SSD-Mobilenet メモ
なぜ今 SSD-Mobilenet なのか
学校で NVIDIA Jetson Orin Nano を使っていて、物体検出をしたかったため。
Jetson で物体検出を行う際に、MobileNet は軽量でよく使われるモデルとして知られている。
Nvidia が onnx にエクスポートするツールを提供しているので、すぐに Jetson で動かせる。
また、私が知見を元に変更を加えたフォーク版もある。
この記事の目的
私が Jetson で物体検出を行った際に、発生した問題や精度向上についてのメモを残す。
Windows または Linux(Ubuntu) で動かしたい人の参考になれば幸い。
環境構築
pytorch-ssd-forkedを利用する場合は、忙しい人向け環境構築を参照してください。
git clone https://github.com/dusty-nv/pytorch-ssd
cd pytorch-ssd
ドキュメントが古い上にバージョンについて詳しい記載がないため、何をインストールすれば良いのかわからない。
可能な限り最新の環境で動作させることを目指す。
Python 3.6 + PyTorch 0.4 とか使ってられないので
幸いにも、ほぼ最新の環境(Python 3.12 + PyTorch 2.5.1 + CUDA 12.4) でそのまま動作した。
最新は Python3.13 であるが、PyTorch が対応していないため、Python3.12 で動かす。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
pytorch-ssd の requirements.txt は利用せずに手動でインストールする。
この時に依存としてインストールされる、numpy は新しすぎて動かないが、後で直す。
protobuf も新しいものは動かないので、4.25 に固定する。
pip install boto3 pandas urllib3 tensorboard opencv-python protobuf==4.25
run_ssd_example.py を修正して最新の numpy でも動くようになる。
1 行変えるだけで直ったのがうれしい。
- box = boxes[i, :]
+ box = list(map(int, boxes[i, :]))
MobileNet V2 で GPU を使ってくれない問題を修正するには vision/ssd/mobilenet_v2_ssd_lite.py を修正する。
なぜこれだけ、device が CPU になっているのか謎。
- def create_mobilenetv2_ssd_lite_predictor(net, candidate_size=200, nms_method=None, sigma=0.5, device=torch.device('cpu')):
+ def create_mobilenetv2_ssd_lite_predictor(net, candidate_size=200, nms_method=None, sigma=0.5, device=None):
そして、README に書いてある Google Drive のリンクからモデルをダウンロードする。
このモデルのライセンスは不明、ソースコードと同じという解釈で良いのかな。
忙しい人向け環境構築
私の作成した fork 版を使用する。上記の問題を修正しているので、忙しい方はこちらを使うと良い。
git clone https://github.com/fa0311/pytorch-ssd-forked
cd pytorch-ssd-forked
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
pip install -r requirements.txt # うまくいかない場合は pip install -r requirements-lock.txt
wget https://github.com/fa0311/pytorch-ssd-archive-model/releases/download/v0.0.1/mobilenet-v1-ssd-mp-0_675.pth -O models/mobilenet-v1-ssd-mp-0_675.pth
wget https://github.com/fa0311/pytorch-ssd-archive-model/releases/download/v0.0.1/mb2-ssd-lite-mp-0_686.pth -O models/mb2-ssd-lite-mp-0_686.pth
忙しい人向け環境構築 (Docker)
Entrypoint は tensorboard を起動するように設定している。
Jetson で MobileNet V3 を動かす
Nvidia が Fork した後に、MobileNet V3 が追加されたので、Nvidia の Fork には MobileNet V3 が含まれていない。
マージしてあげれば動くが、コンフリクトしまくって大変だった。
あんまりテストしてないので、動かないものもあるかもしれない。
学習とパラメータ
train_ssd.py で学習する際のパラメータを説明する。
MobileNet V2 で VOC を学習する場合の例を示す。
python train_ssd.py `
--pretrained-ssd=models/mb2-ssd-lite-mp-0_686.pth `
--net=mb2-ssd-lite `
--dataset-type=voc `
--data=data/voc `
--model-dir=models/output `
--validation-epochs=1 `
--num-workers=8 `
--batch-size=32 `
--num-epochs=30 `
--t-max=30 `
--lr=0.001 `
--extra-layers-lr=0.0001 `
--base-net-lr=0.001 `
--weight-decay=0.0001 `
--validation-mean-ap
また、Windows では pickle 化がうまくいかないため num-workers は 0 にしないと動かない。
並列処理ができないため、かなりの時間を要する。
デフォルトのスケジューラー (--scheduler=cosine) を利用する場合、--t-max はデフォルトが100で、--num-epochs と値が違う場合は --t-max を指定したほうが良い。
--base-net-lr はベースネットワークの学習率で、--extra-layers-lr は追加のレイヤーの学習率である。
どちらも指定していると、--lr は無視されるはずだが、SGD でこの値が使われていそうなので念の為指定する。
この例では行っていないが、--freeze-base-net を指定することで、ベースネットワークの学習を行わず、追加のレイヤーのみ学習することができる。
--freeze-base-net を指定する場合、--base-net-lr は無視される。
--validation-mean-ap を指定することで、Validation の mAP を計算することができる。
学習率のパラメータなどの具体的な値は適当です。実際に動かしてみて調整してください。
tensorboard --logdir models/output/tensorboard で学習の進捗を確認する。
pytorch-ssd-forked を利用する場合
pytorch-ssd-forked で学習する際のパラメータを説明する。
MobileNet V2 で VOC を学習する場合の例を示す。
python3 train_ssd.py `
--pretrained-ssd=models/mb2-ssd-lite-mp-0_686.pth `
--net=mb2-ssd-lite `
--dataset-type=voc `
--data=data/voc `
--model-dir=models/output `
--validation-epochs=1 `
--num-workers=8 `
--batch-size=32 `
--num-epochs=56 `
--t-0=8 `
--lr=0.001 `
--extra-layers-lr=0.0001 `
--base-net-lr=0.001 `
--weight-decay=0.0001 `
--validation-mean-ap `
--scheduler=cosine-warmrestart `
--no-augment
--no-augment を指定することでデータ拡張を削除することができる。
データ拡張を削除したい場合は、このオプションを指定する。
--scheduler=cosine-warmrestart を指定することで、スケジューラーを CosineAnnealingWarmRestarts に変更する。
これにより局所最適解に陥りにくくなる。
--t-0 で最初にリセットされるエポック数を指定することができる。
実際に利用した結果は以下の通りで、8, 24 エポック目で学習率がリセットされていることがわかる。
(最初の周期で8エポック、次の周期で16エポック、次の周期で32エポック、次の周期で64エポック、という感じでリセットされる)

ハードコーディングされているパラメータを変更する
MultiboxLoss のパラメータがハードコーディングされているので、変更する。
neg_pos_ratio はデフォルトで 3 になっているので、調節する。
他にも iou_threshold center_variance size_variance という引数が与えられているが、使われていないように見える。(要検証)
データ拡張を削除する
TrainAugmentation がデータ拡張を行っているが、色を変更する必要がない場合や、欠けている物体を認識する必要がない場合は削除したほうが良い。
この辺は、認識させたい物体やデータセットによって異なるので、適宜削除する。
以下はいちごの写真だが、いちごは必ず赤色であり、色を大きく変更する必要がない。彩度や明るさを変更するだけで十分である。
人間が見て、いちごとは認識出来ないものが生成されている。

私は独自のデータ拡張プログラムを作成してデータ拡張しているので削除した。
self.augment = Compose([
ConvertFromInts(),
- PhotometricDistort(),
- Expand(self.mean),
- RandomSampleCrop(),
- RandomMirror(),
ToPercentCoords(),
Resize(self.size),
SubtractMeans(self.mean),
lambda img, boxes=None, labels=None: (img / std, boxes, labels),
ToTensor(),
])
SubtractMeans によって色が見やすくなっており、lambda img, boxes=None, labels=None: (img / std, boxes, labels) によって色が薄くなっている。
色が重要な場合は、これらを削除したほうが良さそうだが、せっかくの転移学習が台無しになるかもしれない。この辺は検証が必要。
また、train_loader の中身を確認するには以下のプログラムを train_loader が読み込まれた後に追加すれば良い。
train_loader には TrainAugmentation が適用されたデータが格納されている。
pytorch-ssd-forked を利用する場合は、--no-augment を指定することでデータ拡張を削除することが出来る。
for i, data in enumerate(train_loader):
images, boxes, labels = data
for ii, img in enumerate(images):
rgb = cv2.cvtColor((img.permute(1,2,0).numpy() * 255).clip(0,255).astype(np.uint8), cv2.COLOR_BGR2RGB)
cv2.imwrite(f"images/{i}-{ii}.jpg",rgb )
データ拡張を削除するべき状況
- すでに既存のデータセットで十分なデータ拡張が行われている場合
- Validation Loss が Train Loss よりも低い
私の場合、後者の問題で悩み、データ拡張を削除したところ解決した。
過学習させる
学習を辞める目安やパラメータを調整する際の目安として過学習させたいが、MobileNet は軽量なため、過学習させるのが難しい。
エポック数を増やしたり、学習率を下げたりしても、過学習しない。
また、デフォルトでは cosine スケジューラなので、100 エポックで学習率が 0 になり、それから学習率が上がる。
TrainAugmentation によるデータ拡張を削除し、SGD の --weight-decay を小さくすることで、過学習させることができる。
調整して過学習させたものと比較したものが以下の画像のグラフ。20 エポックを超えたあたりから Classification Loss/val と Loss/val が上がっているのがわかる。

モデルの評価
run_ssd_example.py は、単一の画像しか受け付けず、少し不便なのでカメラからの入力を受け付けるスクリプトを作成した。
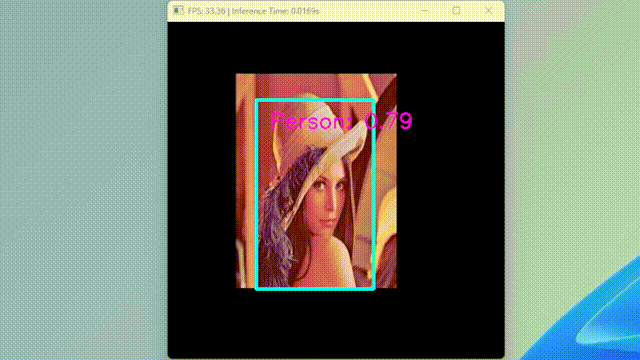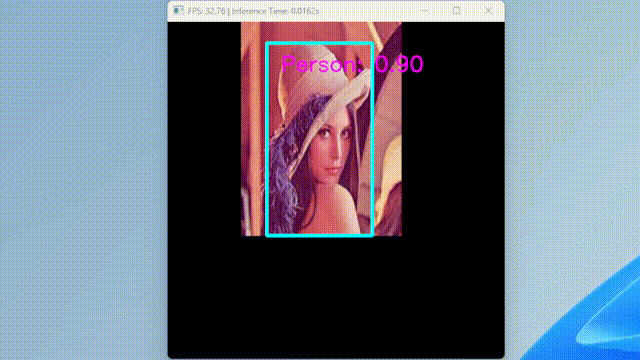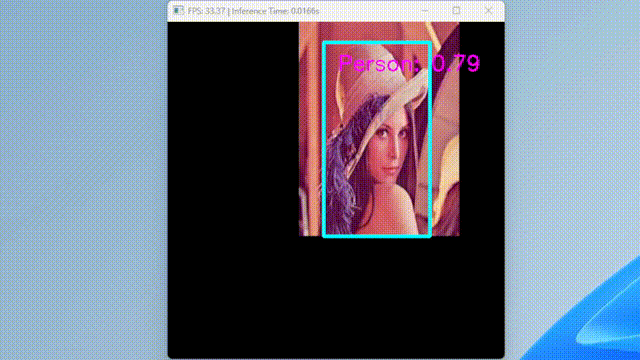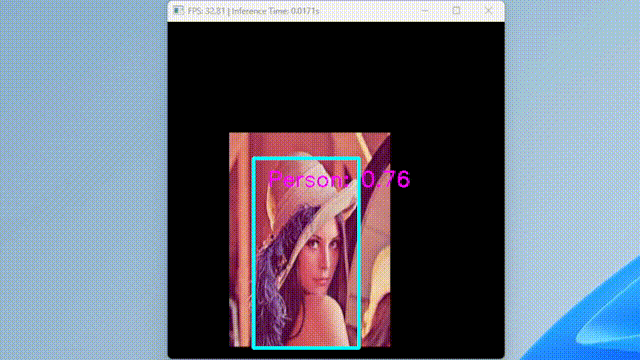
GIF にする際にフレームレートを下げたため実際よりも遅く見えるが、実際は 30 FPS で動いている。
ちなみに、TensorRT に変換して Jetson で動かすと、80 FPS くらいで動作する。
Discussion