はじめに
物体検出とは画像の中から既定のクラスの物体を識別し、その位置を特定する技術です。この技術は、自動運転、道路のひび割れ検出、胸部X線画像からの異常検出など、多岐にわたるアプリケーションで活用されています。物体検出技術は、近年の深層学習(Deep Neural Networks, DNN)の進展により、大きく進化しました。以前はSIFTやHOGなどの局所特徴量を基にした方法が主流でしたが、R-CNN[1]の登場により、DNNモデルが物体検出の分野で広く用いられるようになりました。
物体検出とは何か
物体検出タスクでは、事前に定められたクラス(例:ソファ、犬)の物体を画像の中から見つけ出し、それを四角形(矩形)で囲むことで、その物体の位置とクラスを特定します。以下の図1に示されるように、画像内の複数のクラスの物体を検出し、それぞれの物体を矩形で囲んで表示します。これにより、検出された物体の位置とクラスが確認できます。

図1 物体検出の例:この図は、複数の物体(犬、ソファ)を検出し、それぞれを矩形で囲んで表示しています。各矩形には、検出された物体のクラスラベルが付与されています。このように、物体検出技術を用いることで、画像内の異なるクラスの物体を識別し、視覚的にその位置を示すことができます。
物体検出を行うには
物体検出タスクを実行するためには、適切なモデルの選択が重要です。一般的には、既存の汎用モデルを使用するか、カスタムモデルを開発するかという選択肢があります。
汎用モデルの使用
既に公開されている汎用モデルは、多くの基本的な物体検出タスクに対応可能です。これにより、新たにデータを作成したり、モデルをゼロから訓練する必要がなくなります。例えば、COCOデータセットは広く使用されており、人、自転車、車、信号機など、80クラス以上の物体を含んでいます。このデータセットを使用することで、街中の様々なシーンにおいて物体を識別できるモデルを開発することが可能です。
また直近では、YOLO-WorldやGrounding DINOといったモデルが登場しています。これらは訓練されていないクラスの物体もテキストに基づいて検知可能になりました。こうしたモデルの使用も迅速な物体検出を可能とします。
カスタムモデルの開発
特定のアプリケーションや要件に適合する必要がある場合、既存の汎用モデルでは不十分なことがあります。特に、特定のドメイン特有の物体クラスを識別する必要がある場合や、より高度な識別精度が求められる場合には、カスタムモデルの開発が必要になることがあります。
物体検出のカスタムモデルの開発
物体検出プロジェクトには、広く使用される汎用モデルと、特定のニーズに合わせてカスタマイズされたモデルの二つの主要なタイプがあります。多くのシナリオでは汎用モデルで十分な結果が得られる一方で、特定のドメインで必要とされる独自の物体クラスの検出や、より詳細な要求に応えるためには、カスタムモデルの開発が不可欠です。
以下では、カスタムモデルの開発手順について説明します。
1. データ収集とアノテーション
実際にデータ収集を行う際に、「どれくらいの規模のデータが必要になるのか?」という疑問が出てくると思います。一般的に深層学習による手法は、大量のデータが必要です。
初めに、ターゲットとするクラスのオブジェクトが豊富に含まれるデータソースを特定します。例えば、自動運転のための物体検出モデルを訓練する場合は、道路環境の異なる天候や時間帯の画像を集める必要があります。
次に、データの品質と量に基づいて、データセットを構築します。一般的に、各クラスに対して少なくとも1500枚の画像を目標とし、これに加えて、クラスごとに10000以上のインスタンス(ラベル付きオブジェクト)が含まれることを目指します。画像の多様性も重要で、実際にモデルを使用する環境に近い条件の画像を確保することで、モデルの汎用性と精度が向上します。
画像が十分に集まったところで、アノテーションを行います。アノテーションプロセスでは、特定のオブジェクトを矩形で囲み、適切なクラスラベルを割り当てます。この作業にはLabel StudioやLabelMeなどのツールが役立ちます。アノテーションは非常に時間がかかる作業ですが、モデルのトレーニングに直接影響するため、正確さと一貫性を確保することが重要です。
物体検出におけるアノテーションとは、画像内の特定の物体を識別し、それらに関連する情報を付加するプロセスを指します。アノテーションには主に次のようなステップが含まれます。
物体の特定: 画像内で物体の位置を特定し、それを矩形で囲みます。
ラベリング: 特定された物体にカテゴリーまたはクラスのラベルを割り当てます。例えば、犬、猫、車など、モデルが識別する必要がある物体の種類を示します。
また、アノテーションを行うためのツールとして、OSSにはLabel StudioやLabelMeなどがあります。SaaSにはAnnoFabなどがあります。
図2に、実際のアノテーション作業の一部を載せます。アノテーションツールにはLabelMeを用いています。
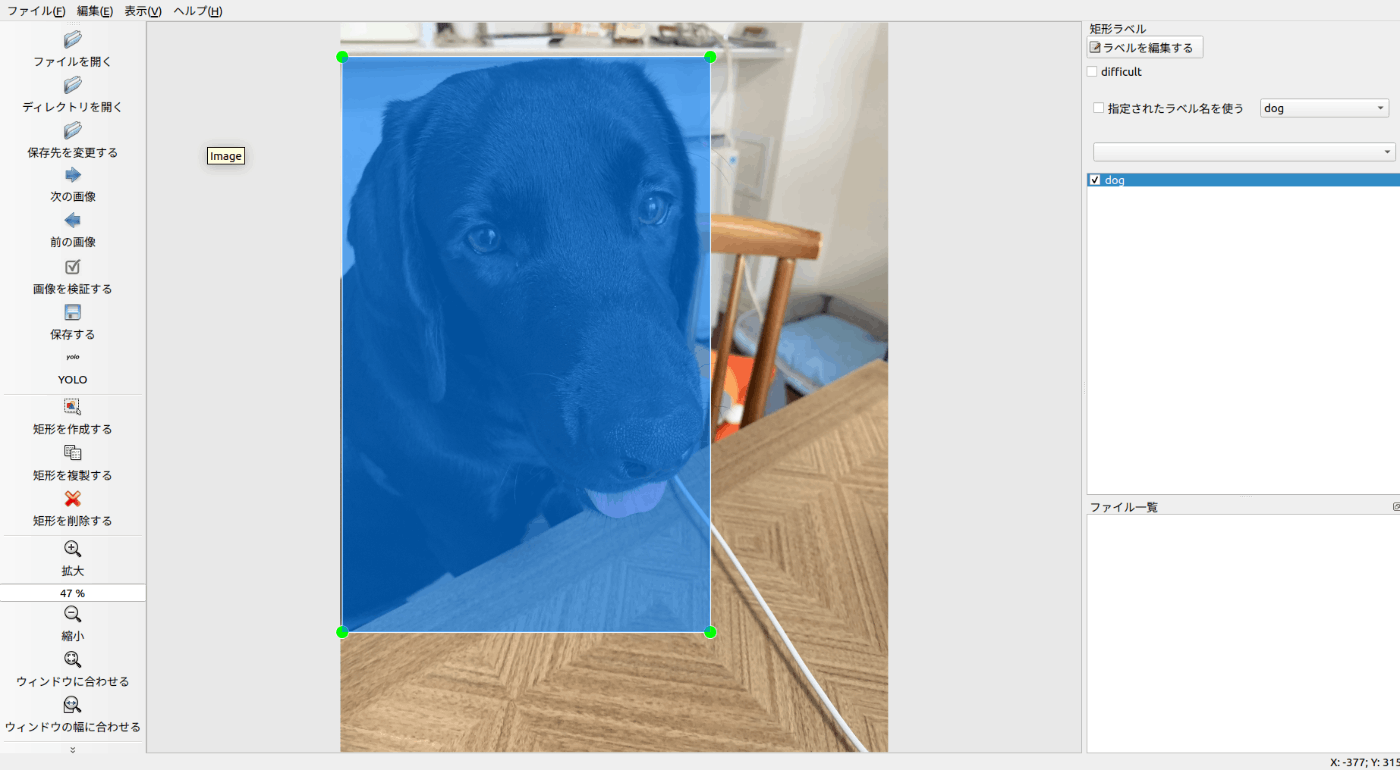
図2 LabelMeによるアノテーション
2. モデルの作成と評価
モデルの選定
データ収集とアノテーションが終わり次第、モデルの選定を行います。
物体検出にはR-CNN、YOLO、SSDなど、さまざまなモデルが存在し、プロジェクトの要件に応じて最適なモデルを選定します。これらのモデルは数多くのライブラリやフレームワークによって提供されています。以下にその中のいくつかの主要なものを紹介します。
TensorFlow Object Detection API
このAPIは、さまざまな物体検出アーキテクチャ(SSD[2]、Faster R-CNN[3]など)に対応しており、独自のデータセットでモデルを訓練したり、事前に訓練されたモデルを利用したりすることができます。
Detectron2
Meta Researchによって開発されたDetectron2は、PyTorchによって実装されています。Detectron2は、最新の物体検出アルゴリズム(Faster R-CNN、Mask R-CNN[4]、RetinaNet[5]など)の実装を提供し、高度な機能と柔軟性を提供します。Detectron2は、特に研究目的や複雑な物体検出タスクに適しています。
YOLO
YOLOは、リアルタイム物体検出システムであり、高速かつ高精度な検出を実現します。YOLOの各バージョンは、精度と速度のバランスを改善するために更新されています。特に、YOLOv8[6]は、シリーズの最新版で、精度と速度の面で最先端の性能を提供します。
モデルの学習
使うモデルを決めたらモデルの学習を行います。
モデルの学習過程では、選定したアーキテクチャに基づいて、前処理されたデータセットを使用しています。この段階では、以下の要素が重要になってきます。
データ拡張:画像の回転、反転、スケーリング、色調の変更などを行うことで、モデルの汎化性能を高めます。データ拡張には、データセットに存在する画像自体にデータ拡張を適用し、単純に画像の枚数を増やす「オフライン拡張」と、モデルに入力するミニバッチ単位に、データ拡張を実施し、学習毎にランダムな画像を生成する「オンライン拡張」があります。オフライン拡張だとストレージを圧迫したり、学習時間が増加したりするため、現在ではオンライン拡張を行うのが一般的です。
学習率の調整:適切な学習率の設定が重要です。高すぎると学習が不安定に、低すぎると収束が遅くなります。学習率スケジューラを利用することも効果的です。
過学習の防止:データ拡張、ドロップアウト、正則化手法を用いて過学習を防ぎます。学習と検証データのパフォーマンスを監視するのが良いでしょう。
バッチサイズとエポック数:ハードウェアが許容する最大のバッチサイズを選択してください。エポック数の設定も非常に重要です。最初は300エポックでスタートします。早い段階で過学習が起こる場合は、エポック数を減らします。300エポック後に過学習が発生しない場合は、より長く学習を行います。例えば、600エポック、1200エポックなどです。
モデルの評価
作成したモデルの性能を適切に評価することは極めて重要です。評価プロセスでは、テストデータセットを用いてモデルの予測能力を検証し、予測されたラベルと実際のラベルを比較します。適用する評価指標は、モデルが利用されるアプリケーションの具体的な要件に依存します。例えば、医療画像分析では再現率が特に重視される可能性がありますが、製造業の品質検査では精度がより重要になるかもしれません。以下は、物体検出モデルの評価に使用される一般的な指標です:
精度(Precision)と再現率(Recall):精度は、正しく検出された物体の割合を示し、再現率は実際に存在する物体のうちモデルが検出した割合を示します。
平均精度(Average Precision, AP):異なる閾値での精度と再現率の平均を取り、この値は各クラスごとに計算され、全クラスの平均値であるmAP(mean Average Precision)として評価されます。
F1スコア:精度と再現率の調和平均であり、両指標のバランスを取るために使用されます。
混同行列(Confusion Matrix):実際のラベルと予測ラベルを比較し、モデルが各クラスをどのように分類したかを示します。これにより、全体的な精度、クラスごとの精度、および誤分類されたクラスの特定が可能になります。
Intersection over Union(IoU):予測された境界ボックスと実際の境界ボックスの重なりを測定し、この値に基づいて検出の正確性を定義します。
mAP@IoU:IoUの特定の閾値におけるmAPの値で、例えばmAP@0.5はIoUが0.5以上の場合のmAPを示します。
これらの指標を選択する際には、アプリケーションの具体的な目的を考慮し、最も影響を受ける性能指標を優先して使用することが推奨されます。それにより、モデルの実用性が向上し、必要に応じた改善が可能となります。
3. システム開発と運用
モデルの開発と評価が完了したら、そのモデルを実際のアプリケーションやシステムに統合します。このステップでは、モデルの組み込みから運用までを計画し、実行します。リアルタイムでの物体検出タスクに使用するための準備が含まれ、運用段階ではモデルの性能を継続的に監視し、再学習や調整を行う必要があります。フィードバックの収集と処理も、運用の効率と精度を向上させるために重要です。
物体検出のプラクティス
1. アノテーションを行う際の重要なポイント
アノテーションは、トレーニングデータの品質とモデルの精度に直接影響を与えるため、非常に重要な作業です。効果的なアノテーションを行うためには、以下のような注意点を考慮する必要があります。
正確な境界ボックス:物体を正確に囲むように境界ボックスを描きます。余計な空間を含めないようにし、物体の全体がボックス内に収まるようにします。
一貫性のあるラベリング:同じタイプのオブジェクトには常に同じラベルを使用します。ラベルの一貫性が不十分だと、モデルが混乱し精度が低下します。
小さなオブジェクトと重なり合うオブジェクト:画像内の小さなオブジェクトや重なり合うオブジェクトも正確にアノテーションします。これらはしばしば見落とされがちですが、とても重要です。
品質チェック:アノテーションの品質を定期的にチェックし、誤りがあれば修正します。不正確なアノテーションはモデルの性能を低下させます。アノテーター間で担当箇所を交換してクロスチェックを行うことも有効です。一人のアノテーターが画像にラベルを付けた後、別のアノテーターがその作業をレビューします。このようにして、担当箇所を変えることで、アノテーションのミスや見落としがあれば相互に指摘し合い、修正を行うことができます。
2. 事前学習モデルの選択
適切な事前学習モデルを選択するための主要な考慮点は以下の通りです。
データセットの類似性:モデルが事前学習されたデータセットが、自身のプロジェクトで使用するデータセットとどれだけ似ているかを考慮します。類似性が高いほど、転移学習は効果的に行えます。
パフォーマンスと精度の要求:利用可能な計算リソース、プロジェクトの要件、およびパフォーマンスと精度のニーズに基づいて行う必要があります。大きな事前学習モデルは一般に高精度ですが、計算コストが高くなります。したがって、利用可能なGPUメモリや処理能力に応じて、小さく効率的な事前学習モデルを選択するか、または高い精度が求められる場合は大きな事前学習モデルを選ぶことが重要です。
3. クラスの不均衡の解消
物体検出におけるクラスの不均衡は、データセット内の異なるクラスが、サンプル数において大きく異なる状態を指します。例えば、犬のクラスは非常に多くのサンプルが存在するが、猫のクラスは比較的少ないサンプルしかない、という状況です。クラスの不均衡は、物体検出における一般的な問題であり、特に現実世界のデータセットで頻繁に発生します。これにより、少数クラスの物体の検出性能が低下します。
解決策として、以下の項目が挙げられます。
データ数の偏りを補正して均衡にする:クラス間の不均衡を解消するため、少数クラスのサンプルをオーバーサンプリングにより増やします。これにより、データセット全体でのクラス間のバランスを改善し、モデルの予測精度を向上させることができます。
学習時にクラスの重みを調整する:各クラスに対して重みを割り当て、その重みを損失計算に適用します。一般的に、サンプル数が少ないクラスには高い重みを、多いクラスには低い重みを割り当てます。これにより、少数クラスのサンプルがモデルに与える影響を増加させ、多数クラスのバイアスを緩和します。
おわりに
本記事では、物体検知とは何か、代表的な手法、そして物体検出を実践する上での重要なポイントに至るまで、幅広く紹介しました。物体検出は幅広い応用分野があり、今後ますますその重要性が高まると考えられます。この記事を通じて、様々な場面で物体検出技術を実践的に活用していただければ幸いです。
参考文献
[1] Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv. arXiv:1311.2524.
[2] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., & Berg, A. C. (2016). SSD: Single Shot MultiBox Detector. arXiv. arXiv:1512.02325.
[3] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv. arXiv:1506.01497v3.
[4] He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask R-CNN. arXiv. arXiv:1703.06870v3.
[5] Lin, T.-Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal Loss for Dense Object Detection. arXiv. arXiv:1708.02002v2.
[6] Reis, D., Kupec, J., Hong, J., & Daoudi, A. (2023). Real-Time Flying Object Detection with YOLOv8. arXiv. arXiv:2305.09972v1.

Discussion