Open8
dpnpの速度ベンチマーク
Intel CPUの内蔵GPUでもnumpy likeな行列演算ができるライブラリdpnpの動作検証。
検証環境
- CPU: Intel Core i5 11500
- iGPU: Intel UHD Graphics 750
- OS: Ubuntu22.04
- Python: Intel oneAPI Python(2023.1.0-46399) の仮想環境 (Python3.9)
numpyとdpnpとpytorchで比較
NumPy
intel MKLが有効になっている。
>>> numpy.__version__
'1.23.5'
>>> numpy.show_config()
blas_armpl_info:
NOT AVAILABLE
blas_mkl_info:
libraries = ['mkl_rt', 'pthread']
library_dirs = ['/opt/intel/oneapi/intelpython/latest/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/opt/intel/oneapi/intelpython/latest/include']
blas_opt_info:
libraries = ['mkl_rt', 'pthread']
library_dirs = ['/opt/intel/oneapi/intelpython/latest/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/opt/intel/oneapi/intelpython/latest/include']
lapack_armpl_info:
NOT AVAILABLE
lapack_mkl_info:
libraries = ['mkl_rt', 'pthread']
library_dirs = ['/opt/intel/oneapi/intelpython/latest/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/opt/intel/oneapi/intelpython/latest/include']
lapack_opt_info:
libraries = ['mkl_rt', 'pthread']
library_dirs = ['/opt/intel/oneapi/intelpython/latest/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/opt/intel/oneapi/intelpython/latest/include']
Supported SIMD extensions in this NumPy install:
baseline = SSE,SSE2,SSE3,SSSE3,SSE41,POPCNT,SSE42
found = AVX512_ICL
not found =
dpnp
>>>dpnp.__version__
'0.11.1'
torch (CPU版)
pipからinstallしていますが、intel MKLとMKL DNNが有効になっています。
pip3 install torch --index-url https://download.pytorch.org/whl/cpu
>>> torch.__version__
'2.0.1+cpu'
>>> print(torch.__config__.show())
PyTorch built with:
- GCC 9.3
- C++ Version: 201703
- Intel(R) oneAPI Math Kernel Library Version 2023.1-Product Build 20230303 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v2.7.3 (Git Hash 6dbeffbae1f23cbbeae17adb7b5b13f1f37c080e)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- LAPACK is enabled (usually provided by MKL)
- NNPACK is enabled
- CPU capability usage: AVX2
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CXX_COMPILER=/opt/rh/devtoolset-9/root/usr/bin/c++, CXX_FLAGS= -D_GLIBCXX_USE_CXX11_ABI=0 -fabi-version=11 -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DLIBKINETO_NOROCTRACER -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Werror=bool-operation -Wnarrowing -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_DISABLE_GPU_ASSERTS=ON, TORCH_VERSION=2.0.1, USE_CUDA=0, USE_CUDNN=OFF, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=OFF, USE_NNPACK=ON, USE_OPENMP=ON, USE_ROCM=OFF,
- dpnpがfloat64の計算ができなかったのでfloat32, int32, int64で検証
- dpnpリポジトリのexampleを修正して、pytorchも比較する。
- 速度は10回計算の平均値とする。単位はsec/回。
matmul
- shape: 16x16, 32x32, 64x64, 128x128, 256x256, 512x512, 1024x1024
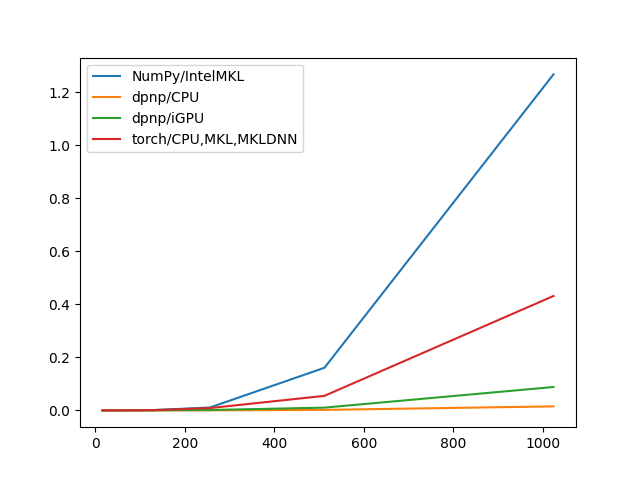
float32
| NumPy/IntelMKL | dpnp/CPU | dpnp/iGPU | torch/CPU,MKL,MKLDNN | |
|---|---|---|---|---|
| 16 | 0.000001 | 0.000090 | 0.000167 | 0.000003 |
| 32 | 0.000002 | 0.000096 | 0.000175 | 0.000005 |
| 64 | 0.000006 | 0.000141 | 0.000209 | 0.000006 |
| 128 | 0.000017 | 0.000165 | 0.000191 | 0.000018 |
| 256 | 0.000104 | 0.000258 | 0.000325 | 0.000108 |
| 512 | 0.000705 | 0.000959 | 0.001019 | 0.000716 |
| 1024 | 0.005930 | 0.006764 | 0.005296 | 0.007296 |
int64
| NumPy/IntelMKL | dpnp/CPU | dpnp/iGPU | torch/CPU,MKL,MKLDNN | |
|---|---|---|---|---|
| 16 | 0.000003 | 0.000168 | 0.000172 | 0.000004 |
| 32 | 0.000021 | 0.000206 | 0.000195 | 0.000010 |
| 64 | 0.000153 | 0.000189 | 0.000222 | 0.000028 |
| 128 | 0.001168 | 0.000189 | 0.000505 | 0.000208 |
| 256 | 0.011949 | 0.000561 | 0.002539 | 0.001641 |
| 512 | 0.164101 | 0.005005 | 0.021120 | 0.014062 |
| 1024 | 1.732274 | 0.054449 | 0.127659 | 0.110528 |
int32
| NumPy/IntelMKL | dpnp/CPU | dpnp/iGPU | torch/CPU,MKL,MKLDNN | |
|---|---|---|---|---|
| 16 | 0.000003 | 0.000143 | 0.000173 | 0.000004 |
| 32 | 0.000021 | 0.000159 | 0.000183 | 0.000014 |
| 64 | 0.000144 | 0.000174 | 0.000195 | 0.000094 |
| 128 | 0.001139 | 0.000200 | 0.000382 | 0.000831 |
| 256 | 0.010917 | 0.000314 | 0.001492 | 0.008805 |
| 512 | 0.160692 | 0.001904 | 0.010477 | 0.054832 |
| 1024 | 1.266861 | 0.015211 | 0.088180 | 0.431325 |
グラフ
float32
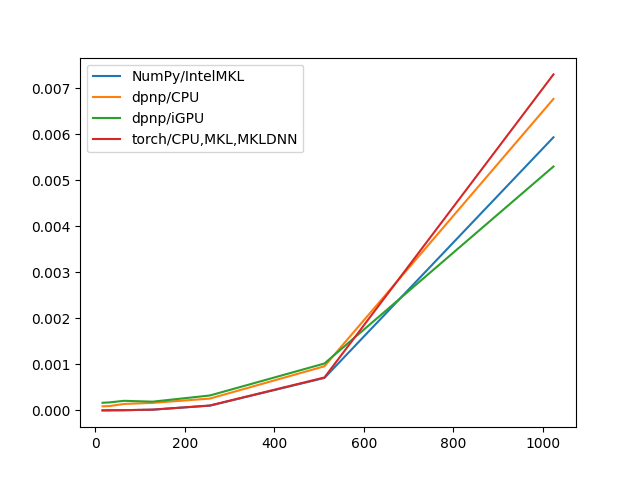
int64
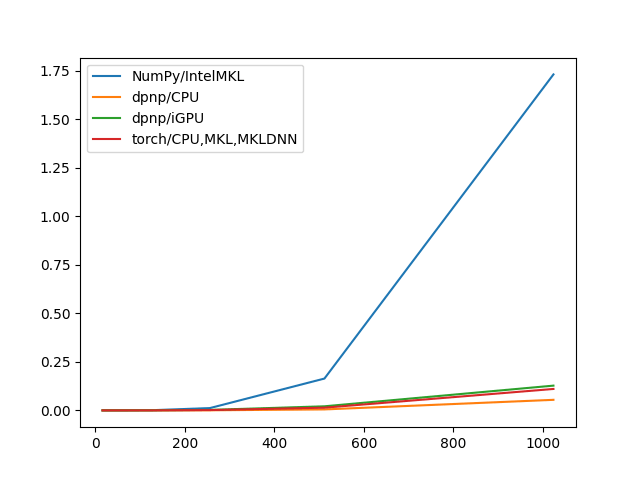
int32