキャッチアップします!!!
最後までご覧いただきありがとうございました。

Discussion