はじめに
はじめまして。ナウキャストでデータエンジニアをしている高橋です。Snowflake Summit 2025でSnowflakeのデータ変換パイプラインに関する機能について紹介されているセッションに参加してきたので、本記事ではその内容の一部を紹介しようと思います。(スライドの写真が一部見づらい点があるかもしれませんが、ご了承ください)
新機能のdbt Projects on SnowflakeやSnowpark、DynamicTableの機能拡張など新しい情報も含まれておりますので、チェックしてみてください!
Topics
今回の記事では、セッションの中で触れられていた以下のTopicについてまとめていきます。
- dbt Projects on SnowflakeとSnowflake Workspaceについて
- Dynamic Tableの機能拡張について
- pandas on Snowflakeについて
1. dbt Projects on SnowflakeとSnowflake Workspaceについて
こちらは、今回のSnowflake Summit 2025で発表されたSnowflakeの新機能になります!
Snowflakeとdbtが統合し、Snowflakeのユーザーがdbt projectの、構築 => テスト => デプロイ => スケジューリング => 監視の全ての作業をワークスペース内で行うことができるようになります。
これによって、システムが統合され新規開発者のオンボーディングが容易になったり、複数チームのコラボレーションがよりやりやすくなったと発表されていました。
セッションでは、Snowflake上でdbt projectを実際に実行するデモンストレーションが実演されました。
今回は、そのデモンストレーションの内容からSnowsight上でどのようにdbtを開発できるか、UIのイメージを載せながらまとめていきます!
Snowsight上のdbt projectのUIイメージ
最初に、Snowflake Workspaceでのdbt projectの利用について説明されました。
workspace上でdbtのprofileの選択や実行コマンドを選択・実行、DAGの表示などdbtの開発やテストがSnowflakeのUI上で行うことができます。
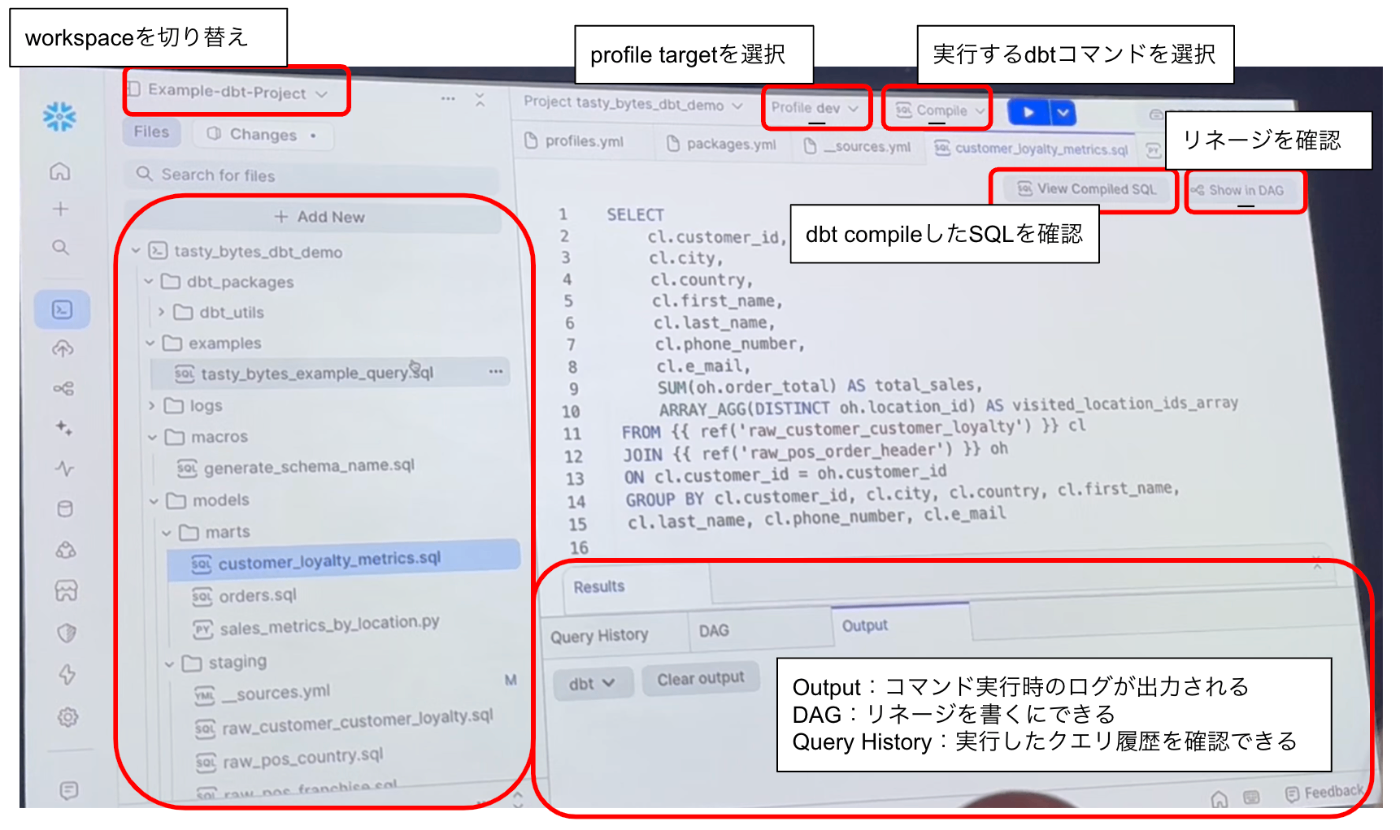
実行コマンドとして以下が表示されており、開発に必要な機能は一通り揃っているようでした
- Deps:dbt projectの依存パッケージをダウンロードする
- Show:model、test、analysisのSQLを実行し結果を確認できる
- List:projectの全てのリソースをリスト化する
- Compile: models、seed、snapshotなどのリソースをコンパイルし、実行可能なSQLクエリを生成する
- Run:コンパイルされたモデルをデータウェアハウス上で実行し、結果のテーブルやビューを作成または更新する
- Test:dbt projectで定義されたテストを実行し、データ品質や整合性を検証する
- Build:dbt run, dbt test, dbt seed, dbt snapshotを実行する
- Seed:CSVファイルなどの静的データをデータウェアハウスにロードし、dbt project内で利用可能なテーブルとして扱えるようにする
- Snapshot:データウェアハウス内の特定のテーブルの履歴を追跡し、データがどのように変化したかを記録する
- Run operation:dbt projectで定義された任意のマクロを実行する
作成されたモデルのDAGは以下のように確認することができます

dbt compileを実行すると、以下のようにcompileされたSQLクエリを確認できました

作成したdbt projectをdeployする際には、画面右上のボタンから[Redeploy dbt project]を押し、deploy先のスキーマとdbt projectを選択し[Deploy]を実行します

また、dbt projectをスケジュールで実行することもでき、[Create Schedule]から「スケジュール名」「実行タイミング」「実行コマンド」を設定し作成することができます。

また、去年のSnowflake Summit 2024で発表されたSnowflake Trailによるtelemetry機能との統合により、パイプライン実行に関する豊富なトレーシング情報が提供され、デバッグとパフォーマンス分析も簡単そうです!

Snowsight上でdbt projectを開発できるのは、個人的にとても嬉しい機能です。dbt projectのテンプレートを作成し、各開発者にそのテンプレートを配布し、自由にdbtでの開発を行えるようになれば便利だろうと想像しました。
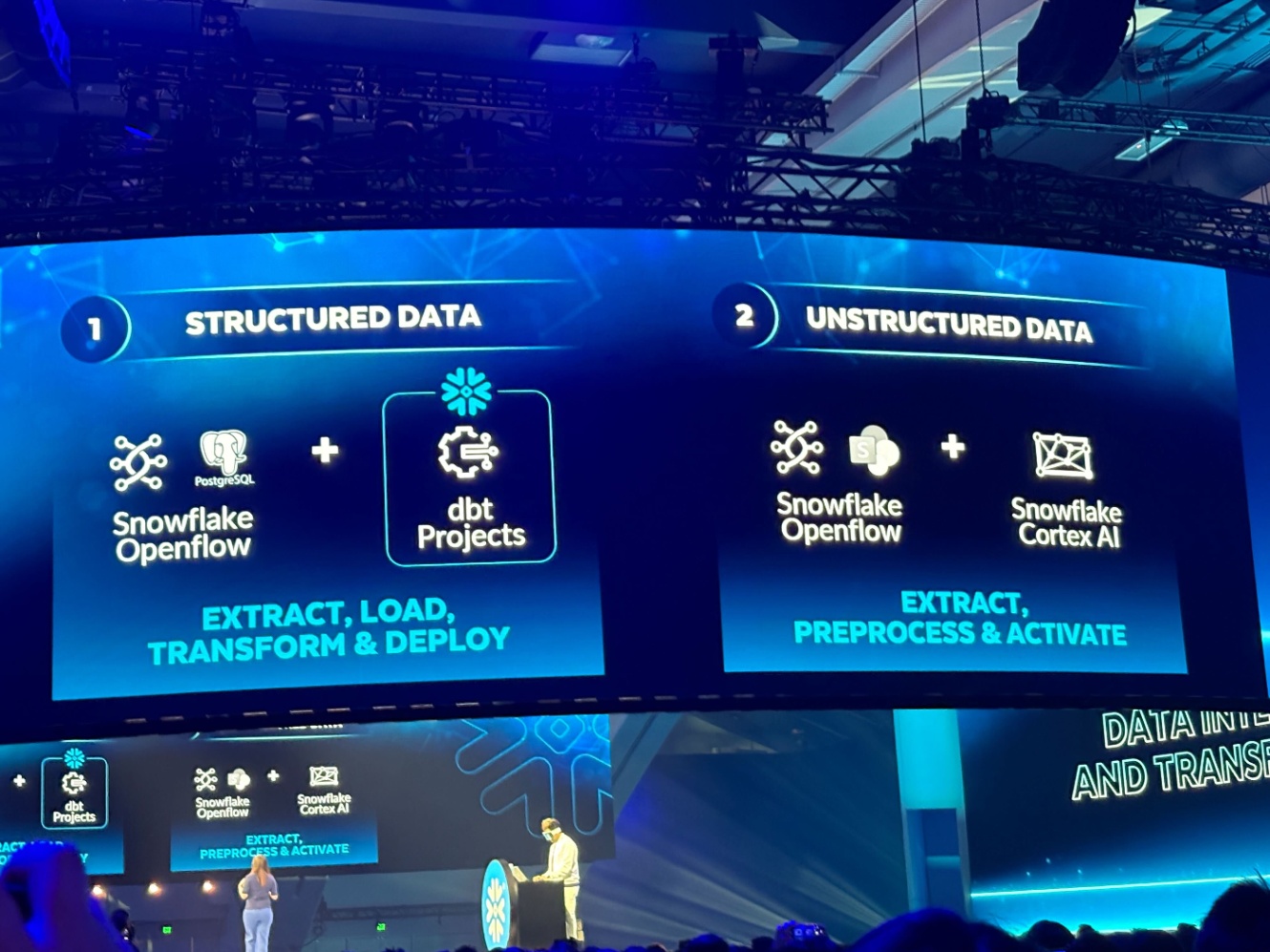
Platform Keynoteでは、以下の画像のように「構造化データはdbt project」「非構造化データはSnowflake Cortex AI」とデータ変換ツールとしてはdbtを標準として、今後もアップデートを続けていくものと期待しており、引き続きチェックしていきたいと思います。
2. Dynamic Tableの機能拡張について
Dynamic TableはSnowflake TaskとStream機能を組み合わせて、オーケストレーションを自動化しながら、連続的な増分データ処理をしてくれる機能です。
今回のセッションでは、このDynamic Tableの機能拡張について以下の点が発表されていました。
- Apache Icebergのサポート
- ニアリアルタイムパイプラインの構築が可能
- パフォーマンス改善
- 増分更新のための現在の日時によるフィルタリングをサポート

Apache Icebergのサポート
1つ目は、Apache IcebergのDynamic TablesのサポートがGA (2024年4月)されたとのことです。
これにより、Iceberg Tableでバッチまたはストリーム処理パイプラインが構築可能になりました。
リアルタイムなパイプラインの構築が可能
Dynamic Tableでより低いレイテンシのパイプラインをサポートし、最短15秒でデータを取り込み
ニアリアルタイムなパイプラインをサポートできるようになったと発表されました。
増分更新のための現在の日時によるフィルタリングをサポート
CURRENT_TIMESTAMP、CURRENT_DATE、CURRENT_TIME関数がincrementalモードの動的テーブルのWHERE/HAVING/QUALIFY句などで使用できるようになりました。
3. pandas on Snowflakeについて
今回、pandas on Snowflake with hybrid executionが現在プライベートプレビュー中であることが発表されました。
pandas on Snowflakeでは、pandas APIを使用してSnowflakeデータを扱うことができるようになり、使い慣れたpandasのAPIを利用しつつ、Snowflakeの分析関数をSnowflake内のエンジン上で実行できるようになる機能になります。
これまでインメモリーで実行していたpandasをSnowflakeのエンジンを利用して実行できるようになり、大規模なデータセットでも柔軟にデータ分析ができるようになるため、notebookだけでなく、dbt PythonモデルやStreamlit上での複雑なデータ変換処理の実装など、幅広い用途で活用することができます。
今回、新しく発表されたpandas on Snowflake with hybrid execution は、localで実行するのかPush DownしてSnowflakeのエンジンを使うのかを自動で決定してくれる機能みたいです。
開発者は、どこでコードを実行するのが最も効率的かを考慮する必要なく、慣れ親しんだpandasコードを書き続けることができ、パイプラインがスケールするにつれて、コンピューティングをSnowflakeエンジンにプッシュすることで、パフォーマンスとスケーラビリティの恩恵をシームレスに受けることができます。
ただ、Snowflakeがこの「インテリジェントな判断」を行う際に、具体的にどのような条件に基づいてローカル実行とプッシュダウン実行を切り替えるのかの説明はなかったと思います。


まとめ
今回は、dbt on SnowflakeやDynamic Table、pandas on Snowflakeなどデータ変換パイプラインについて新しい機能の発表を中心に速報的にまとめてみました。
開発者にとってよりSnowflakeが柔軟かつ簡単に開発ができる機能が多くリリースされ、とても嬉しいですね。


Discussion