はじめに
ナウキャストは、Snowflake Summit 2025に13名という大所帯で参加しました。私自身も多くのセッションに参加し、Snowflakeの新機能について学びました。その中でも特に印象に残った「Snowflake Intelligence」について、詳しく解説します。
Snowflake Intelligenceとは?
Snowflake Intelligenceを一言で説明するのはなかなか難しいと感じましたが、公式ブログでは以下のように表現されています。
Today, we're thrilled to announce Snowflake Intelligence (in public preview soon), a transformative new experience designed to bridge the data-to-action gap. It empowers employees to securely converse with their data, derive profound insights from trusted enterprise information and initiate actions — all from a unified, intuitive interface.
Snowflake Intelligence: Talk to Your Data, Unlock Real Business Insightsより
Snowflake Intelligenceとはexperienceとのことで、わかったようで、わからないですね。
私の理解では、Snowflake Intelligenceは「Snowflake上でAIエージェントをローコードで構築し、チャットUIで対話的に利用するための体験を提供する総合的な仕組み」と捉えています。
SnowflakeはこれまでCortex Analyst(構造化データ)、Cortex Search(非構造化データ)、基盤モデルの拡大など、AI関連の機能を着実に拡大してきました。Openflowによる非構造化データも含めた様々なデータのリアルタイム連携も実現し、いよいよAIプラットフォームとして必要なパーツが揃いつつあります。
重要なパーツが揃ったこのタイミングで基盤モデル選択、ツール、インターネット検索、エージェントのランタイムなど、エージェント実装に必要なベーシックな実装が行えるUIをリリースし、Snowflake上でエージェントを簡単に実装できるようにしたのがSnowflake Intelligenceなのかなと思っています。
他の会社はエージェント管理のUIを先行して出しがちですが、データ検索、権限管理、基盤モデルの性能など、AIエージェントをエンタープライズで実装するにあたりボトルネックになりがちな機能を先にリリースしておき、一定のユーザー体験が担保できたタイミングで出すあたりがAppleっぽくて個人的には好きでした。
Snowflake Intelligenceでできること
まずはSnowflake Intelligenceを使うと何ができるのかを見ていきましょう。
公式がYoutubeで出してくれている動画がわかりやすいので、この動画を元に解説をします。
Cortex Analyst/Searchを使ったチャットでの質問対応
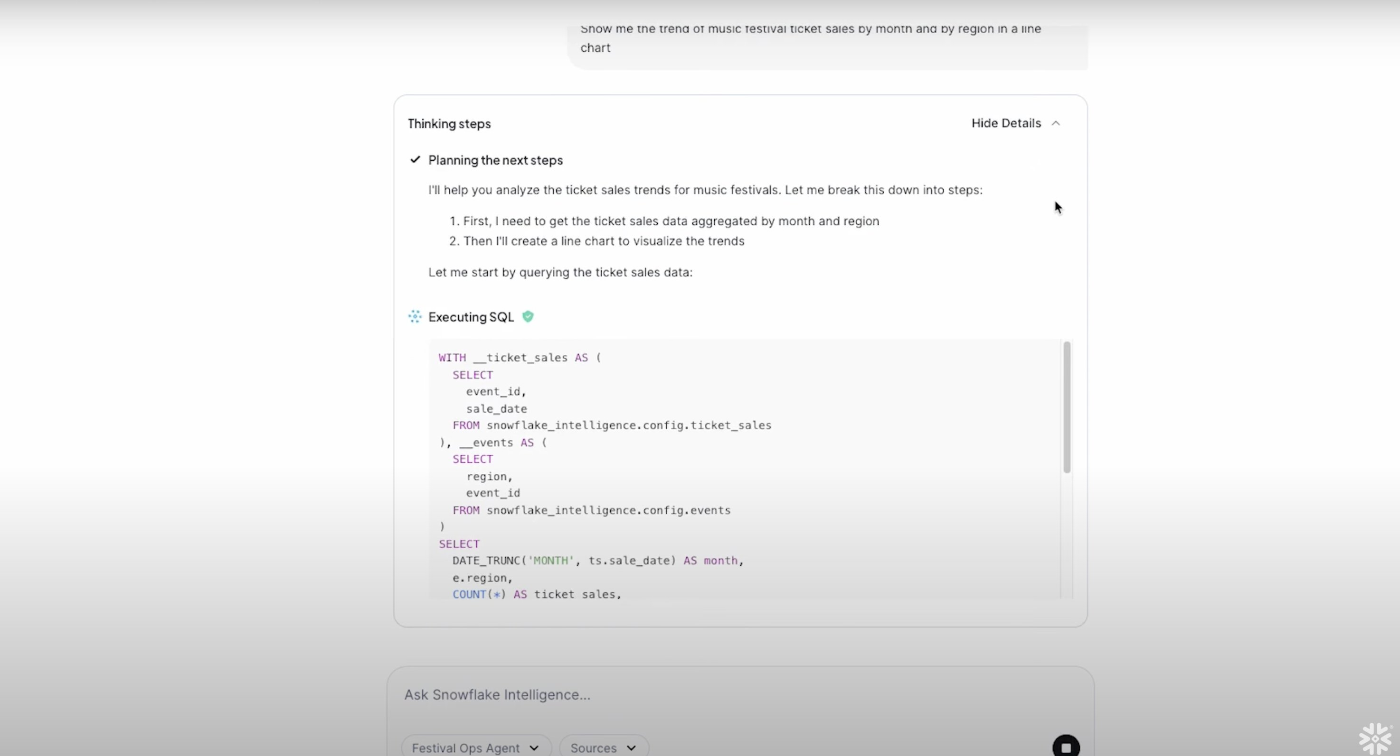
Snowflake Intelligenceの利用画面はこんな感じになります。
ユーザーの問いかけに対してAIが計画を立て、事前に定義されたツールを使いながら回答をする一般的なAIエージェントです。
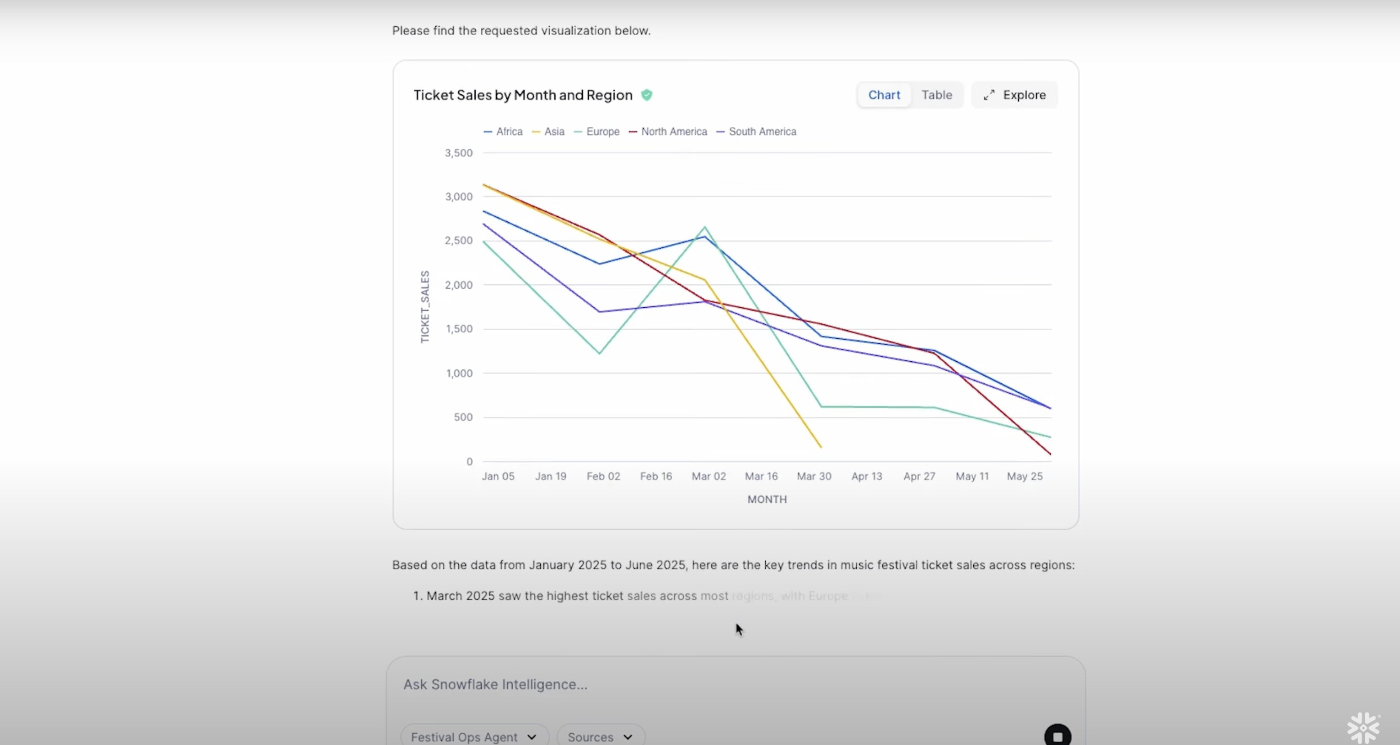
この画面では「チケットの売上をリージョンと月ごとに説明して」という質問に対して、Cortex Analystを用いてデータを取得し、結果をチャートにしてAIが説明しています。
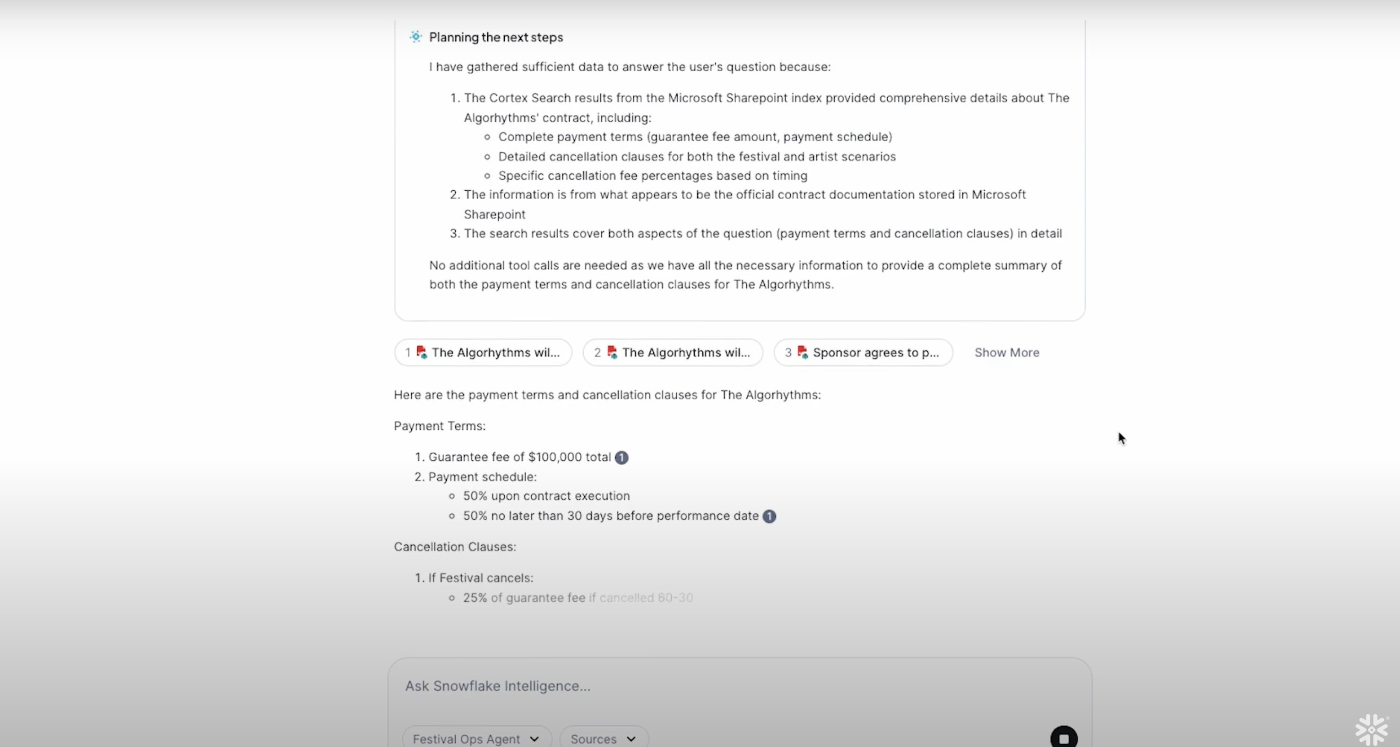
Cortex Searchを用いたテキストデータの参照も可能です。このデモではあるアーティストのキャンセル条項等について説明してという質問に対して、Sharepointのデータを利用して回答をしています。
Cortex Analyst/Searchの使い分けはオーケストレーション機能であるCortex Agentsが行います。
セマンティックビューの設定
デモではここからセマンティックビューの説明になります。社内の複雑な構造化データを分析するにはテーブル定義だけでは情報が足りず、カラムの意味や売上や利益の計算式など、追加的な情報を与えないとハルシネーションや見当違いの結果が返ってくる原因になります。
例えば、ある組織において純収益が「総売上から割引を引いたもの」という定義の場合、SUM(gross_revenue * (1 - discount))という定義をメトリクスとして書いておくと、正しい計算をAIが行えるようになります。
これまでのyaml形式のセマンティックモデルをSQLでも呼び出せるようにすることで、AIからもBIからも同じ情報を参照できるようになりました。
FESTIVAL.SALESというスキーマを対象にセマンティックビューを作成しています。FESTIVAL.SALESはチケットの金額や売上のテーブルを含むスキーマです。
まずはセマンティックビューの保存場所、名前、説明を入力します。

次に個人的にとても良いなと思った機能なのですが、TableauやPDFの情報からAIが自動でセマンティックビューを作ってくれる機能があります。ここではTableauとPDFをコンテキストとして与えています。
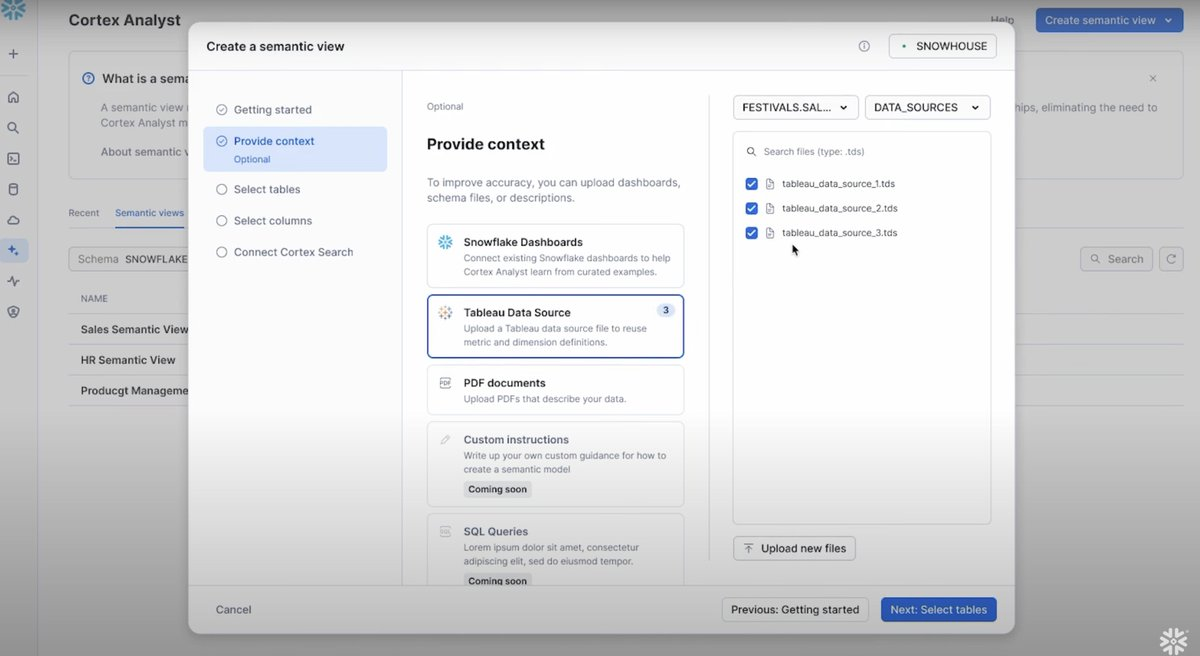
最後に対象のテーブルとカラムを選んでおおよそ作業は完了です。現地のデモだとここから作成されたセマンティックビューを人間が修正したり、AIが自動でテストしたりするんですが、長くなるので別のブログにまとめようと思います。
より複雑な質問への回答
次に2025/3のヨーロッパの売上のスパイクの原因をAIに調べてもらう流れになります。
この質問はWhatではなくWhyを問う質問で、回答には高度な思考が必要になります。
オーケストレーションのステップでスパイクの原因を調べるための調査計画をAIが作成し、まずはAIがこの期間中にマーケティングキャンペーンがあったかどうかの確認から始めています。
このように、AIが自分で問いを立ててデータにアクセスする際に、さっき作ったセマンティックビューが効いてくるかたちですね。
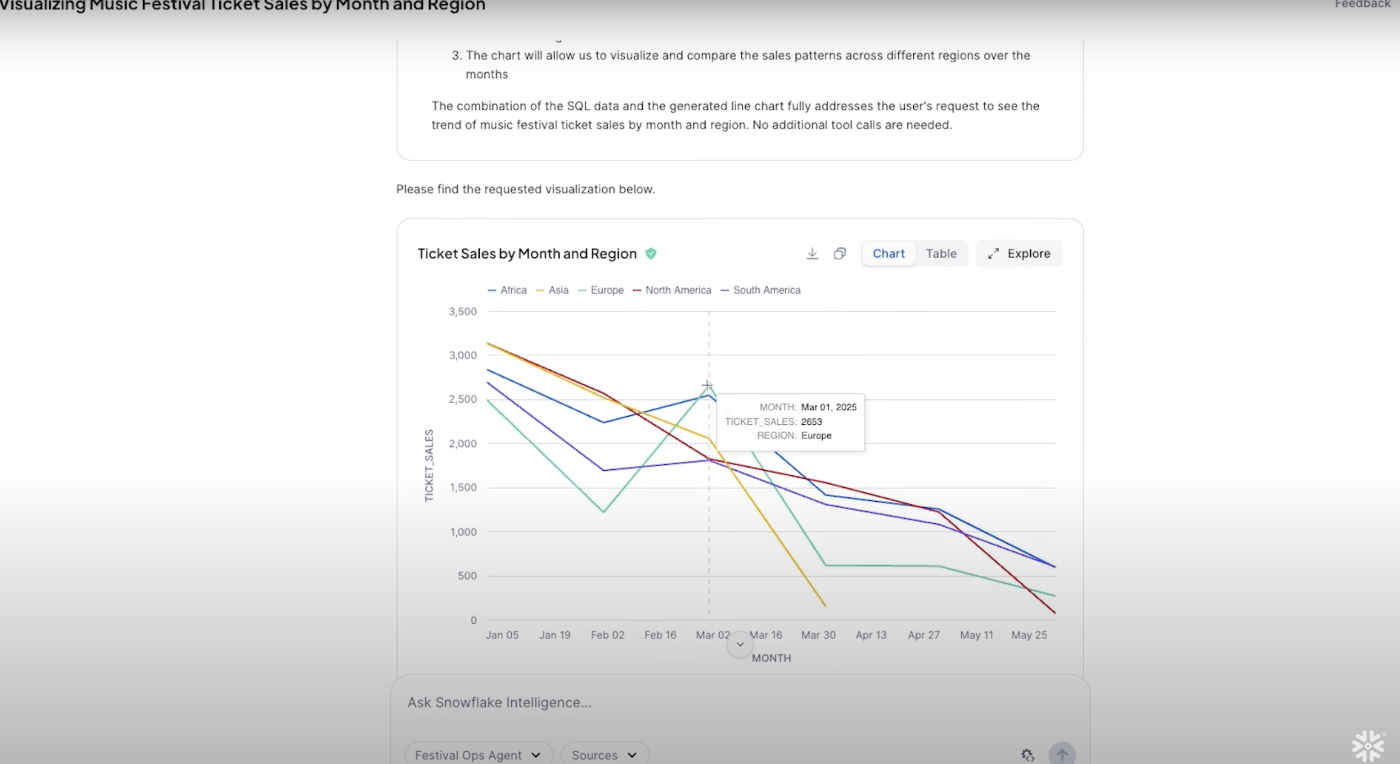

次に社内のDBからイベントの有無を確認した後、マーケットプレースのニュースデータからのヨーロッパ全体のイベント情報なども取得しています。

売上のスパイクがあった際に、期間内の社内外のイベントやキャンペーンに原因があるのではと問いを立てて、実際にデータを調査する流れは人間と比べても遜色ないですね。
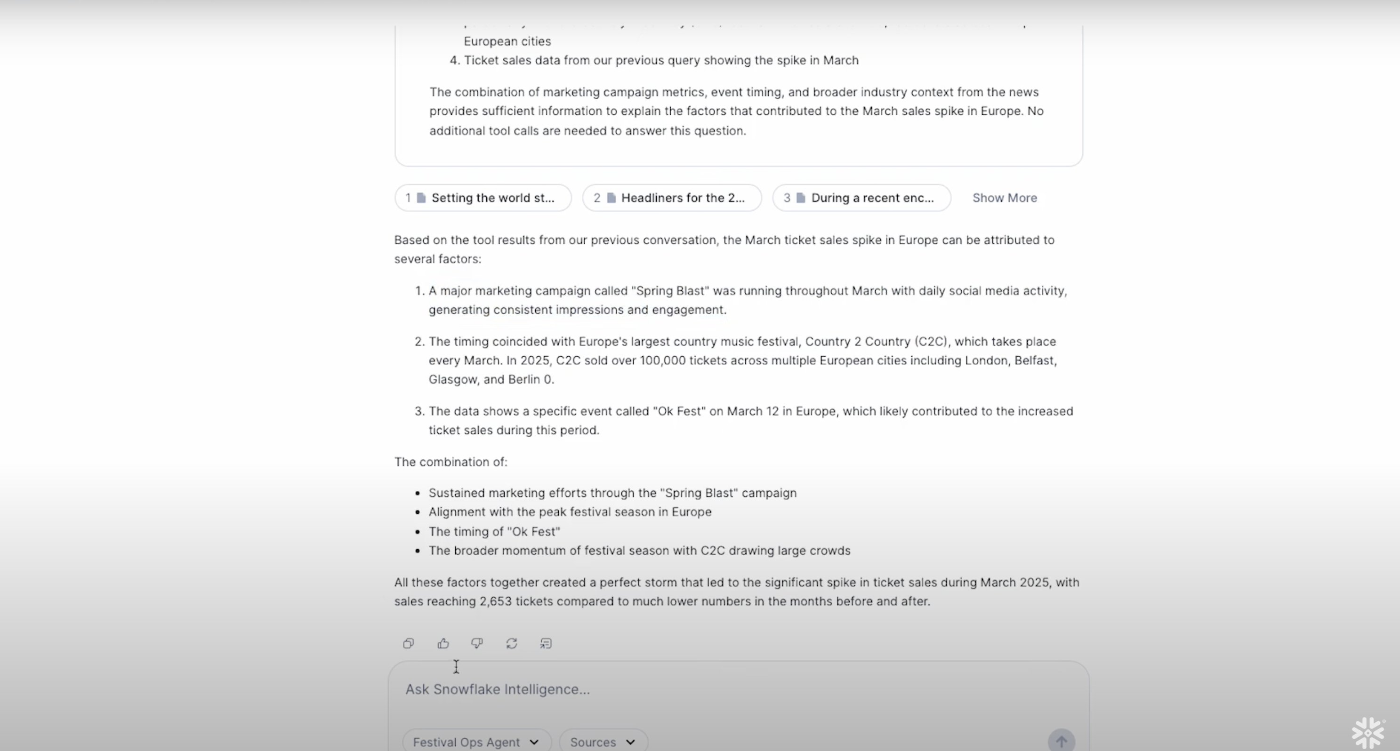
これらの結果を最終的にAIがまとめて、スパイクの原因をデータに基づいて報告してくれます。
最終的にはマーケティングキャンペーン、3/12のイベント、ヨーロッパ最大の音楽フェスの3つをスパイクの原因として挙げています。
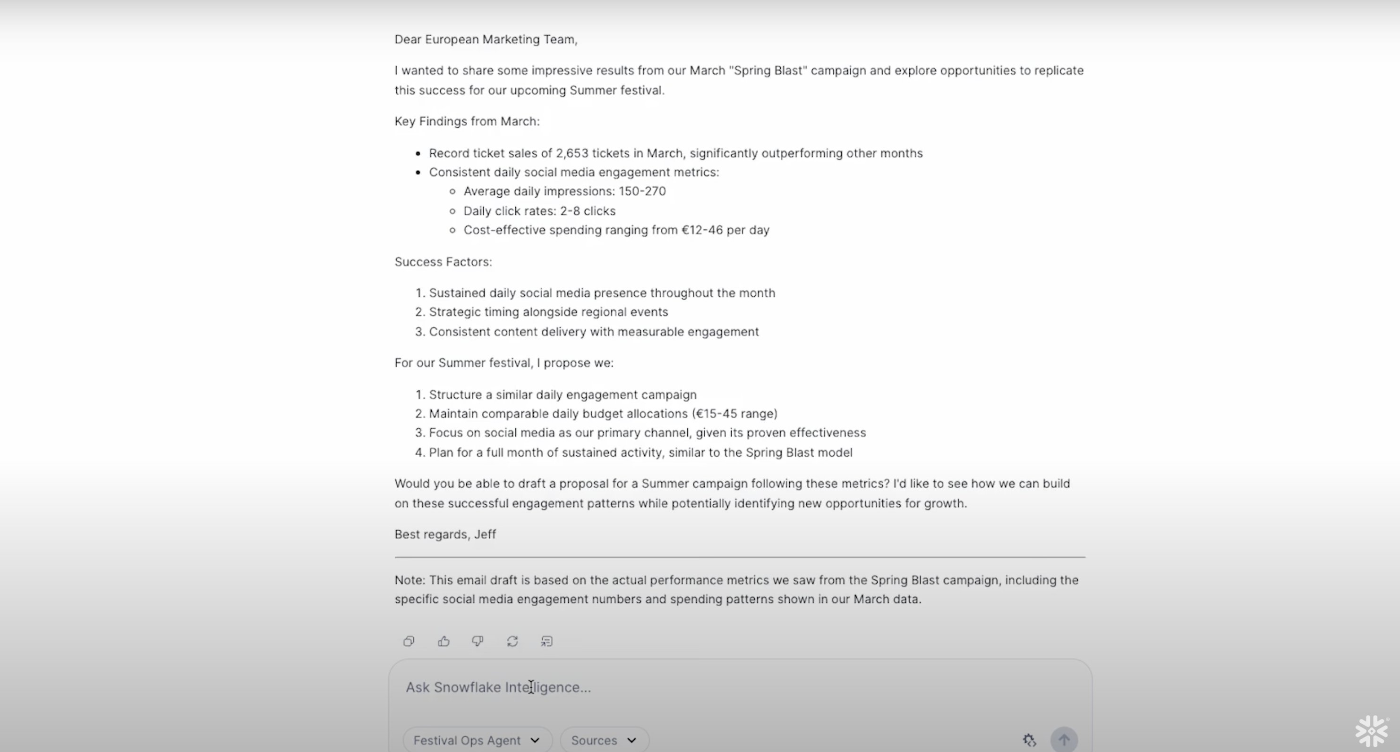
結果をメールで送信
最後にこれまでの調査結果をマーケティングチームにメールで報告してデモは終了になります。Gmailの連携はエージェントビルダー画面でワンクリックで行うことができます。メール送信までしてくれるとかなり便利になりますね。
Snowflake Intelligenceの強み
最近の基盤モデルはかなり賢くなっており、この様なAIエージェント機能のボトルネックはデータの提供と検索になることが多いです。
正しいコンテキストさえ与えられれば検索、分析、メールくらいなら今のAIにとって朝飯前ですが、正しいコンテキストを与えるためにデータを溜めて、検索に必要なビジネスメタデータを整備し、適切な検索エンジンでクエリできるようにすることが障壁になります。
あらゆるデータのリアルタイム連携をOpenflowで行い、構造化データの検索はCortex Analystで行い、非構造化データの検索はCortex Searchで行い、外部データをマーケットプレースで補い、様々な基盤モデルを自前のGPU環境で提供し、それらをCortex Agentsでオーケストレーションし、Snowflake IntelligenceとしてわかりやすいUIで提供するSnowflakeのプロダクト戦略は今回のSummitで一番感動した内容でした。
エージェントの作り方
次にSnowflake Intelligenceによるエージェント実装の方法を説明します。
こちらはYoutubeのデモでは公開されておらず、2025/6/8時点ではSummitのセッション動画以外では公開されていないはずです(たぶん)
この記事ではセッションのデモ動画を元に解説していきます。
エージェントの作成
Snowsightのサイドバーからエージェント一覧画面に移動し、「Create agent」ボタンからエージェントの作成が可能です。
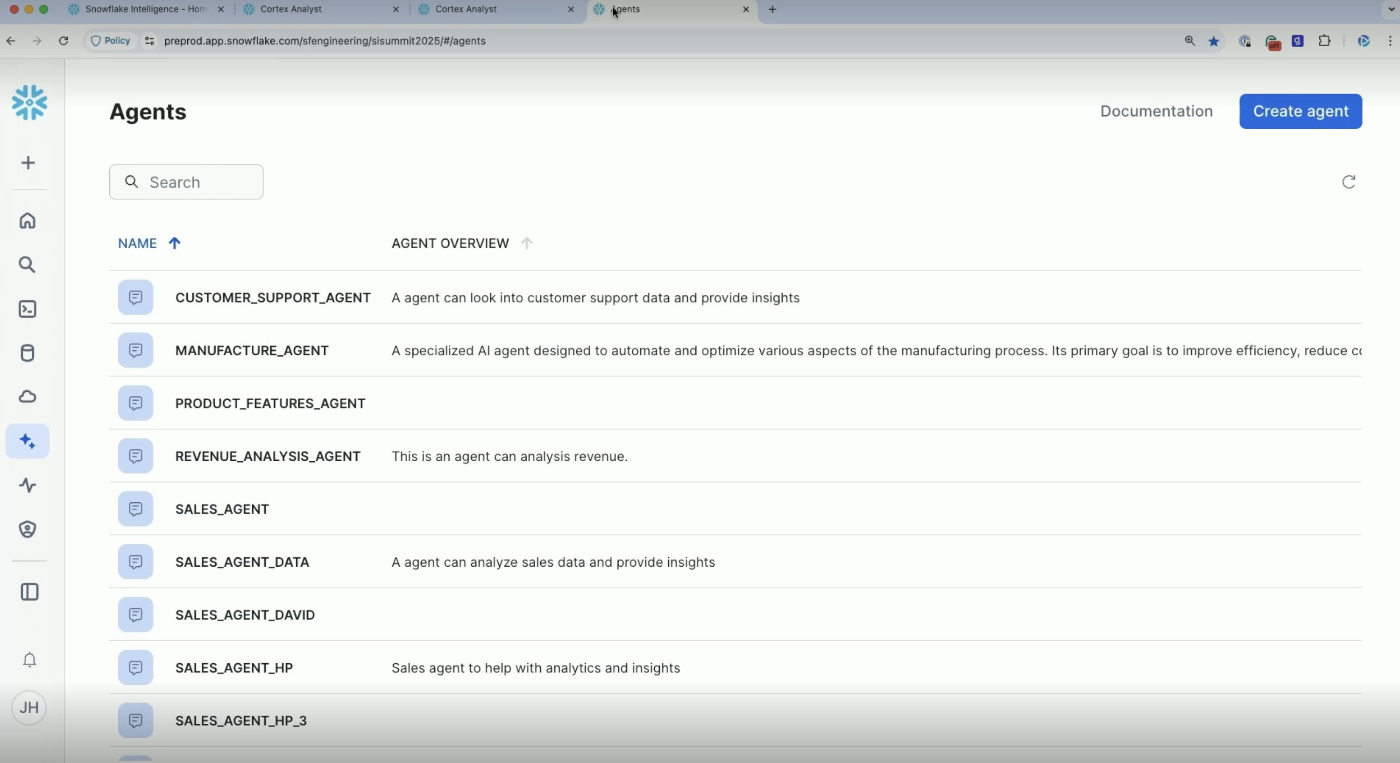
ボタンを押下すると作成用のモーダルが表示され、エージェントの名前に加えて、ここでスキーマを指定します。検索対象のスキーマはこの後のCortex Analystで指定するため、このスキーマはエージェント(EXTERNAL AGENTオブジェクト)の保存場所になるので注意してください。
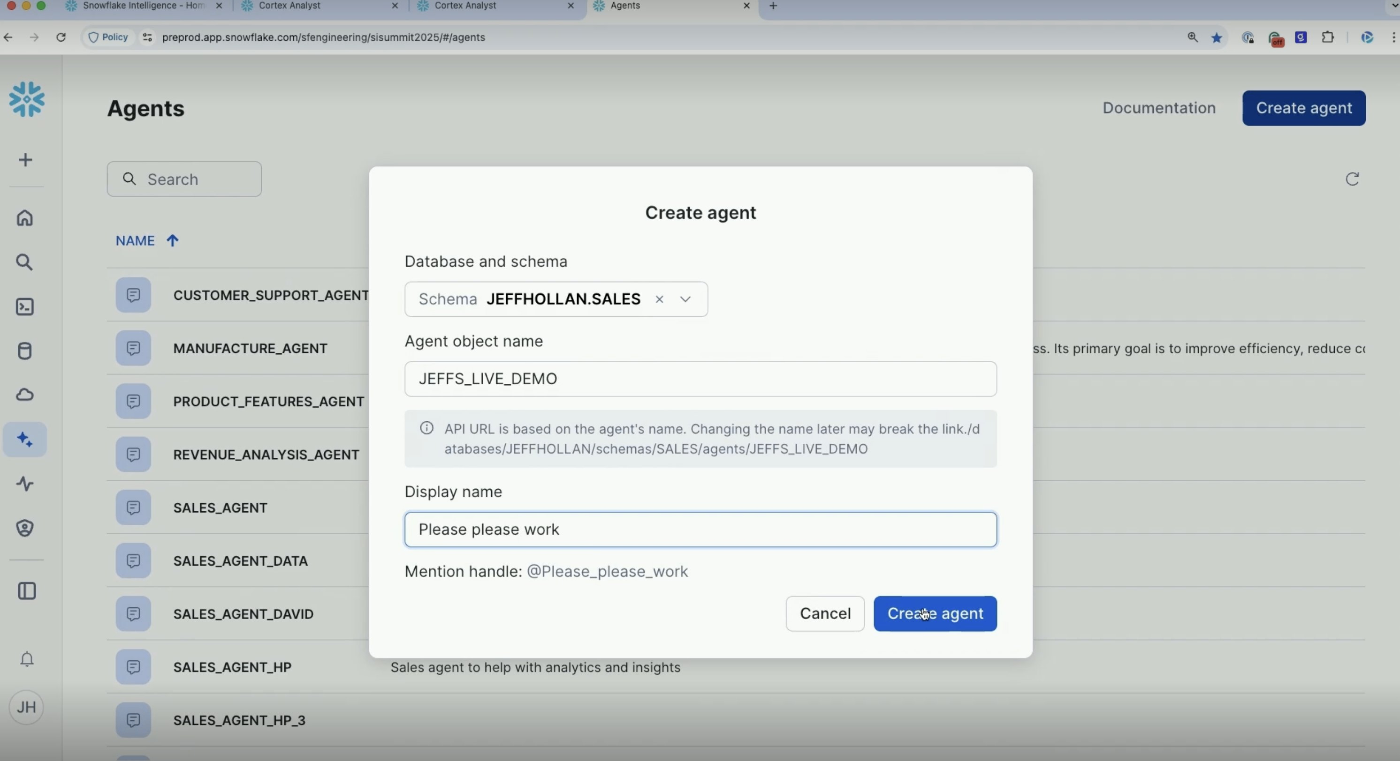
作成が完了するとオーバービュー画面に移動します。エージェントの設定が左側で確認でき、右側では実際にエージェントを試すことができます。ChatGPTのGPTsにそっくりなUIですね。

Editを押下するとエージェントを編集することができます。
編集画面では主にツール、オーケストレーション(モデルなど)、アクセス権限の設定をしていきます。ツールにはCortex Analyst(構造化データの検索)、Cortex Search(テキストデータの検索)、インターネット検索、その他、カスタムツールの指定をすることが可能です。
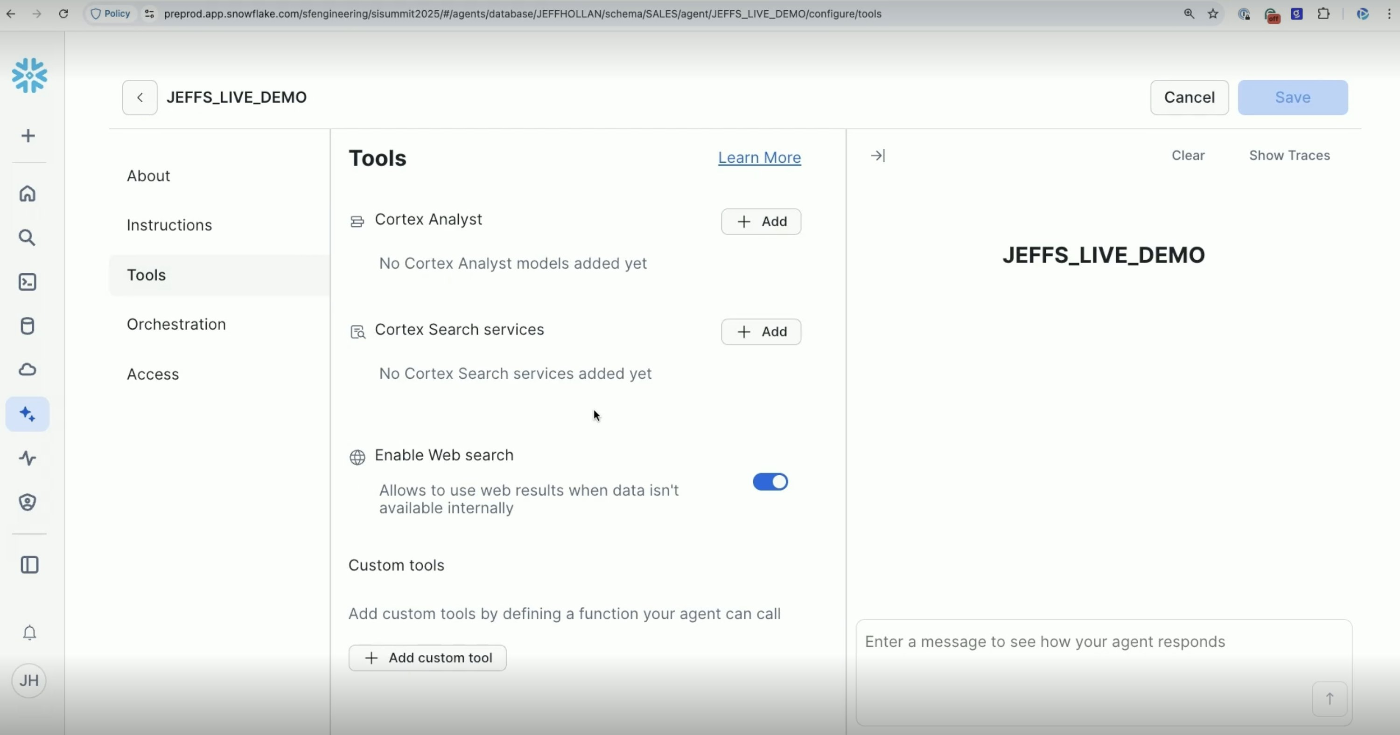
Cortex Analystの設定
Toolsを押下するとツールの設定画面に移動し、Cortex Analystの追加を行うことができます。
Cortex Analystの設定=セマンティックビュー(or モデル)の指定であり、セマンティックビューを通して検索対象のスキーマやテーブルを指定します。
「セマンティックビューを作らないとAIエージェントの検索対象として追加させないぞ」というスタンスがSnowflakeらしくて良いなと思います。
今後はエージェントのユースケースを意識してセマンティックビューを設計/チューニングすることが重要になりそうです。
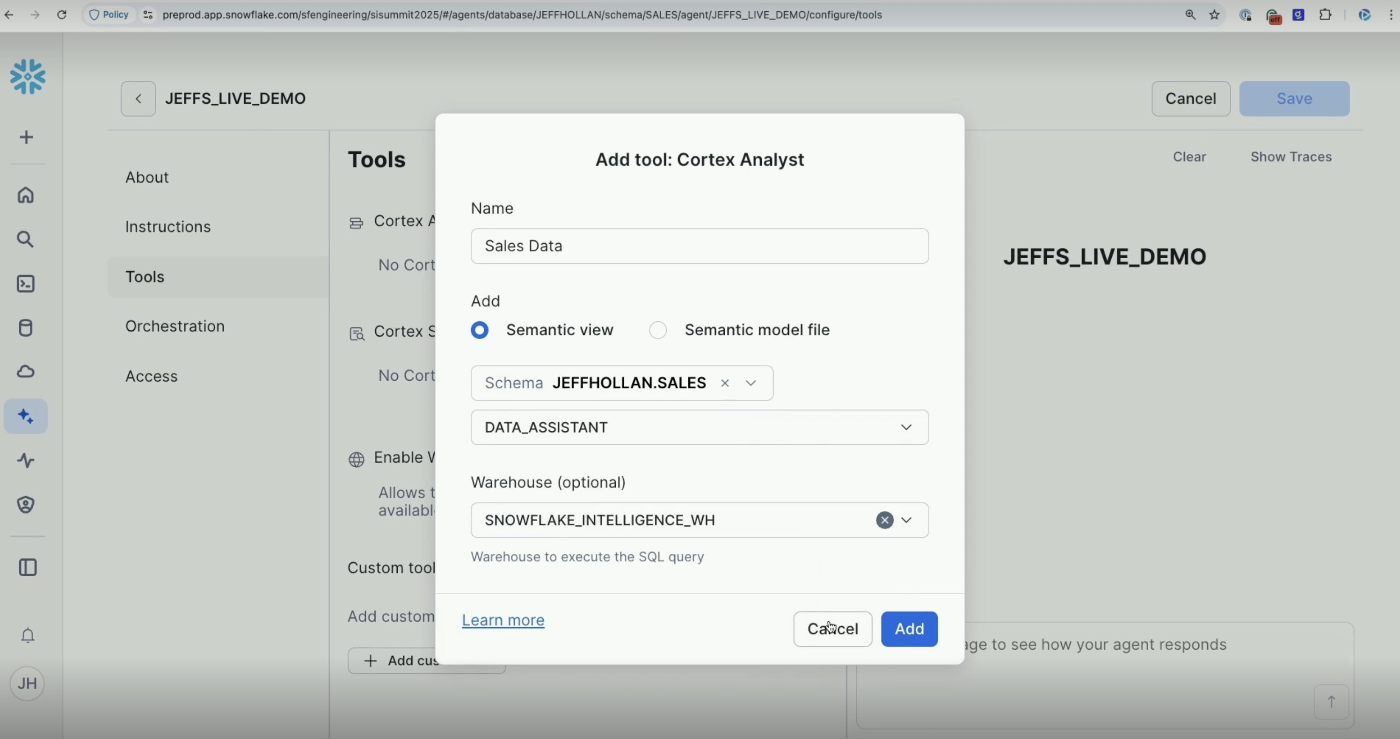
Cortex Searchの設定
Cortex Searchの設定画面では検索対象のCortex Search Service(以下、Service)を指定します。Cortex Searchの中身はベクトル検索とリランキングなので、色んな書類をごっちゃにせずドメインごとに適切なスコープでServiceを作り、エージェントに利用するServiceを判断させるのが精度向上において重要になりそうです。
今のところ、Serviceの作成画面にもServiceの設定画面にもServiceの説明文の様な属性は見当たらないので、内部的にAIがどのように利用するServiceを選択するのかはわかりません。
Service名だけで判断してるとは思えないので、内部的にデータから自動で説明文などを作っているのかもしれませんね。
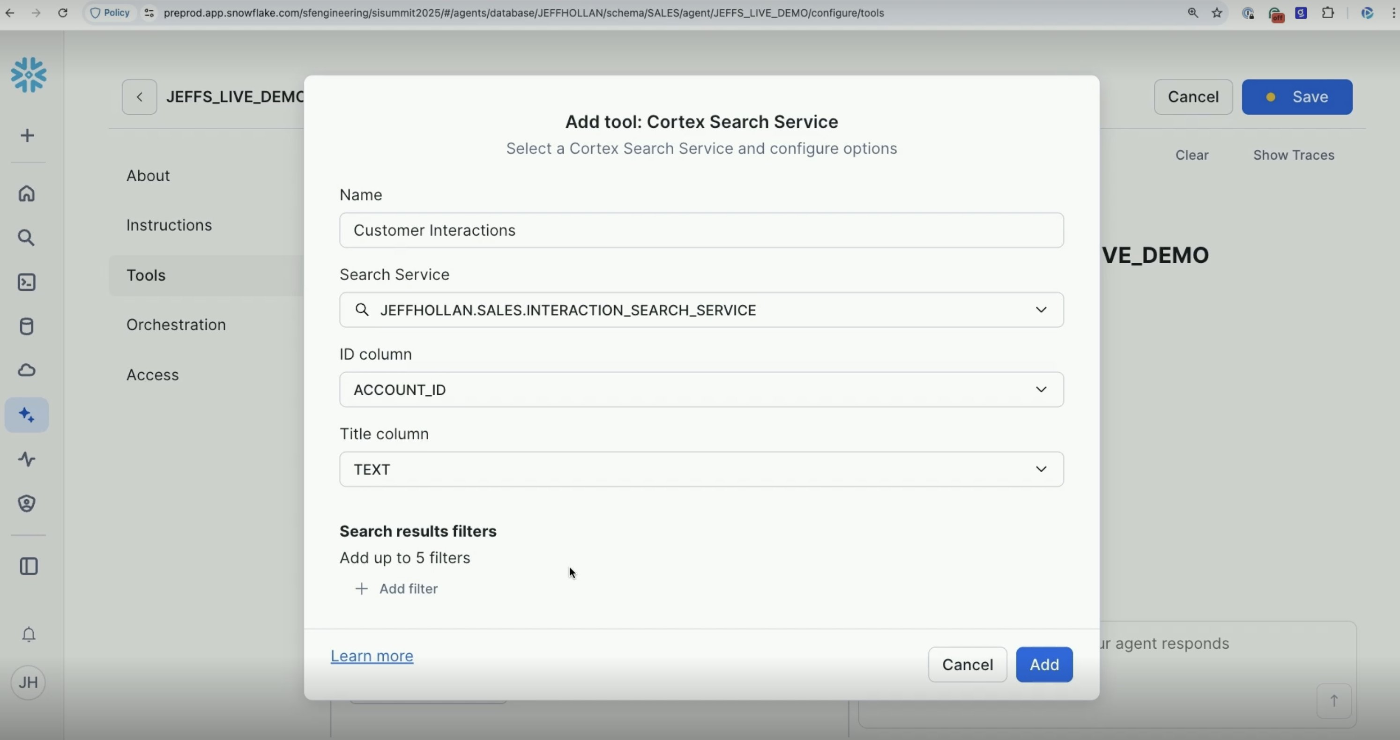
オーケストレーションの設定
オーケストレーション設定ではモデルとプロンプトを設定できます。
とりあえずは一番賢いモデルを指定しておけば良さそう。

加えて計画時のプロンプトも指定でき、デモでは「チャートが描けそうならチャートを書いて」「私達の決算期は〜です」という内容を指定しています。
これにより、AIエージェントがチャートのツールを利用するようになったり、クエリのレビューをする際に決算期を正しく理解できるようになります。
オーケストレーションは少しわかりにいく概念で、実行計画策定、ツールの選定、クエリの評価/書き換え、終了判定などを担当するステップです。そのうち、モデルや計画時のプロンプト以外もこの画面でカスタマイズができるようになるかもしれません。
アクセス権限の設定
最後にアクセス画面です。
Snowflake Intelligenceではエージェントがデータにアクセスする際はエージェントを実行したユーザーの権限が引き継がれます。これによりエージェントを経由して見れちゃいけないデータが見えることはないわけですね。
タスク実行ロールのようなものは導入せず、ユーザーロールで統一するところにもSnowflakeのこだわりを感じますね。
なので、この画面では基本的にやることはないのですが、特定のロールを持つユーザーだけに利用者を絞りたい場合はここでロールを指定します。

エージェントの全体像
これでエージェントの作成は完了です。
画面にするとステップ数が多く感じるかもしれませんが、やっていることはCortex Agentsの最低限の設定を画面から行っているだけです。
Cortex Agentsの全体像はこのスライドがわかりやすかったです。こうやって見ると本当にシンプルなエージェント機能ですね。

Snowflake Intelligenceのエージェント作成画面では、エージェント実装の基本的な機能をわかりやすいUIで提供している印象でした。
今後の展望に関する所感
最後に期待感もこめて今後のSnowflake Intelligenceの展望についての私見を述べたいと思います。
TruLensによる強化学習用のデータ収集と個社カスタマイズ
Snowflake Intelligenceのエージェントの実行ログ可視化の機能は他社よりもかなりわかりやすく感動しました。
それもそのはず、SnowflakeはLLM Appのオブザーバビリティの確保や品質担保のフレームワークを提供するサービスである「TruLens」を開発するTruEraを買収していたんですね。
Summitまで知りませんでしたが、Snowflake IntelligenceがTruLensのSnowflake統合のお披露目だったということですね。
また、SnowflakeはText2SQL R1というモデルで強化学習によるText2SQLの精度向上に成功しています。 この手法は生成されたSQLが正しいかどうかを二値(厳密には違いますが)で人間がFBするだけというシンプルなアプローチで精度の向上に成功している点で優れています。
TruEraによるログの可視化によりユーザーのFBを集め、強化学習を行い少しずつ検索精度を高めていく様なアプローチも将来は可能になるかもしれません。
ヘッダレスなAIエージェント基盤
今回のSummitの別のセッションでは、Cortex Agentsで構築したAIエージェントをCopilot Studioを経由してTeamsに埋め込むユースケースが紹介されていました。
Cortex AgentsをREST APIであることを強調して公開している点なども含めると、Snowflakeはエンタープライズデータの検索に強みをもつ高精度なAIエージェントを提供する基盤を目指している様に感じました。
強みのあるデータの蓄積や検索にリソースを投下し、強みのないアプリケーションレイヤーに関してはオープン戦略をとるのは、後から見ると当たり前なアプローチですが、一貫した戦略に基づいて機能がリリースできているのはすごいことですね。
今後はAPIを経由してSlack、Google workspaceなど、様々なアプリケーションに統合されたり、A2Aで他のエージェントから呼び出されたりするユースケースが増えていきそうです。
最後に
約2年前にナウキャストのデータAIソリューション事業の立ち上げを決めた時、「今後は生成AIの活用を前提としたより複雑で実装難易度の高いEDPが必要になる」と強く感じました。
データAIソリューション事業ではナウキャストのデータエンジニアリングの知見を活かしながら、生成AI時代のデータ基盤構築を支援するパートナーを目指しています。
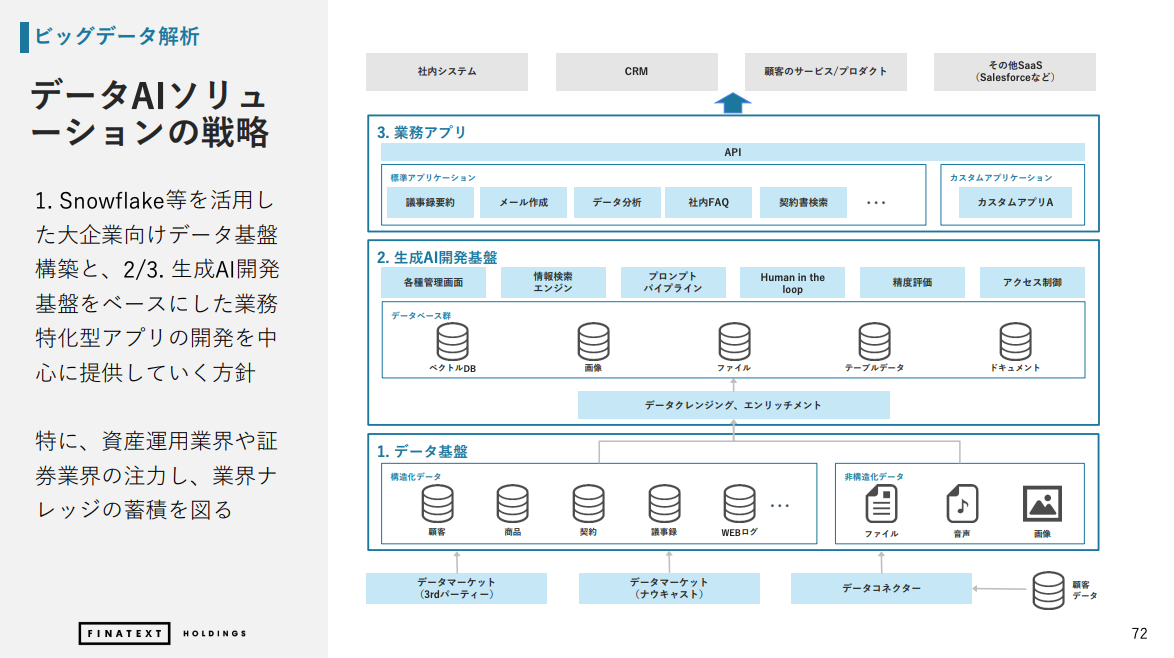
データAIソリューション事業の基本方針(FinatextホールディングスのIR資料より)
Snowflake Intelligenceを中心としたSnowflakeの戦略は「生成AI時代のデータ基盤」のあり方について一つの大きな方向性を具体的に示してくれた様に思います。
ナウキャストではSnowflakeを用いたデータ基盤開発や生成AI開発を行うデータエンジニア、LLMエンジニア、サーバーサイドエンジニア、インフラエンジニアを常に募集しています。
少しでも興味を持っていただけた方は以下のリンクからカジュアル面談ができますので、ぜひお話させてください!

Discussion