こんにちは。 生成AIとBIを組み合わせた次世代BI「Urumo BI」を開発するプロダクト開発部の海沼玲史です。
2023/10 に開発をスタートしたプロダクトがローンチ後1年経過したので、開発状況を振り返りながら苦労した点や工夫した点などテクニカルなTipsを交えつつ赤裸々に紹介させていただきます。
(Google Cloud Next"24 にて登壇した資料データ分析を支えるLookerを用いた生成AI + BIプロダクトについて、より詳細に解説した記事です)
プロダクト概要
BIサービスとはデータベースをバックエンドに「集計・可視化」を責務とする、データからビジネス上の示唆を得るためのツールです。
TableauやPower BI、エンジニアであればLooker/Redash/Steep/Streamlitなどをイメージしていただければより分かりやすいと思います。
従来のBIサービスは便利な半面、難しさを多分に含みます。
利用者にとっては「データを使ってビジネスに活かしたい」だけなのに、
- どのようなデータを準備して
- どのような可視化を行い
- どのように解釈し
- どのように行動するか
はすべて利用者任せという建付けになっているためです。
これは「データ分析」の本質的な難しさでありBIサービスが悪いということではありませんが、実際BIサービスを開発するに当たって多くのユーザーにヒアリングする過程で、「とりあえずBIを導入してみたが使いこなせない」「年間1000万を超えるコストを支払っているが運用できていない・メリットを享受できていない」という声をたくさんいただきました。
昨今、データエンジニアリングに関連するエコシステムの充実によってデータまたはデータ基盤の民主化自体は随分推進しやすくなったものだなと思う反面、まだまだ「データ分析の民主化」にはハードルがあるというのが実情です。
そこでデータ分析の難しさを解決するために、小売データ(日本屈指のデータ量を誇るIDPOSデータ)を対象に生成AIを組み合わせ開発したBIサービスが「Urumo BI」です。
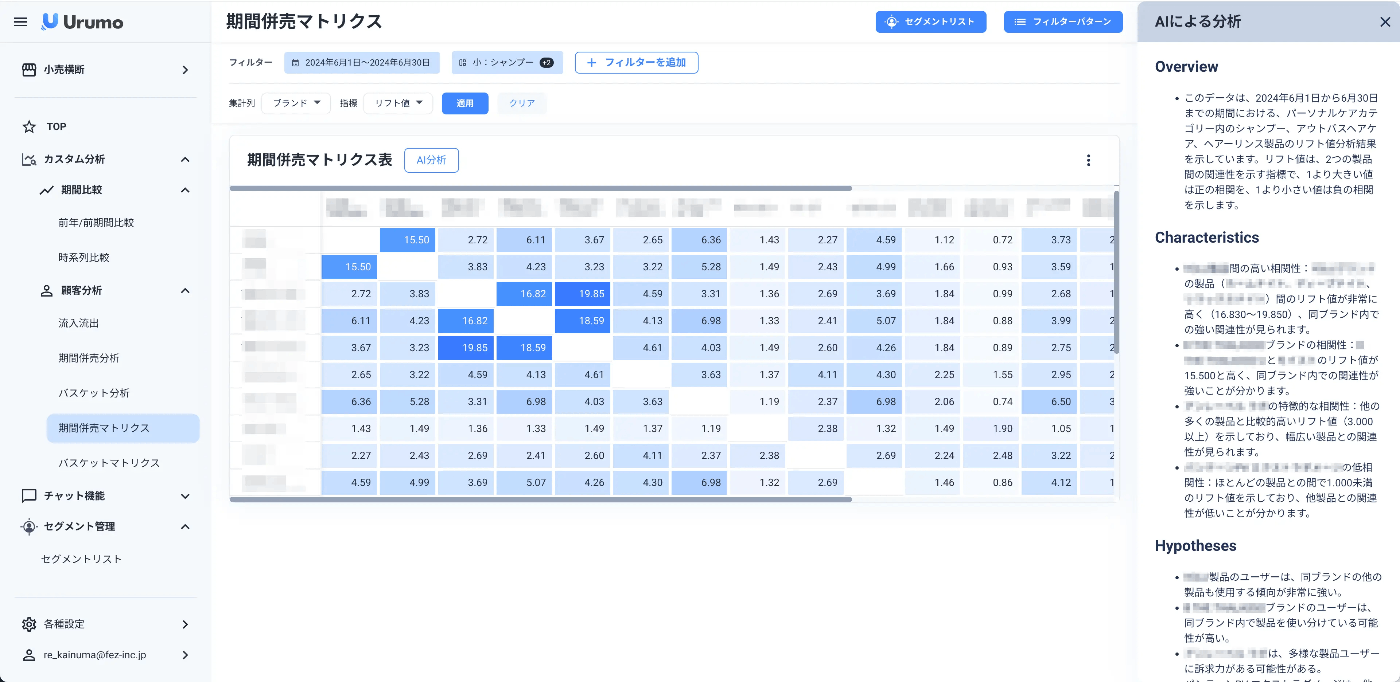
Urumo BIの持つ「AI分析」機能。出力したデータに関する解釈と仮説・次のアクションを提案する
開発経緯
開発のきっかけとしては大きく2つの理由がありました。
1. データ分析プロセスを資産化し、開発効率を上げる
実は弊社では、他に2つのBIサービス(Urumo Explorer / Urumo Shopper)を運用していました。
それぞれのサービスにはそれぞれの特徴があり素晴らしいプロダクトではあったのですが、以下のような課題がありました。
- データ分析ロジック(SQL)はそれぞれの開発チームで実装が行われるがアプリケーション中にSQLが直接にコーディングされアプリケーションと分析が密結合している状態
- アナリストなどWeb開発者以外のメンバーが分析ロジックに修正を加えたいとき、Web開発者にSQLの修正依頼をし、Web開発のライフサイクルとしてQA・リリースを行うという形になっておりリリースまで時間がかかる
- それぞれのBIサービスで同じような分析ロジックを別に開発する工数が発生しており、加えて微妙に数値が違うというケースも存在
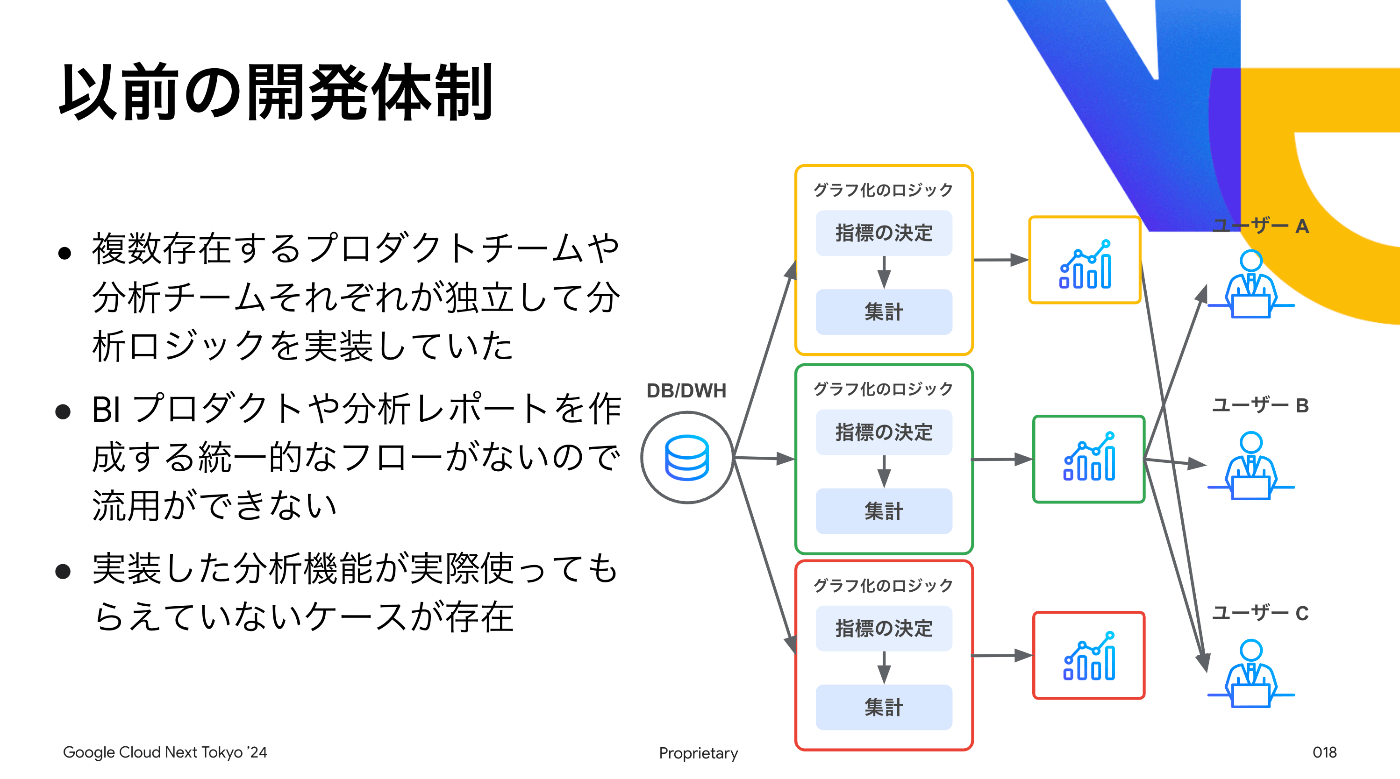
そこで分析ロジックを一箇所に集約し、「Web開発とデータ分析ロジック開発の分離」「分析プロセス資産化」が必要になりました。
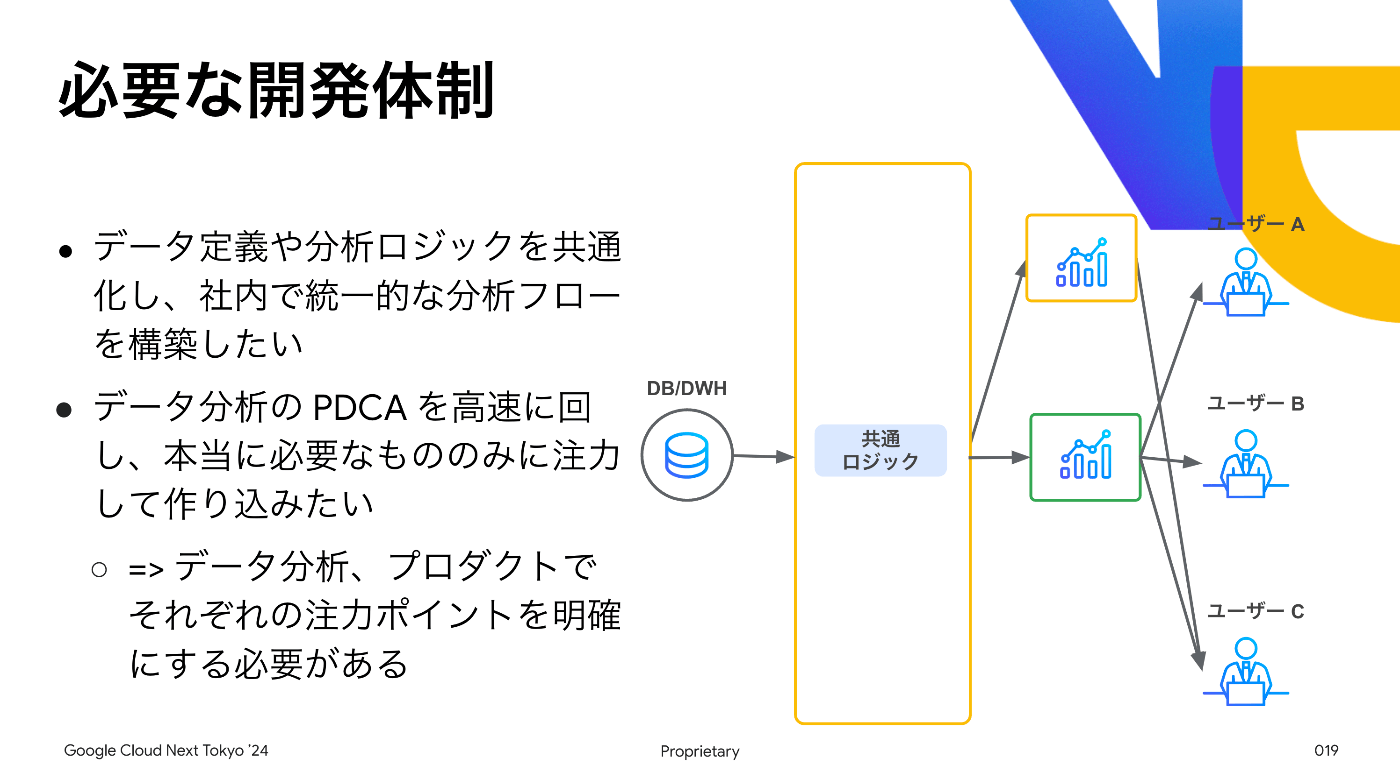
つまりSemantic Layer Proxyレイヤを新規に整備・構築し既存プロダクトの共通基盤にできればよい[1]という整理ができました。
2. AI使っておもろいことやりたい..AI使っておもろいことやりたくない?
2022/10 にChatGPTがリリースされると2023/01 には1億ユーザーに利用されるようになるなど、2023年は多くのITエンジニアにとってワクワクと焦燥が同時に発生した年だったのではないでしょうか?
例に漏れず私自身も2023年にChatGPTで遊び始め、勝手にコード解釈して解説して欲しいというモチベーションでrepositoryのソースを読み込んでチャットで質問できる環境を作ってみたりし、プロダクトに組み込むにはどうあるべきか、ということを考え始めていました。
(余談ですが2025年現在ではモデルの進化やClaude Code/CodexなどのCoding Agentの登場によって開発体験自体が大きく変わっていますね。ここ1-2年の出来事なのだから恐ろしい。)
ちょうど社内向けのダッシュボード利用用途でLookerの採用を決めつつある中で、「生成AIがデータ分析実行してくれれば便利だな?」 => 「Semantic Layerと生成AI組み合わせればAIが精度高くデータ分析やってくれるな?」と思考が少しずつ洗練され、結果的に生成AIとSemantic Layerを組み合わせたプロダクトの開発がスタートしました。
生成AIを使ったプロダクト開発初手としてありがちなチャットbot開発が始まった瞬間
PoC(プロト開発)
2023/10 に開発に着手し、まずは
- Semantic Layerをバックエンドにすることで他のBIサービスの開発効率が上がること
- 生成AIの精度がそれなりに実用可能な状態または見込みがあること
を達成項目として6ヶ月のプロト開発フェーズを開始させました。
当時は(今もですが(笑))特に生成AI回りに関しては不確実性が高く、開発組織として担保したい開発効率性と新規プロダクトとしてのMVPの達成を同時に実現させるためには高速なスクラップ&ビルドが必要不可欠でした。
最悪PoCの成果物は最悪全て捨て去ることも視野には入れつつ、サーバー・フロントともに負債にならないように極力シンプルな構成にすることを意識し、下記のような技術選定を行いました。[2]
開発スコープ
「どんなデータ分析をしたいか日本語で入力すると分析結果と示唆が返ってくる状態」をゴールとし、
体験として「簡単にデータを取得できる世界」「データと示唆を得ることで何かしらの価値ある行動に落とし込める」を与えられるか判断する。
バックエンド
前提として他のViewerプロダクトのバックエンド全般を担う責務があるシステムのため、
スケーリング性能・パフォーマンス性能・長期メンテナンス性に重きを置いている。
複雑さが増すような意思決定はなるべくしない。
シンプルに保つための議論は都度十分に行う。
-
フレームワーク
FastAPI on CloudRunを採用。
データアナリスト・サイエンティストがデータ分析のために作ったワンショットスクリプト・アルゴリズムをすぐに組み込めるようPythonを選定する。
アプリケーションレイヤーにおけるデータ設計は少なくとも初期フェーズにおいて複雑なモデリングの必要がない。基本的な考え方として「なるべくシンプルに」を前提とし、最初から便利機能が盛り込まれているDjangoよりもシンプルかつ高パフォーマンスであるFastAPIを採用。 -
ディレクトリ設計
- APIのエンドポイントとディレクトリ/ファイルの関係性が直感的になっていること
- モデル層が肥大しすぎないようにORMのモデルファイルとユースケース毎のロジックがきちんと分離されていること
- レイヤー毎の処理責務を侵害しないこと
に気をつけつつ実装する。
フロントエンド
短期スコープではあくまでバックエンドシステムがメインのアプリケーションであり、
提供する体験としては「データを取得する手間を最小化し、データの取得の価値を感じてもらう」ものに留めるためスクラップ&ビルドしやすい環境にし体験の検証を行いやすい状態に留める。
-
フレームワーク
Next.js を採用。verとしては13以降を前提とするが、App Routerは必ずしもマストとはしない。
ランタイムBun(※後述)では 2023/10 時点で Next.13 App Routerに対応しておらず、App Router採用のメリット、Bun利用時の開発効率観点でのメリットとのトレードオフとして少なくともプロトフェーズではBun + 非App Router前提で進行する。
ただし早い段階で Server Componentsのメリット = App Routerのメリットについてきちんと検討する必要がある。 -
CSS
CSS in JS を採用。 @emotion/react による String Styles でcssを記述する。Figmaとの連携観点でメリットが大きいと考えたため。
- https://techblog.zozo.com/entry/zozotown-css-in-js
- https://techlife.cookpad.com/entry/2021/03/15/090000
などの企業ブログの採用理由を全面的に信用する。
当時はまだMulti Agent構造を簡単に実現する仕組みはありませんでしたが、 LangSmithでプロンプトを管理、ソースコードから分離することで デプロイせずとも生成AI単体のPDCAを回せるようにする などとにかく検証と開発がそれぞれスムーズに進行できる状態を意識しながら、小さいチームだからこそ開発の障壁なりうる全てに対し細かく解決するよう努めました。
検証から実運用へ
基本コンセプト(Lookerをバックエンドに生成AIによって自然言語を使って分析実行する仕組み)を実現後、既存運用のUrumo Shopperに組み込まれていた分析項目(SQL/フィルタ・集計の仕組み)をUrumo BIに載せ、既存ユーザーのmigrationを行うことをローンチのためのミニマムスコープと定義しました。つまりこのタイミングでPoCの成果物をそのまま顧客展開するインターフェースを含むプロダクトに昇華する意思決定をしました。
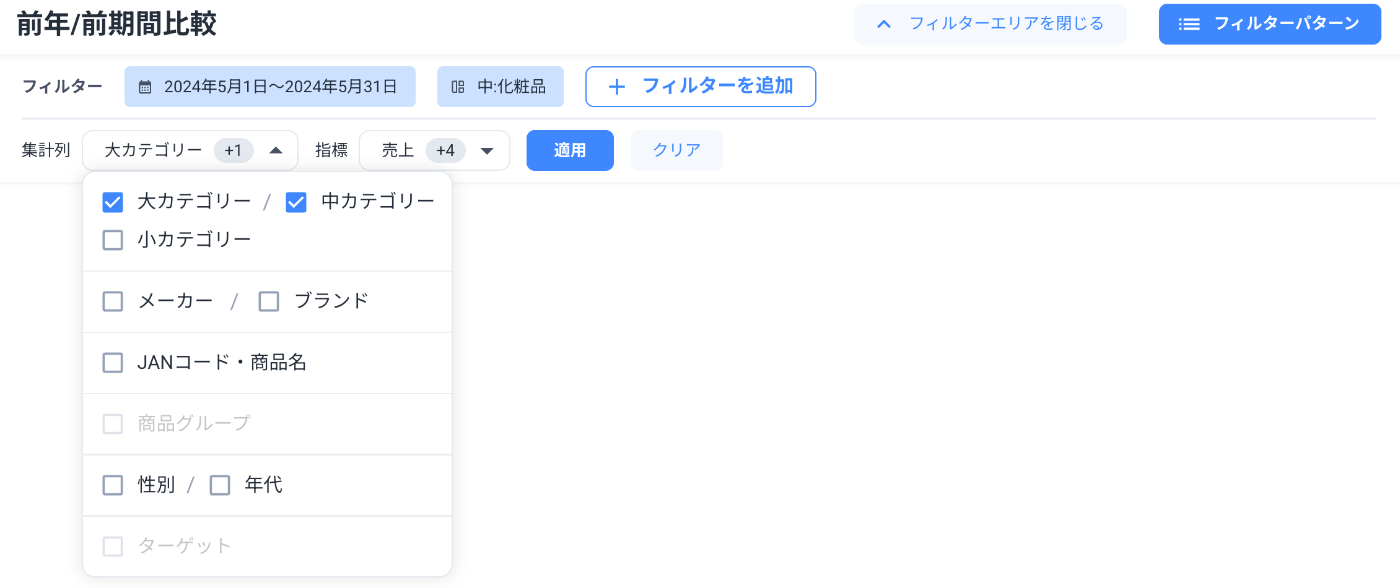
フィルタ・集計を担うコンポーネント
実際に小売・メーカーのユーザーが業務のためデータ分析用途で利用することを前提としたとき、一般的なBIの設計=どんなフィルタでデータを抽出し、どの単位で集計するのかを柔軟に指定できる仕組みが当然必要です。とはいえこれでは普通のBIサービスと何ら変わりはありません。
そこで、生成AIがあるからこそ実現できる・恩恵がある機能として データの解釈をサポートするためにAIを利用するAI分析機能 を再定義、PoCで実装したコンポーネント群を使いまわし、Urumo Shopper(通常BI) + 生成AI(解釈サポート) = Action BI(実行性のあるデータ分析プロダクト)、とコンセプトが洗練されました。
Shopperの機能をAction BIに載せ替える作業自体爆速に進み、約3ヶ月後の 2024/7 頃無事にUrumo BIとしてローンチすることができました。
(Shopperから移管した実利用者からも「体験が良くなった」「データ分析しやすくなった」などの喜びのお声をいただき、特に導入企業の全社会にて「これからはUrumo BIをしっかり使っていく」という社長からのメッセージが展開された、という情報を教えていただき、何にも代えがたい興奮を覚えました。
ローンチ後のFBは何よりも嬉しい
ローンチ後の状況
上記では生成AIを使ったプロダクトの開発経緯、特に一般的に想像しうるデータ分析という文脈でのBIプロダクトに焦点を当てて紹介してきました。
新たな試みを組み込んだプロダクトとしてはPoCから1年で特許をとりローンチしtoBプロダクトとして運用ができているという意味でかなりスムーズに進行した珍しい事例だと感じますが、一方事業的にはまだまだこれからもチャレンジが続く見込みです。
根本的に言えば「データ分析」というプロセスは殆どの場合業務に絶対に必要なものではなく、あくまで「より売上を高めるため/よりよい施策をうつための投資」 とみなされ、導入していただくにはそれなりにハードルがあることがわかっています。
予算観点の話としてもBI単体で見ると調査費から計上されることがほとんどですが、一般に調査費としては高々年間3桁万〜4桁前半規模しか張られていないケースが多いようで、決済にもハードルがあります。
単価をとるためにも、定期利用していただくためにも、データ分析を軸にプロダクトでできることを増やしていき業務に組み込まれる状態を作る必要があります。
開発観点でもデータxAI 領域のSaaSとしてはまだまだプロダクトの進化の余地はあるでしょう。
そこで我々は、直近マーケティング領域に注力しCDP的機能・マーケティングの本質に迫る機能の開発を行っています。こちらについてはまた別の記事で紹介したいと思います。
終わりに

2025/9 現在のプロダクト開発部の構成
当初私一人で始めたPoCを行うチームに少しずつチームメンバーが加入し、今では10名前後の組織としてUrumo BIのエンハンスを行っています。
最初はPdMもTech Lead的な役割も自分が全てやる気持ちでいましたが、自分より高パフォーマンスのPdM人材、CS(Customer Success/Support)を含む顧客コミュニケーションを行うチームがUrumo BIに専門的に関わることになったり、自分では考えつかないようなデータアルゴリズムを提供してくれるデータサイエンスに強いメンバーが加入したりと、チームのケーパビリティは広く深く成長してきています。[3]
2023年に新規に着手したAIxデータプロダクトの開発経緯や具体的な取り組みを紹介してきましたが、2025年の今では更に生成AIによって開発効率が増し、開発のスタイルも改善の余地があります。
プロダクト・事業の伸びしろを作るために、開発プロセスを改善しながら顧客体験を考え抜き次世代のBIプロダクトを開発するプロダクト開発メンバーや、新たなデータ分析アルゴリズム・示唆だしのためのデータ開発を行うデータエンジニアメンバーが全く足りていません。
共にUrumo BI を共に開発する プロダクトエンジニア / データエンジニアを大募集中です。
興味のある方は 直接DMいただくか, 採用サイトよりご応募お待ちしております!
-
つまり当初はHeadless BIそのものの開発をしていた ↩︎
-
当初このような技術選定をしたこと、またこれらを意思決定ドキュメントとして残しておいたことはとても良かったと考えており、プロトフェーズ中に何度か陥った開発議論において個人的に5回は見直したし、また新規メンバ参入時のオンボーディングの際にも「これをまずは読んでおいてください」といってリンクを渡すだけでざっくりとした思想は共有できたため非常に有益だったと思っています。これは前職で経験したADRを残そうという文化に多大に影響を受けています。 ↩︎
-
それはそれで挫折感を味わうことも多いのですが(笑) ↩︎

フェズは、「情報と商品と売場を科学し、リテール産業の新たな常識をつくる。」をミッションに掲げ、リテールメディア事業・リテールDX事業を展開しています。 fez-inc.jp/recruit
Discussion