先端技術開発グループ(WAND)の小島です。福原と佐藤と私は、主に機械学習エンジニアが使うためのサンドボックス用のAWS環境(デモ環境)の保守運用を行っています。有志の協力もあり、かれこれ2年近く運用しているのですが、今回は「一見なんのことだかわからないOpenSearchの謎料金」が請求書にあり、この正体を解明するのにハマったため記事にしていきたいと思います。
OpenSearchのクラスタがないのに課金が発生してる!?

AWSの請求書を見ていると前から気になっていたOpenSearchの課金がありました。しかも月額約240ドルと決して安くない金額です。
(※本請求画面はデモ環境のもので、プロダクトや案件等の本番のデータやリソースは入っていません)
しかし、OpenSearchのダッシュボードを見ても全く出てきません。「この課金はどこからきているの?」ということで、このお化けのような課金の正体を探りに行きます。
OpenSearch Serverlessのコレクションが原因
サポートに問い合わせたところ、「OpenSearch Serverlessのコレクションが原因で課金が発生していますよ」とのことでした。

実際に確認してみると、「Bedrockナレッジベース」からきているものでした。これはナレッジベース(RAG)の裏側で使われているベクトルデータベースのようです。そこそこ個数がありますね。
参考:Amazon Bedrock ナレッジベースでデータソースに接続してナレッジベースを作成する
「どのぐらい使われているのか?」ということで各コレクションを見てみると、実はどれもインデックスが登録されていませんでした。
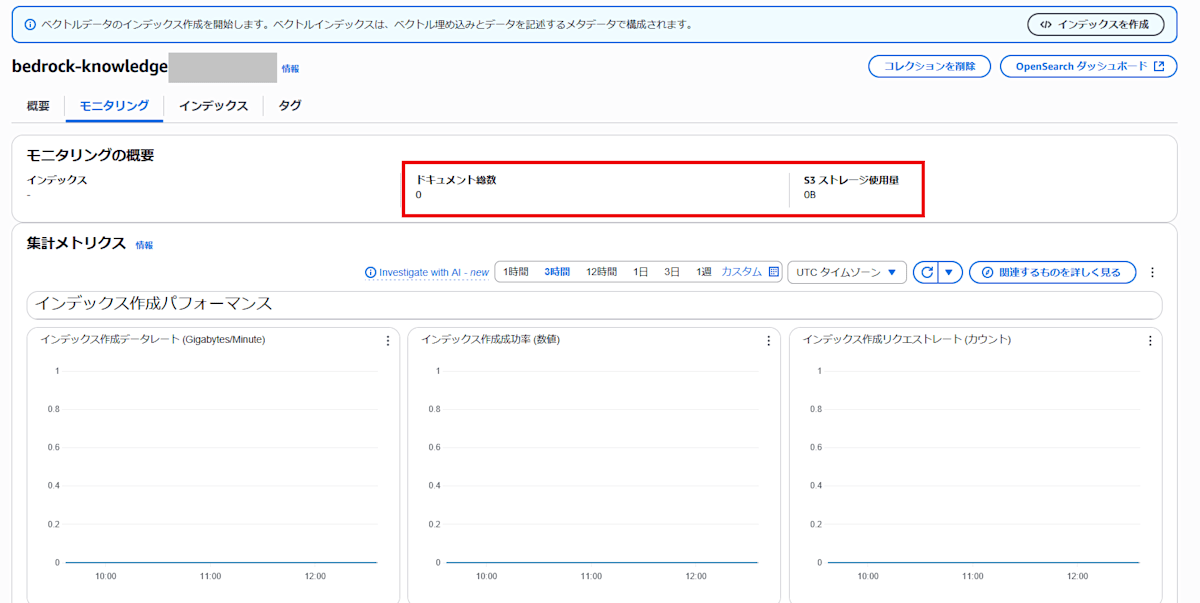
この状態で本当に課金されるのでしょうか? コレクション数は7個と、かなり数がありますが、個数分課金されているのでしょうか?
Amazon OpenSearch Serverlessの料金体系
AWSの公式ページによると、OpenSearch Serverlessの料金は以下のように書かれています。
OpenSearch Serverlessの料金説明
Amazon OpenSearch Serverless では、ワークロードによって消費されたリソースに対してのみ支払いが発生します。OpenSearch サーバーレスは、コンピューティングとストレージが別々に課金されます。計算能力は OpenSearch Compute Units (OCU) で測定されます。OCU の数は、データのインデックス作成やクエリーの実行に必要な CPU、メモリ、Amazon EBS ストレージ、I/O リソースに直接対応しています。1つの OCU は、6GB の RAM、対応する vCPU、GP3 ストレージ (アクセス頻度の高いデータへの高速アクセスに使用)、Amazon Simple Storage Service (S3) へのデータ転送で構成されています。
OCU-hours のコンピューティングの項目が1つあり、データのインデックス作成用と検索用の2つのラベルが表示されています。OCU は、秒単位のコレクションで時間単位で課金されます。Amazon S3 に保存されたデータについては、GB-月単位で課金されます。 アカウントの最初のコレクションでは、少なくとも 2 OCU (1 OCU [0.5 x 2] のインデックス作成にはプライマリとスタンバイが含まれ、1 OCU [0.5 x 2] の検索には HA のレプリカが 1 つ含まれます) について課金されます。ただし、最小値は、使用しているデータサイズとコレクションのタイプによって異なります。
さらに、OpenSearch Serverless は、冗長スタンバイノードなしでコレクションを起動できる開発テストオプションも提供します。このデプロイモードでは、インデックス作成で 0.5 OCU、検索で 0.5 OCU となるため、さらにコストを半減できます。どちらのモードでもすべてのデータは Amazon S3 に保存され、完全なデータ耐久性が提供されます。ただし、最小値は、使用しているデータサイズとコレクションのタイプによって異なります。
同じ暗号化キーを使用する後続のコレクションは、それらの OCU を共有できます。お客様のコレクションをサポートするために必要なコンピューティングインスタンスとデータに基づいて、追加の OCU が追加されます。アカウントごとに OCU の最大数を設定し、コストをコントロールすることができます。
ベクトル検索コレクションが検索コレクションまたは時系列コレクションと同じ KMS キーを使用している場合でも、ベクトル検索コレクションは検索コレクションや時系列コレクションと OCU を共有できません。初めてのベクトル検索コレクション用に新しい OCU セットが作成されます。ベクトル検索コレクションの OCU は、同じ KMS キーベクトルコレクション間で共有されます。
参考:Amazon OpenSearch Serverless
長くてわかりづらいのでAIに要約させましょう。Claude Sonnet 4による要約です。
- ワークロード消費分のみ課金(コンピューティング+ストレージ別々)
- 計算能力はOCU(OpenSearch Compute Units)で測定
- 1 OCU = 6GB RAM + vCPU + GP3ストレージ + S3データ転送
- OCUは秒単位・時間課金、S3データはGB-月課金
-
最小構成
- 通常:最低2 OCU(インデックス1 OCU + 検索1 OCU、各HA構成)
- 開発テスト:1 OCU(インデックス0.5 + 検索0.5、冗長性なし)
-
OCU共有
- 同じ暗号化キーのコレクション間でOCU共有可能
- ベクトル検索は他タイプとOCU共有不可(専用OCU必要)
- アカウント単位でOCU上限設定によるコスト制御可能
暗号化キーの共有
ポイントは「暗号化キー(KMS)を共有していれば、OCUを共有可能」という点だと思います。データベースを暗号化するときに「どのKMSを使うか」を指定します。

特に指定なく作ればAWSマネージドのKMS(AWS所有のキー)になるので、KMSの共有により、「開発テスト」の最小構成では7個分のコレクションは、1 OCU(インデックス0.5OCU + 検索0.5OCU)の課金となるということになります。ただ、その一方で、1個でもコレクションがあれば最小の「1 OCU」分がフルで課金されるということもわかります。

実際の請求書を見ると、8月はインデックス・検索がそれぞれ「372 OCU-Hour」消費されています。これを時間あたりで計算すると、「372(OCU-時) ÷ 31(日) ÷ 24(時) = 0.5 OCU」とぴったり計算が合いました。これで謎課金の正体を突き止めることができました。
追加課金の発生する状況
また、DBの使用量が増加し、0.5 OCUよりスケールアウトした場合は追加で課金が発生します。スケールアウトは「キャパシティ制限」で管理可能です。詳細は下記のドキュメントが詳しいです。
参考:Amazon OpenSearch Serverless でのキャパシティ制限の管理
また、今回はBedrockナレッジベースだったので関係ないかもしれませんが、ベクトル検索以外のコレクションが入ってきた場合も別枠で課金が発生します。
S3 Vectorsに期待
「KMSが同一の場合にOCUが共有される」という仕様は嬉しいですが、逆に少量の使用では「1個コレクションが存在しただけで月額約240ドルの課金が発生」してしまいます。これをどう見るかというのはいろんな意見があるかと思いますが、個人的には「高いな~」という印象です。
ただ、最近AWSの格安のベクトルDBサービスとして「S3 Vectors」がリリースされたため、これでOpenSearchが代替できるようになれば、少量の使用でもかなりリーズナブルに使えるのではないかと期待しています。2025年9月現在、S3 Vectors自体が東京リージョンにはまだきていませんが、Bedrockナレッジベースとの統合は既に用意されているようです。
参考:Using S3 Vectors with Amazon Bedrock Knowledge Bases
これが東京リージョンに来て、ベクトルDBのデファクトスタンダードとして標準化されれば、かなり使いやすくなるのではないかと思います。
謎課金になってしまった原因
OpenSearchのドキュメントを読むとよく書いてあるのですが、この課金の正体がわかりづらいのは、以下の複合的な要因があったからと考えられます。
- AWSマネジメントコンソールの「OpenSearch」のトップ画面にコレクションが表示されない。「サーバーレス」の画面に遷移して初めてわかる
- Bedrockナレッジベースが原因であるということは突き止められても、Bedrockの料金にはOCUの説明がない(2025年9月時点)。この料金説明はナレッジベースのデータ取り込みやクエリに関するもので、これだけ読むと安いように錯覚してしまう
- Bedrockの裏側で使用しているOpenSearchの課金体系は、OpenSearchの料金ページで別に紹介されている
- OpenSearchの料金説明を読み解くには読解力がいる
最近「RAGを簡単に作れるサービス」が増えていますが、この裏側でOpenSearchなどのデータベースを使っていて、使っている側が気づいていないことが多いので料金は注意が必要だなと思いました。
最後に、テクニカルサポートで丁寧に回答してくださった、AWSの担当者の方、ありがとうございました。
リソースを作った方々に聞いてみた
なお、このリソースを作成した担当者の方々に聞いてみました。元コメントをAI(Claude Sonnet 4)で要約してお伝えします(※掲載許可済みです)。
検証でKnowledgeBase経由でOpenSearch Serverlessのデータソースを作成し、高コストを懸念してKnowledgeBaseは削除しましたが、OpenSearch Serverlessのデータソースは連動削除されず、不要な課金が発生してしまいました。OpenSearchの削除確認を怠った点を反省しています。
本記事のミニマム課金額について、使わなくてもリソース維持だけで数万円かかることは調査で理解していましたが、詳細は把握していませんでした。Serverlessサービスでも従量課金とは限らないため、利用前に支払いの仕組みをしっかり理解することの大切さを身に染みて学びました。
AWSのMCPワークショップの復習作業中でした。
ワークショップではOpenSearchを使用していましたが、コストを考慮してS3 Vectorsを試そうと思いました。
しかし、S3作成後にナレッジベース構築時、S3 Vectorsが日本リージョンで利用できないことを思い出し、まずは追試としてOpenSearchで試すことにしました。
今後、手軽にRAGを試したい方が同じ問題に遭遇する可能性があるため、注意が必要ですね。
失礼いたしました。
AWSに比較的詳しい方でもこのようにハマりがちなポイントであったため、特にOpenSearchに関してはリソースの自動削除を検討していく必要がありそうだなと思いました。

Discussion