Amazon Auroraのアーキテクチャについて調べる
基本的なアーキテクチャ
基本的にはこの図が一番よくまとまっている

分散合意アルゴリズム
Writeで4/6、Readで3/6のACKが返ってくる必要がある。なので、3つのAZにそれぞれ2つコピーを置いておけば、仮にAZが一つ止まっても合意ができる。
仮にネットワークやNodeの不具合でWriterインスタンスからの情報を取り逃がしても、Node間でgossipプロトコルを用いてランダムにPeerを組んで欠損した分の情報を補っている。


redoログをNodeに送信し、受信完了のACKを持って合意とみなしている。ACKを返せなかったNodeの補完はgossipアルゴリズムで行う形を取っている。これにより、Masterが重い処理をして分散合意を行っていくような既存の分散合意アルゴリズム(Paxos・Raftベース)が不要になる。
WriterとReaderは同じクラスタボリュームを共有しているため、一度ログが保存されればストレージへアクセスする分には一貫性が保証される。
書き込みの流れ
redoログによるストレージへの書き込み
書き込みはWriterインスタンスが担当する。Writerインスタンスはredoログをクラスタボリュームに送信する。クラスタボリュームの各Nodeはredoログをキューに入れる。キューに入ったredoログを整理した上で、hot logという領域へ格納し、gossipアルゴリズムで利用する。
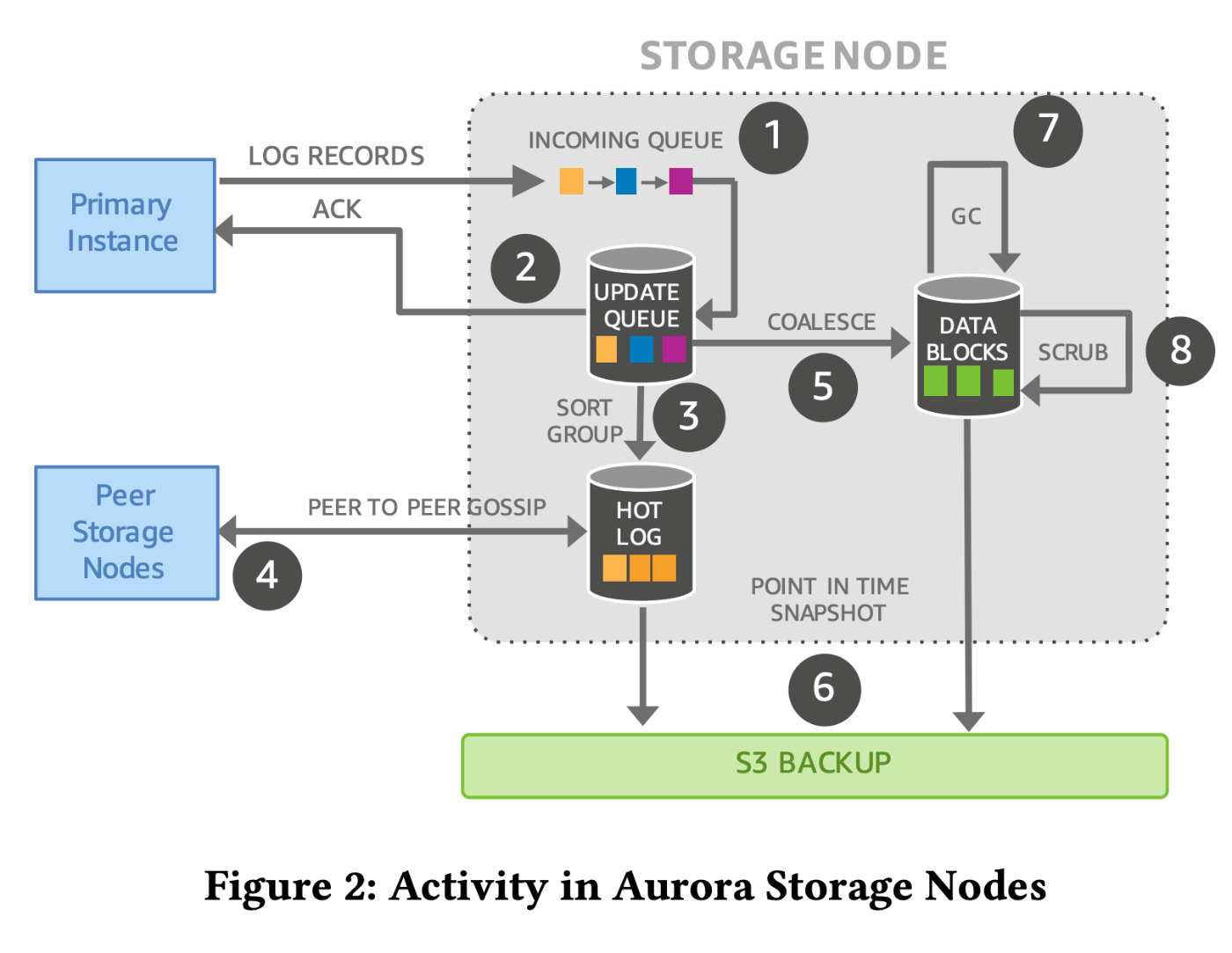
コミット
Nodeはキューに格納できた時点でコミット可能としてWriterインスタンスにACKを返却する。Writerインスタンスは4/6のACKが届き次第コミット可能であると判断して、クライアントへコミットを通知する。
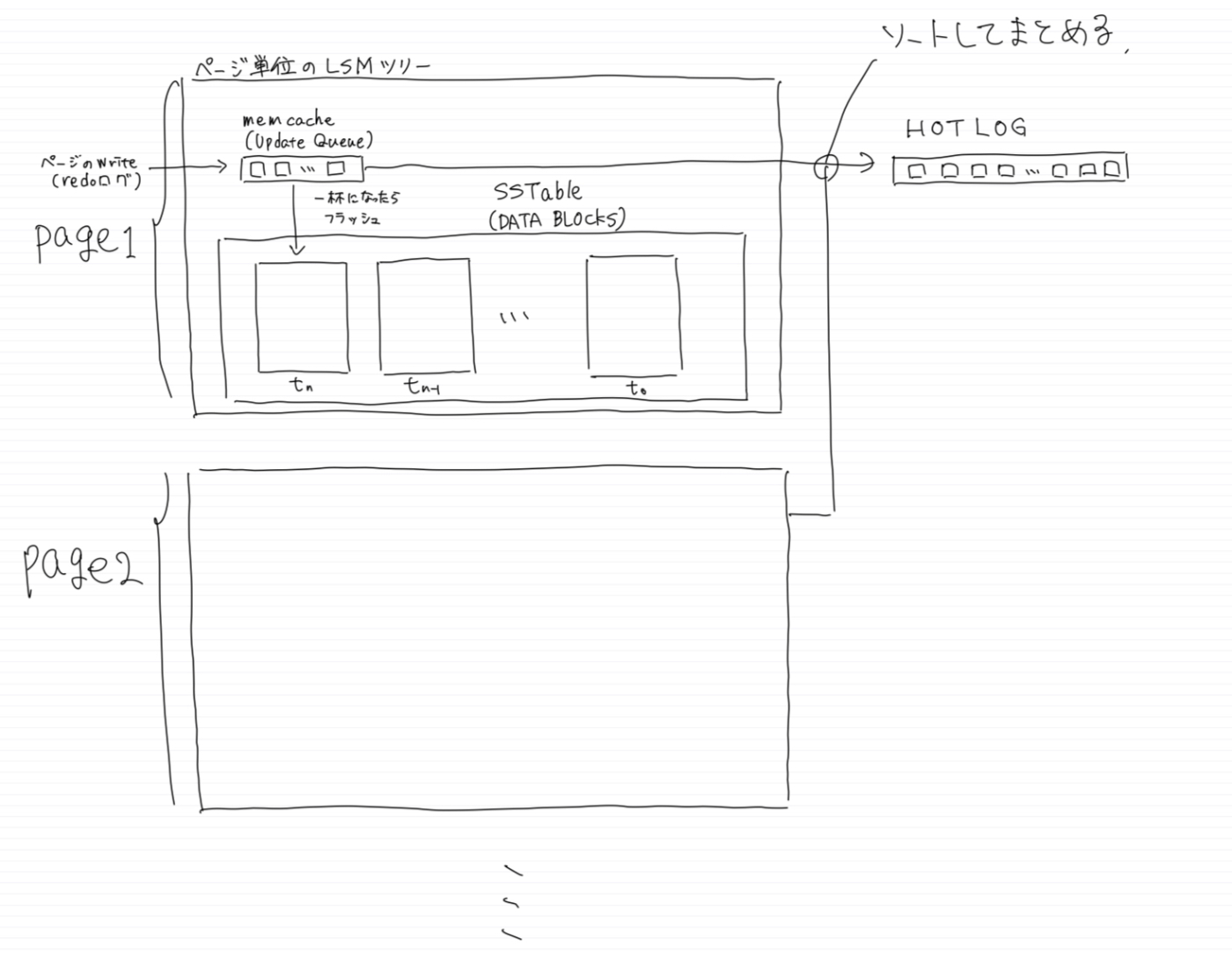
ストレージの構造
Update QueueはLSMツリーでいうmemcacheの役割を担っていて、DATA BLOCKSがSSTableに相当すると理解してよさそう。
UpdateQueueとDATA BLOCKSがページ単位でストレージノードに存在し、UpdateQueueがいっぱいになったら新しいバージョンをDATA BLOCKSにフラッシュしていそう。
SSTableのバージョンは膨れすぎるとRead時の調停コストが高くなってしまうので、定期的にコンパクションされている。
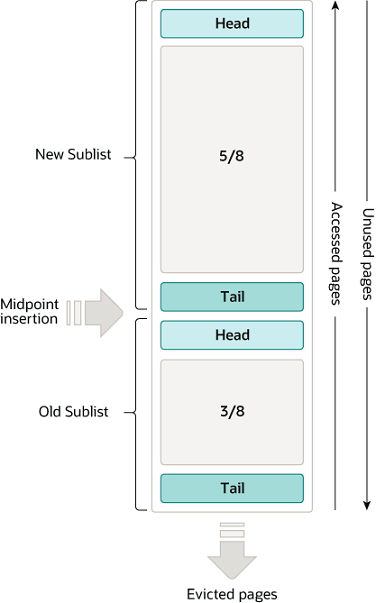
ページキャッシュ
WriterインスタンスやReadインスタンスはページキャッシュ(バッファプールみたいなLRU方式のページを格納するバッファ)を持っている。ページキャッシュの目的はReadの高速化で、トランザクションで要求されたページがヒットすればストレージにページを要求する必要がない。
Writerインスタンスはクラスタボリュームにredoログを送信し、4/6クオラムのACKでコミットする。その際にページキャッシュも更新するが、Readerインスタンスにもページキャッシュの変更を伝播させる必要があるので、それを非同期でredoログを送信することでReaderインスタンスのページキャッシュの更新を行わせている。
ここで、クラスタボリュームとのコミットのためのやり取りは同期式のコネクション型(返事を待つ)であるのに対して、Readerとのページキャッシュ更新はコネクションレス型(完了を待たない)であることに注意が必要。コミットの確定はあくまでクラスタボリュームとの合意を持って行われるので、そこからredoログをReaderへ送信してページキャッシュの更新の完了までは待機しない。よって、WriterへのリクエストとReaderへのリクエストでレスポンスが異なる状態が発生しうる。その遅延は20〜40msらしい。

limitless database
最近発表があり、Write負荷への対処に水平スケールの選択肢を与えるもの。現在はまだプレビューの機能。
基本的なコンセプトは、分散ジョインと分散コミットを回避することで読み書き両方に恩恵を受けようというもので、Cloud Spannerのシャーディングに近いものを感じた。
利用できる機能としては、
- シャードテーブル: シャードキーを指定することで、特定のキーのハッシュレンジでシャーディングを行う
- collocate: 分散JOINを避けるために、特定のテーブル同士を同じシャードキーで分散させて同一シャードに格納する。SpannerのINTERLEAVEのように物理的に連続して格納することでJOINのコストがより軽減されるかどうかについては、まだ公開されていなそう。
- reference: 全シャードにデータをコピーして格納する。変更が少なく頻繁にJOINされるようなテーブルを指定する。
実際のデータはクラスタボリュームのストレージに格納されており、おそらくNode(ページの集合)がシャードに対応するのだと思われる。
ハッシュレンジで書き込むべきNodeが決まるようになるため、書き込みを並列化することができる。(いわゆるストライピングの戦略)

読み取りの流れ
読み取りの場合、まずページキャッシュを参照する。ページキャッシュはReaderインスタンスの場合は20〜40msのredoログ適用遅延があるが、Webアプリケーションではそこまで厳密な要求は少ないため、基本的には最新のデータが入っていると思って良い。厳密に最新の値を取得したい場合はWriterに要求を投げることになるのだと思うが、その場合はおそらく書き込みの影響があるのでロックによる排他待ちが発生する。
トランザクションが要求するページがキャッシュヒットすればクラスタボリュームとはやり取りせずにレスポンスを返す。ヒットしなければクラスタボリュームに問い合わせる。
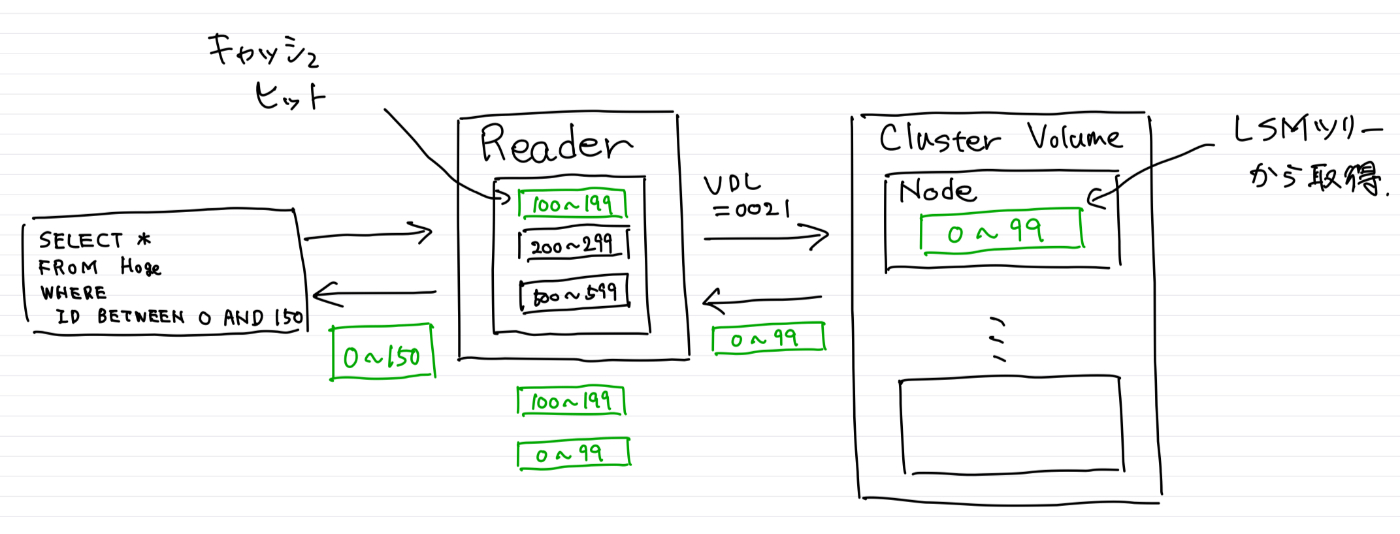
読み取り要求を行う場合は、読み取りトランザクションが発行されたタイミングのVDLを読み取りポイントとして、ストレージにページを要求する。要求を受けたストレージノードは、指定されたVDLまでのログをUpdate QueueとDATA BLOCKSの調停によって組み立ててページを返却する。
このとき、Update Queueには次々と新しいデータが書き込まれるが、読み取りポイントとしてVDLを定義しているため、VDL以降のredoログは考慮する必要がない。よって、LSMツリーのイミュータブルな特性を利用してロックフリーな読み取りができる。
