こんにちは。ナウキャストのFinancial Research Unitでアナリストをしている中山です。
この記事では、FinatextグループのAIコンテストにレポート執筆の自動化ツールという内容で参加し、優秀賞を受賞するまでの一連の流れを振り返っていきたいと思います。
はじめに:レポート執筆の課題とAIコンテストへの挑戦
私は普段は主にクレジットカード決済やPOSデータなどのオルタナティブデータを用いた企業業績の分析レポートを執筆し、機関投資家向けに提供しています。
後述しますが、この執筆にはデスクトップリサーチと実際のデータ分析を併せて膨大な工数が掛かっています。
各種AIチャットのDeep Research機能を使ってWebから情報収集をしてみたりと自分で出来る範囲の効率化はしていたのですが、大きな効果は得られていませんでした。
その後普段は不動産会社向けのサービスを開発しているスゴ腕エンジニアの酒匂さんと一緒にレポート執筆の効率化について調査・検証していたところにAIコンテストの開催が案内されたため、チームを作り本格的にツール作成に取り組むことになりました。

(初期の検証結果資料 プロジェクト名はメカ中山)
自動化の対象:オルタナティブデータレポートとは?
実際に作ったツールを説明する前に、自動化の対象とした「オルタナティブデータを使った機関投資家向けのレポート」というややニッチで特殊な商品を少し詳しく説明させてください。
現在ナウキャストの主力ビジネスとなっている機関投資家向けビジネスでは、投資家の属性ごとに異なるニーズに合わせた粒度の集計・加工・分析を行いデータを提供しています。

(Finatextホールディングス 決算資料より引用)
上図三段目のファンダメンタルファンドでは、データをモデルに組み込んで運用する訳ではなく人が判断して運用を行っています。なので、データそのものを提供して顧客に分析してもらうよりも、分析結果がまとまったレポートとして提供する方が効率的に運用に役立ててもらえます。
このレポートの価値として大きく2つのことが挙げられます。
1つ目はデータの動きをその背景要因から説明することです。あるアパレル企業の売上が急増しているとき、それが新商品がヒットし他社からシェアを奪っているのであれば市場はポジティブに受け止めるかもしれませんが、天候など単なる一過性要因であれば評価されない事も多いです。こういった背景情報を考慮しレポートで確認できるようにする事で、データが示す結果を投資行動に結びつけやすくなります。
2つ目がより大事な点で、オルタナティブデータはそのデータが生成される過程から発生するバイアスを注意深くケアしないとミスリーディングな結果にたどり着く場合もあります。
典型的な例だと、ある企業がバーコード決済に対して大きなポイント還元のキャンペーンを行うと、クレカデータの売上が大きく減少する事があります。これは実際の売上が減少しているわけではなくクレカからバーコード決済への一時的なスイッチングが起きているだけなので、クレカデータの減少をそのまま受け取ると企業の実態を過小評価してしまうことに繋がります。
このようなデータにバイアスを与える事象が発生していないかどうかを調査し、データの信頼性を担保することもレポートの価値となっています。
こういった点を踏まえてレポートを執筆する際には、単にデータを集計・分析するだけではなく、デスクトップリサーチを中心に分析対象の企業を細かく調査し、データと比較しながらアナリストの解釈を加えていくという工程が発生します。
個別のアナリストの知見に基づいて行われていたこの一連の流れをAIを使って可能な限り自動化しよう、というのが今回の取り組みになります。
開発したレポート執筆自動化ツール「メカ中山」の概要
いよいよ、今回AIコンテストに向けて実際に作ったものを紹介します
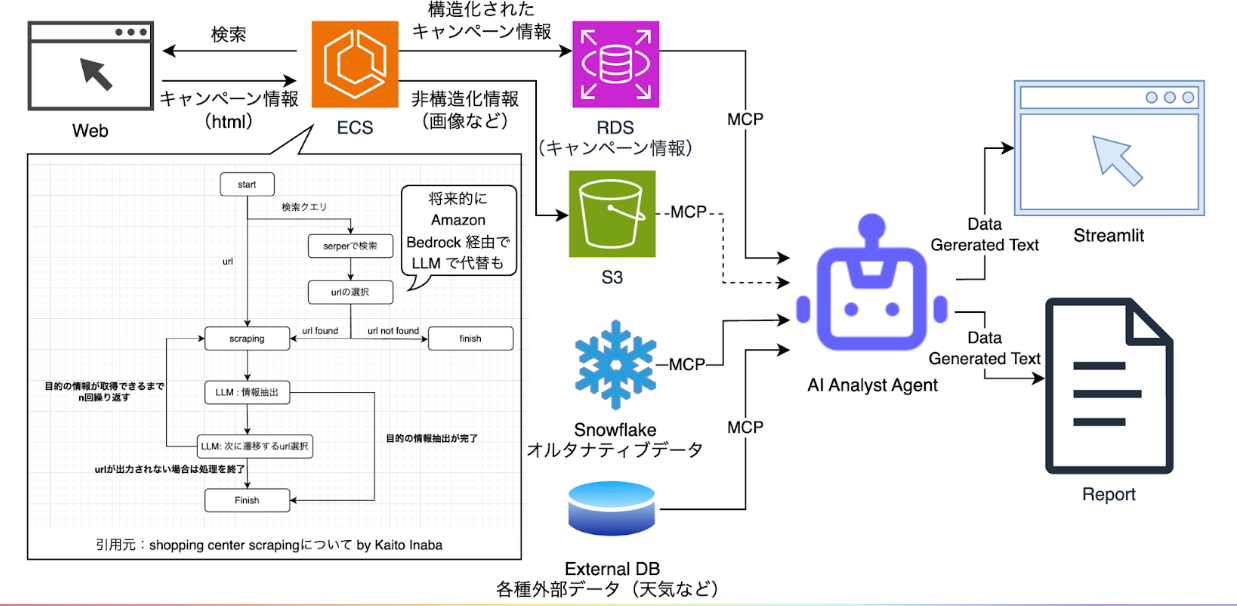
(メカ中山のシステム構成図)
主要な機能は大きく下記の3つに分けられます。
- Webクローリングによって調査対象となる企業に関連するキャンペーンや新商品などの情報をWebから収集し構造化データとして蓄積する
- MCPサーバーを通じて、分析対象となるオルタナティブデータ、Webから収集したキャンペーン情報、企業の財務情報や天候などその他のデータを統合する
- LLMにそれらのデータを与え、適切な分析コメントを作成する
下記のような一連の流れでアウトプットが生成されます。

(UIはStreamlitで実装。分析したいTickerを指定する)

(集めてきた情報を元にコメントが生成される)
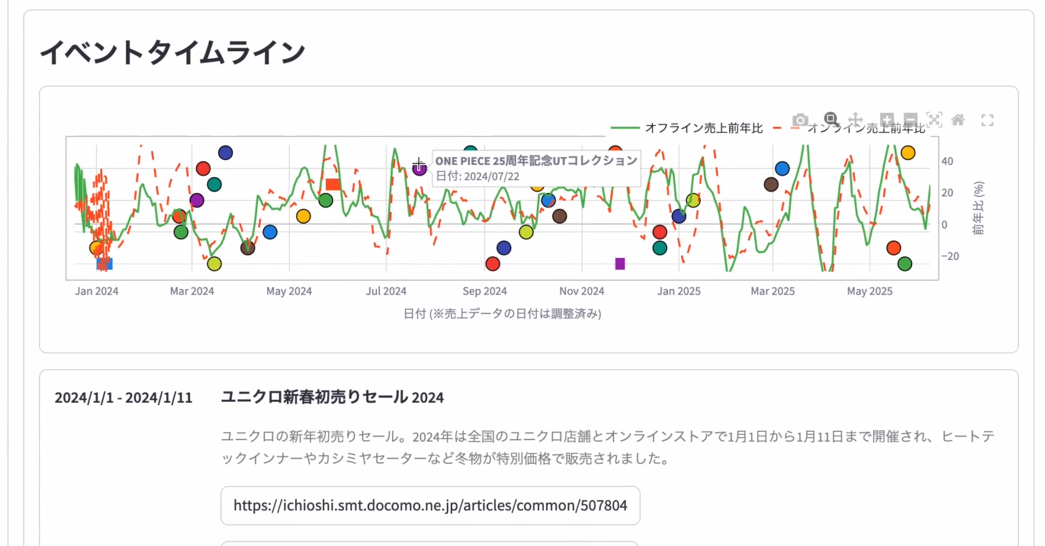
(収集したキャンペーン等の情報をグラフと並べて表示。ファクトチェックのために情報元のURLも確認できる)
開発の初期段階でプロンプトをブラッシュアップし、およそ間違いのないコメントを生成する事が出来るようになりました。
とは言え、カバーする銘柄を増やしていくにつれ人の手直しが必要なものも出てくることが想定されます。今後の運用段階については生成されたコメントにアナリストが評価を付け、改善→精度検証のサイクルが回るような仕組みも導入する予定です。
AIコンテスト=ユニットを越えたコラボレーションの機会
先述の通りレポート執筆の効率化については長らく課題感を持ってはいたのですが、自分一人では開発の知見もなく、根本的な改善に取り組めていませんでした。
それを前に進めることが出来たのは、AIコンテストという機会で、普段のユニット体制を越えた枠組みで取り組めたからなのではないかと思います。
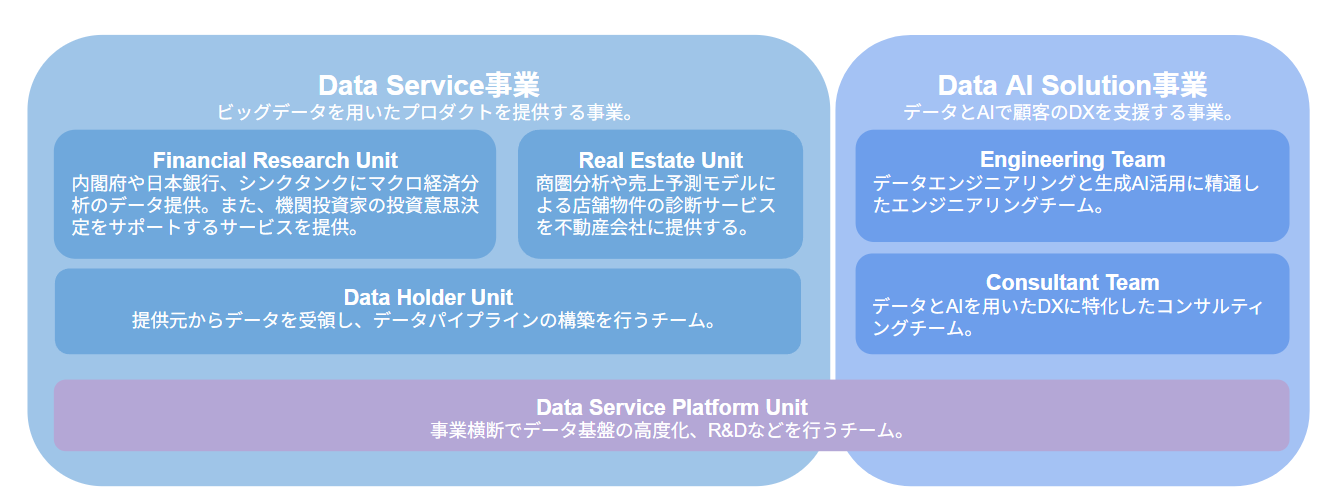
(ナウキャストのユニット体制)
今回はFinancial Research UnitのメンバーだけではなくReal Estate Unit, Data Holder Unitのエンジニア陣と一緒に取り組みました。
前述の主要な機能のうち、Webクローリングによる情報収集については、LLMに判断させながらweb上を探索し必要な情報を取得する仕組みを実装しています。これは、ナウキャストの不動産業界向けのサービスを作るユニットが物件情報の収集等のために既に開発していたものを活用しています。
Financial Research Unitはデータの集計・加工や分析に強みがあるメンバーが集まっているのに対し、Real Estate Unitは事業会社向けの業務SaaSを作る性質上、AIの業務への活用が進んでおり、その知見を吸収する事が出来たのが良かったです。
また、MCPサーバーを使ったデータの統合に関しては、分析に用いる各種オルタナティブデータや気象データはSnowflakeで整備されているため、開発がしやすい状況でした。
Data Service Platform Unitによる知見の集積、データ基盤の整備が奏功したと言えると思います。
今後の展望:社内ツールから顧客向けサービスへの展開
今回AIコンテストで作成した「メカ中山」は目下本格稼働に向けて開発中です。
技術的な取組みは改めて当Tech Blogでご紹介
また、社内のレポート執筆業務を効率化するところから始まった今回の取り組みは、顧客向けサービスとして展開する余地があるのでは、と考えています。
- 企業調査に有益なWeb上の情報をLLMを用いて高い精度で収集する
- ユーザーのニーズに合わせた企業の分析を、データ基盤上の複数データを統合し自動で行う
というメカ中山の基本機能は恐らく企業調査を専門に行う機関投資家など、ナウキャストの顧客にとってもニーズがあるのではないか、という仮説を持っています。
今後ナウキャストのFinancial Research Unitでは、単なるオルタナティブデータおよびそこから得られる示唆の提供にとどまらず、より企業調査・運用業務に入り込んだサービスの提供を模索していきたいと考えています。

Discussion