【6章】データベースリライアビリティエンジニアリング【スライド】
DBRE 輪読会 vol.06
2021/08/04
~インフラストラクチャマネジメント~
おさらい
1 章:学習を続け、チームを超えて改善を進める
2 章:SLO が全ての基礎
3 章:SLO のためにリスクを認識し低減する
4 章:SLO への影響を知るための見える化
5 章:DB クラスタ構築の実践例
この章で学ぶこと
前章で学習したインフラストラクチャのコンポーネントを
どのように管理しスケールさせていくかに着目
具体的には以下について学ぶ
- インフラのコード化
- インフラ構築の自動化
- バージョン管理
目次
- 1. データベースインフラ設定の定義
- 2. データベースインフラ設定とビルド
- 3. データベースインフラ設定の管理
- 4. インフラストラクチャ定義とオーケストレーション
- 5. テストとコンプライアンス
- 6. サービスカタログ
- 7. まとめ
- 8. 次回
1. データベースインフラ設定の定義
DB クラスタの設定とビルドの自動化に
以下のような設定管理ツールを用いると良い
- Chef
- Ruby と Erlang ベースの構成管理ツール
- Ruby を拡張した Ruby DSL で Recipe, Cookbook を記述する
- Puppet
- JSON ライクな独自の DSL で Manifest と Module を記述する
- Ansible
- RedHat 製、Python ベースの構成管理ツール
- YAML で Playbook を記述する
- SaltStack (Salt)
- Python ベースの構成管理ツール
- YAML で Formula を記述する
- CFEngine
- C ベースの構成管理ツール
- 1993 年にリリース (Ansible は 2012 年)
1. データベースインフラ設定の定義
設定管理ツールのメリット
- 冪等性を担保できる
- 変数パラメータを活用することにより、開発環境やテスト環境に合わせて設定を柔軟に変更できる
- 構築物のテストが容易
2. データベースインフラ設定とビルド
コードからインフラを構築する場合、大きく 2 つ方法がある
- ベイキング(Baking)
- パン種をオーブンでチンするだけ
- システムの起動前に構成を追加する(ex. AMI)
- ゴールデンイメージの問題
- フライング(Frying)
- 小麦粉、卵、パン粉といった下処理をした上で揚げる必要がある
- システムの起動後に構成を追加する(ex. 前述のツール)

参考: https://joachim8675309.medium.com/devops-concepts-bake-vs-fry-2-c2973d532c92
3. データベースインフラ設定の管理
設定漂流(Configuration Drift)を避けるためにイミュータブルインフラストラクチャを行う
利点
- 設定変更を禁止することで、インフラの状態が構築時と変わっていないことを保証する
- インフラの状態が構築時と変わらないため、問題発生時の調査が容易
- ゴールデンイメージを利用して状態を再現できるので、MTTR を短縮できる
3.1. 設定定義の更新
設定定義に基づいたインフラの更新方法には、以下の 2 種類がある
- 全サーバー間で設定を同期する
- 発生してしまった未コミットの変更を、同期時に正しい設定に戻す
- サーバーの再構築
- 未コミットの変更が発生し次第、自動的にサーバーを破棄・再構築する
設定ツールを使うことにより、各サーバーがコミットされたコードのみで動作できる
4. インフラストラクチャ定義とオーケストレーション
オーケストレーションツールとは
- インフラのデプロイを統合管理するもの
- インフラを、アプリケーションやサービスといった高レイヤのコンポーネントと結合
- 開発者がインフラからアプリケーションの構築とデプロイまでを一括して実行できるようになる
インフラを定義する際は、スタックという用語が使われる。
スタックとは、サービスを構成するコンポーネントを階層化してリストにまとめたもの
4.1. モノリシックなインフラストラクチャ定義
すべてのアプリケーション、全てのサービスが 1 つの大きな定義の中に収まる
モノリシックなインフラストラクチャ定義には、悪い点がたくさんある
- 1 つの設定を更新した場合に、全ての設定をテストし直す必要がある
- そのためテストに時間がかかる。テストが失敗しやすい。開発者が変更を嫌う
- 設定が適切に分離されていない場合、1 つの変更が全体を壊す可能性がある
- コンポーネントの一部だけをテストしたい場合でも、全てを一緒にビルドする必要がある
- インフラの全体像を把握できているのが一部の開発者のみになりやすい
- そのため、変更に時間がかかり、ボトルネックになる
4.2. 垂直的な分割
垂直的な分割によってより小さく、よりシンプルなアーキテクチャ単位で構築/管理が可能になる
また、障害が発生しても、影響範囲を対象のサービスのみに留められる
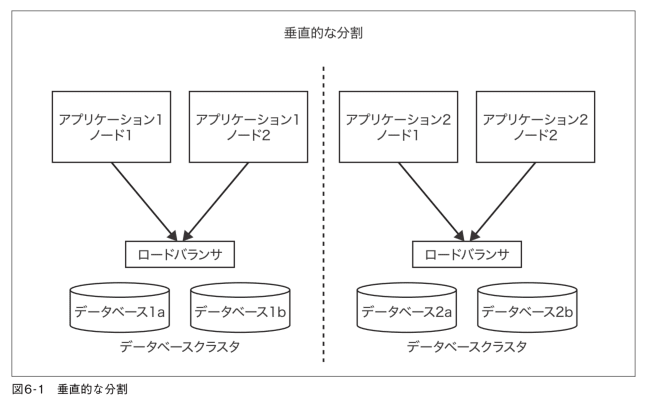
アプリケーションが DB を共有している場合は、DB をシャーディングする必要がある

4.3. 水平的な分割
ウェブサーバー、アプリケーション・サーバー、DB サーバーをそれぞれのスタックに分割することで、さらに障害発生時の影響を抑えられる
ex. DB サーバーの設定変更によって、ウェブサーバーの挙動が変わることがない
5. テストとコンプライアンス
ServerSpec のようなツールを使用することで、インフラのイメージに対してテストを走らせることが可能
-
ServerSpec
- Ruby ベースのサーバーの自動テストツール
- 構築したサーバーに SSH で接続し、用意したテストコードを実行する
- テストコードは RSpec で記述する
- コンプライアンスやセキュリティのテストが可能
6. サービスカタログ
インフラのコード化によって自動でビルド、スケール、破棄されるようになると、サーバーの現在の状態を把握できるものが必要になる
- サービスディスカバリ
- 特定の機能やサービスが持つサーバーの IP アドレスやホスト名をマッピングして意味のある名前付けを行う
- これにより、サービスレベルでサーバーやサーバー群の状態を管理できる
- Ex.
- AWS Cloud Map
- Zookeeper
- Consul.io
- Etcd
7. まとめ
以下は DBRE として絶対に必要なスキルセット
- インフラのコード化
- インフラ構築の自動化
- バージョン管理
これらにより、以下が達成できる
- 骨折り仕事を自動化
- ヒューマンエラーの撲滅
- 自己完結するサンドボックス環境の提供
8. 次回
データの一貫性と冗長性を保証するため、バックアップとリカバリについて、考察を進めていく
Discussion