可用性を上げる方法について考えてみた
はじめに
AWSの可用性について考えることがあったので記事にしてみました。
可用性ってよく聞くけど、なんだろう、冗長性とはどう違うんだろうという疑問を解決したいと思います。
可用性とは
まず、「可用性とは」で検索すると
システムが継続して稼働できる能力。障害発生時に安定して利用することができるシステムは可用性が高いと言えます。
という感じの説明がたくさんヒットします。
なんとなく分かるような、分からないような、という感じです。
可用性は稼働率とも言い換えられます。
稼働率(%)は式で表せます。
(稼働時間ー停止時間)÷ 稼働時間 x 100(%)
この式から分かることは
稼働時間を多く、停止時間を少なくすれば稼働率の値が大きくなる、ということです。
ということは、なんとなく可用性を高くする方法が分かってきたような...

どうすれば可用性が高くなるのか?
では結論から
可用性を高める要素は
- 障害時にシステムが継続できる仕組み
- 障害が起きにくい仕組み
- 復旧時間を短くする仕組み
このあたりが可用性の向上に繋がると思います。
ではこの仕組み作りをAWSで実現する方法をいくつか考えていきます。
障害時にシステムが継続できる仕組み
「障害時にシステムが継続できる仕組み」のことを冗長性を確保すると言ったしります。
常に複数のシステムやサービスを動かすことで、どこかに障害が発生しても、別のところで動いている状態です。

AWSでは冗長性を確保する手段がたくさんあります。
例えばマルチリージョンやマルチAZで、システムを複数用意することもできます。
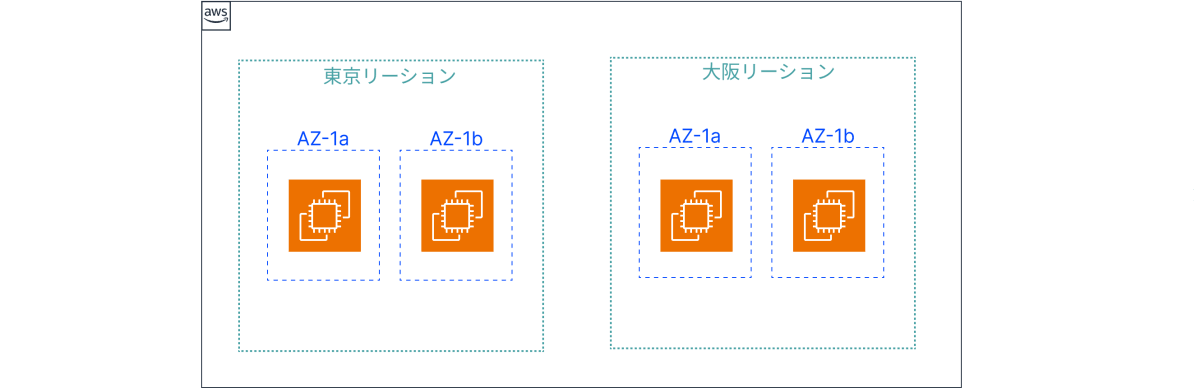
また、サービスによっては標準やオプションでマルチAZ構成を用意しているサービスもたくさんあります。
代表的なものではS3やAuroraなどは複数のAZで冗長化されています。
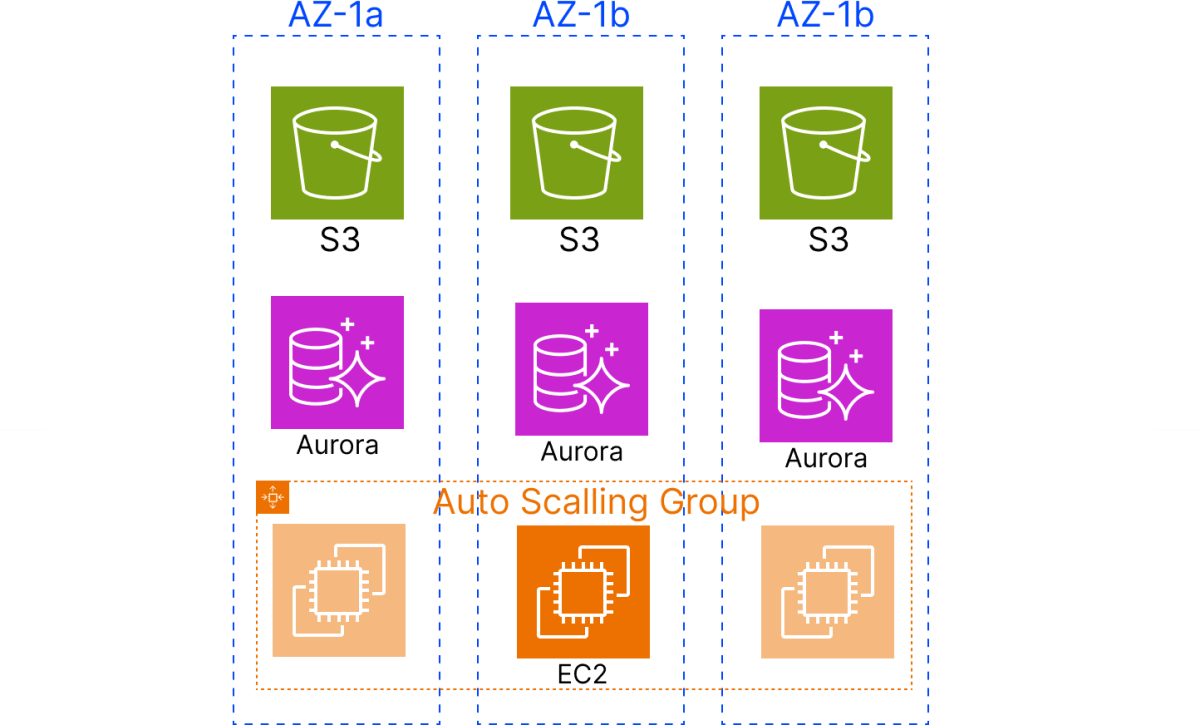
他にもたくさんありますが、こういったサービスを使うことで
障害が起きても、予備を用意してるから大丈夫!という状態にすることが大切です。
障害が起きにくい仕組み
「障害が起きにくい仕組み」は耐久性や信頼性に含まれます。
そもそも障害が起きなければ万事解決です。
例えば、S3は耐久性を表す指標としてイレブンナイン(99.999999999%)などと言います。

これは10,000,000 のオブジェクトのうち、1 つのオブジェクトの損失発生率が、10,000 年に 1 度ということを表しています。
桁が多くてイメージがつきにくいですが、とにかくデータの損失が発生しにくいということだけは分かりますね。
大事なデータはより壊れにくいサービスに保管できないか考えてみましょう。
負荷分散
負荷分散も「障害が起きにくい仕組み」に入るのかな、と私は思います。
負荷分散は負荷を一箇所に集めない仕組みです。
方法はいくつかあります。
- オートスケーリング
- システムとしての負荷分散
オートスケーリングができるサービスは
EC2のAuto Scaling Group, EFS, S3, Lambda, API Gatewayなど様々あります。

これらのサービスは処理に応じて増減できるので、負荷によりシステムがダウンするのを防げます。
システムとしての負荷分散は
AWSの様々なサービスを適材適所に配置する方法です。
例えば、webアプリケーションのセッション管理をEC2で行うのではなくElastiCacheを使う。
RDSの接続にはRDS Proxyを使って接続をプールする。
ユーザーからのアクセスはCloudFrontを経由して、高速な配信を行う
などなど、負荷を一箇所に集中させない仕組み作りも大切です。

このように、障害が発生すること自体を回避する仕組みも可用性の向上に繋がります。
復旧時間を短くする仕組み
「復旧時間を短くする仕組み」は保守性と言ったりします。
主に復旧時間を早めるには、障害を監視する仕組み、障害時に通知や自動で復旧する仕組みが必要です。

また、バックアップやスナップショットをとっておくことで復旧時間を短縮できます。

復旧処理は自動でやってくれるものもあれば、手動で行うものもあります。
RDSのマルチAZ構成や、Route53のフェイルオーバールーティングなどは自動でやってくれます。
手動のもはCloudWatch AlarmやSNS, Lambdaなんかを組み合わせて自動化すると手間が省けると思います。
障害が起きない対策だけではなく、障害が起きた時にどう対処するかも可用性の向上においては重要です。
まとめ
可用性において重要なのは、いかにシステムの稼働時間を長くするか、です。
可用性にしても冗長性にしても、それだけで成り立つのではなく、他の項目と重なる部分が多いのでややこしいですね。
間接的にはセキュリティも障害が起きにくい仕組みに入ってくると思います。
複雑ではありますが、なんとなく指標を持っておくことで構成を考える際に説得力が生まれるんじゃないかなと思いました。
参考資料
Discussion