本記事の目的
ナウキャストでデータエンジニアをしている大森です!
これまで Airflow で DAG を作成することは何度かあったものの Trigger Rules にあまり向き合ったこともなかったため、 最近組んだ DAG で苦闘した部分も含めて自分なりにまとめてみようと思います。
今回作った DAG がベストプラクティスとは限らないので、もっと良いあり方があればぜひコメントいただけると嬉しいです!
結論
DAG を作成する時は Trigger Rules を活用し、まずは下流のタスクで制御できないか考えよう
最近組んだ DAG
今回題材にする DAG を紹介します。
やりたいこと
データA、データBの存在を確認し、両者が存在すればデータA, B を用いて計算しデータCを作成する。
設定
- データCは月に一度作成されれば良い。
- データA,Bは毎月作成されるタイミングがバラバラ
- データCの作成は出来るだけ早いほうが良いため、日次で DAG を回す
- データBが存在しない場合は外部からの取得を試みる
処理の流れ
これをフローチャートにしたものが以下です。

指針
フローチャートを元に DAG を作成します。
指針としては、
- データA, Cの存在を確認する分岐の Task は SensorTask を用いる
- データB の存在を確認する分岐の Task は BranchPythonOperator を用いる
SensorTask とは
ファイルの存在チェックなどを行い、存在すれば success ステータス、なければ fail ステータスにするような Task 群です。例えば S3SensorTask では指定した path にオブジェクトがあれば success、なければ fail ステータスになります。
soft_fail という fail 時に skip ステータスにする機能があります。
詳しくは公式ドキュメント参照。
BranchPythonTask とは
次に発火する Task を指定できます。
def choose_branch(**kwargs):
s3_key_sensor_result = kwargs["dag_run"].get_task_instance("parent_task").state
if s3_key_sensor_result == "success":
return "child_task_1"
else:
return "child_task_2"
詳しくは公式ドキュメント参照。
Trigger Rules との格闘
上記のフローチャートを実現する際にいくつか失敗したことがあったので Trigger Rules と共にここで紹介します、、笑
Trigger Rules とは
親のタスクのステータスを見て、自身のタスクを発火させるかどうかを決めるためのルールです。デフォルトでは親タスクが成功した場合のみ発火するような Trigger Rule が設定されています。
この Trigger Rules をうまく活用することで、複雑なフローの管理が可能になります。
Trigger Rules
By default, Airflow will wait for all upstream (direct parents) tasks for a task to be successful before it runs that task.
However, this is just the default behaviour, and you can control it using the trigger_rule argument to a Task. The options for trigger_rule are:
all_success(default): All upstream tasks have succeededall_failed: All upstream tasks are in a failed or upstream_failed stateall_done: All upstream tasks are done with their executionall_skipped: All upstream tasks are in a skipped stateone_failed: At least one upstream task has failed (does not wait for all upstream tasks to be done)one_success: At least one upstream task has succeeded (does not wait for all upstream tasks to be done)one_done: At least one upstream task succeeded or failednone_failed: All upstream tasks have not failed or upstream_failed - that is, all upstream tasks have succeeded or been skippednone_failed_min_one_success: All upstream tasks have not failed or upstream_failed, and at least one upstream task has succeeded.none_skipped: No upstream task is in a skipped state - that is, all upstream tasks are in a success, failed, or upstream_failed statealways: No dependencies at all, run this task at any time
Trigger Rule に頼らなかった失敗
Trigger Rule はいわば「下流側での制御」ですが、 「上流側での制御」にこだわりすぎた結果複雑なことをしてしまう Task がありました。
フローチャートの一番最初の「データCが存在」という分岐では、
- 存在していれば後続を全てスキップして終了
- 存在していなければ後続タスクを実行
を行う必要がありました。
ここで、SensorTask は soft_fail を True にすることで「存在しなければ後続を全てスキップして終了」ができるのですが、存在している場合に後続をスキップさせることができません。
そこで、最初に行ったのは SensorTask を継承したクラスを作成し、結果を反転させるというものでした。これによりファイルが存在したら fail ステータスを返せるようになり、soft_fail を True にすることで、「存在していれば後続を全てスキップして終了」ができるようになりました。
しかし、ここではカスタムオペレーターを追加せずとも下流のタスク Trigger Rule でフローを制御することが可能でした。下流のタスクは親が「失敗した時だけ実行する」ようにすればよかったのです。
具体的には all_failed や one_failed といった Trigger Rules を用いることで実現が可能です。
上流側で無理に制御しようとして複雑なことをする前に、一度 Trigger Rules を思い出し、下流側で制御ができないかということを考えると見通しが良くなる場合があるということを学びました。
Trigger Rule だけで解決しようとした失敗
今度は逆に、Trigger Rule で実装をシンプルにできないかにこだわってハマった箇所を紹介します。
フローチャートの「データBが存在」の分岐は、どちらに分岐した場合でも何かしらの後続タスクが発生していたため BranchPythonOperatorを使っていました。
これはいわば「上流側の制御」ですが、「データBが存在」のタスクの成否により下流側で制御できないか、具体的には
- 「データBが外部取得可能」のタスクの発火条件を「データBが存在」に失敗した時
- 「データCを作成」のタスク(正確には間に挟んでいた Empty Task。Empty Taskが必要な理由は後述)の発火条件を「データBが存在」に成功した時
にすれば branch task が不要ではないかと考えました。
しかし、結果としてはうまくいきませんでした。
具体的には、親タスクが成功した場合は片方が実行されもう片方が skip になるが、親タスクが失敗すると upstream failed になってしまう(期待する挙動は skip)ということが起こりました。

親タスクが成功した場合は片方が実行されもう片方が skip になる
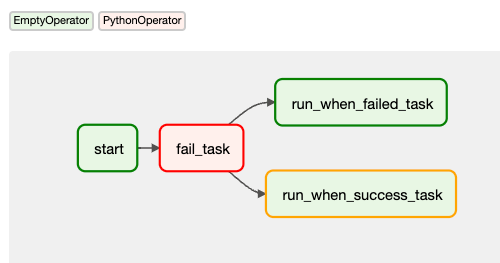
親タスクが失敗すると upstream failed になってしまう
これは、親タスクが失敗時 one_failed を Trigger Rule にしている task は期待通りの発火するものの、one_success を Trigger Rule にしている task は upstream failed ステータスにするのが通常の挙動であるためです。
今回のケースでは少なくとも Trigger Rule で解決するのは難しく、branch task で個別に挙動を制御する方がよさそうという結論に至りました。
最終的に作成した DAG
上記の失敗も含め、フローチャートに沿って作成した DAG と各タスクの Trigger Rules を載せておきます。

join task の Trigger Rule が none_failed_min_one_success となっているのは、親のいずれかがスキップ、いずれかが成功している時のみ発火してほしいためです。ここの設定をしないとデフォルトの all success が Trigger Rule となり、タスクが skip となってしまいます。
また、dummy task が存在するのは、branch task は必ず成功するため、join task に直接繋げてしまうと join task も毎回発火してしまうためです。
DAG を組むときの考え方
以下の流れで制御を考えると見通しが良くなるかと思います!
- まずは下流側から Trigger Rules を用いた制御を試みる
- 難しい場合は上流側からの制御アプローチも視野に入れる
Airflow をある程度触っている方も改めて公式ドキュメントに立ち返ってみると色々と発見があるのではないでしょうか?
長くなりましたが、最後まで読んでいただきありがとうございました!!
仲間を募集中!
ナウキャストでは一緒に働く仲間を募集中です!

Discussion