この記事はdatatech-jp Advent Calendar 2024の15日目の記事です。
背景
データのスキーマは様々な理由で変更されることがあり、データオーナー側はその変更の影響範囲を正確に把握することが難しいです。
そのため、複数のデータオーナーと安全にソースデータを連携するために、新規ソースデータの連携方法を明確化する必要があります。近年、ソースデータのスキーマ情報の管理やソースデータ監視などの仕組みの必要性が重要視されてきています。
そこでData Contractという概念を取り入れ、ソースデータのスキーマ情報の管理を行うことが最近のトレンドとなっています。

Data Contract flow https://datacontract.com/
Data Contractでは、データの送り手(データオーナー)と受け手(データ分析基盤チーム)の間で連携するデータのスキーマ情報を明示的に定義し、その定義を遵守することで連携するソースデータに関する契約を結ぶ概念です(身近な類似している例としては、APIの共有する際に使用するOpenAPI Specification(Swagger)が近いです)。
Data Contractは概念としては素晴らしいですが、実際にどうやって運用していくかが課題だと思います。運用をしていく上で自動化は重要だと思っており、今回はData Contractのyamlは手動で作る前提で、Data Contractさえ作れば、データテスト、dbtのschema.ymlの生成を自動化するCI/CDを構築します。
実現したいこと
- Data Contractのyamlをvalidateして、かつ実データに対してテストを行う
- Data Contractのhtmlを生成してホスティングし、閲覧できるようにする
- Data Contractのyamlからdbtのschema.ymlを生成する
前提
- Data ContractはGitHubで管理する
- データ基盤チームがデータ基盤内で行う加工処理はdbtを使用して、かつdbtのコードは別のGitHubリポジトリで管理する
- CI/CDはGitHub Actionsを使用する
- 自由に使えるAWSアカウントを持っている
全体像
今回提示するCI/CDの全体像は以下の通りです。
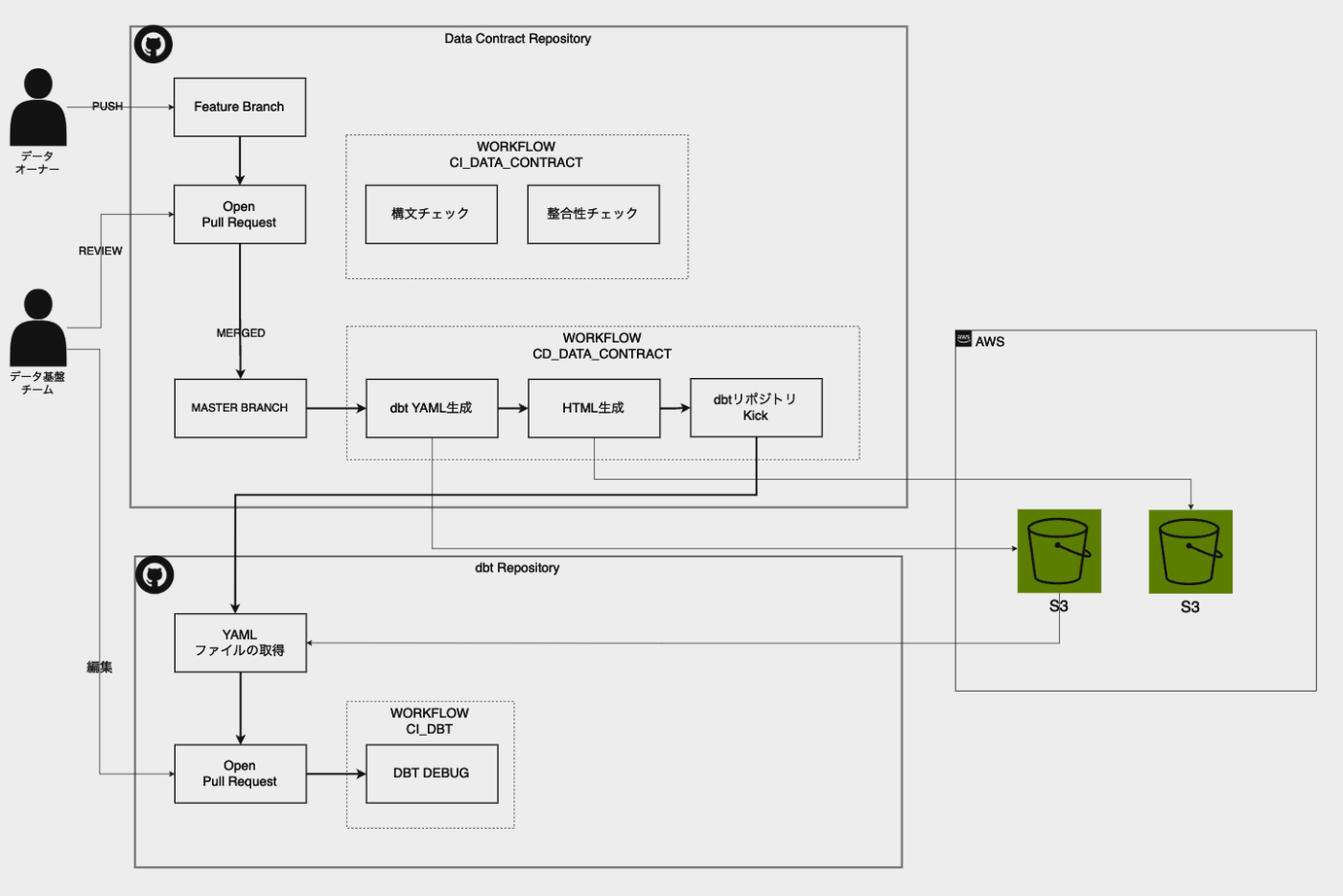
- (データオーナー)Data Contractを管理するリポジトリに連携したいソースデータのスキーマ情報を入力したYAMLファイルを作成し、GitHubにpush ⇒ Pull Requestを作成する
- (Data Contract Workflow)Pull Requestが作成されると、GitHub Actionsにより以下が自動で実行される
- 作成したYAMLファイルの構文チェックおよび実データとの整合性のチェック
- (データオーナー)上記が正常に終了後、データ基盤チームをreviewerに指定する
- (データオーナー)データ基盤チームのapprove後、Pull Requestをマージする
- (Data Contract Workflow)Pull Requestがmasterブランチにマージされると、自動でdbtが読み込むYAMLファイルとHTMLファイルを生成しS3にファイルをコピー、dbtプロジェクトを管理するリポジトリのワークフローをkickする
- (dbt Workflow)dbtを管理するリポジトリのワークフローで、5でコピーされたS3のファイルを取得し、Pull Requestを作成する
- (データ基盤チーム)上記で作成されたPull Requestを編集しパイプラインにソースデータを組み込み反映する。
各Stepの詳細
Data Contractのリポジトリではdata_contractsディレクトリにYAMLファイルを配置します。今回はサンプルで以下のようなYAMLファイルを配置します。
S3にCSVファイルが配置されている前提で、そのデータに対するContractを定義します。
dataContractSpecification: 1.1.0
id: data_contract_sample:custmer
info:
title: custmer
version: 0.0.1
description: "sample for Data Contract"
owner: "koki muguruma"
contact:
name: "koki muguruma"
email: koki.muguruma@finatext.com
servers:
dev: # 開発環境
type: s3
location: "s3://hoge/tables/sample/v1/customer.csv"
format: csv
description: "sample for Data Contract csv"
models:
customer:
description: "all customer"
fields:
name:
description: 人物の名前
type: text
required: true
primary: false
unique: false
enum: []
pii: true
age:
description: 人物の年齢
type: integer
required: true
primary: false
unique: false
enum: []
pii: false
sex:
description: 人物の性別
type: text
required: true
primary: false
unique: false
enum:
- 男性
- 女性
pii: false
email:
description: 人物のメールアドレス
type: text
required: true
primary: false
unique: true
format: email
enum: []
pii: true
phone_number:
description: 人物の電話番号
type: text
required: false
primary: false
unique: false
enum: []
pii: true
example:
- type: csv
description: head(3)
data: |
名前,年齢,性別,メールアドレス,電話番号
山田太郎,28,男性,yamada@example.com,090-1234-5678
佐藤花子,32,女性,sato@example.com,080-2345-6789
鈴木一郎,45,男性,suzuki@example.com,070-3456-7890
servicelevels:
frequency:
description: update data in one shot.
# type: batch
# interval: daily
# cron: "0 0 * * *"
support:
description: サポートが提供される時間
time: "平日 9:00 - 18:00"
responseTime: "24時間以内"
Data ContractのYAML validation、データテスト
Data Contractのyamlファイルの構文チェックと、実データとの整合性チェックを行います。
これらの処理はData Contract CLIのlintコマンド、testコマンドを使用します。
また、Data Contract CLIは破壊的な変更があるかどうかをチェックするbreakingコマンドも提供しています。こちらも必要に応じて実行します。
Data ContractのHTML生成
Data Contractのyamlファイルからhtmlファイルを生成し、S3にアップロードします。あらかじめ、S3にはCloudFrontと連携してホスティングできるようにしておきます。これにより、データオーナーやデータ基盤チームがData Contractの内容を確認できるようになります。
Data ContractのHTML生成には同じくData Contract CLIのcatalogコマンドを使用します。

DataContract catalogのindexページ
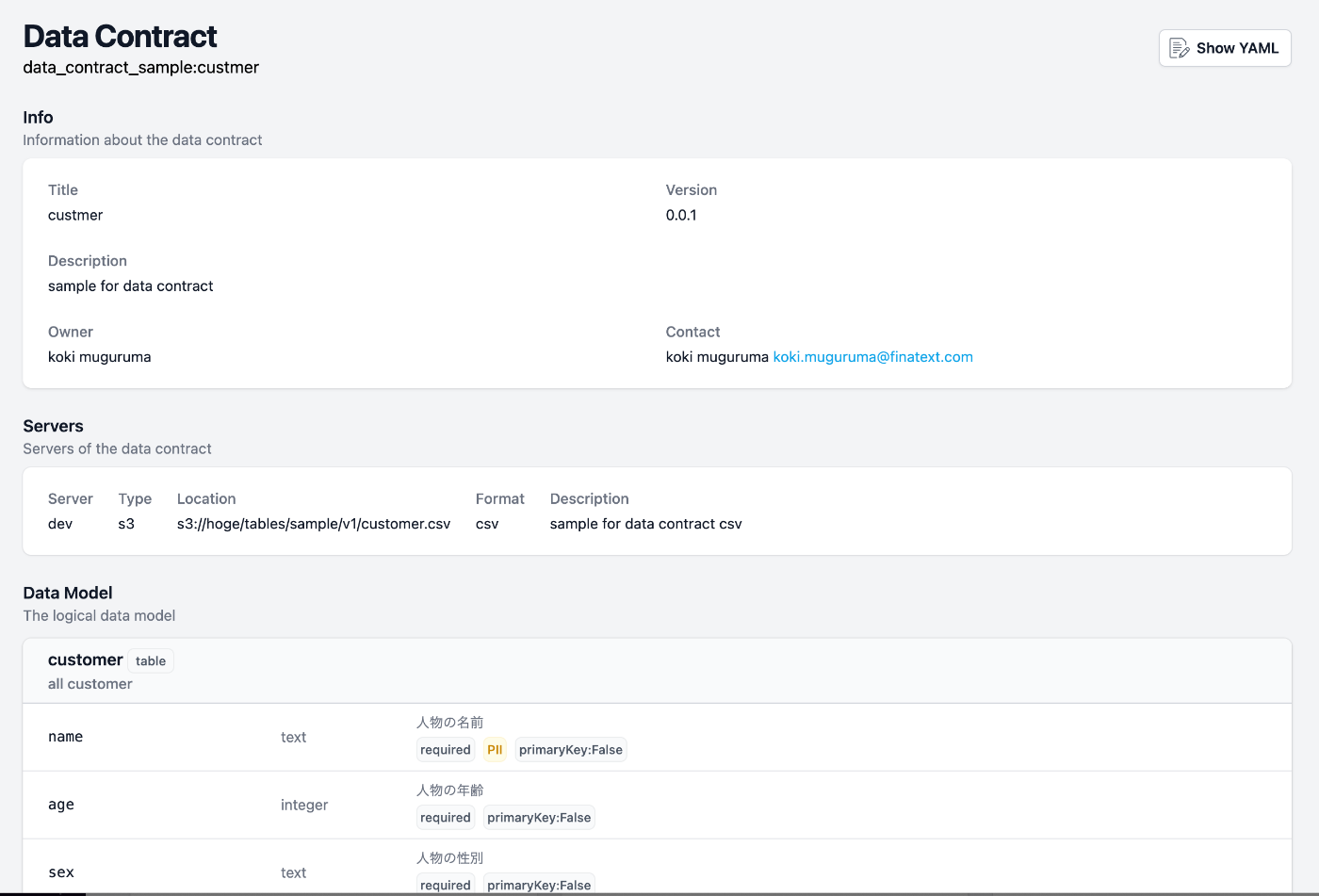
各DataContractのページ
ここまでの内容をGitHub Actionsで定義したものは以下となります。
GitHub Actionsのワークフロー
name: CI_data_contract_test
on:
pull_request:
types: [opened, synchronize]
paths:
- "data_contracts/**"
jobs:
call_data_contract_test:
runs-on: ubuntu-latest
permissions:
id-token: write
contents: write
pull-requests: write
env:
DATACONTRACT_SNOWFLAKE_USERNAME: ${Snowflakeのデータに対しての認証情報}
DATACONTRACT_SNOWFLAKE_PASSWORD: ${Snowflakeのデータに対しての認証情報}
DATACONTRACT_SNOWFLAKE_WAREHOUSE: ${Snowflakeのデータに対しての認証情報}
DATACONTRACT_SNOWFLAKE_ROLE: ${Snowflakeのデータに対しての認証情報}
DATACONTRACT_SNOWFLAKE_CONNECTION_TIMEOUT: 10
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python 3.11
uses: actions/setup-python@v4
with:
python-version: '3.11.9'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install "datacontract-cli[all]==0.10.15"
- name: Configure AWS Credentials
id: aws-credentials
uses: aws-actions/configure-aws-credentials@v4
with:
aws-region: ${{ secrets.AWS_REGION }} # AWSリージョンを指定
role-to-assume: ${{ secrets.AWS_ROLE_GITHUB_ACTIONS_DEV_ARN }} # ロールARNを指定
- name: git diff
id: git_diff
run: |
BASE_BRANCH="${{ github.event.pull_request.base.ref }}"
HEAD_BRANCH="${{ github.event.pull_request.head.ref }}"
TARGET_DIR="data_contracts/"
git fetch origin $BASE_BRANCH
git fetch origin $HEAD_BRANCH
DIFF_FILES=$(git diff --name-only origin/$BASE_BRANCH origin/$HEAD_BRANCH -- $TARGET_DIR)
DIFF_FILES_COMMA_SEPARATED=$(echo "$DIFF_FILES" | tr '\n' ',')
echo "DIFF_FILES=$DIFF_FILES_COMMA_SEPARATED" >> $GITHUB_ENV
- name: Data Contract test
run: |
set -Ceu
echo "DIFF_FILES: $DIFF_FILES" # デバッグ用に出力
IFS=',' read -r -a FILES <<< "$DIFF_FILES"
for FILE in "${FILES[@]}"; do
echo "Processing file: $FILE"
datacontract lint "$FILE"
datacontract test "$FILE"
done
- name: datacontract breaking
run: |
set -Ceu
NEW_DIR="tmp"
mkdir -p "$NEW_DIR"
BASE_BRANCH="${{ github.event.pull_request.base.ref }}"
git fetch origin $BASE_BRANCH
IFS=',' read -r -a FILES <<< "$DIFF_FILES"
for FILE in "${FILES[@]}"; do
if ! git show "origin/$BASE_BRANCH:$FILE" &> /dev/null; then
echo "File $FILE does not exist in base branch $BASE_BRANCH. Skipping."
continue
fi
mkdir -p "$NEW_DIR/$(dirname "$FILE")"
git show "origin/$BASE_BRANCH:$FILE" > "$NEW_DIR/$FILE"
datacontract breaking "$NEW_DIR/$FILE" "$FILE"
done
- name: Export Data Contract
run: datacontract catalog --files "./data_contracts/*/*.yaml" --output ./catalog/
- name: Export to S3 Bucket dev
run: aws s3 sync ./catalog/ s3://"$DEV_DATA_CONTRACT_HTML_BUCKET"/html/ --delete
datacontract lint でYAMLの構文チェックを行い、datacontract test で実データとの整合性チェックを行います。
その後、datacontract catalog でData ContractのHTMLを生成し、S3にアップロードします。
dbtのschema.ymlを取得しPull Requestを作成
Data Contractのyamlファイルからdbtのschema.ymlファイルを生成し、dbtプロジェクトを管理するリポジトリにPull Requestを作成します。これにより、データ基盤チームはソースデータを素早くデータ基盤に反映できるようになります。
Data ContractのYAMLからdbtのschema.ymlを生成するには、Data Contract CLIのexportコマンドを使用します。
datacontract export data_contracts/sample/customer.yaml --format dbt
そして生成されたdbt schema.ymlは一旦S3に配置します。その後dbt repo側でschema.ymlを取得してPRを自動作成します。
別リポジトリへのブランチの作成・コミット・プッシュ・PRの作成を行うためにGitHub Appを利用すると良いです。
ref: GitHub Apps / GitHub Actionsを使って別のリポジトリにファイルをコピーするPRを作成する
今回のCI/CDによる恩恵
- 実データに対する整合性チェックにより、連携されるソースデータの信頼性が担保される
- データ基盤チームは、どんなソースデータが連携されたのか確認しやすい
- データ基盤チームとしてデータの期待する定義が確認しやすいので、データ品質向上のプロセスが踏みやすい
- データ基盤チームは、dbtのスキーマYAMLが半自動生成されるため、ソースデータを素早くデータ基盤に反映しやすい
課題点
- Data Contract CLIはまだ開発途中であり、機能が不足している
- dbtのschema.ymlを生成する機能には不十分感が強い
- なので、Data Contract生成からのdbt schema.yml生成までをCI/CDで完結させることは難しい(humanによる手動作業が必要)
- データオーナー側はData ContractのYAMLを作成する必要があるため、データオーナー側の負担が大きい
- こちらに関しては、Data ContractのYAMLをより簡単に作成できるツール・仕組みがあれば解決できるかもしれない
まとめ
本記事では、Data ContractとCICD連携によるデータテストとdbt schema生成の自動化について紹介しました。Data Contractの概念は素晴らしいものの、実際の運用には課題もあります。しかし、本CI/CDの取り組みにより、ソースデータの信頼性向上やデータ基盤への反映スピードアップなどの効果が期待できます。今後、Data Contractの利用が広がり、より使いやすいツールが登場することで、データ品質管理の自動化がさらに進むことが期待されます。
とりわけData Contract CLIはコンセプトとして素晴らしいツールであるため、私自身もコントリビュートしていきたい所存です!

Discussion