はじめに
こんにちは!ナウキャストのデータエンジニアのけびんです。
現在ナウキャストでは dbt-snowflake を利用して Snowflake 上で ELT パイプラインを日々開発しています。基本的には dbt の使い方を把握していれば開発は可能ですが、やはり Snowflake 特有の設定というのも存在します。本ブログでは dbt-snowflake で開発をする際に個人的に重要だと思う以下の設定についてまとめます。
- Table - Clustering
- Table - COPY GRANTS
- External Table
- Secure View
Table - Clustering
Partitioning と Clustering のおさらい
大規模なテーブルにおいて Clustering の設定はパフォーマンスを向上させるために重要です。
Partitioning とは大規模なデータを小さく管理しやすいデータに分割して保存しておく手法です。特定のカラムの値に応じてファイルを分割するということが多いです。例えば日付のカラムで Partitioning しておくと、日付に関する条件があるクエリでは Partition Pruning が可能になります。
一方 Clustering とはあるテーブル全体のデータの分布に関する話で、特定のカラムでデータをソートしておくことでテーブル全体のデータの局所性を増す(似たデータが近くに配置されるようにする)という手法です。
Snowflake では Clustering (ソート) の設定が Partitioning に直結するため非常に重要です。
Snowflake ではデータは micro partition として数百MBごとに分割して保存されますが、その作られ方としてはデータが来た順番に適宜分割されるイメージです。ソートされていないままのデータの場合、 どの micro partition にも各カラムで幅広い値のデータが分散して保存されてしまいます。一方事前にデータをソートしてからテーブルを作成するようにすると、各 micro partition にはソートで使用した列については特定の値だけ含まれるというような状況が作られるわけです。
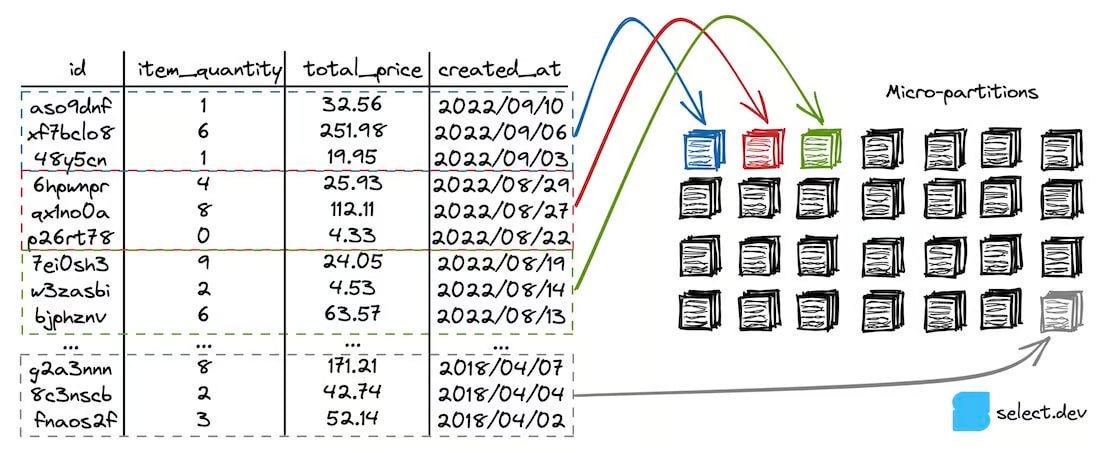
https://select.dev/posts/snowflake-clustering より。created_at でソートされているため created_at では pruning しやすい形で分割されているが、それ以外のカラムではどの partition でも幅広い値が含まれ pruning はできない形になっていることがわかる。
ちなみに Clustering する方法は大きく分けて2つあります。
- automatic clustering として Snowflake に定期的にソートしてテーブルを再作成してもらう
- Snowflake が定期的に行う
- テーブル作成時やデータの挿入時に前もって明示的にソートしておく
- こちらの場合、Automatic Clustering と違い全て自分で行う
- 作成時に適切に order by 句でソートしておく:Manual Clustering
- ELTで定期実行する中で自然とクラスタリングされる:Natural Clustering
この辺りのことは以下の記事が詳しいです。
Manual / Natural Clustering
基本的には Automatic Clustering による定期的な reclustering が必要ない形でテーブルを作成できることが一番です。テーブルの性質を見極め、適宜ソートしておくべきカラムの検討がついたら、 dbt model に order by 句で明示的にソートの条件を入れましょう。
これにより、 automatic clustering 無しでソートされた状態になります。再クラスタリングの費用もかからないので、これが一番コスト効率は高いです。
{{
config(
materialized="incremental",
incremental_strategy="delete+insert",
-- cluster_by や automatic_clustering については何も書かない
)
}}
select
...
from {{ ref("upstream_model")}}
order by (col1, col2) -- 明示的にソートする
差分更新を行う場合にはそこの実行ロジックによって、良い Natural Clustering となるかが決まるので実装には注意しましょう。
Automatic Clustering
どうしても定期的な再クラスタリングが必要な場合には Automatic Clustering が利用できるような形で dbt model の設定をしましょう。
実際に Automatic Clustering を行うためには、 dbt model の config において cluster_by と automatic_clustering の2つを適宜設定すればOKです。
-
cluster_by- デフォルト : none
- モデルの最後に order by 句を入れるかどうかを制御できる
- また、以下のクエリを実行するかを制御する
alter {{ alter_prefix }} table {{relation}} cluster by ({{cluster_by_string}});
-
automatic_clustering- デフォルト :
false - モデル実行後、以下のクエリを実行するかを制御する
alter {{ alter_prefix }} table {{relation}} resume recluster; - この設定を利用すると、もし dbt model 外で明示的に automatic clustering が suspend されていても再度有効化されるようになります
- デフォルト :
{{
config(
materialized="incremental",
incremental_strategy="delete+insert",
cluster_by=["date", "dim_code"],
automatic_clustering=true,
)
}}
select
...
-- cluster_by により order by は追加されるため、明示的に order by 句を書く必要はないです
より細かい挙動を知りたい場合には dbt-snowflake の以下のあたりのコードを参照してください。
Table - COPY GRANTS
dbt では run を実行すると CREATE OR REPLACE TABLE AS SELECT ... という CTAS のクエリが実行されます。2回目以降の dbt run では Replace の挙動となりますが、この際に、元のテーブルの権限を引き継ぐかどうかの設定が COPY GRANTS です。
デフォルトの設定だと COPY GRANTS が付与されないため、対象のテーブルの権限は毎回外れてしまいます。
以下のように dbt_project.yml で copy_grants を true にしておくことでこれを回避できます。
models:
+copy_grants: true
External Table
dbt-external-tables というパッケージを利用すれば、 Snowflake の External Table を dbt の source として設定することも可能です。
このパッケージを利用することで source の yaml において external というセクションにて外部テーブルに関する情報(ステージやパーティションなど)を追記することができるようになります。
version: 2
sources:
- name: POS_A
schema: POS_A
description: Lake layer of POS_A data
tables:
- name: original_transaction
description: >
POS_A transaction data.
Data is located in `s3://{pos_bucket}/transaction/` with Hive partition.
columns:
- name: data_date
...
external:
file_format: "(TYPE=CSV COMPRESSION=NONE SKIP_HEADER=0 BINARY_FORMAT=UTF8 NULL_IF=())"
location: '@{{target.database}}.POS_A.S3_POS_A_BUCKET/transaction/'
partitions:
- name: received_date_partition
data_type: date
expression: TO_DATE(split_part(split_part(metadata$filename, '/', 7), '_', 1), 'YYYYMMDD')
description: >
One of the partition columns.
Corresponding `data_date`.
- ...
外部テーブルに関しては以下の記事もご覧ください。
Secure View
Snowflake はデータ共有系の機能が強いですが、その際のセキュリティを担保するために Snowflake の View には Secure View と普通の View があります。具体的な違いとしては
- 普通の View
- View の定義がオーナー以外でも確認可能
- View にクエリした際、定義情報などを利用して最適化が実行される
- Secure View
- View の定義はオーナーしか確認できず、安全
- Secure View にクエリした際、定義情報などは利用できず一部の最適化ができない
といった点が挙げられます。
dbt-snowflake において Secure view を作成するためには secure という設定を true にするだけでOKです。
まとめ
基本的には https://docs.getdbt.com/reference/resource-configs/snowflake-configs にある程度記載がある内容ではありますが、実際の dbt-snowflake のコードも見つつ整理すると具体的な挙動などの理解が深まるかなと思います。
dbt-snowflake 使い倒していきましょう!

Discussion