はじめに
Fairy Devices で LINKLET のサーバーサイドの開発をしている nope です。
みなさんは、サーバーからのレスポンスが全く返ってこない、そんな悪夢のような事態に遭遇したことはありますか?
私たち LINKLET 開発チームは、今年 (2025年) の 1 月、まさにその悪夢を体験しました。以下はその時の Slack の投稿です。

「サーバーがダウンした?」「まさか DB に異常が?」様々な憶測が飛び交う中、原因特定は難航しました。
この記事では、障害の概要と、そこから得られた教訓についてお話しします。
目的と対象
この記事は、以下の読者を対象としています。
- Rust でサーバー開発を行い、DB アクセスを利用している方
- コネクションプールの設定を見直したいと考えている方
結論
デッドロック、それは静かなる脅威。。。
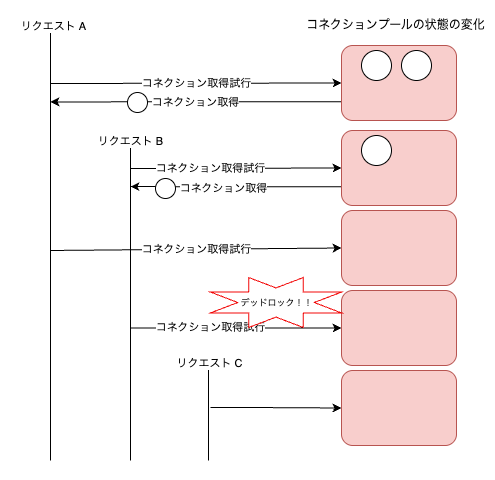
今回の障害の直接的な原因は、DB のコネクションプールを管理するクレートである deadpool の内部でデッドロックするような実装をしていたことでした。
具体的には、特定のリクエスト処理において DB のコネクションプール内のコネクションを保持したまま、さらに別のコネクションを取得しようとした結果、コネクションプールが枯渇し、かつコネクション取得時のタイムアウト設定がなかったために、その他のリクエスト内でコネクションを取得しようとすると永久に待機するという、デッドロックに陥っていました。
教訓 「コネクションプールの最大コネクション数と wait (connection) timeout は設定しておこう!」
...はい、これだけでは面白くありませんよね。
どのようにして調査し、解決に至ったのか、その過程を少しお話しします。
ざっくり実況
詳細については別の記事に書くかもしれませんが、この記事では解決に至るまでの内容をざっくりとした実況でお届けします。
「LINKLET Consoleに接続できません!」という第一報から、私たちの戦いは始まりました。
社員 X さん: 「LINKLET Consoleに接続できません!」
チームメンバー A さん: 「チーム召集!」
チームメンバー全体: 「はい!」
私: 「はいはい、こういう時はエラー出るよね。Slack のアラートチャンネルを見れば原因が分かるだろう」
チームメンバー B さん: 「...アラート何も上がってないけど?」
チームメンバー全体: 「...?!」
チームメンバー A さん: 「サーバーダウンしたのかも、インスタンス見てみるわ」
チームメンバー A さん: 「...サーバー動いてるし、なんならログをみるにリクエストを処理してそうだけど?」
チームメンバー全体: 「...?!」
チームメンバー C さん: 「...なんか Console 見られる時があるんだけども」
チームメンバー全体: 「...?!」
チームメンバー A さん: 「特定のサーバーが何かしら異常かもしれないか」
-- 数時間にわたるログ調査 --
チームメンバー A さん: 「フロントエンドには 504 を返しているんだけど、これはアプリケーションサーバー手前のロードバランサーが返していて、アプリケーションサーバー自体はリクエスト処理の開始のログを出したあとにストップしてそう」
私: 「リクエスト処理の終了のログが出てないエンドポイント見るに、DB アクセスがないリクエストはレスポンスまでできていそうではない?」
チームメンバー B さん: 「再現できるかやってみたいよね」
チームメンバー A さん: 「再現できたかもしれない!フロントエンド でミーティング中のデバイスの音量をこんな感じ(以下動画参照のこと)で操作すると発生する!」
検証環境で実施した時の映像
チームメンバー全体: 「...omg」
私: 「DB アクセスあたりにデバッグログ仕込みまくって試してみます。」
-- 数時間のデバッグ作業 --
私: 「これ DB のコネクションプールからコネクション取得前後にログ仕込んでみたら、取得後のログが全く出ない!」
チームメンバー C さん: 「つまり DB アクセスによるデッドロックが発生していたってことか!」
チームメンバー全体: 「...!!!」
原因
LINKLET の一部サーバーで利用している deadpool で管理する DB プールのコネクション取得処理で、デッドロックしたことが原因でした。
もう少し詳しく説明すると、特定のリクエスト処理において、複数の DB のコネクションプールからコネクションを取得した後に、開放しないまま、別のコネクションを取得しようとしたことが直接的な原因でした。
つまり、大量の特定リクエストが送信された結果、各リクエストが処理の途中でコネクションプールから新しいコネクションを取得しようとしたものの、プール内のコネクションが全て使用中であり、かつコネクションの取得にタイムアウトが設定されていなかったため、永久に待機する状態に陥り、デッドロックが発生していました。
デバッグ時、deadpool のセマフォがロックされている箇所は以下でした。
このサーバーでは diesel_async を使用し、DB のコネクションプールには deadpool を使用しています。
昨年、社内で diesel の async 対応のために diesel_async を導入した際、DB のコネクションプールのクレートを r2d2 から deadpool に変更しました。
この時、コネクションプールの設定をデフォルトのままにしたことが、今回の障害の発見を遅らせた大きな要因でした。
deadpool のコネクションプールのデフォルト設定では、コネクションプール内のコネクションが枯渇し待機状態になっていたとしても、タイムアウトしない設定になっています。
そのため DB アクセスを伴う処理が永続的に待機する状態が発生しました。
結果として、サーバー自体はダウンせず、エラーも出力されない一方で、ロードバランサーからのリクエストタイムアウトが発生するという非常に厄介な状況に陥りました。
対策
上記の原因を踏まえ、以下の暫定対応を実施し、恒久対応を検討しています。
暫定対応
- コネクションプールの最大コネクション数を増やす
デッドロック自体は解決しませんが、コネクションプールが枯渇しにくい状態にするため、コネクション数を増加させました。
- コネクション取得のタイムアウトを設定する
コネクションプールが枯渇した場合でも、タイムアウトを設定することでデッドロックからの自動的な解放を可能にしました。
- コネクション取得失敗時のヘルスチェック失敗とインスタンス(AWS ECS)自動起動設定
サーバーへのヘルスチェックリクエスト内でコネクションプールの状態をログに出力し、コネクション取得失敗時にヘルスチェックが失敗するように設定しました。
また、ヘルスチェック失敗をトリガーに、失敗したアプリケーションサーバーのインスタンスを停止し、健全なインスタンスを起動するようにしました。
万一同じような事象が発生した場合でも、自動的に復旧する仕組みを構築しました。
- フロントエンド操作アクションの改善
問題の引き金となったデバイス音量調整の操作ですが、音量のスライダーをマウスで動かしている間はアプリケーションサーバーに大量のリクエストを送ってしまう実装になっていました。
そのため、マウスボタンを離したときに1回だけリクエストが送信されるよう修正しました。
恒久対応
- アプリケーションサーバー自体のリクエスト応答時間の監視する
今回の障害は DB アクセスに起因するため、暫定対応では DB アクセス周りを重点的に監視しました。
今後はアプリケーションサーバーのリクエスト応答時間全体を監視することで、他の原因によるデッドロックやリクエストタイムアウトも検知できるようにしたいと考えています。
この点については、tatsuya6502 さんが興味深い仕組みを実装されているため、参考にさせていただき、将来記事にするかもしれません。
- 1つの処理が同時に2つ以上のコネクションを持たない実装をする
今回のデッドロックの根本原因である、1つのリクエスト処理内で複数のコネクションを取得する実装を見直す必要があります。
コネクション取得処理を抽象化し、内部的に複数コネクションの取得を回避する仕組みを実装する予定です。
コネクションプールのデフォルト設定
参考までに、主要クレートのコネクションプールにおけるデフォルト設定を調査しました。
| クレート | 最大コネクション数 | コネクション待機時間 (seconds) |
|---|---|---|
| deadpool[1] | cpu_count * 4 | None |
| r2d2[2] | 10 | 30 |
| bb8 | 10 | 30 |
| mobc | 10 | 30 |
| sqlx[3] | 10 | 30 |
比較してみると、deadpool のデフォルト設定は、コネクション数が cpu_count * 4 と CPU 物理コア数に依存している一方で、コネクション待機時間が無制限である点が特徴的です。
コネクション待機時間が永続的であるため、コネクションの奪い合いによるデッドロックが発生しやすい点に注意が必要です。
他のクレートでは、適切なタイムアウトが設定されており、デフォルトでコネクション取得時のデッドロック回避策が組み込まれています。
最後に
今回の障害から得られた最大の教訓は、コネクションプールの設定はちゃんと確認しようということでした。
安易にデフォルト設定で乗り切るのではなく、指定した値で制御できる状態にしておき、常に監視しておくことが重要だと感じました。
もしあなたが Rust でサーバー開発をしていて、DB アクセスにコネクションプールを使用しているのであれば、今一度、コネクションプールの設定を見直すのが良いかもしれません。
今回の経験が、あなたのシステム開発の一助となれば幸いです。

Discussion