はじめに
株式会社エクサウィザーズWAND兼NLPギルドの大西です。
2025年9月17日から19日にかけて自然言語処理の若手研究者が集まるシンポジウム、YANS2025が開催されました。
弊社もゴールドスポンサーおよび発表者として参加いたしました。本記事では、特に興味を持ったポスター展示内容の紹介や当日のブースの様子について記載したいと思います。
YANSとは?
YANSは、自然言語処理に関する若手研究者のためのシンポジウムや懇親会を行っている取り組みです。
20年の歴史があり、昨年度からは言語処理学会の正式な若手支援事業のひとつとして開催されるようになりました。
どのような経緯で生まれたのかや、過去の歴史などについては今回のシンポジウムでちょうどポスターが作られていたので、そちらを参照ください。
ポスター展示内容紹介
今回のYANS2025では、2日に渡ってポスター発表が行われました。弊社はゴールドスポンサーとして参加していたため、スポンサー賞1件を選出する役割も担っていました。
スポンサー賞の選考にあたって、弊社が特に興味を持ったポスター展示内容をこちらで紹介させていただきます。
※発表者の方に許可をいただき、写真および内容紹介の掲載をしていますが、何か問題等あればご連絡ください。また、快諾いただいた発表者の皆様に感謝申し上げます。
スポンサー賞の様子

[S1-P43] 日本語における音声弁別ABX評価データセットの構築

こちらの発表をエクサウィザーズのスポンサー賞として選出いたしました。
発表内容としては音声品質評価のためのABX評価データセットの構築に関するものでした。
音声合成などの分野では、音声品質を評価するためにABX評価がよく用いられます。ABX評価とは、AとBの2つの音声が与えられたときに、XがAに近いかBに近いかを判定するタスクです。この評価は、音声品質を定量的に評価するために非常に有用ですが、日本語におけるデータセットは存在していません。この発表では、データセット構築のために弁別が難しい音声ペアをJVS(フリーの日本語多数話者音声コーパス)から選定、同時に日本語非母語話者が弁別困難なサブセットも作成し、まずは著者本人の耳で評価を行っていました。また、日本語・英語の既存の事前学習済み音声モデルでの弁別精度の調査も行っており、先の弁別困難なサブセットにおけるモデル傾向が人間と逆の傾向であったりと、興味深い結果も報告されていました。
今後の音声インターフェース標準の世界に向けて、音声品質評価の重要性はますます高まっていくと考えられます。そうした中で、日本語データセットの構築は非常に意義のある取り組みだと感じました。弊社でも音声合成や音声LLMの開発に強く力を入れており、今後の発展とデータセットの公開に期待し、スポンサー賞とさせていただきました。
[S1-P27] 特許のドメイン知識を活用した対話的特許情報検索

こちらの発表は、特許情報検索における対話的アプローチを提案したものでした。
特許文献は非常に専門的であり、曖昧なクエリ入力の場合、適切な情報を提供することが難しいという課題があります。この発表では、クエリ分類、追加対話生成、特許情報検索・回答生成といったステップを踏むことにより課題に取り組む内容が提案されました。
YANS時点では提案に留まりましたが、低コストの分類、知識グラフ活用による情報網羅性向上といった具体策は、特許以外にも、高度に構造化されたドメイン知識にも応用可能なフレームワークとして利用できるのではないかと期待しています。
[S2-P35] スタイル表現学習のための意味とスタイルの分離
※撮影状態の関係で一部不鮮明な箇所があります。ご了承ください。

こちらは、日本語テキストにおける「意味」と「スタイル」を分離して扱うための埋め込み表現を学習する手法を提案したものでした。
「意味」と「スタイル」を分離して扱うことで、スタイル変換やパーソナライズされた発話生成など、多くの応用が考えられますが、効果的に分離する手法はまだ十分に確立されていません。この発表では、意味埋め込み・スタイル埋め込み・文再構成の3つのマルチタスク学習を行い、「同じ意味の文同士の意味埋め込みは、スタイルが異なっていても近づける」「同一スタイルを持つ文同士のスタイル埋め込みは、意味が異なっていても近づける」という学習をすることで、効果的に分離する手法が提案されています。
特徴として、任意の言語モデルの埋め込み層に適用できる柔軟性や、方言や話者属性など多様な日本語スタイルの判別にも応用可能とのことだったので、LLMにおける発話スタイル制御への応用実現にも期待が高いと感じました。
[S3-P33] パラメトリックRAGによる未知知識の注入効果の検証
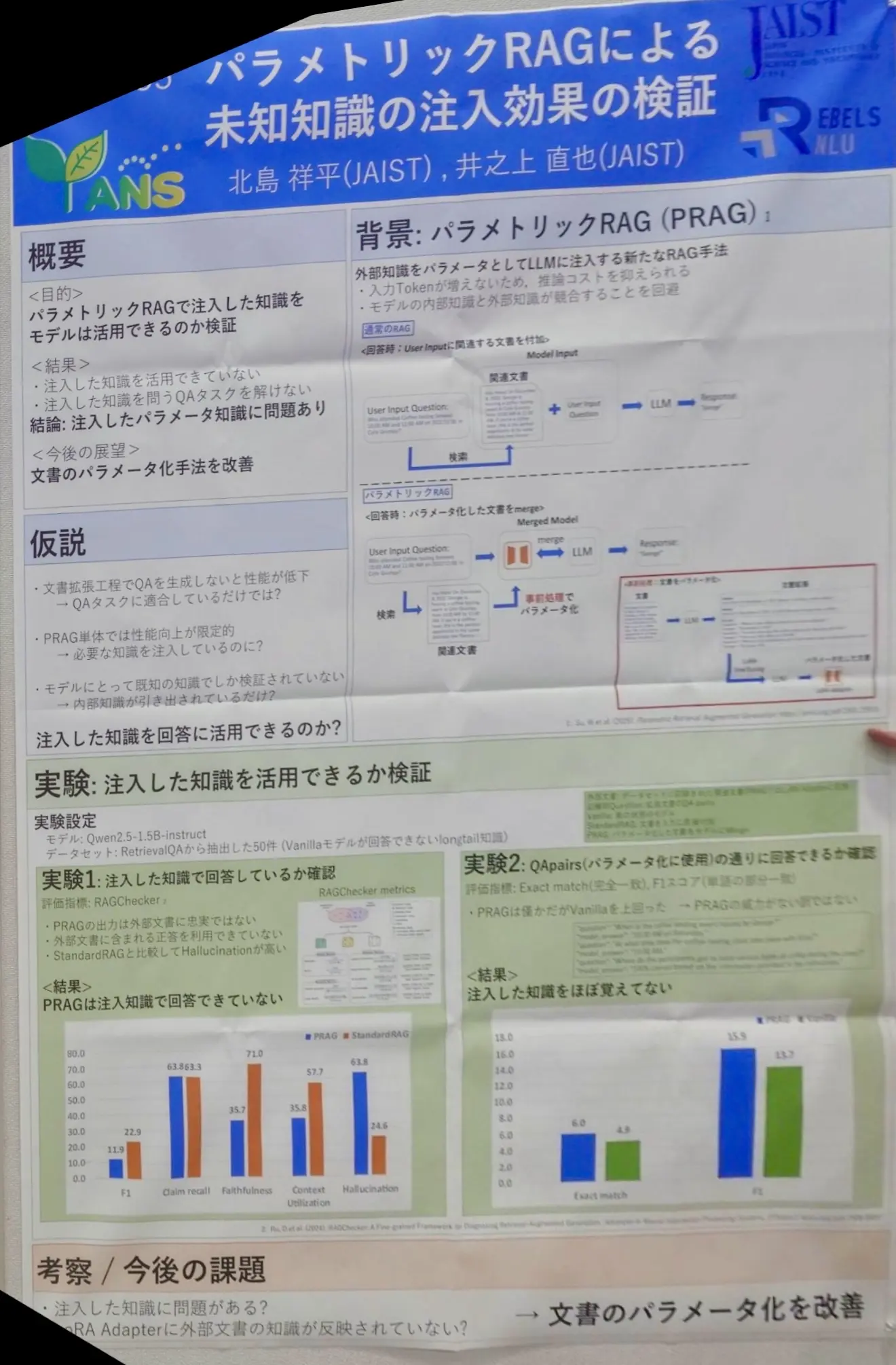
こちらは、RAG(Retrieval-Augmented Generation)の新手法の一つであるパラメトリックRAG(PRAG)の効果を検証したものでした。
PRAGは、検索対象文書をLoRAによってパラメータ化し、その重み(Adapter)を LLMに組み込むことで、プロンプトに関連テキストを添付せずとも知識検索を可能にするアプローチですが、PRAG単体での性能向上が限定的であり、既存の評価ではモデルにとって既知の知識でのみ評価されているという問題点があります。この発表では、モデルの知識では回答できないクエリが出題されるRetrievalQAタスクを用いてPRAGの効果を再検証したところ、注入した知識を利用した回答がほとんど生成されず、学習済み知識としても十分に取り込めていないという結果が報告されていました。
今回の実験設定ではPRAGはあまり良くない結果でしたが、エポック数やハイパーパラメータ調整、データ規模の拡大など、実施条件を再設計してPRAGの潜在能力の最大化を試みるとのことだったので、RAGの精度改善に取り組んでいる弊社としても、今後の検証結果に注目していきたいと感じました。
弊社ポスター発表内容紹介
[S4-P15] 推論過程のファインチューニングによる職能ペルソナLLMの構築と評価
弊社からも1件ポスター発表を行いましたので、最後に、弊社の内容についても紹介させていただきます。
※写真撮り忘れたので原稿スクショです

本発表は、エンジニアやセールスといった職能ペルソナの一貫性と専門タスク適合性の両方で高い性能を示すモデルを構築することを目的とした研究です。
マルチエージェント化が進む中で、ペルソナを持ったLLMの重要性が高まっていますが、プロンプトベースでは職能ごとの推論過程を十分に反映できないという課題がありました。この課題に対して、ペルソナに基づく推論過程を反映した合成データを作成し、ファインチューニングを行うことで、一貫したペルソナを持つモデルを構築することを提案しています。LLM-as-a-judgeによって合成データが4つの判断基準を満たしているかどうかを評価し、品質基準を満たしたデータを生成しています。
本手法のモデルは、プロンプトベースに比べ、多くの場合でペルソナを明確に反映し、専門性が求められるタスクでも高い性能を示すことが明らかになりました。しかし、その優位性は役割・質問タイプに大きく依存することが分かったため、今後はさらなるデータ拡充や評価の充実をしていく予定です。
ブースの様子

弊社のブースでは写真のように、プロダクト紹介やポスター展示を行っていました。デモ環境も用意しており、実際に動作している様子をお見せすることができました。弊社のポスター発表内容のサンプル出力などは特に興味を持っていただけたようです。
50人を超える多くの学生の方が訪れてくださり、また企業の方にもお越しいただき自然言語処理に関する技術や弊社の取り組み、プロダクト等に興味を持っていただけました。
また、YANSの取り組みとして、企業ブースツアーなどの施策があったり、ブースの場所としてもポスター発表が行われているすぐ横だったりと、自然と参加者と交流ができる仕組みになっており、非常に良い機会でした。
今回初めてノベルティとして、弊社ロゴが印字されたミントタブレット(机上右手前)を配布しましたが、こちらも好評でした。ミントタブレットはNLP2026のブースでも配布予定なので、ご予定ある方はぜひお立ち寄りください!
余談
静岡県浜松市での開催ということで、さわやかのハンバーグを食べたり、うなぎを食べたりと、グルメも楽しむことができました。
美味しいですね、浜松。

まとめ
YANS2025にスポンサーとして参加した報告をさせていただきました。若手の方々の熱意を感じることができ、弊社としても非常に有意義な時間となりました。今後も引き続きこういった場に参加していきたいと考えています。
NLP2026の宇都宮でもお会いできることを楽しみにしています!
弊社では、自然言語処理やAIに関する研究開発を積極的に行っており、一緒に働く仲間を募集しています。興味のある方はぜひ採用ページをご覧ください!

Discussion