Cloud Spannerのパフォーマンスチューニングの勘所
この記事はUniposアドベントカレンダー2022の4日目の記事です!
はじめに
Uniposのサーバサイドエンジニアの周東です。新卒でUniposに入社して、1年半も経ちました。
入社当初は「SQLとかどうやって書くんだっけ?大学で習ったけど忘れちゃったな〜」なんて思いつつ、Spannerに挑んで見事に玉砕しました。そこからデータベースに興味を持って深く調べるようになり、今ではデータベーススペシャリスト試験を受験してみたり、キャリアの軸にしたいなーとか思い始めています。
僕にとってSpannerは困難を共に乗り越えたベストフレンドであり、データベースに興味を持つきっかけにもなった思い入れのあるデータベースになりました。
Cloud Spannerを1年半業務で使って知見が貯まってきていますが、まだまだ難しくてわからないことだらけです。でも、Spannerの気持ちがちょっとずつわかってきたので、今回はパフォーマンスチューニングの観点からまとめてみます。エンジニア1年目で一番大変だったのがSpannerのパフォーマンス改善だったので、どこかで思うようにSpannerでパフォーマンスが出せないけど社内に知見がなくて困っている新米エンジニアに届いたらいいなという気持ちで書きます。
※図は丁寧に作るのが面倒だったので低予算クオリティです。
INDEX
この辺は普通のRDBMSでも共通の話です。Cloud SpannerではINDEXもテーブルもどちらもsplitの集合として表現されています。下記の認識で全部INDEXだと思ってたらよさそう。
- ベーステーブル: 主索引(プライマリインデックス)で主キーによる検索が高速
- INDEX: 副次索引(セカンダリインデックス)でキーに指定した属性の順が検索が高速
ベーステーブルの主キー検索が高速な時点でわかりますが、一般的なDMBSのB+木構造と同じく、splitで表現されるデータに対しても範囲検索による高速化が可能です。ちゃんと調べていませんが、おそらく特定のキーの範囲ごとにポインタを持つsplitがあって、まずはそこを参照してスキャンすべきsplitを絞ることで高速化しているんだと思います。
DDLは標準的な書き方です。テーブルの主キーは自動でINDEXのキーの末尾に付与されます。また、split分散の都合上先頭のキーはUUIDにすることが推奨されています。テーブルの主キーが分散に適さない可能性があればUUIDの代替キーを付与してしまうのが良いです。その場合は代理キーとなった元主キーに対してUNIQUE制約の付与を忘れないようにします。
CREATE INDEX <INDEX_NAME> ON <TABLE_NAME>(<KEY01>, <KEY02>);
INDEXはFORCE_INDEXというhintを使って指定します。Cloud Spannerはオプティマイザが優秀で色々よしなにしてくれるのですが、突き詰めていくと自分でちゃんとデータ構造やアルゴリズムを理解した上で、「オプティマイザに解釈の余地を与えない」 ように書いた方が高速なクエリを実現できることが多いです。
-- INDEX指定しない
SELECT * FROM <TABLE_NAME> WHERE <CONDITION>;
-- INDEX指定する
SELECT * FROM <TABLE_NAME>@{FORCE_INDEX=<INDEX_NAME>} WHERE <CONDITION>;
STORING
Cloud SpannerではSTORINGという機能でINDEXのキーとは別のカラムの値を格納することができます。INDEXはキーが16個、合計サイズが8KiBの上限があり、扱うテーブルの性質やカラムのデータ型によってはなんでもかんでもINDEXのキーに入れていると、上限に引っかかってしまうことがあります。そんな時はSTORINGを使います。
CREATE INDEX <INDEX_NAME> ON <TABLE_NAME>(<KEY01>) STORING (<COLUMN01>);
INDEXのコンセプトとして、指定したキー順に並べたポインタをデータとして格納します。
ポインタということは、INDEXのスキャンが完了したら必要な行のデータを取得するために、ベーステーブルまでデータアクセスをする必要があります。特にSpannerは分散DBなのでデータセンタ同士が物理的に離れており、このデータアクセスに大きなオーバヘッドが発生します。そこで、INDEXにキー値以外のクエリに必要なカラムの値を一緒に格納することでデータアクセスを回避することができます。

Null Filtered INDEX
NullableなカラムがあるようなINDEXにおいては、NULL_FILTEREDのhintでキーカラムがNULLなレコードのINDEX追加を無効にすることができます。例えば、特定のカラムがNULLであることが検索条件に入る場合は、この機能を活用することでINDEX自体の容量と行数を削減することができます。STORINGと組み合わせることで,「NULLフィルタされているので高速に検索ができて」・「必要な列だけを格納した」実質的なマテリアライズドビューを実現できます。Spannerはマテリアライズドビューをサポートしていませんが、NULLでフィルタするケースに限っては実現可能であることを知っておくとよいです。
-- KEY02がNULLのレコードはINDEXに追加されない
CREATE NULL_FILTERED INDEX <INDEX_NAME> ON <TABLE_NAME>(<KEY01>, <NULLABLE_KEY02>);
-- STORINGと組み合わせることで、実質的なマテリアライズドビューになる
CREATE NULL_FILTERED INDEX <INDEX_NAME> ON <TABLE_NAME>(<KEY01>, <NULLABLE_KEY02>) STORING (<COLUMN01>, <COLUMN02>);
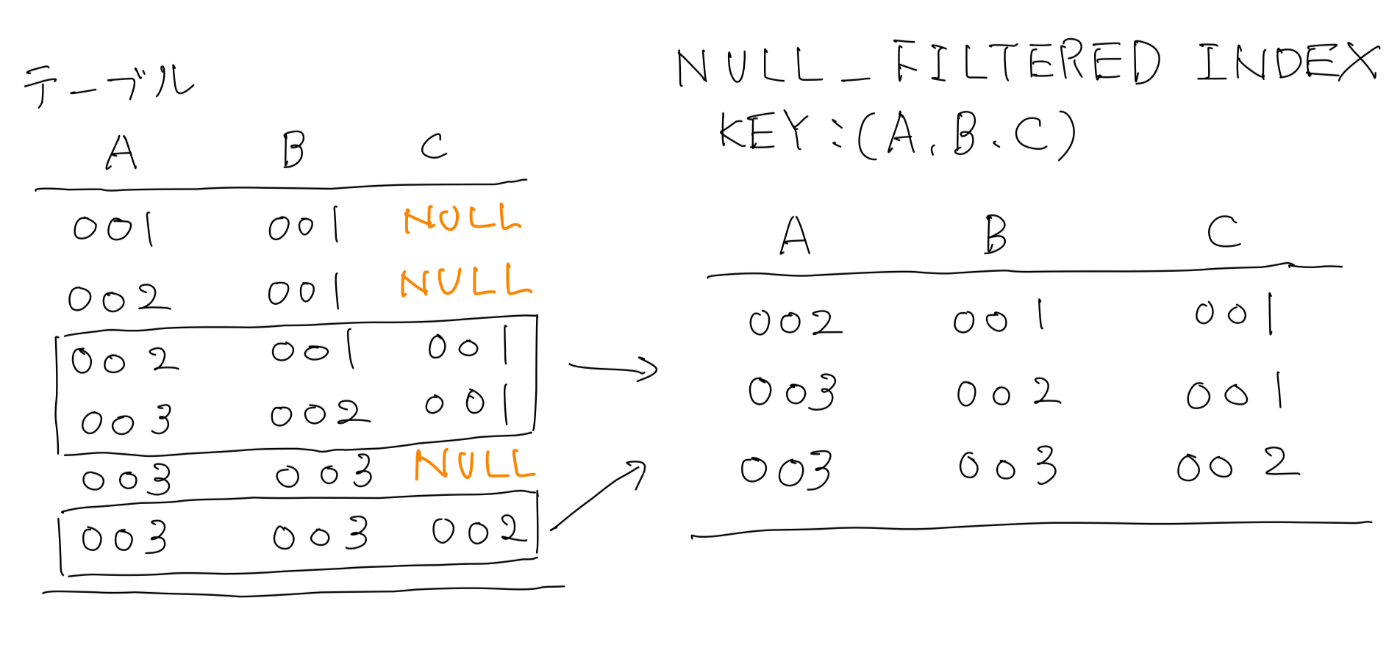
ただし、NULL Filtered INDEXを利用する場合にはINDEXで引けないレコードが出てくるので、知識のない利用者でも通常のINDEXとは違うということがわかりやすい名前にすることをお勧めします。公式のドキュメントでは末尾にNoNullsを付与していますが、弊チームではNullFilteredを先頭に付与する運用にしています。
UNIQUE INDEX
UNIQUE制約を付与する際にはUNIQUE INDEXを作成することで実現します。標準的なDBMSではDDLでカラムごとにUNIQUEオプションを付与したりしますが、実は内部的にはユニーク索引を作成する実装になっていたりするのですが、Spannerでは自分でユニーク索引を作る必要があります。この索引は通常のINDEX同様に利用することができます。
-- KEY01とKEY02の組に対してUNIQUE制約を付与する
CREATE UNIQUE INDEX <TABLE_NAME> ON <TABLE_NAME>(<KEY01>, <KEY02>);
-- NULL_FILTEREDとの合わせ技もできるが、ベーステーブルのUNIQUE制約を保証できない(後述)
CREATE UNIQUE NULL_FILTERED INDEX <TABLE_NAME> ON <TABLE_NAME>(<KEY01>, <KEY02>);
UNIQUE NULL_FILTEREDを指定する場合には、キーのユニーク性が保証されなくなります。キー値がNULLのレコードはINDEX作成の対象外になるため、INDEX作成時のエラーとして検出されないからです。
INTERLEAVEと外部キー
テーブル間の親子関係を表現する場合にはINTERLEAVEを利用します。INTERLEAVEを使うと親と子が物理的に連続な番地にデータが保存されるため、親と子を同時に取得したいようなクエリを高速化することができます。親と子が強エンティティと弱エンティティの関係になっており、親の削除時に子の連鎖削除を行うON DELETE CASCADEの指定もINTERLEAVEを使わないと出来ません。
物理的な格納のイメージは公式docがわかりやすいので引用させていただきます。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;

強エンティティと弱エンティティの実現には一般的には外部キーを用いますが、Spannerでも外部キーを利用することはできます。公式docを見てみるとINTERLEAVEと外部キーの違いはこのように説明されています。外部キーでは連鎖削除ができないことや、物理的な格納場所を一緒にするかどうかなどの違いがあります。

INTERLEAVEを使った子テーブルの取得
INTERLEAVEしたテーブルを高速に取得したい場合には構造体として一緒に取得するクエリが便利です。
SELECT
p.*,
ARRAY(SELECT AS STRUCT c.* FROM Child c WHERE c.ParentId = p.ParentId) Children,
FROM PARENT_TABLE@{FORCE_INDEX=_BASE_TABLE} p
WHERE p.ParentId = <UUID_STRING>;
INTERLEAVEした親子を同時に取得する際の注意点としては、FROM句でINDEXを利用しないことです。ベーステーブルとインデックスは別のsplitに格納されており、INTERLEAVEが定義されたテーブルにしか子テーブルは一緒に格納されていません。遠く離れた場所で高速なINDEX SCANを行った後にネットワークを介して子テーブルのレコードと結合を行うので、データアクセスのオーバヘッドが発生することになります。FORCE_INDEXに_BASE_TABLEを明示的に指定することで副次索引の利用を禁止することができます。
例に挙げたクエリでは主キーを検索条件として指定しているため、特にINDEXを指定しなくても主索引が利用されますが、もうすこしWHERE句の条件が複雑な場合にはオプティマイザが勝手にSCANに有利なINDEXを利用してしまい、結果として子とのデータの結合に時間がかかってしまうケースがあります。
INTERLEAVEした親子を同時に取得したい上に、複雑な条件でINDEXを用いた高速な検索を行いたい時には、クエリ実行のタイミングをWITH句でずらしてしまうことでこの問題を回避できます。
WITH FilteredParent AS(
-- 複雑な抽出条件はINDEX SCANで行って、IDだけ先に抽出しておく
SELECT ParentId
FROM PARENT_TABLE@{FORCE_INDEX=<COMPLEX_INDEX>} p
WHERE <COMPLEX_CONDITION>
)
SELECT
p.*,
ARRAY(SELECT AS STRUCT c.* FROM Child c WHERE c.ParentId = p.ParentId) Children,
FROM FilteredParent fp
-- 抽出したIDに対して、主索引を使ってINNER JOINする
INNER JOIN PARENT_TABLE@{FORCE_INDEX=_BASE_TABLE} p
WHERE fp.ParentId = p.ParentId;
JOINアルゴリズム
SpannerのJOINの記述方法は基本的に標準のSQLと同じですが、いくつか最適化のためのhintが用意されています。ここではよく使うものだけを紹介します。
JOINのメソッドはJOIN_METHODのhintで指定することができます。こちらも適切なメソッドを指定することで、オプティマイザにおまかせよりも高速なSCANを行うことが可能です。知っておくべきなのはAPPLY JOINとHASH JOINの二つです。
SELECT <COLUMNS>
FROM <INDEX_01>
INNER JOIN@{JOIN_METHOD=APPLY_JOIN}
バチッと一発で最適なメソッドを指定するのは難しいので、docをみながらいろんなhintを指定してみて、速くなったら「なんで速くなったんだ?」と考察をしていく方が良いです。僕も試しながら学びました。
APPLY JOIN
APPLY JOINは結合するテーブル同士を上から順番にぶつけていって条件に合致したものを結合していく方式です。メソッドを特に指定しない場合、このアルゴリズムがオプティマイザに選択されることが多いです。
APPLY JOINはドキュメントではCROSS APPLY(分散結合)と表記されていて、Googleも思い入れがあるのか特集記事を書いています。詳しく知りたい人はそちらを参照してみてください。
記事の重要なポイントはこの辺。
Input 側から Map 側への行の送信は、バッチで行われます。この際、DCA は GetRow API を使用して Input 側の行をインメモリ バッファにバッチとしてまとめていき、バッファがいっぱいになった時点で Map 側へと送信します。このバッチ化された行は、送信前に結合列に基づいて並べ替えられます。この例では、Input 側の行はすでに SingerId で並べられているため並べ替えは不要ですが、常にそうであるとは限りません。続けて、バッチがサブバッチ(Map 側のテーブル(Albums)のスプリットごとのサブバッチなど)に分割されます。バッチ内の各行は、それらの行と結合される行を含む可能性がある Map 側スプリットのサブバッチに付け加えられます。バッチを並べ替えておくと、サブバッチへの分割に役立つだけでなく、Map 側でのパフォーマンスも上がります。
要約するとこの3点。
- LEFT側のレコードを上からバッチにまとめて、RIGHT側に送ってるよ
- バッチはsplit単位でサブバッチに分割されて各splitで並列処理できるので速いよ
- LEFT側とRIGHT側は結合に有利なように並び替えておいた方がいいよ
これだけ知っておいても十分高速化できるのですが、データの性質によってはBATCH_MODE=FALSEのhintを付け加えてバッチにまとめるのをやめて、行単位の結合を優先した方が早い例外のケースもあります。行単位の結合とは、文字通りネストループと言われるようなLEFTの行数*RIGHTの行数の素直な総当たりのSCANのことです。

その例外とは、データの並びが考慮されており、LIMIT句に小さな値が指定されていて、LEFTとRIGHTの並びの上の方をちょっとJOINすればすぐにSCANが終わるケースです。バッチ適用ではバッチ単位にLEFT側のデータをまとめるわけですが、そのバッチでLIMIT句に指定しただけのレコードがhitするとは限らない点がポイントです。一度バッチにまとまると、そのバッチもRIGHT側の全行と照らし合わせるまで次のバッチのチェックが始まらないため、バッチの実行数が増えてくるとネストループよりも遅くなることがあります。これはかなりデータの性質に依るので、使い所に気を付ける必要がありますが知っておくと劇的に改善できるケースはあります。
HASH JOIN
HASH JOINは、片方のデータから結合条件を用いたハッシュテーブルを作成し、あとはInput側のレコードを順番にハッシュ値に変換していけばその行に結合すべきレコードを計算量1で取得できるよ!という夢のようなアルゴリズムです。

ここで大事なのは、ハッシュテーブルの作成に時間がかかってしまうということです。ハッシュテーブルの作成に1時間かかるのであれば、APPLY JOINの方が速いでしょう。
HASH JOINで高速化できるケースは、ハッシュテーブルを作成する側のレコード数が少ない場合です。どれくらいで少ないか、というのはわからないので一旦試してみるのもお勧めです。hintとしてHASH_JOIN_BUILD_SIDEを指定することで、LEFTとRIGHTどちらからハッシュ関数を作成するのか指定できるので、結合の対象になるレコード数が少ない方を指定することが高速化に有効です。
SELECT <COLUMNS>
FROM TABLE_A a
INNER JOIN@{JOIN_METHOD=HASH_JOIN, HASH_JOIN_BUILD_SIDE=BUILD_RIGHT} INDEX_B b -- bでハッシュテーブルを作成する
ON a.Id = b.Id
WHERE
-- aの絞り込みはあまり効きがよくない
a.Clmn01 = "hoge"
-- bは指定できる条件が多く、絞り込みの効きがいい
AND b.Clmn01 = "fuga"
AND b.Clmn02 = 1
AND b.Clmn03 = "piyo"
さいごに
長くなってしまいましたが、これら全てを全部マスターする必要はないですし、ここに書いたことはSpannerの一部の一部だけです。ですが、共通して言えることしてはこの辺です。
- オプティマイザに解釈の余地を与えない
- とりあえず持ちうる手段を全て試してみる
- 上手くいったらなんで上手くいったのかを深く考察し、納得する
このポイントをふまえて、少しでもSpannerの気持ちになろうと思える人が増えたらいいなと思います。あと、僕のSpanner愛が伝わったら嬉しいです。最後まで読んでいただきありがとうございました。
読み手が限定的になりそうな話はzennに置いていくようにする予定
Discussion
STORINGに関して、公式docの一部の理解を間違えていたので修正しました。
当初、NULL_FILTERED INDEXにおいてキーにNullableなカラムを入れなくともSTORINGしておけばNULLフィルタがかかると読んでしまっていました。実際には、「NULL_FILTERED と STORINGを組み合わせることでマテリアライズドビューが実現できる」というただそれだけの話だったことに検証の結果気づきました。
と書いてあるので、ストレージコストが削減されるだけでReadパフォーマンスはほとんど改善しなさそうな気がしてきた。
気になったので試した結果、
NULL_FILTEREDをつけてもつけなくてもINDEXのSCAN行数やレイテンシ・CPU時間に変化がなさそう。SCAN行数に関してはINDEX効いていたら変わらないだろうなとは思っていたが、パフォーマンスに関してもほぼ差がないという理解でよさそう。Pricing Calculatorでもわかるけど、Node(PU)の課金が圧倒的なのでデータストレージの節約の影響は微々たるもの。
パフォーマンスを改善するために無理な非正規化を行った結果、Nodeあたりのデータストレージのサイズの上限に来てしまいPUを上げる(=課金も増える)しかないみたいなことになるのがつらいので、ストレージサイズのための課金を避けるという側面が強そうだなと感じた。