導入
こんにちは。株式会社フェズ プロダクト開発部部長の海沼玲史です。
普段はプロダクトエンジニアを名乗りプロダクトのためならなんでもやると宣言しチームのボトルネックを見つけ解決するムーブに努めています(できていないことも多々あります)。最近のボトルネックは採用なので採用活動を強めています。
昨今の生成AI時代のソフトウェアエンジニアとしては(特に新卒の方や経験が浅い方にとっては)、どんな職種でどんな働き方をすれば良いんだろうということに思い悩むことも多いのではないでしょうか。
実際私自身もこれまでバックエンドエンジニア/SRE/データエンジニアをそれぞれ経験してきていますが、それらの経験が一般的に定義される「バックエンドエンジニア」「データエンジニア」など職種の責任範囲のみだけで業務をしていたことは少なく、むしろそれぞれの領域にまたがる雑務を全て吸収することでなんとか価値を発揮して生き延びてきたという実情があります。
自分ごととしても思い悩むのに、チームとして/組織として、どういうエンジニアがより活躍できるか?どういうエンジニアがより評価できるのか?もしくは目指すべきなのか?の目線が合うわけはありません。
そこで今後どのようなエンジニアになっていくべきだと思うのか、開発組織としての目線を合わせ、同じ方向性を目指すべくエンジニア職について2025年現在の考え方を取り入れ再定義を行いました。
前提
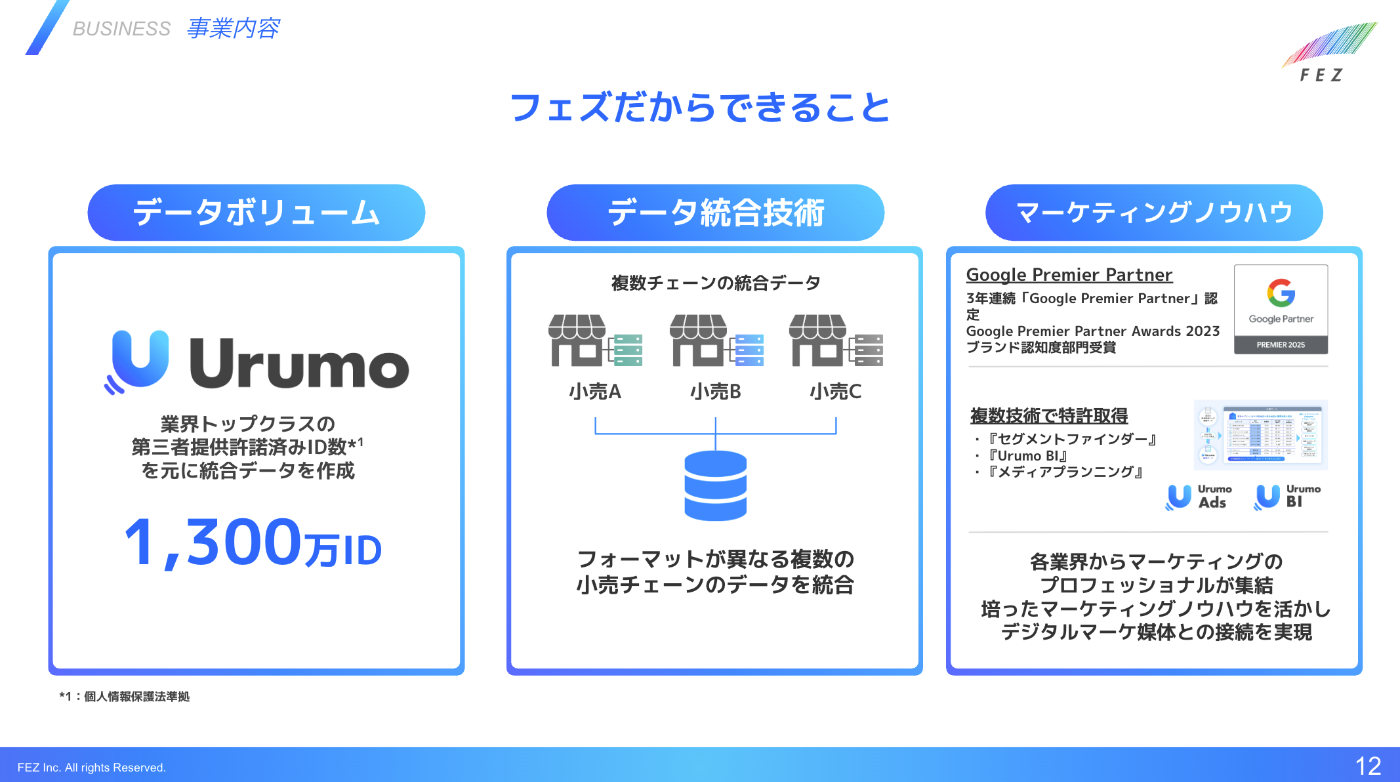
株式会社フェズは、小売業界の複数流通様からお預かりした業界トップクラスのデータ量となるIDPOSデータ(=売上に紐づく会員情報を含む実店舗の売上データ)を中心に
- リテールメディア(≒広告)事業
- データプラットフォーム事業
など複数の事業を展開する会社です。

特に私が所属するプロダクト開発部では Urumo BI(実行性の高いデータ分析を支援するAIを組み込んだ新時代のBIプロダクト) をメインに開発しています。
通常のWeb開発の経験・技術に加え大量のデータをどのようにプロダクトに組み込むか、どのように価値に変えるか、を検討・設計する必要があります。
よってデータを中心に全ての開発プロセスを検討する必要があり、エンジニアとして担保するべき責務範囲を整理すると概ね
- データを集約し使える状態にする責務(DWHを利用者に展開するまでをスコープとする)
- DWHを使ってビジネス価値を創造する責務
- ビジネス価値を実現するために必要なデータ開発・プロダクト開発を行う責務
という3つの段に責務を整理することができます。
一般的なWebプロダクト開発組織に比べてデータの比重が重いのが特徴です。
この前提をベースに、生成AI時代にあるべき開発組織とは?というトップダウンの考え方と実作業ベースのボトムアップの考え方をそれぞれ織り交ぜ、生成AI時代に求められる責務の再定義を行いました。
すべての職種に共通する生成AI時代の価値
- ヒューマンインザループの考え方を組み込み「人が判断するポイント」「積極的に生成AIに任せる領域」を見極め仕事を効率化できる素養
- 生成AIの最新状況をキャッチアップし、従来の業務アクションを改善し続けられる素養
- 「構造化」と「合意形成」
プロダクトエンジニア/LLMエンジニア
従来の責務
- API設計・開発、データベース設計・管理
- アプリケーションのパフォーマンス、信頼性、セキュリティの担保
- インフラの構築・運用(デプロイ・CI/CD)
生成AI時代の責務(再定義)
- コア価値
- プロダクト要件に基づきデータエンジニアと連携してAPI/DB設計に関するドキュメントを整理しつつ、生成AIによる設計・コード支援を前提としたアーキテクチャ選定と開発プロセスの最適化を推進する
- 構造・設計・ナレッジ集約を掌握できる
- 差分
- 「コードを書く人」から「コードを書くAIを設計する人」へ
- 「システムを設計する人」から「AIと協調する構造を設計する人」へ
- 「仕様をコードに落とす人」から「仕様をAIが理解できる形で表現する人」へ
| タスク | 従来の割合 | 生成AI活用後の割合 | 変化のポイント | 必要な意識 |
|---|---|---|---|---|
| 要件整理・設計 | 20% | 40〜50% | 設計の質が全体の成果を左右するため、重視度が上がる | 正しい仕様をプロンプトやコメントで伝える能力 |
| コーディング(実装) | 40% | 15〜25% | コードはAIに書かせる。人はプロンプト・レビュー・組み合わせに集中 | 「伝わる設計」と「AIで量産可能な形式」 |
| テスト設計・実行 | 20% | 10〜15% | 単体テストの生成はAI任せ、統合・シナリオテストに集中 | テスト戦略設計+AIが出したコードの意図チェック |
| インフラ・CI/CD運用 | 10% | 10〜15% | IaCやAIOpsを活用し、設計・監視中心に変化 | |
| ドキュメント・ナレッジ共有 | 10% | 10〜15% | ドキュメント生成もAI支援、ただし共有文化の設計がより重要に | 自動Doc生成も活用しつつ、「誰が何のために見るのか」を意識したナレッジ構造設計へ 組織内に向けたプロンプト共有・リファレンス整備も業務の一環 |
データサイエンティスト
- ビジネスに対して示唆を与える高度人材として、統計・機械学習・データ加工・可視化すべてを担う役割として期待されていたが実態としては職能の広さゆえに 「全方位に忙殺される職種」 になりやすく、再現性やプロダクト実装からは乖離しがちだった
- 分析に必要なデータマート整備が進み、「集計して可視化する」だけの業務は専門職でなくても遂行可能になる一方で、より抽象度の高い問い・予測・仮説探索などは依然として高度なスキルと経験が必要
- ビジネスとAIの間に立ち、「問いの設計・示唆の導出・意思決定支援」を行う職能→人間中心の「意味処理レイヤー」に責任を持てるかどうか
従来の責務
- ビジネス課題に対するデータ探索・仮説構築・モデル選定・評価
- データ処理・特徴量設計・前処理・アルゴリズム実装
- 可視化や説明資料の作成、施策への示唆の提供
- 一部ではABテスト設計や統計的有意性の検定なども担当
生成AI時代の責務(再定義)
-
コア価値
-
曖昧な問いを「AIが理解し、分析可能な構造」に変換する媒介者
→ ビジネスからの自然言語の課題・疑問を分析ロジックに翻訳し、AIと協働して解釈可能な形式へ落とし込む力
-
データからの「解釈可能な示唆」を人・AIの協働で導くファシリテーター
→ LLMと共に示唆をナラティブに構造化・言語化することで、意思決定プロセス全体に価値を与える
-
プロンプト設計とデータ分析を融合した「分析設計者」
→ 単なるアルゴリズム選定者ではなく、自然言語・プロンプトでの分析指示、結果の品質評価、精度チューニングを設計できる役割
-
-
差分
- 分析者から分析設計者へ
- データを渡されて分析するだけでなく、問いの構造・前提・プロンプトまで設計
- 示唆を出す人から示唆を導く流れを整える人へ
- 解釈をAIと共同で作り、説明責任を持つ
- 「自分で手を動かす」から「AIを動かして確認・編集」へ
- コードや可視化の生成を委ねつつ、本質的な判断・チューニングに集中
- 分析者から分析設計者へ
| タスク | 従来の割合 | 生成AI活用後 | 変化のポイント | 必要な意識 |
|---|---|---|---|---|
| 仮説・分析設計 | 20% | 35〜40% | 問いの粒度・構造次第でAIの性能が変わる | 構造化・自然言語記述力 |
| データ前処理・加工 | 30% | 15〜20% | 基本処理はAI+ETLツールで自動化可能に | 検算と前提確認 |
| モデリング・アルゴリズム選定 | 25% | 20〜25% | LLMやAutoMLでベースライン構築が加速 | 精度評価・運用可能性判断 |
| 可視化・示唆の生成 | 15% | 20〜25% | ナラティブ要約・視覚化補助にAI活用 | 伝わるストーリー構成力 |
| レポート・ナレッジ共有 | 10% | 10〜15% | 自動ドキュメント生成と人間の編集のハイブリッド | 再利用されやすい表現力 |
データエンジニア
- クラウドの進化に伴いデータエンジニア単体の職責は狭く薄くなってきており、アナリティクスエンジニア/データマネジメント/データスチュアードなど微妙に細分化されていた領域が一つの職責に集約される未来が来るだろうという立場視点の整理
- それらを内包する形で「データサイエンス」以外のデータ領域のすべてを担う想定
従来の責務
- データ基盤設計・構築(DWH、ETL/ELTパイプライン)
- データマート・スキーマ設計、クレンジング・整形
- モニタリング・品質担保(欠損・型・変動)
- BIツール/SQL/ログ基盤の整備・運用
- データドキュメンテーション・スチュワード業務(ガバナンスやリネージュ管理)
生成AI時代の責務(再定義)
-
コア価値
-
「人とAIが正しく使えるデータ構造」を設計・保証する責任者
→ 単なるETL運用ではなく、「誰が」「どのように」「どの文脈で」使うかを意識したデータ設計
-
生成AIと人の両方にとっての“Queryable”で“Reasonable”な構造をつくる
→ LLMが参照できるナレッジグラフ的構造や、RAG用の分割・メタ情報付与設計など
-
データライフサイクルとメタデータの設計者
→ 「いつ・誰が・何を目的に・どんな粒度で使うか」を体系化し、プロダクト的に運用する意識
-
-
差分
- 「ETLを書く人」から「データ契約と構造を設計する人」へ
- パイプライン構築より「正しく使える構造」の設計と運用に価値が移る
- 「技術運用者」から「意味を扱うデータファシリテーター」へ
- データの意味を明示し、他者と接続する責任を担う
- 「静的定義」から「動的メタ構造設計者」へ
- モデル更新やプロンプト変更に耐えるメタ情報管理の再設計
- 「ETLを書く人」から「データ契約と構造を設計する人」へ
| タスク | 従来の割合 | 生成AI活用後 | 変化のポイント | 必要な意識 |
|---|---|---|---|---|
| ETL/ELT実装・整形 | 40% | 15〜20% | 汎用処理はSaaS or AIへ。再利用可能な定義・テンプレ化が重要 | 抽象化・標準化能力 |
| データ設計・マート設計 | 25% | 30〜35% | LLM/BI活用を想定した正規化・非正規化のバランスが鍵 | セマンティック設計 |
| 品質管理・監視 | 15% | 15〜20% | テストコード生成・監視定義もAI補助可能に。重要度は維持 | 組織的品質保証設計 |
| ドキュメント・カタログ整備 | 10% | 15〜20% | 自動生成を活用しつつ、可読性・共有設計がより重要に | メタ情報の意味づけ |
| ユースケース支援(BI/DS連携) | 10% | 10〜15% | AI分析のベースをどう作るかという視点での連携が増加 | データ民主化の支援力 |
補足
上記の整理はまだ具体的なタスク・issueに掘り下げられる状態ではありません。
例えば直近ではデータエンジニアとして・データ基盤の進化の方向として間違いなく「生成AIにいかにデータを食わせるフロー・環境を構築するか=AI Readyなデータ基盤を構築するためには」というissueが中長期にかけて最も重要であることに疑いの余地はありませんが、上記の整理から前述の結論に着地できるほど具体的な解釈ができる状態ではありませんし、最終的な着地点も定められておりません。(あくまで目線合わせとして半期単位で振り返る程度に利用するのか、最終的にエンジニアリングラダー/評価定義まで落とし込むのか(個人的には望みませんが)は会社の状況によって様々でしょう。)
が、それでも議論のたたき台には十分なりえる粒度に整理したつもりですし、実際に弊社でもこれをベースに議論を始めています。
いずれにせよ生成AIをいかに組織にインストールし、いかに最適な組織を設計・構造化するかについては組織の中でしっかり議論し落とし込んでいくプロセスが不可欠ですし、議論にあたっては生成AIについての理解も不可欠=ソフトウェアエンジニアとして生成AIをしっかり使い込んでいく必要があるでしょう。
この記事をもとに議論が起こり、各社の開発組織に少しでも動きを与えられたら嬉しいです。
終わりに
いかがだったでしょうか。「なるほど!」と思えるポジティブな箇所もあれば、「それは本当か?」と疑いの気持ちを持つ箇所もあるかもしれませんね!
フェズでは、上記のような責務整理の中で Urumo BI を共に開発する プロダクトエンジニア / データエンジニアを大募集中です。
興味のある方は 直接DMいただくか, 採用サイトよりご応募お待ちしております!

フェズは、「情報と商品と売場を科学し、リテール産業の新たな常識をつくる。」をミッションに掲げ、リテールメディア事業・リテールDX事業を展開しています。 fez-inc.jp/recruit
Discussion