はじめに
初めまして、株式会社エクサウィザーズのWANDチームでインターンをしている東光です。本記事では、近年注目を集めているベクトルDBのパフォーマンス向上を目的とした、最適なベクトルインデックスの選択方法を紹介します。具体的には、一般的なベクトルインデックスへの見解と実際に実験した知見から、ベストプラクティスを目指すための考え方を示します。
背景
ベクトルDBとベクトルインデックスの関係
生成AIの飛躍が激しい今、ベクトルDBは多くのAIプロダクト(RAG, AI Agent)に利用されています。実際、僕がインターンをしている株式会社エクサウィザーズのAIプロダクトもAmazon AuroraにてベクトルDBを使用しています。そんなベクトルDBですが、課題もあります。それは、データ数が多くなるとDBの効率が悪くなるという点です。この問題に対して、一般的にベクトルインデックスを導入すると、ベクトルDBを効率化することができます。(図1からベクトルインデックスの威力がわかると思います。ベクトルインデックスなし(左図)の応答時間4秒。ベクトルインデックスあり(右図)の応答時間0.007秒。)
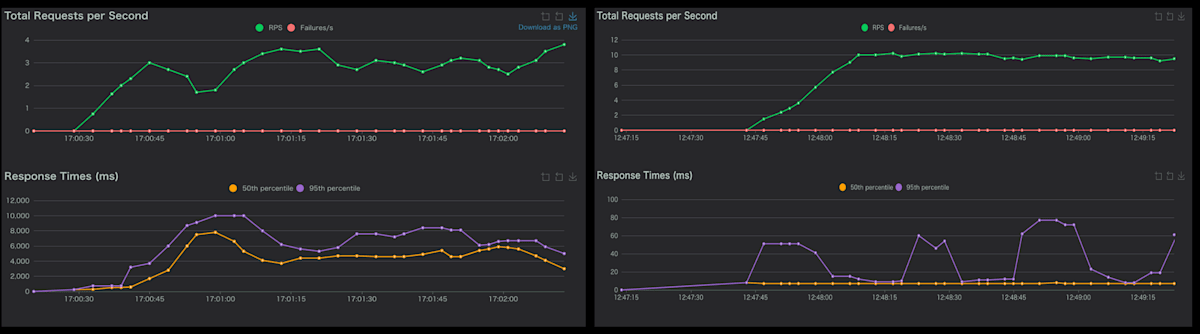
fig.1 ベクトルインデックスの有無による応答時間の差。
左がベクトルインデックスなし。右がベクトルインデックスあり。
ベクトルインデックスの特徴は、「インデックス構築手法が沢山あり、どの手法もハイパーパラメータを数多く持つ」ことです。ベクトルインデックスの代表例としてIVFFLATとHNSWがあります。それぞれの特徴を以下にまとめます。
IVFFLATとは
IVFFLATは、k-means型のクラスタリング構成でデータを保管します。図2は、IVFFLATのクラスタリングのイメージ図です。

fig.2 IVFFLATのイメージ図。⚫︎がデータ(ベクトル)。▲がIVFFLAT内で作成したクラスタ。
IVFFLATを用いたベクトルインデックスでは、DBに登録されたデータ(ベクトル)を複数のクラスタに分けて管理します。検索時は、クエリベクトルに近いクラスタを特定し、そのクラスタに属するデータから探索を行います。
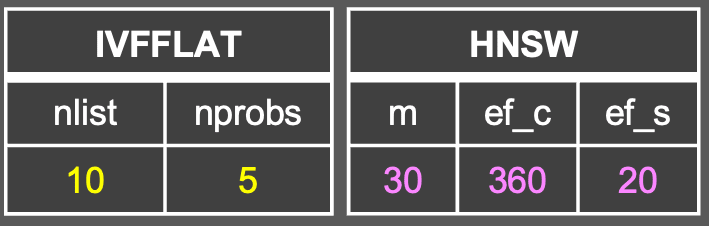
また、IVFFLATにおけるハイパーパラメータは以下になります。
- インデックス構築時のハイパーパラメータ
-
nlist: 何個のクラスタを配置するか
-
- 検索時のハイパーパラメータ
-
nprobes: 何個のクラスタを探索範囲にするか
-
※もっと詳しくIVFFLATを知りたい方はこちらの記事に詳細な情報が記載されています。
HNSWとは
HNSWは、階層クラスタリングとグラフ構造を組み合わせた構成でデータを保管します。図3は、HNSWのクラスタリングのイメージ図です。
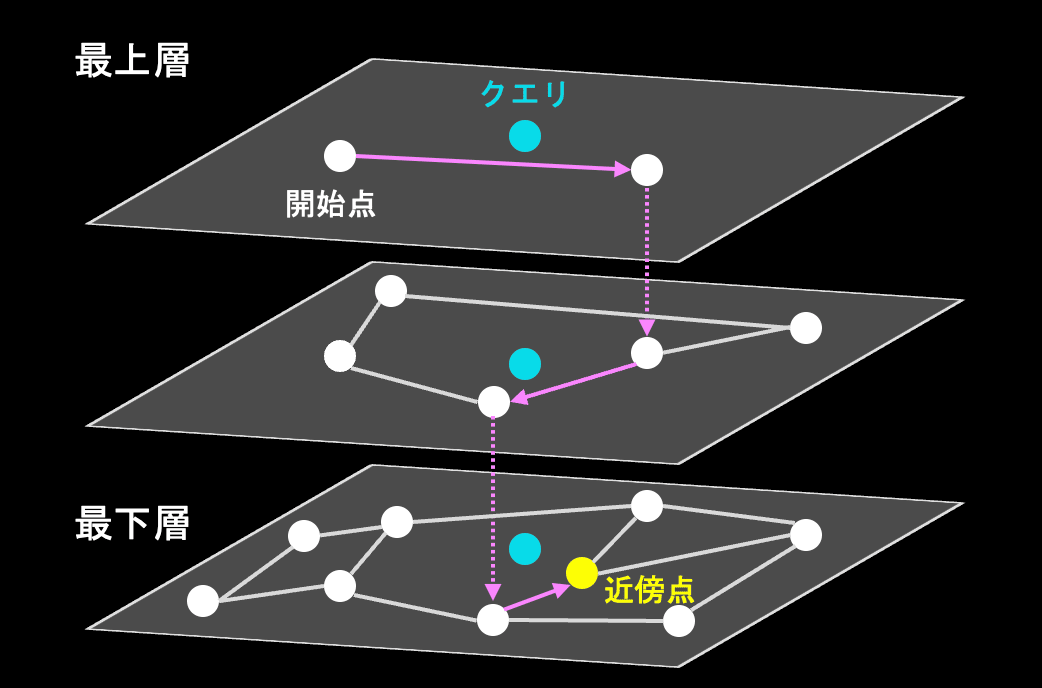
fig.3 HNSWのイメージ図。⚫︎がデータ(ベクトル)。
HNSWを用いたベクトルインデックスでは、DBに登録されたデータ(ベクトル)を階層的なグラフ構造の点(ノード)として管理します。検索時は、グラフの最上位層(最も疎な層)から探索を開始し、クエリベクトルに近いノードをたどりながら、効率的に下の層(より密な層)へと絞り込み、最近傍のデータを見つけ出します。
なお、HNSWにおけるハイパーパラメータは以下になります。
- インデックス構築時のハイパーパラメータ
-
m: グラフの各ノードが持つ接続(エッジ)の最大数。 -
ef_construction: グラフ構築時に、各ノードの最適な接続先を探すための探索範囲の広さ。
-
- 検索時のハイパーパラメータ
-
ef_search: 検索時に、候補となるノードを保持するリストのサイズ。
-
※もっと詳しくHNSWを知りたい方はこちらの記事に詳細な情報が記載されています。
ベクトルインデックスの課題
話を戻します。これまで述べた通り、ベクトルインデックスの構築手法は数多く存在し、どの手法もハイパーパラメータを複数持っています。それゆえ、実務において、「どのベクトルインデックスを採用し、どのパラメータをチューニングすれば良いか」が明らかになっていません。ベクトルDBのインデックスは、理論的な比較はあるものの、「試してみないとわからない」ことが多く、毎回実測評価が必要なのが現状です。
※IVFFLATとHNSWの一般的な見解をまとめたものはこちらの記事に記載されています。
目的
そこで本記事では、一般的なベクトルインデックスへの見解と、実際に実験して得られた知見から、ベクトルDBにおけるインデックスのベストプラクティスを探ることを目的とします。具体的には、IVFFLATとHNSWに対して、「どちらを優先して選択するべきか」、「パラメータチューニングの方法はどうするべきか」の指針を示します。
先にまとめ
忙しい方向けに、先に結論を述べます。
一般的な見解&実験して得られた知見をまとめた表
| 特徴 | 一般的な話 | 実際に試して得た知見 |
|---|---|---|
|
メモリ使用量 ビルド時間 CPU |
IVFFLAT:○ HNSW: × |
・メモリ使用量&ビルド時間は理論通りIVFFLATの方が優れている。 ・CPU使用率はHNSWの方が優位。 |
| ドリフト耐性 |
IVFFLAT: × HNSW: ○ |
・ドリフト耐性は理論通り、HNSWの方が高い。 ・検索精度自体も、IVFFLATよりHNSWの方が高い。 |
| 速度・精度 |
IVFFLAT: × HNSW: ○ |
・検索精度は理論通り、HNSWの方がIVFFLATより高い。 ・HNSWでは、インデックス時に計算コストをかけると 精度劣化を防止できる。 ・検索精度が同一の条件では、クエリ速度はHNSWの方が高速。 ・HNSWでは、インデックス構築時に計算コストをかけると、 検索時のCPU使用率を抑えられる。 |
※ドリフトとは、ベクトルインデックス構築時のデータ分布とクエリ時のデータ分布が異なる状況のことを指します。
この記事における結論
上記の表から以下のことが言えます。
実験の前準備
まとめに示した事項について、この章以降では実際に実験を行った結果を示します。先に実験環境・評価指標の説明をしてから、
- メモリ使用量・ビルド時間及びCPU使用率の検証
- ドリフト耐性の検証
- 検索精度と検索速度の検証
について説明します。
実験環境
| カテゴリ | 名称 | バージョン |
|---|---|---|
| 実行環境 | AWS Aurora Serverless PostgreSQL | 17.5 |
| プラグイン | pgvector | 0.4.1 |
| 基盤モデル | Dinov3 | vitb16 |
|
使用した ベクトルインデックス |
IVFFLAT HNSW |
使用したデータセット
衛星画像の画像データをベクトルDBで検索するタスクを実行しました。検証で使用したデータセットにEuroSATを用いました。(Kaggle上にデータが公開されています。)EuroSATは、図4のように衛星画像とラベルがセットになったデータが格納されています。

fig.4 EuroSATデータの一例紹介。左の画像は河川の衛星画像、右の画像は住宅街の衛星画像。
このEuroSATの画像を基盤モデルDinov3-vitb16でベクトル化し、DBに登録しました。データの具体的特徴を以下にまとめます。
| データサイズ | ベクトル次元数 | ラベル数 |
|---|---|---|
| 27000 | 768 | 10 |
※データサイズ(27000件)は、EuroSAT kaggle-datasetの'train.csv', 'test.csv', 'validation.csv'ファイルを結合させたサイズです。
最後に基盤モデルDinov3-vitb16が、画像を適切に分類できているかをU-MAPを用いて検証しました。図5はその結果です。この結果から、画像は基盤モデルDinov3-vitb16によって適切に分類できていることが確認できます。
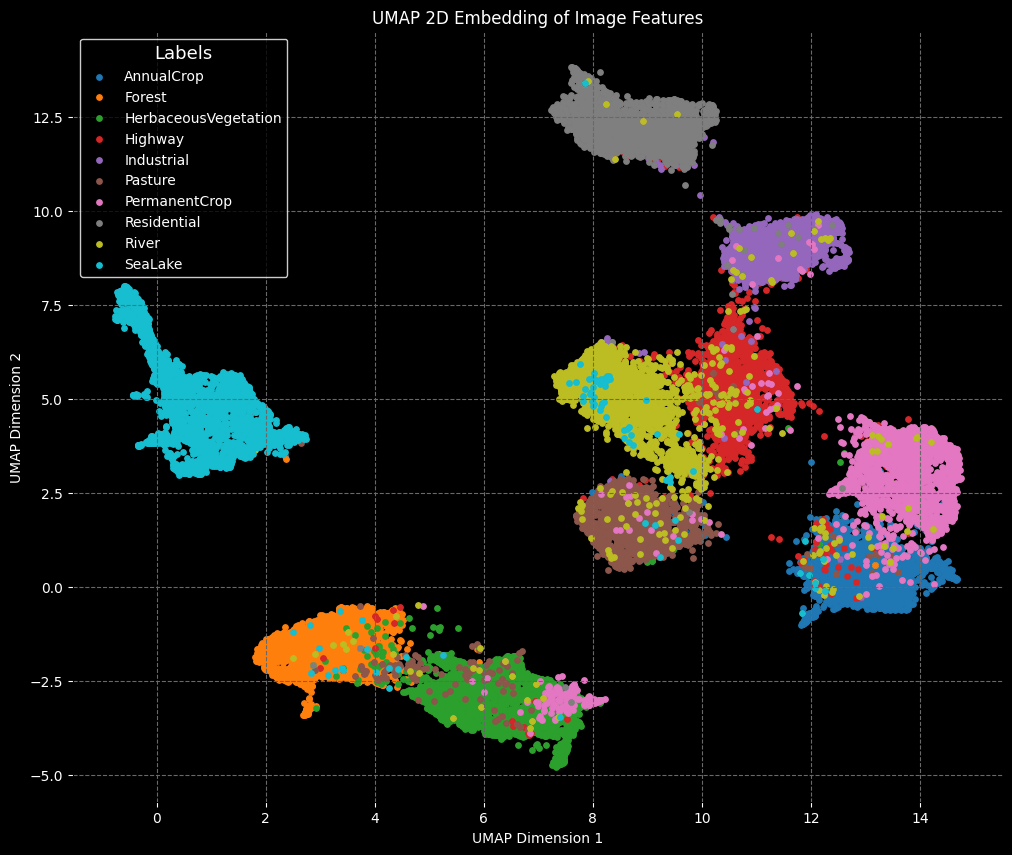
fig.5 U-MAPを用いたEuroSATデータ分布の可視化
評価指標(正解率)の定義
ここでは、メモリ使用量・ビルド時間及びCPU使用率の検証・ドリフト耐性の検証・検索精度と検索速度の検証で使用する「正解率」について説明します。この評価は、クエリに対してどれだけ正確なラベルを検索できるかを測定することを目的とします。以下に計算方法の手順を示します。
1. ラベル予測:
1つのクエリに対し、クエリ近傍上位n件をデータベースから取得します。そのn件の中で最も多いラベル(最頻値)を、クエリの予測ラベルとします。 (近傍1位から順にラベルを確認していき、同数の最頻値が現れた場合は、順位が若いラベルを優先します。)
- クエリ近傍上位n件のデータ
L = [l_1, l_2, \dots, l_n] -
P_i i
と定義すると、最終的な予測ラベル
※ここで
2. 正解率の計算:
「1. ラベル予測」を全ての検証データで行い、予測ラベルと本来の正解ラベルが一致した割合を正解率として算出します。
メモリ使用量・ビルド時間及びCPU使用率の検証
HNSWとIVFFLATに対して、インデックス構築時のメモリ使用量・ビルド時間を一般論と比較して検証を行いました。また、クエリ時のCPU使用率を比較しました。
インデックス構築時のメモリ使用量・ビルド時間について
HNSWはIVFFLATに比べ、複雑なデータ構造を取ります。それゆえ、一般的には「インデックス構築時はHNSWの方がIVFFLATに比べ、インデックス構築時の時間・メモリ消費量が重い」と言われています。そこで、実際にどの程度両者の間に差があるのかを検証しました。
実験方法
- DBにEuroSATデータ27000件を登録。
- 以下のベクトルインデックスをDBにそれぞれ構築する。
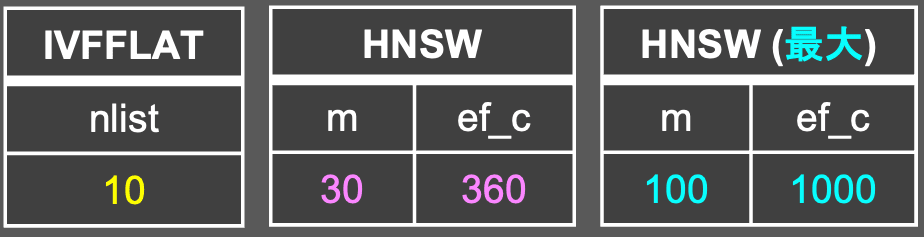
- インデックス構築までの時間・メモリ消費量をAWSのCloudWatch Metrics上で計測。
※実験を行ったAurora Serverless PostgreSQLの最大・最小容量 = 4
結果
図6にインデックス構築時間とメモリ消費の関係を表したグラフを示します。グラフから、IVFFLATの方がHNSWに比べ、インデックス構築にかかるビルド時間・メモリ消費量が少ないことがわかります。この結果は一般論の傾向と一致しているため、妥当な結果だと言えます。また、HNSWのハイパーパラメータを増やすと、ビルド時間・メモリ消費量ともに増加することが読み取れます。これも、ハイパーパラメータを増加させると、HNSWのデータ構造が複雑になるので、直感と一致した結果になります。
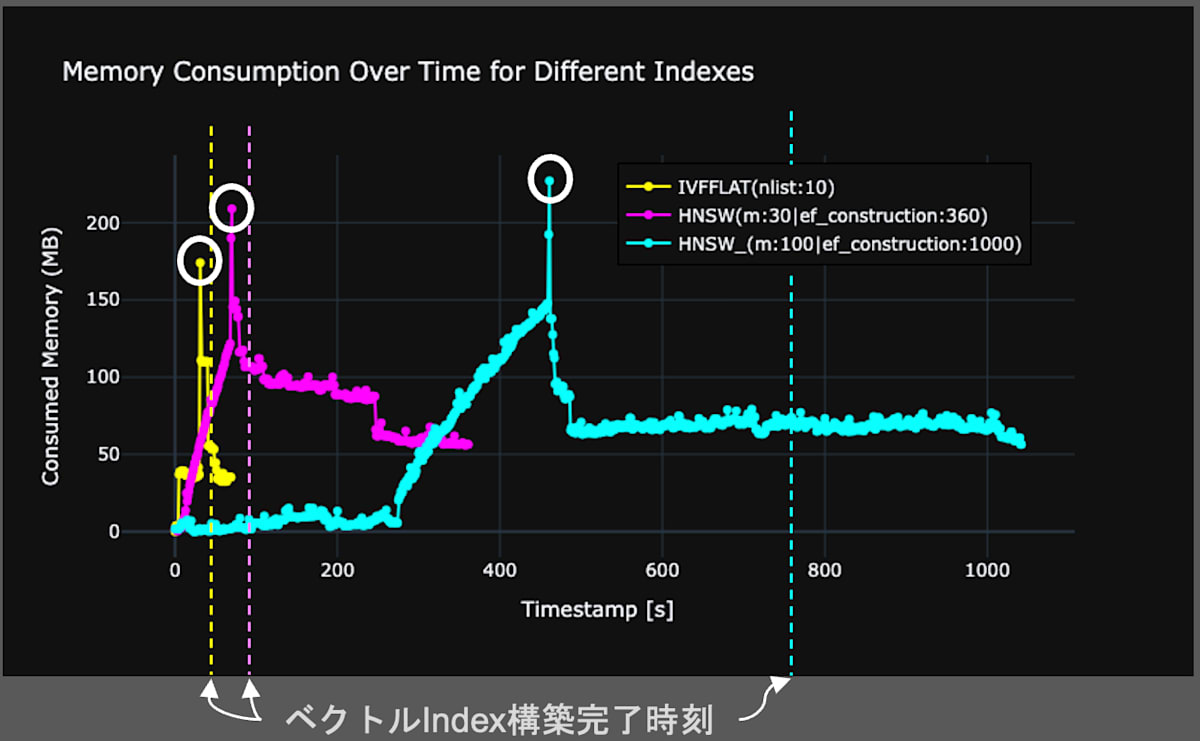
fig.6 インデックス構築時間とメモリ消費量の関係。横軸は時間、縦軸は消費メモリ量を示す。
図6の結果から、一般的な見解と同じく、IVFFLATの方が、HNSWよりインデックス構築時間 & メモリ消費は軽いと言えます。最後に、HNSWのインデックス構築時に消費するメモリの量は、理論値が存在しており、図6の数値の信頼性については補足事項HNSWの理論値と実験値の比較にて説明しています。
クエリ時のCPU使用率について
ベクトルインデックス構築後のDBのクエリ時におけるCPU使用率を調べました。
実験方法
- DBに訓練用EuroSATデータ(train.csvとvalidation.csv)を登録する。
- 以下のベクトルインデックスをDBにそれぞれ構築する。
- 負荷実験ツールLocustを用いてDBへ大量のクエリを投げる。(1秒間に1人ずつユーザーが増加し、最大20人まで増えるシナリオを適用)
- CloudWatch Metricsにて、CPU使用率を計測。
※実験を行ったAurora Serverless PostgreSQLの最大・最小容量 = 1
結果
図7にHNSWとIVFFLATにおける、クエリ時のCPU使用率を比較したグラフを示します。グラフから、HNSWの方がIVFFLATよりもCPU使用率が少ないことがわかります。これは、HNSWはデータ構造が複雑なので、クエリデータに近いデータを探索する際に、グラフを効率的に辿ることで計算量を抑えられるからだと考察します。一方、IVFFLATは、候補となるクラスタ内の全データと総当たりで比較するため、CPU負荷が高くなる傾向にあります。
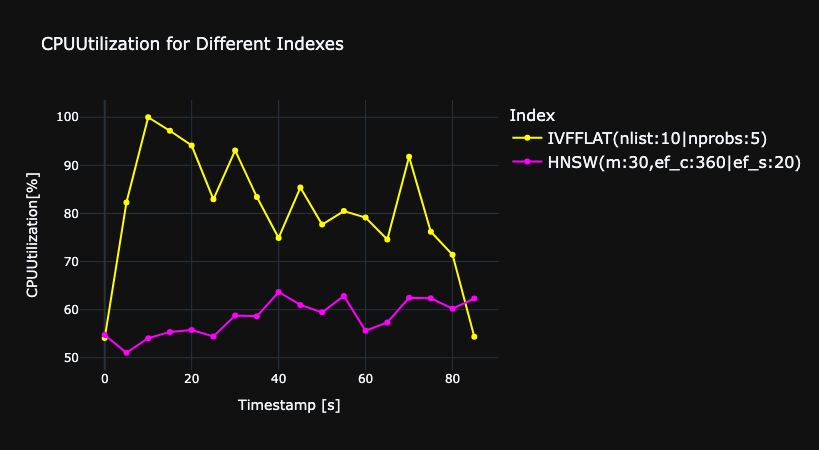
fig.7 クエリに対するCPU使用率の関係。横軸は時間、縦軸はCPU使用率を示す。
この結果から、クエリ時は、HNSWの方がIVFFLATよりもCPU使用率が少ないことがわかりました。
メモリ使用量・ビルド時間及びCPU使用率の検証から得られた知見
ドリフト耐性の検証
HNSWとIVFFLATに対して、データのドリフト耐性を比較・検証しました。(ここでのドリフトとは、ベクトルインデックス構築時のデータ分布とクエリ時のデータ分布が異なる状況のことを指します。)意図的にデータドリフトを再現し、HNSWとIVFFLATの検索性能を比較しました。一般的に「IVFFLATはドリフト時に備え、定期的にインデックスを再構築する必要がある。HNSWは再構築する必要はない」と言われています。
ドリフトとは
ここでは、改めてベクトルDBにおけるドリフトについて説明します。(自動車のドリフトとは違います。)下の図を交えながら例え話をします。
- あなたは、ベクトルDB運用初期にベクトルインデックスを構築しました(左図)。
- ベクトルDB運用開始から時間が経過すると、新規データがDBへ登録され、データ分布も変化します。
- あるタイミングでベクトルDBにクエリを投げる必要が出てきました。この時のデータ分布は、初期のデータ分布とはかけ離れた分布になっています(右図)。
このベクトルインデックス構築時のデータ分布とクエリ時のデータ分布が異なる状況のことをドリフトと呼びます。 インデックス構築時と異なる分布のデータがクエリ時に推論されることで、インデックスが誤判定を起こしてしまい、検索性能が大きく下がる可能性があります。
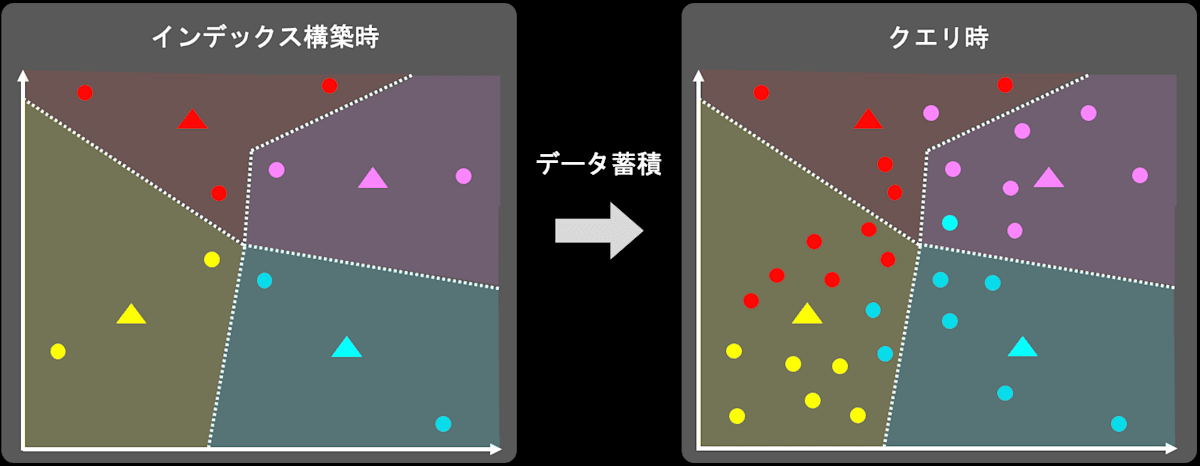
データドリフト発生のイメージ図(IVFFLATを例に出しています。)。
⚫︎がデータ(ベクトル)。▲がIVFFLAT内で作成したクラスタ。色が同じ点は同じラベルを示します。
実験方法
- EuroSATデータを、訓練データ(train.csvとvalidation.csv)と検証データ(test.csv)に分ける。
- 意図的にデータドリフトを発生させるため、無作為に選んだ図8の青枠に囲まれていないラベルの訓練データをDBに登録。
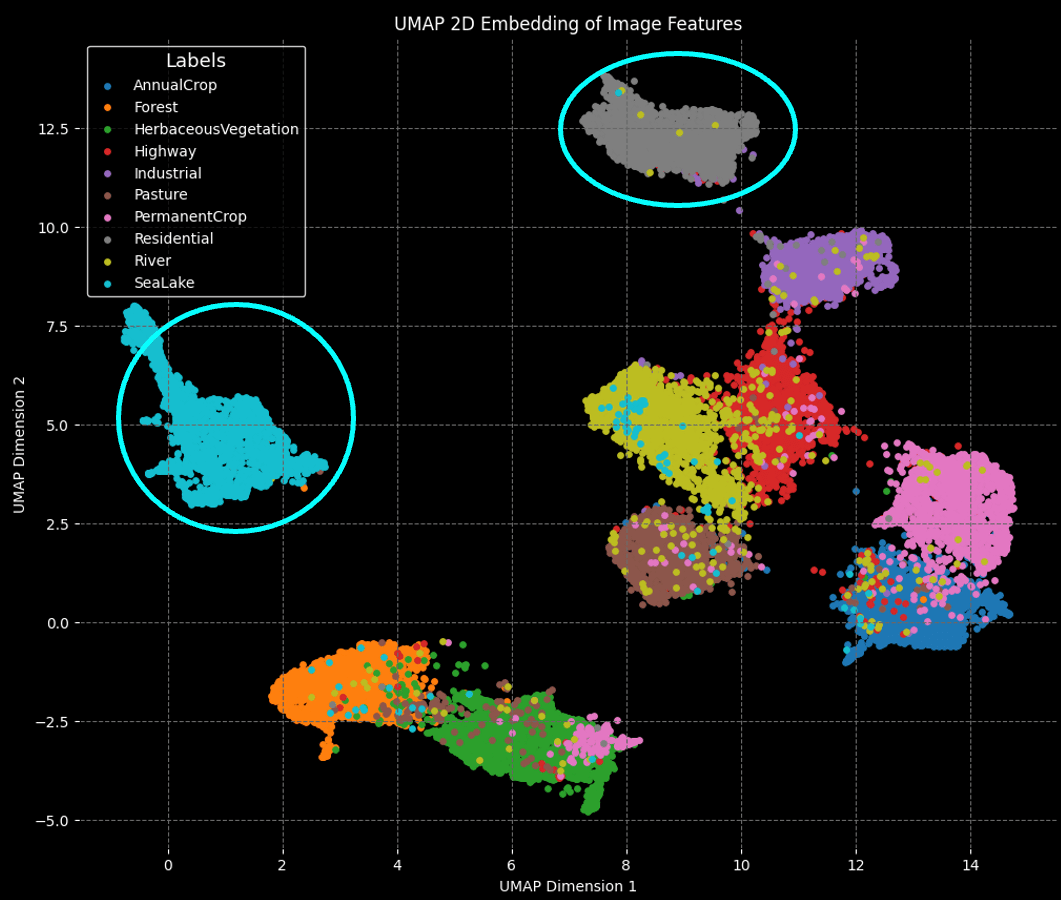
fig.8 無作為に選んだデータ(U-Mapで可視化)
- 以下のベクトルインデックスをDBにそれぞれ構築する。
- ベクトルインデックスが張られたDBに、図8の青枠で囲まれたラベルの訓練データを追加登録。(この時点でデータのドリフトを再現)
- 検証データを用いて、クエリに対する正解率を求め、HNSWとIVFFLATの検索性能を比較する。
結果
図9に結果を示します。HNSWとIVFFLATは共に、正解率が、Nが10のあたりをピークに、その後はNが増えるにつれて減少しています。これは、正解率を計算するための、多数決をとる母数が増加するにつれ、ノイズが多く含まれるからだと考えます。一方、IVFFLATのインデックス再構築前後で正解率の上昇が確認されたことから、IVFFLATインデックスの再構築の有効性は確認できたものの、HNSWの方がIVFFLATより検索性能が高いことがわかりました。
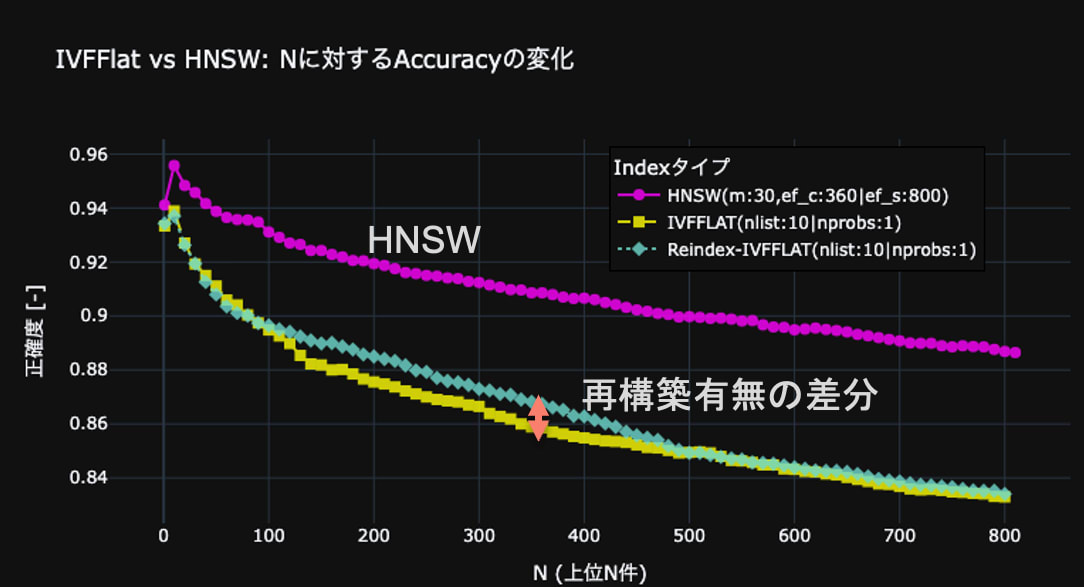
fig.9 HNSWとIVFFLATのデータドリフト時における検索性能の比較。
横軸はクエリに近いベクトル上位N件、縦軸は正解率。薄い緑の線は、クエリ直前にIVFFLATを再構築した場合を示す。
ここまで、図8のケースでドリフト耐性について話を進めてきましたが、他のケースでも検証を行いました。詳しくは補足説明他のケースによるドリフト耐性の検証をご確認ください。
ドリフト耐性の検証から得た知見
- ドリフト耐性は理論通り、HNSWの方が高い。
- 検索精度自体も、IVFFLATよりHNSWの方が高い。
検索精度と検索速度の検証
HNSWとIVFFLATに対して、クエリ時の検索精度と検索速度の比較を行いました。
検索精度の検証
HNSWとIVFFLATのハイパーパラメータが、検索精度に与える影響を明らかにします。一般的に、検索精度はHNSWが優れており、IVFFLATはパラメータチューニング次第で良いと言われています。一般論では定性的な説明に留まることが多いため、以下の実験手順で検証しました。
実験方法
- EuroSATデータを、訓練データ(train.csvとvalidation.csv)と検証データ(test.csv)に分ける。
- 意図的にデータドリフトを発生させるため、無作為に選んだ図8の青枠に囲まれていないラベルの訓練データをDBに登録。
fig.8 無作為に選んだデータ(U-Mapで可視化)
-
以下のベクトルインデックスをDBにそれぞれ構築する。
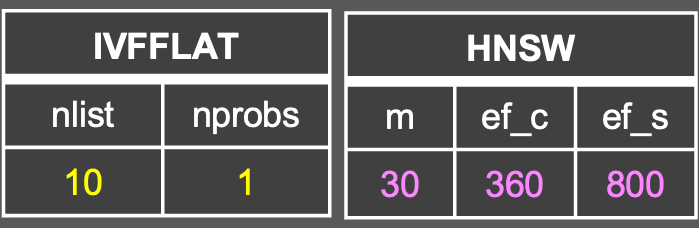
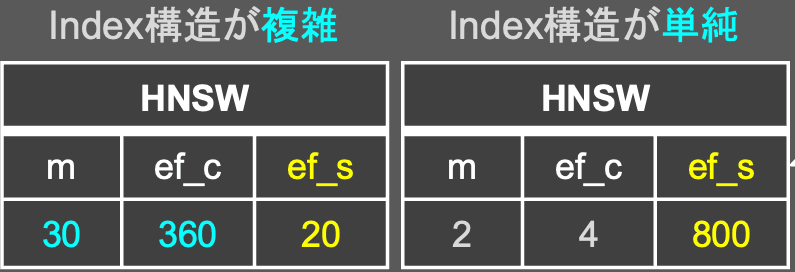
(なお、HNSWにおけるmとef_cの値が増加すれば、インデックス構造が複雑になり、mとef_cの値が小さければ、インデックス構造が単純になる。)IVFFLAT HNSW 
-
ベクトルインデックスが張られたDBに、図8の青枠で囲まれたラベルの訓練データを追加登録。
-
検証データを用いて、クエリに対する正解率を求め、HNSWとIVFFLATの検索性能を比較する。この時、以下の表に該当するパラメータを変化させた。
比較項目1 比較項目2 IVFFLATの nprobes
(探索時のクラスタ操作範囲を決定)HNSWの ef_s
(探索時に保持するノードの数を決定)
比較項目1(IVFFLAT)のパラメータチューニングの結果
図10はベンチマークとして、HNSW(m:30 | ef_c:360 | ef_s:800)を設定し、IVFFLAT(nlist:10)での検索時のハイパーパラメータnprobesを変更させた場合の、検索精度の変動を観測したグラフです。グラフから、nprobesが増加すると検索精度も上昇することが読み取れます。これはnprobesを増やすと、IVFFLAT内のクラスタ数の探索範囲が増え、全探索状態に近づくため精度が上がると考えます。また、図10では、HNSW(m:30 | ef_c:360 | ef_s:800)とIVFFLAT(nlist:10 | nprobes:5)、IVFFLAT(nlist:10 | nprobes:10)が一致しました。IVFFLAT(nlist:10 | nprobes:10)は全探索と同義なので、この結果は、検索精度の上限に達したことを示します。
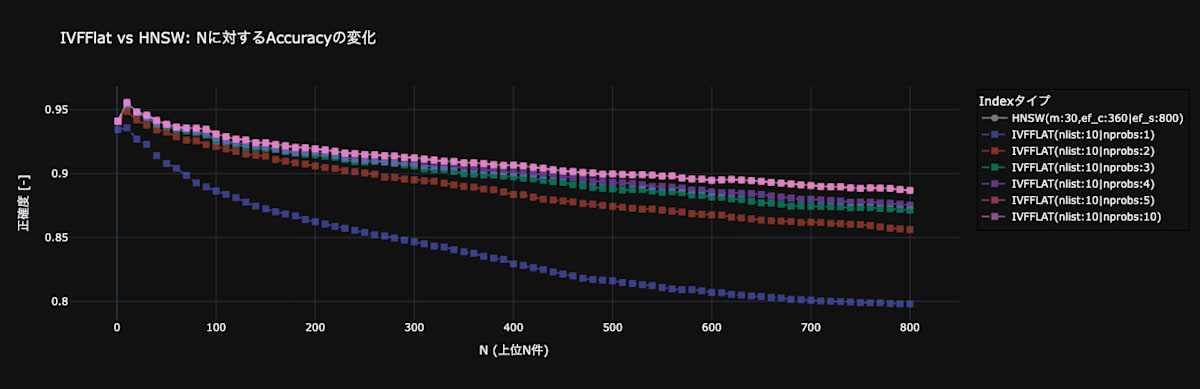
fig.10 IVFFLATのハイパーパラメータが検索精度に与える影響。
ベンチマークにHNSW(m:30 | ef_c:360 | ef_s:800)を設定。
この結果から、IVFFLATは一般的な見解と同じで、検索時のハイパーパラメータnprobesを上げれば、HNSWに並ぶほど検索精度が向上することがわかりました。
※IVFFLAT(nlist:10 | nprobes:5)でHNSW(m:30 | ef_c:360 | ef_s:800)と検索精度が並びました。
比較項目2(HNSW)のパラメータチューニングの結果
図11・図12はベンチマークとして、IVFFLAT(nlist:10 | nprobes:1)を設定し、HNSWの検索時のパラメータef_sを変更させた場合の、検索精度の変動を観測したグラフです。図11・図12に共通する点は、ef_sのパラメータを増加させると、検索精度が向上することです。これは、一般的な見解「検索時のパラメータef_sを上げると、検索精度が向上する」と一致しているため、妥当な結果だと言えます。一方、図11ではef_sが小さいと検索精度が劣化する傾向が見られ、図12では検索精度が劣化する現象は見られませんでした。この結果から、HNSWのインデックス構造を複雑(インデックス構築時のパラメータm、ef_cを上げる)にすると、ef_sによる検索精度劣化を防げると言えます。
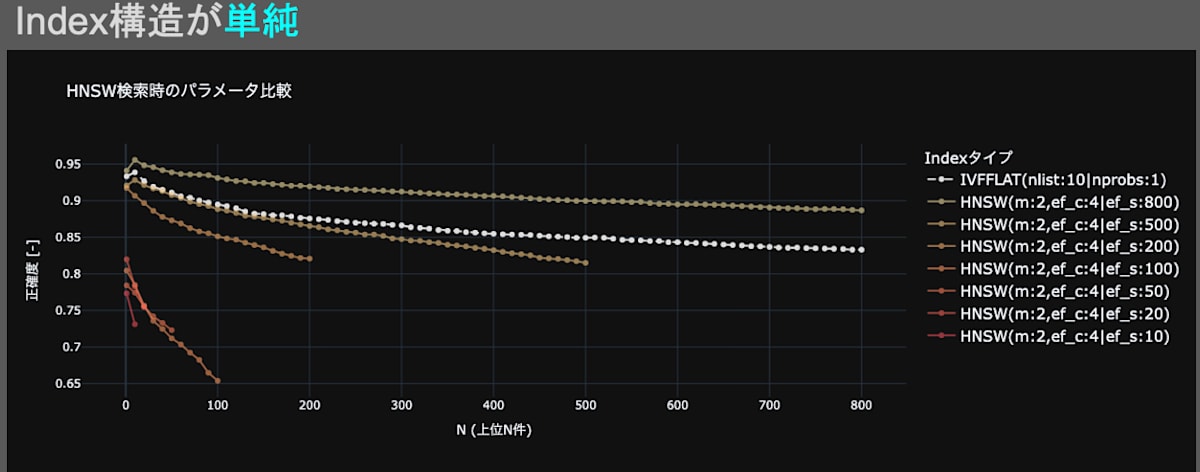
fig.11 HNSW(m:2 | ef_c:4)の検索時のハイパーパラメータが検索精度に与える影響。
ベンチマークにIVFFLAT(nlist:10 | nprobes:1)を設定。
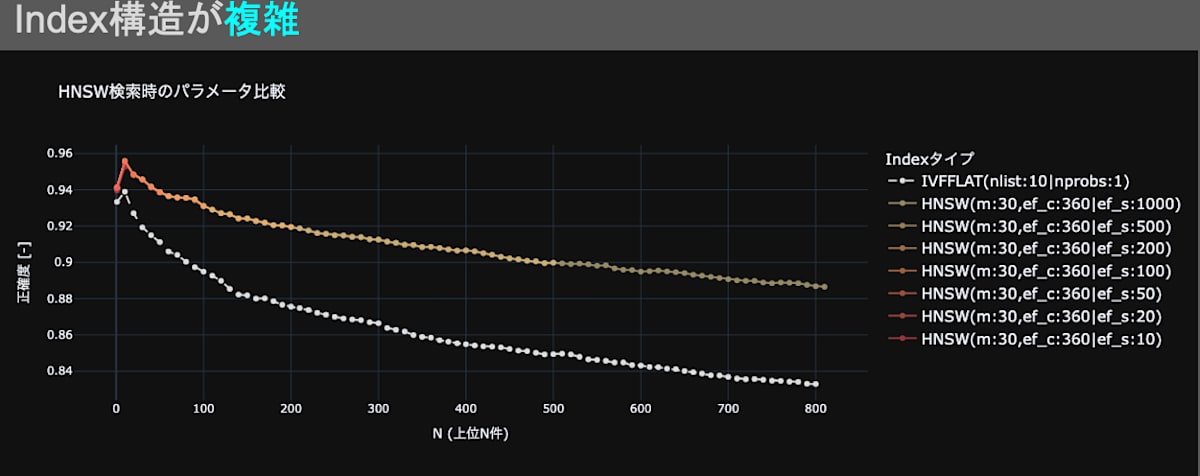
fig.12 HNSW(m:30 | ef_c:360)のハイパーパラメータが検索性能に与える影響。
ベンチマークにIVFFLAT(nlist:10 | nprobes:1)を設定。
IVFFLATとHNSWによる検索速度の検証
検索精度と速度はトレードオフの関係にあります。そこで、先ほどの実験で得られた結果を用いて、検索精度を同一に揃え、以下の実験手順でLocustを用いて検索時間の検証を行いました。
実験方法
- EuroSATデータを、訓練データ(train.csvとvalidation.csv)と検証データ(test.csv)に分ける。
- 意図的にデータドリフトを発生させるため、無作為に選んだ図8の青枠に囲まれていないラベルの訓練データをDBに登録。
fig.8 無作為に選んだデータ(U-Mapで可視化)
-
以下のベクトルインデックスをDBにそれぞれ構築。(これまでの実験から、検索精度が揃っていることは確認済みです。)
(なお、HNSWにおけるmとef_cの値が増加すれば、インデックス構造が複雑になり、mとef_cの値が小さければ、インデックス構造が単純になる。)
-
ベクトルインデックスが張られたDBに、図8の青枠で囲まれたラベルの訓練データを追加登録。
-
負荷実験ツールLocustを用いてDBへ大量のクエリを投げる。(1秒間に1人ずつユーザーが増加し、最大20人まで増えるシナリオを適用)
-
Locustにてクエリに対するレスポンス時間を測定。
-
CloudWatch Metricsにて、CPU使用率を計測。
※実験を行ったAurora Serverless PostgreSQLの最大・最小容量 = 1
結果
図13、図14、図15はLocustで得られたクエリ応答時間の結果です。グラフ及び表から、検索精度が同一の条件では、HNSWの方がIVFFLATより検索速度が速いことがわかりました。
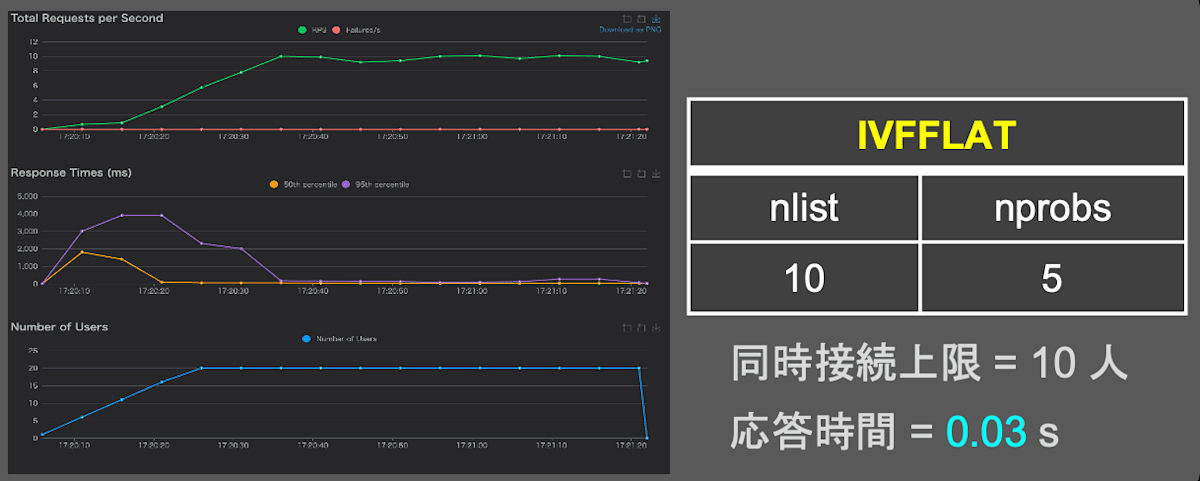
fig.13 IVFFLAT(nlist:10 | nprobes:5)のクエリ応答時間
グラフの横軸は負荷実験の経過時間。縦軸は上から順に、1秒間に受け付けたクエリ数、1つのクエリに応答するまでの時間、1秒間にクエリを送る人数を表す。
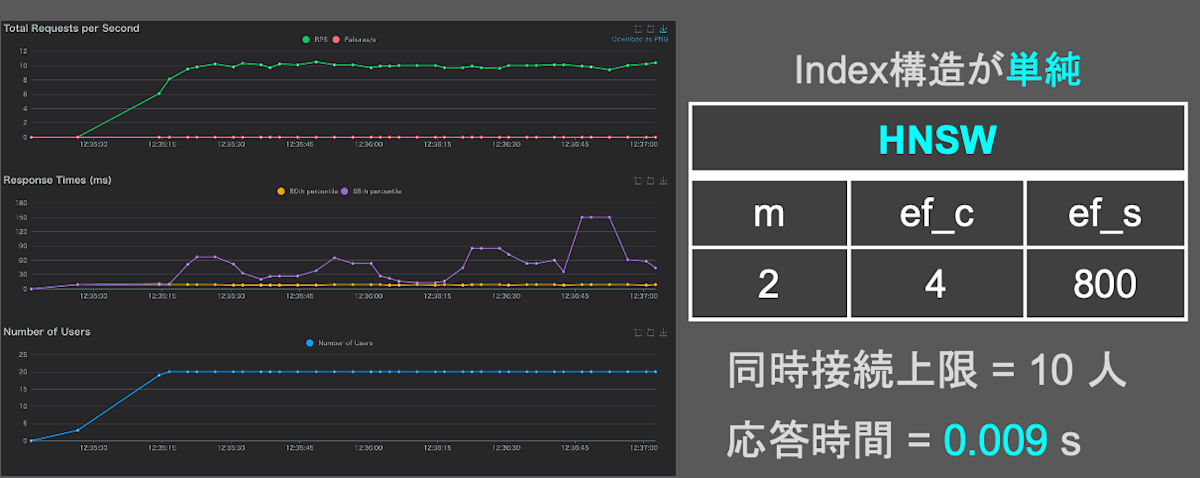
fig.14 HNSW(m:2 | ef_c:4 | ef_s:800)のクエリ応答時間
グラフの横軸は負荷実験の経過時間。縦軸は上から順に、1秒間に受け付けたクエリ数、1つのクエリに応答するまでの時間、1秒間にクエリを送る人数を表す。
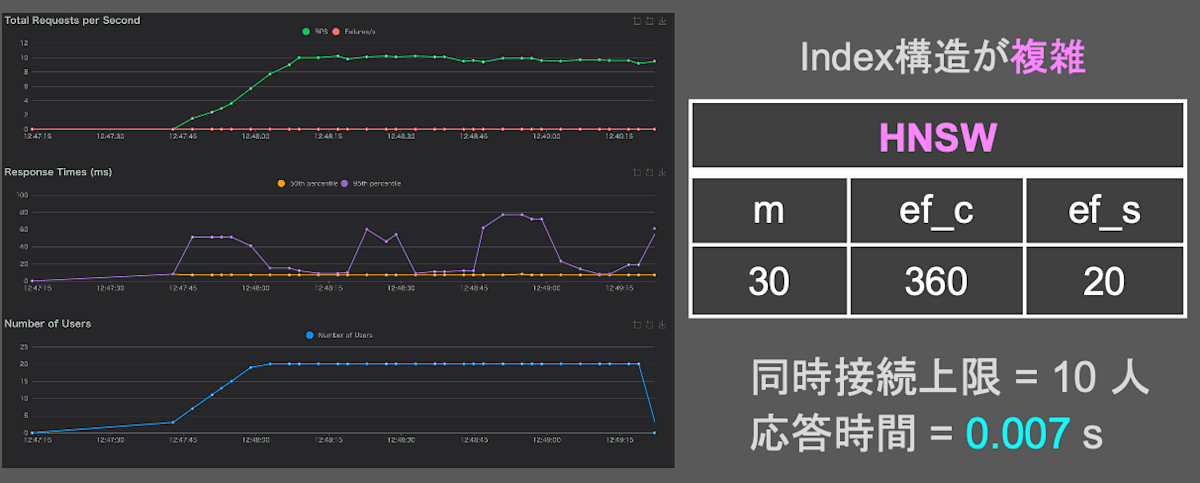
fig.15 HNSW(m:30 | ef_c:360 | ef_s:20)のクエリ応答時間
グラフの横軸は負荷実験の経過時間。縦軸は上から順に、1秒間に受け付けたクエリ数、1つのクエリに応答するまでの時間、1秒間にクエリを送る人数を表す。
さらに、図16は、クエリ時のCPU使用率を可視化したグラフです。IVFFLATがHNSWに比べCPU使用率が高いことがわかります。(この結果の考察はクエリ時のCPU使用率についてにて説明しています。)また、HNSWにおいては、インデックス構造が複雑(m:30、ef_c:360)の方が、インデックス構造が単純(m:2、ef_c:4)に比べてCPU使用率が抑えられることがわかりました。これは、インデックス構築をしっかり行っている方(インデックス構造が複雑)が、クエリ時にグラフを効率的に辿ることができ、計算量を抑えられるからと考察します。
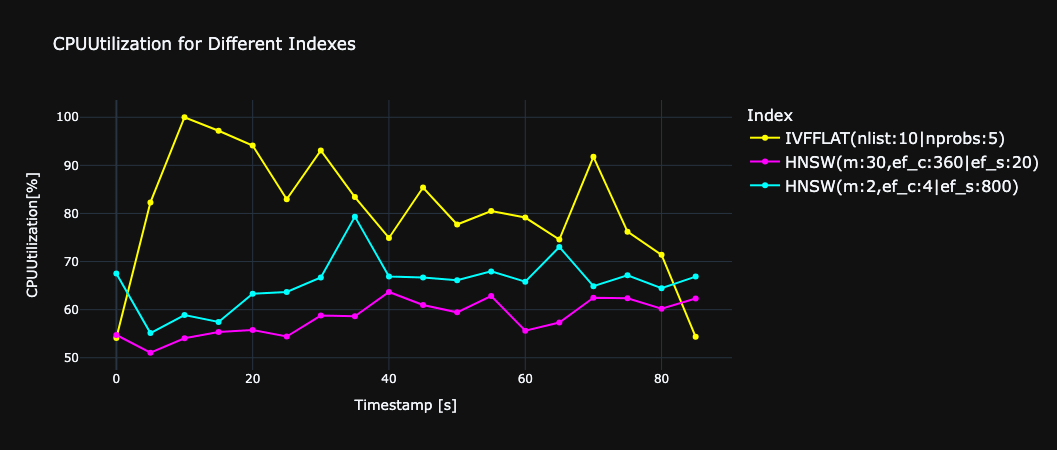
fig.16 クエリ時のcpu使用率
検索精度と検索速度の検証から得られた知見
- 検索精度は理論通り、HNSWの方がIVFFLATより高い。
- HNSWでは、インデックス構築時に計算コストをかける(インデックス構造を複雑にする)と、精度劣化を防止できる。
- 検索精度が同一の条件では、クエリ速度はHNSWの方が高速。
- HNSWでは、インデックス構築時に計算コストをかける(インデックス構造を複雑にする)と、検索時のCPU使用率を抑えられる。
補足事項
この章では、検証時の補足説明をします。
HNSWの理論値と実験値の比較
図6の結果を以下の表にまとめました。

HNSWのインデックス構築時に消費するメモリの量は、理論値が存在します。それは次の式で表されます。
| 変数名 | 説明 |
|---|---|
dimension |
ベクトル次元数 |
m |
1つのノードが持つエッジ数 |
num_vectors |
レコード総数 |
理論式に検証時に使用したHNSWのパラメータを代入すると、
表の実験値の消費メモリと比べると、いずれも「理論値 + 約123 MB = 実測値」の結果になりました。メモリ計測したCloudWatch Metrics FreeableMemoryには、インデックス以外の情報もメモリ使用量に含まれるため、この約123MBの一定な差分は、インデックス本体とは別に、PostgreSQLのプロセスやOSなどが消費する基本的なメモリ(オーバーヘッド)であると考えられます。この結果から、実験で計測した消費メモリは理論値に、システム固有のオーバーヘッド(約123MB)が加わった妥当な値であり、実験値の信頼性は高いと判断できます。
他のケースによるドリフト耐性の検証
- 実験方法
- EuroSATデータを、訓練データ(train.csvとvalidation.csv)と検証データ(test.csv)に分ける
- 意図的にデータドリフトを発生させるため、無作為に選んだ図17の黄色の枠に囲まれていないラベルの訓練データをDBに登録。
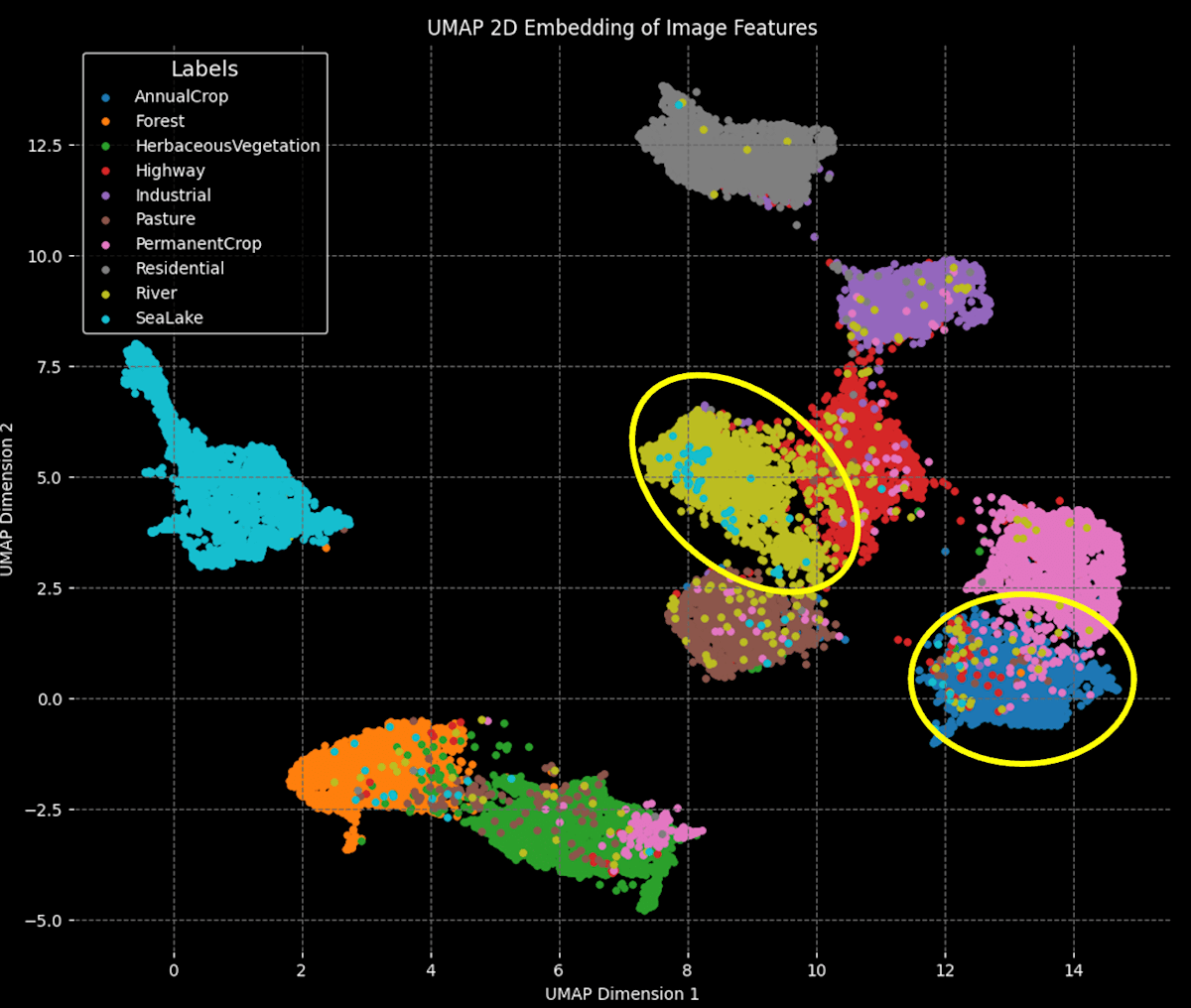
fig.17 無作為に選んだデータ(U-Mapで可視化)
- 結果
図18に結果を示します。HNSWとIVFFLATも共に、正解率が、Nが10の地点をピークに、その後はNが増えるにつれて減少しています。これは、正解率を計算するための、多数決をとる母数が増加するにつれ、ノイズが多く含まれるからだと考えます。一方、IVFFLATのインデックス再構築前後で正解率の上昇が確認されたことから、IVFFLATインデックスの再構築の有効性は確認できたものの、HNSWの方がIVFFLATより検索性能が高いことがわかりました。
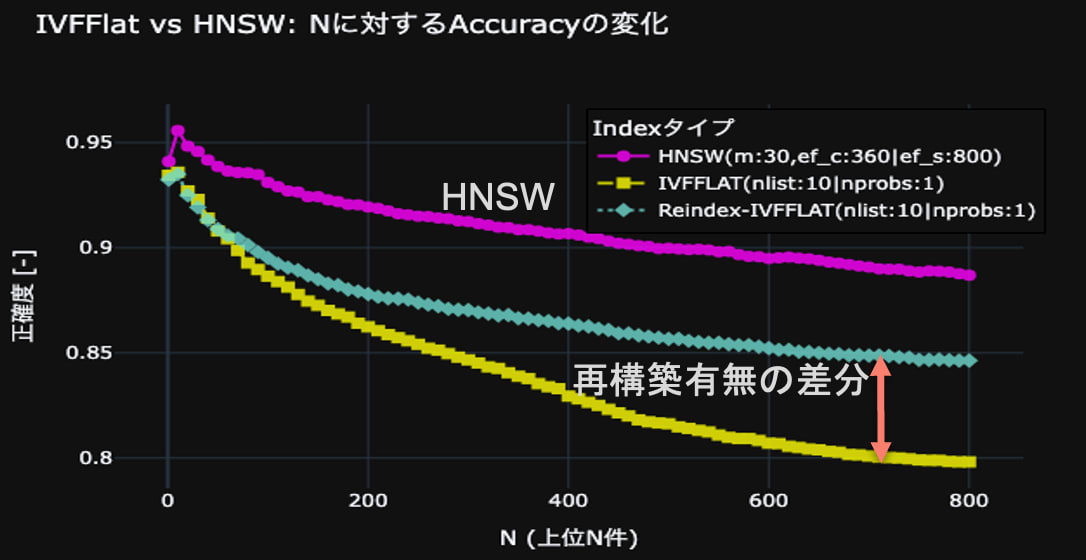
fig.18 HNSWとIVFFLATのデータドリフト時における検索性能の比較。
横軸はクエリに近いベクトル上位N件、縦軸は正解率。薄い緑の線は、クエリ直前にIVFFLATを再構築した場合を示す。
おわりに
本記事では、ベクトルDBにおける代表的なインデックスである IVFFLAT と HNSW について、実務でのベストプラクティスをAWS Aurora PostgreSQL環境下で探りました。
実験の結果、IVFFLATよりもHNSWの方が、検索精度とリソース効率(CPU使用率、検索時間)の観点から優れており、HNSWでは、検索時よりもインデックス構築時に計算コストをかける方が良いことがわかりました。
今回の検証結果が、ベクトルDBを導入・運用する際のインデックス選択とパラメータチューニングにおける、一つの指針として役立てば幸いです。
最後になりますが、このような実践的な検証の機会を与えてくださった株式会社エクサウィザーズのWANDチームの皆様に、この場を借りて感謝申し上げます。

Discussion