S3 Vectors実践入門:サーバーレス類似検索で最小RAGを作る
はじめまして!株式会社エクサウィザーズの高橋です。
この記事では2025年7月にリリースされた、S3 Vectorsについて、概要とそれを用いた簡単なRAGの構築について解説します。
本記事の内容(リージョン、料金、API仕様、ベストプラクティス等)は執筆時点(2025年10月)の情報をもとにしています。最新の提供状況や価格は公式ドキュメントをご確認ください。
1. S3 Vectorsとは?
- S3 上にベクトルをそのまま保存して “意味で近い” を探せる、サーバーレスな類似検索基盤。
- テキスト/画像/音声などから作ったベクトルを S3にネイティブに保存し、サブ秒の類似検索を API だけで実行できる。原本は通常の S3 バケットに置き、ベクトル+メタデータはベクターバケットに保管するため、サーバーレスで低コストに拡張できる。
- ベクトルはベクターバケット配下のベクターインデックスに格納し、専用API (PutVectors / QueryVectors / GetVectors 等) で操作する。(公式発表 / ユーザーガイド / QueryVectors API)。
2. 他サービスとの使い分け (OpenSearch / Aurora pgvector)
検索頻度が高く、低レイテンシが必要なデータ(ホット)は OpenSearch に、検索頻度が低く長期保管したい大容量のデータ(コールド)は S3 Vectors に置く。用途で置き場所を分けることで、速度(OpenSearch)とコスト(S3 Vectors)のバランスが取りやすい。
2.1 役割の違い
| サービス | 役割・強み | レイテンシ目安 | 向いている場面 |
|---|---|---|---|
| OpenSearch(Managed / Serverless) | 検索専業。HNSW/IVFなどのエンジン選択やハイブリッド検索。 | 〜10ms台(ワークロード依存) | 高QPS・低遅延のホット層 |
| Aurora PostgreSQL(pgvector) | RDBとベクトルを同居。ACID/SQLと並べて使える。 | 数十ms〜(設計依存) | トランザクション性、小〜中規模の一体運用 |
| S3 Vectors | 保存重視・超大規模をS3で抱えつつサーバーレス検索。 | サブ秒(msよりは遅め) | 低頻度検索、アーカイブ寄り、費用最適化 |
2.2 選定フローチャート
3. 機能(ざっくり)とリージョン/コストの前提
3.1 メタデータとフィルタの基本演算
- メタデータ型:
string / number / boolean / list(ネストJSONは不可) - 演算:
$eq, $ne, $gt, $gte, $lt, $lte, $in, $nin, $exists, $and, $or(AND/OR) - 制約:1ベクトルあたり合計40KB(うちfilterableは2KB、キー総数は10など)
3.2 ベクトルとインデックス
- 類似度:Cosine / Euclidean
- 次元:1〜4096
- ベクトルサイズの目安:次元 × 4B(例:1024次元 ≒ 4KB)
- 実装Tips:最大500ベクトル/リクエスト(1回のPut API呼び出しに含められるベクトル件数=バッチサイズ)でバルクPut、Put/Deleteは少なくとも5RPS(Requests Per Second)/インデックス推奨
3.3 大きめのデータ・画像データの扱い
- 原本(画像・音声・PDF などの大きなバイナリ)は 通常の S3(汎用バケット) に置き、S3 Vectors には 「埋め込みベクトル+メタデータ」 だけを格納するのが基本。( Limitations and restrictions, S3 Vectors best practices)
3.4 連携と移行
- S3 Vectors → OpenSearchの構成が可能(段階的移行やハイブリッド検索に向く)
3.5 リージョン(2025/08/22時点、プレビュー)
- 提供:us-east-1 / us-east-2 / us-west-2 / eu-central-1 / ap-southeast-2(Sydney)
- 未対応:ap-northeast-1(東京)
- ネットワーク注意:Gateway VPC Endpoint / PrivateLinkは非対応 (公式ドキュメント)
同一リージョン内のS3→多くのAWSサービス間は転送無料。クロスリージョンやインターネット向けはS3の転送料金が発生
3.6 コスト
- コストの詳細:S3 Pricingの英語版のVectorsタブ(日本語版には記載なし)
- 公式の計算例(US-EAST-1):
- 例1:1,000万ベクトル(6.17KB/件)、40インデックス、月100万クエリ → 保存 $3.54、PUT $1.97、クエリ $5.87=合計 $11.38/月(API $2.50 + データ処理 $3.37)。
- 月100万クエリのイメージ
- チャット型RAG(社内):3,300セッション/日 × 10クエリ/セッション × 30日 ≒ 100万クエリ/月
- サポート現場:100名 × 100クエリ/日 × 20営業日 ≒ 20万クエリ/月 (5拠点で運用すると100万クエリ/月)
- 社内検索ポータル:5,000ユーザー/日 × 7クエリ × 30日 ≒ 105万/月
- 月100万クエリのイメージ
- 例2:4億ベクトル、月1,000万クエリ → 保存 $141.22/PUT $78.46/クエリ $997.62=合計 $1,217.29/月。
- 例1:1,000万ベクトル(6.17KB/件)、40インデックス、月100万クエリ → 保存 $3.54、PUT $1.97、クエリ $5.87=合計 $11.38/月(API $2.50 + データ処理 $3.37)。
4. S3 VectorsでRAGプロトタイプを作ってみる
最小構成の RAG を一気通貫で動かす手順とベンチで見るポイントをまとめる。
4.0 概要(何を作るか・どう流れるか)
目的
- ベクトル化したコンテキストを S3 Vectors に保存し、クエリを埋め込み → QueryVectors で topK を取得 → LLM で回答を作る最小パイプラインを用意する。
使うもの
- S3 Vectors(vector bucket / vector index)
- s3vectors-embed-cli(PyPIパッケージ名。インストール後の実行コマンドは s3vectors-embed)
- API Gateway + Lambda(Python/boto3、QueryVectors を呼び出す最小 API)
- Bedrock Embedding(クエリの埋め込み)、Bedrock LLM(回答)
- データ整形スクリプト(JSONL: question / 正解(gold_answer) / context)
流れ(インジェスト)
- JSONL に整形したコンテキストを s3vectors-embed-cli で埋め込み生成 → S3 Vectors へ put
- メタデータに doc/id/source を付ける。スニペットは S3VECTORS-EMBED-SRC-CONTENT に入る
流れ(検索〜回答)
- API にクエリを投げる → Lambda がクエリを埋め込み → QueryVectors で topK
- 返ってきたメタデータのスニペットを LLM に渡して回答を作る
- 目視用に Markdown を出す(質問・正解・回答・参照コンテキスト)
注意点
- インデックスの次元は埋め込みモデルに合わせる(例: Titan v1 は 1536)
- index 作成時に S3VECTORS-EMBED-SRC-CONTENT を non-filterable に入れておくとスニペット確認が楽
- Lambda の s3vectors クライアントは index のリージョンに合わせる
4.1 AWS リソース構築
Vectorsが提供されているリージョンのうち、今回はus-east-1を選択した。
-
Vector bucket と Vector index を作る
- S3 → 左ペイン「Vector buckets」→ Create。
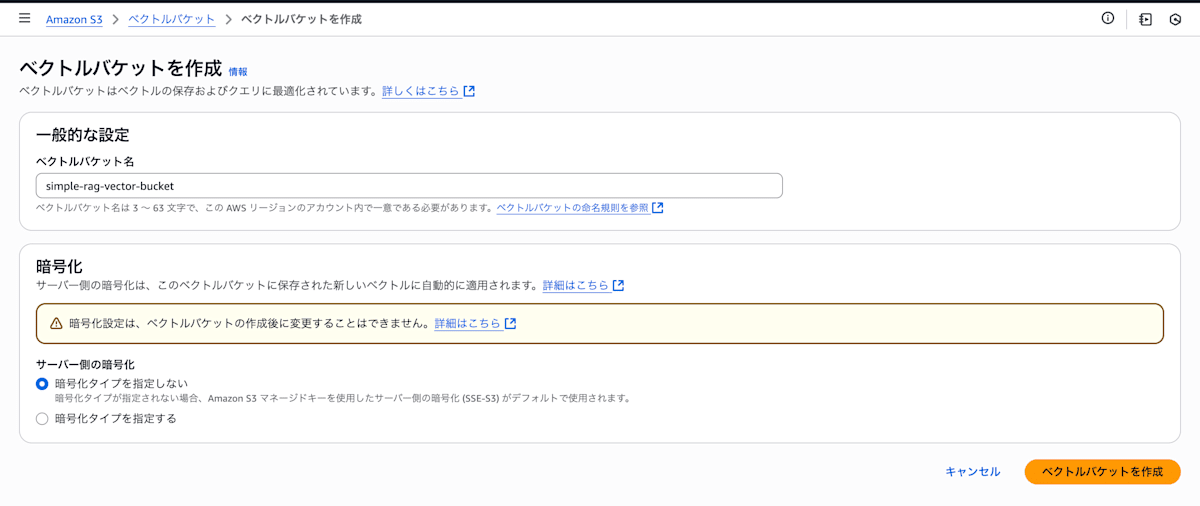
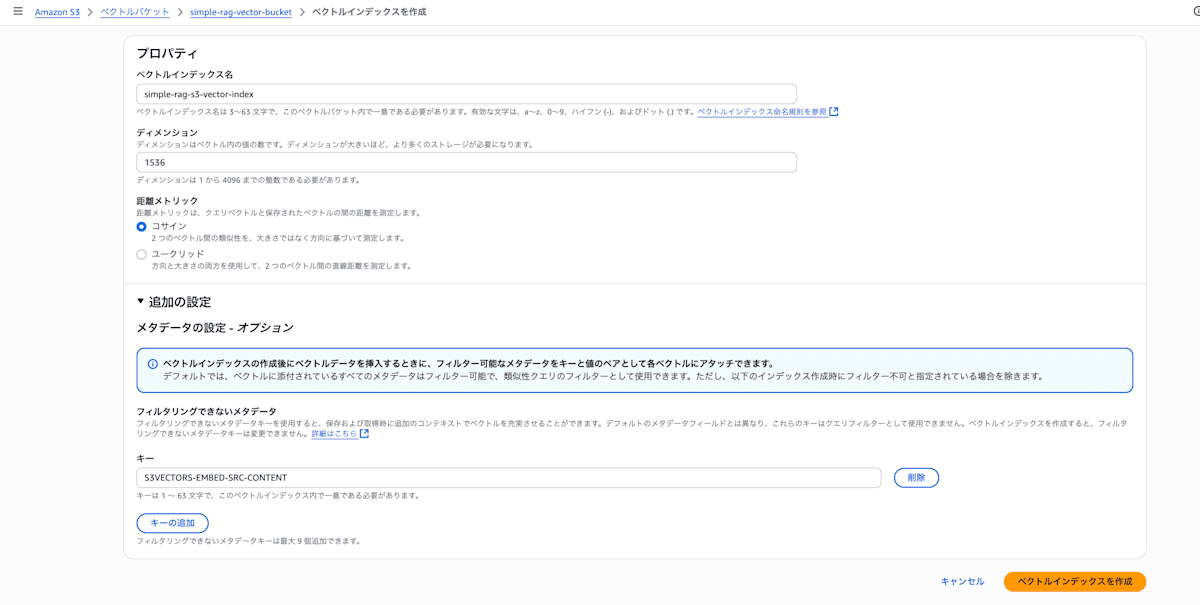
- 当該バケット内で「Create vector index」。
- distance は Cosine、dimension は使う埋め込みモデルに合わせる(今回はTitan Text Embeddings v1を使用するので1536)。
- 非フィルタ用メタデータに
S3VECTORS-EMBED-SRC-CONTENTを追加しておく(後でスニペット確認がしやすい)。
- S3 → 左ペイン「Vector buckets」→ Create。
-
Bedrock の Model access を有効化
- Bedrock → Model access → 対象モデルを Enable。
- 疎通確認(200が返ればok)
% aws bedrock-runtime invoke-model \ --region <your-bedrock-region> \ --model-id <your-embedding-model-id> \ --body '{"inputText":"hello"}' \ --cli-binary-format raw-in-base64-out \ --content-type application/json \ --accept application/json | jq . -
Lambda 実行ロールを作る
- IAM → Roles → Create role
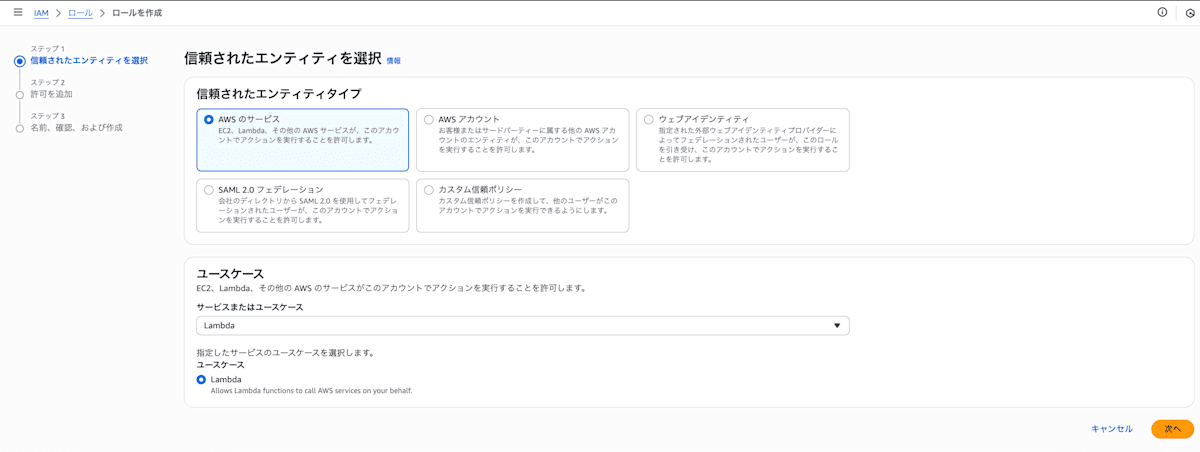
- ポリシーに関してはJSONタブに以下を貼る。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "S3VectorsQuery", "Effect": "Allow", "Action": ["s3vectors:QueryVectors","s3vectors:GetVectors"], "Resource": "arn:aws:s3vectors:<AWS_REGION>:<AWS_ACCOUNT_ID>:index/<VECTOR_INDEX_ID>" }, { "Sid": "BedrockInvoke", "Effect": "Allow", "Action": "bedrock:InvokeModel", "Resource": "*" }, { "Sid": "Logs", "Effect": "Allow", "Action": ["logs:CreateLogGroup","logs:CreateLogStream","logs:PutLogEvents"], "Resource": "*" } ] } - IAM → Roles → Create role
-
Lambda関数のデプロイ
- 3で作成したロールを選択して、Lambda関数を作成する
- 以下の環境変数を設定する
- AWS_REGION = us-east-1
- BEDROCK_REGION = us-east-1
- INDEX_ARN = (1で作成したVector IndexのARN)
- MODEL_ID = amazon.titan-embed-text-v1 (埋め込みモデル)
- lambda_function.pyのコードは以下
LambdaのPythonコード
import os import json import base64 import boto3 from typing import Any, Dict, Tuple, Optional # 既定は Titan Embeddings v1(1536 次元)。v2 を使う場合は index の dimension も合わせること。 DEFAULT_EMBED_MODEL_ID = os.environ.get("MODEL_ID", "amazon.titan-embed-text-v1") # モジュールスコープのクライアントはコールドスタート後に再利用される _BEDROCK = None # type: Optional[Any] _S3V = None # type: Optional[Any] _INDEX_ARN = None # type: Optional[str] def _region_from_arn(arn: str, fallback: str) -> str: try: return arn.split(":")[3] if arn.startswith("arn:") else fallback except Exception: return fallback def _runtime_region() -> str: # 明示設定がなければ boto3 のセッションから推測 return os.environ.get("AWS_REGION") or (boto3.session.Session().region_name or "us-east-1") def _ensure_clients() -> Tuple[str, Any, Any]: """ 初回呼び出し時に INDEX_ARN と各クライアントを初期化する(未設定なら 500 を返す側で拾う)。 """ global _BEDROCK, _S3V, _INDEX_ARN if _BEDROCK and _S3V and _INDEX_ARN: return _INDEX_ARN, _BEDROCK, _S3V index_arn = os.environ.get("INDEX_ARN") if not index_arn: raise ValueError("INDEX_ARN is required (環境変数 INDEX_ARN が未設定)") rt_region = _runtime_region() s3v_region = _region_from_arn(index_arn, rt_region) bedrock_region = os.environ.get("BEDROCK_REGION", rt_region) # ここでクライアント生成(以降は再利用) _BEDROCK = boto3.client("bedrock-runtime", region_name=bedrock_region) _S3V = boto3.client("s3vectors", region_name=s3v_region) _INDEX_ARN = index_arn return index_arn, _BEDROCK, _S3V def _parse_event(event: Dict[str, Any]) -> Dict[str, Any]: """ API Gateway v2 / Lambda 直 invoke 双方を受けられるように body を取り出す。 base64 の場合は復号。 """ body = event.get("body", event) if isinstance(body, str): if event.get("isBase64Encoded"): try: body = base64.b64decode(body).decode("utf-8") except Exception: # 復号に失敗したらそのまま解釈を試みる pass try: body = json.loads(body) except Exception: body = {"query": body} return body if isinstance(body, dict) else {} def _int_in_range(val: Any, default: int, lo: int, hi: int) -> int: try: v = int(val) except Exception: v = default if v < lo: v = lo if v > hi: v = hi return v def _embed_text(bedrock, text: str, model_id: str) -> list: payload = json.dumps({"inputText": text}) r = bedrock.invoke_model( modelId=model_id, contentType="application/json", accept="application/json", body=payload, ) data = json.loads(r["body"].read().decode("utf-8")) vec = data.get("embedding") or data.get("vector") if not vec and isinstance(data.get("embeddings"), list) and data["embeddings"]: vec = data["embeddings"][0] if not vec: raise RuntimeError(f"embedding not found in response: keys={list(data.keys())}") return vec def _ok(body: Dict[str, Any]) -> Dict[str, Any]: return {"statusCode": 200, "body": json.dumps(body, ensure_ascii=False), "headers": {"Content-Type": "application/json"}} def _bad_request(msg: str) -> Dict[str, Any]: return {"statusCode": 400, "body": json.dumps({"error": msg}, ensure_ascii=False), "headers": {"Content-Type": "application/json"}} def _server_error(msg: str) -> Dict[str, Any]: return {"statusCode": 500, "body": json.dumps({"error": msg}, ensure_ascii=False), "headers": {"Content-Type": "application/json"}} def lambda_handler(event, _context): try: index_arn, bedrock, s3v = _ensure_clients() except Exception as e: # import 時ではなく実行時に明確な 500 を返す print(f"[error] init failed: {e}") return _server_error(f"init failed: {e}") body = _parse_event(event) query = body.get("query") or body.get("q") if not query: return _bad_request("query required") # topK は 1..30 でクランプ(必要なら上限は調整) topk = _int_in_range(body.get("topK", 5), default=5, lo=1, hi=30) # フィルタは辞書のみ許可(それ以外は無視) flt = body.get("filter") if isinstance(body.get("filter"), dict) else None model_id = body.get("modelId") or DEFAULT_EMBED_MODEL_ID try: vec = _embed_text(bedrock, query, model_id) resp = s3v.query_vectors( indexArn=index_arn, topK=topk, queryVector={"float32": vec}, filter=flt, returnMetadata=True, returnDistance=True, ) except Exception as e: print(f"[error] query failed: {e}") return _server_error(f"query failed: {e}") # 代表的なキー名のどれかに合わせて取り出す results = ( resp.get("vectors") or resp.get("results") or resp.get("matches") or resp.get("vectorMatches") or resp.get("items") ) out: Dict[str, Any] = {"query": query, "topK": topk, "results": results if results is not None else []} if results is None: # 想定外の形なら raw も返す(デバッグ用) out["raw"] = resp # 返り値は API Gateway/Lambda Proxy と互換の JSON return _ok(out)
4.2 実行手順(データ投入から回答プレビューまで)
-
事前準備
% export AWS_REGION=us-east-1 % export VBUCKET=<ベクターバケット名> % export VINDEX=<ベクターインデックス名> % export DOC_TAG=jsquad_demo % export LAMBDA_FN=<Lambda関数名> % export BEDROCK_LLM_ID=<BedrockのLLMのモデルID> % python -m pip install -U pip datasets huggingface_hub truststore boto3 s3vectors-embed-cli使用可能なBEDROCK_LLM_IDは以下のコマンドで確認できる。
% aws bedrock list-foundation-models \ --by-inference-type ON_DEMAND \ --by-provider anthropic \ --region "$AWS_REGION" \ --query 'modelSummaries[].modelId' -
コード
-
取得&整形
JSQuAD「日本語」から 10 件だけ取り出して JSONL 化コード:「01_jsquad_flatten.py」
#!/usr/bin/env python3 """ JSQuAD(JGLUEのSQuAD互換)から最初の N 件を抽出し、 question / gold_answer / context の JSONL に整形して保存します。 """ import argparse import json import itertools import sys from datasets import load_dataset DATASET_ID = "sbintuitions/JSQuAD" def main(): parser = argparse.ArgumentParser(description="JSQuAD → JSONL flattener") parser.add_argument("--split", default="train", help="JSQuAD は通常 'train'") parser.add_argument("--max-rows", type=int, default=10, help="先頭から出力する件数") parser.add_argument("--out", default="dataset_ctx_top.jsonl", help="出力ファイル(JSONL)") args = parser.parse_args() # データ読み込み。指定 split が無ければ 'train' にワンステップでフォールバック。 try: dataset = load_dataset(DATASET_ID, split=args.split) except Exception as e: if args.split != "train": print(f"[warn] split='{args.split}' が見つからないため 'train' に切替えます: {e}", file=sys.stderr) dataset = load_dataset(DATASET_ID, split="train") else: print(f"[error] データセット読み込み失敗: {e}", file=sys.stderr) sys.exit(1) written = 0 with open(args.out, "w", encoding="utf-8") as f: for example in itertools.islice(dataset, args.max_rows): question = example.get("question") or "" context_text = example.get("context") or "" answers = example.get("answers") or {} texts = answers.get("text") if isinstance(answers, dict) else None gold_answer = (texts[0] if texts else "") or "" # 欠損はスキップ if not question or not context_text: continue rec = {"question": question, "gold_answer": gold_answer, "context": context_text} f.write(json.dumps(rec, ensure_ascii=False) + "\n") written += 1 used_split = getattr(dataset, "split", args.split) print(f"Saved: {args.out} rows={written} (dataset={DATASET_ID}, split={used_split})") if __name__ == "__main__": main() -
S3 Vectors に投入
コード:「02_ingest_dataset_cli.py」
#!/usr/bin/env python3 """ JSONL(question / gold_answer / context)を、s3vectors-embed-cli で S3 Vectors に 1行=1ベクトルとして投入します。 必須: 環境変数 VBUCKET, VINDEX(DOC_TAG は未設定なら jsquad_demo) 任意: EMBED_MODEL_ID(既定: amazon.titan-embed-text-v1)、EMBED_CLI """ import hashlib import json import os import sys import subprocess import shutil from pathlib import Path INPUT_PATH = "dataset_ctx_top.jsonl" VBUCKET = os.environ.get("VBUCKET") VINDEX = os.environ.get("VINDEX") DOC_TAG = os.environ.get("DOC_TAG", "jsquad_demo") MODEL_ID = os.environ.get("EMBED_MODEL_ID", "amazon.titan-embed-text-v1") # 1536次元 def require_env(name: str, value: str | None): if not value: print(f"[error] {name} is not set. export {name}=...", file=sys.stderr) sys.exit(1) def resolve_embed_cli() -> str: # 優先: 環境変数 → .venv 固定パス → PATH 検索 → そのまま if os.environ.get("EMBED_CLI"): return os.environ["EMBED_CLI"] venv_cli = Path(".venv/bin/s3vectors-embed") if venv_cli.exists(): return str(venv_cli) return shutil.which("s3vectors-embed") or "s3vectors-embed" def run_cmd(argv: list[str]): # ログ表示(可読性のため簡易クォート) pretty = " ".join(repr(a) if " " in a else a for a in argv) print("$", pretty) subprocess.run(argv, check=True) def main(): require_env("VBUCKET", VBUCKET) require_env("VINDEX", VINDEX) path = Path(INPUT_PATH) if not path.exists(): print(f"[error] {INPUT_PATH} がありません。先に 01_jsquad_flatten.py を実行してください。", file=sys.stderr) sys.exit(1) rows = [json.loads(l) for l in path.read_text(encoding="utf-8").splitlines()] embed_cli = resolve_embed_cli() seen = set() ok = 0 for i, rec in enumerate(rows): context = (rec.get("context") or "").strip() if not context: print(f"[skip] no context at row {i}") continue # 追加: 内容ハッシュで重複除去 h = hashlib.sha256(context.encode("utf-8")).hexdigest() if h in seen: print(f"[skip] duplicated context at row {i}") continue seen.add(h) tmp = Path(f"/tmp/ctx_{i:03d}.txt") tmp.write_text(context, encoding="utf-8") meta = {"doc": DOC_TAG, "id": f"case_{i:03d}", "source": "jsquad"} meta_json = json.dumps(meta, ensure_ascii=False) argv = [ embed_cli, "put", "--vector-bucket-name", VBUCKET, "--index-name", VINDEX, "--model-id", MODEL_ID, "--text", str(tmp), "--metadata", meta_json, ] try: run_cmd(argv) ok += 1 except subprocess.CalledProcessError as e: print(f"[warn] failed at row {i}: {e}", file=sys.stderr) # 続行(ブログ検証の再現性を優先) print(f"✅ Ingest complete. ok={ok}/{len(rows)} doc={DOC_TAG}") if __name__ == "__main__": main() -
RAG の回答を出し、目視用の Markdown を作成
コード:「03_rag_preview_answers.py」
#!/usr/bin/env python3 """ Lambda retriever で topK を取り、上位コンテキストを Bedrock LLM に渡して 回答のプレビュー(Markdown / JSONL)を生成します。 """ import argparse import json import os import re import sys import boto3 def load_rows(path: str): with open(path, encoding="utf-8") as f: return [json.loads(l) for l in f] def call_lambda(lam, function_name: str, payload: dict) -> list[dict]: resp = lam.invoke(FunctionName=function_name, Payload=json.dumps(payload).encode("utf-8")) body = json.loads(json.loads(resp["Payload"].read().decode("utf-8"))["body"]) results = ( body.get("results") or body.get("vectors") or body.get("matches") or body.get("vectorMatches") or body.get("items") or [] ) # distance が小さいほど近い。None は末尾へ。 results.sort(key=lambda v: (v.get("distance") is None, v.get("distance", 1e9))) return results def _norm_snip(s: str) -> str: # 空白を潰して比較(微小差分を吸収) return re.sub(r"\s+", " ", (s or "")).strip() def build_prompt(question: str, contexts: list[dict]) -> tuple[str, str]: def sanitize(s: str, limit=500) -> str: s = re.sub(r"\s+", " ", (s or "")).strip() return s[:limit] + ("…" if len(s) > limit else "") lines = [f"[{i}] {sanitize(c['snippet'])}\n(出典: {c['source']})" for i, c in enumerate(contexts, 1)] system = ( "あなたは厳密な日本語アシスタントです。以下のコンテキスト【のみ】を根拠に回答してください。" "外部知識や推測はしないでください。可能な限りコンテキストに現れる語をそのまま用いて抽出的に答えます。" "質問の種類に応じて出力形式を選びます:" " 1) 短答型(名称/用語/数値/日付/Yes-No/『〜は何という?』)の場合、" " 先頭行は答えのみを1行で出力(説明や前置きは付けない)。" " 2) 説明型(定義/理由/比較/手順/要約など)の場合、1〜2文、または最大3点の箇条書きで簡潔に。" " 3) 根拠が不十分な場合は『不明』のみ。" "回答の本文に出典表記は書かないでください。" ) user = ( f"質問: {question}\n\n" "コンテキスト(これ以外は使わない):\n" + "\n\n".join(lines) + "\n\n" "上記ルールに従って最小限で回答してください。" ) return system, user def invoke_bedrock_anthropic(br, model_id: str, system: str, user: str) -> str: body = { "anthropic_version": "bedrock-2023-05-31", "max_tokens": 512, "temperature": 0.2, "system": system, "messages": [{"role": "user", "content": [{"type": "text", "text": user}]}], } r = br.invoke_model( modelId=model_id, contentType="application/json", accept="application/json", body=json.dumps(body).encode("utf-8"), ) data = json.loads(r["body"].read()) text = "".join([blk.get("text", "") for blk in data.get("content", []) if blk.get("type") == "text"]) return text.strip() def main(): ap = argparse.ArgumentParser(description="Generate RAG preview (Markdown + JSONL)") ap.add_argument("--input", required=True, help="dataset_ctx_top.jsonl") ap.add_argument("--doc-tag", default=os.environ.get("DOC_TAG", "jsquad_demo")) ap.add_argument("--lambda-fn", required=True) ap.add_argument("--region", default=os.environ.get("AWS_REGION", "us-east-1")) ap.add_argument("--topk", type=int, default=10) ap.add_argument("--num-ctx", type=int, default=3) ap.add_argument("--llm-id", required=True) ap.add_argument("--out-md", default="preview_answers.md") ap.add_argument("--out-jsonl", default="preview_answers.jsonl") args = ap.parse_args() lam = boto3.client("lambda", region_name=args.region) br = boto3.client("bedrock-runtime", region_name=args.region) rows = load_rows(args.input) md_lines: list[str] = [] with open(args.out_jsonl, "w", encoding="utf-8") as fjson: for i, rec in enumerate(rows): question = rec.get("question", "") gold = rec.get("gold_answer", "") results = call_lambda( lam, args.lambda_fn, {"query": question, "topK": args.topk, "filter": {"doc": {"$eq": args.doc_tag}}}, ) unique_results = [] seen_snips = set() for v in results: m = v.get("metadata") or {} sn = _norm_snip(m.get("S3VECTORS-EMBED-SRC-CONTENT") or "") # スニペットが空ならユニーク化のキーに使えないので素通し key = sn or f"__key:{v.get('key')}" if key in seen_snips: continue seen_snips.add(key) unique_results.append(v) if len(unique_results) >= args.topk: break results = unique_results contexts = [] for v in results[:args.num_ctx]: m = v.get("metadata") or {} contexts.append( { "snippet": m.get("S3VECTORS-EMBED-SRC-CONTENT") or "", "source": m.get("source") or m.get("doc") or v.get("key") or "", } ) try: sysmsg, usrmsg = build_prompt(question, contexts) answer = invoke_bedrock_anthropic(br, args.llm_id, sysmsg, usrmsg) except Exception as e: answer = f"(LLM呼び出しエラー: {e})" # Markdown md_lines.append(f"## case_{i:02d}") md_lines.append(f"- Question: {question}") md_lines.append(f"- Gold : {gold}") md_lines.append(f"- Answer : {answer}\n") md_lines.append("Contexts used") for j, v in enumerate(results[:args.num_ctx], 1): m = v.get("metadata") or {} sn = re.sub(r"\s+", " ", (m.get("S3VECTORS-EMBED-SRC-CONTENT") or "")).strip() src = m.get("source") or m.get("doc") or v.get("key") or "" # 500文字で切り、残りは省略記号 sn_short = sn[:500] + ("…" if len(sn) > 500 else "") md_lines.append(f"{j}. dist={v.get('distance')} src={src}\n {sn_short}") md_lines.append("\n---\n") # JSONL(解析用) fjson.write( json.dumps( { "id": f"case_{i:02d}", "question": question, "gold": gold, "answer": answer, "contexts": contexts, "topk_hits_meta": [ { "distance": v.get("distance"), "key": v.get("key"), "snippet": (v.get("metadata") or {}).get("S3VECTORS-EMBED-SRC-CONTENT"), } for v in results[:args.topk] ], }, ensure_ascii=False, ) + "\n" ) with open(args.out_md, "w", encoding="utf-8") as fmd: fmd.write("\n".join(md_lines)) print(f"✅ wrote: {args.out_md} / {args.out_jsonl}") if __name__ == "__main__": try: main() except Exception as e: print(f"ERROR: {e}", file=sys.stderr) sys.exit(1)
-
-
実行コマンド
% python 01_jsquad_flatten.py --split train --max-rows 10 % python 02_ingest_dataset_cli.py % python 03_rag_preview_answers.py \ --input dataset_ctx_top.jsonl \ --doc-tag $DOC_TAG \ --lambda-fn $LAMBDA_FN \ --region $AWS_REGION \ --topk 10 \ --num-ctx 3 \ --llm-id $BEDROCK_LLM_ID
4.3 実験条件
- Embedding: Amazon Titan Text Embeddings v1(1536 次元)
- Retriever: S3 Vectors(距離: Cosine、topK=10、num-ctx=3)
- LLM: Anthropic Claude 3.5 Sonnet(Amazon Bedrock)
- 入力データ: JSQuAD から 10 件(question / gold_answer / context)
[補足]
- この評価は「最小構成 RAG の妥当性を目視で確かめる」目的で、上記設定を固定して簡易に実施しています。
[データ出典]
- JSQuAD(JGLUEの一部)。本稿ではJSQuADのquestion/gold/contextを無加工で使用しています。ライセンス/注意事項はJGLUE/JSQuADの配布元に従ってください。
4.4 データ品質に関する注意(評価除外の扱い)
抽出した10件のうち2件で質問文の一部が欠落していました。
今回のquestionはJSQuADのレコードを無加工で使用しており、欠落は上流の入力データ(JSQuAD の該当レコード)由来です。
- case_02: 文頭が欠落(「新たに …」の先頭が落ちている)。質問文単体では情報が不足していますが、retriever が返したスニペットが問と一致していたため、実運用上は意図の推測が可能と判断し、今回は評価に含めました(軽微欠落として注記)。
- case_08: 文末が欠落し、疑問文としての体裁が崩れていました。yes/no 解釈に偏るリスクが高く、公平性を保つ目的で評価集計から除外しました。
参考として、case_02 も評価外にした場合の指標も併記します(下記「4.5 実行結果」末尾)。
4.5 実行結果(10 件・うち 1 件は評価外)
評価指標の定義
- EM(Exact Match):gold と完全一致(表記ゆれなし)。
- Soft:gold を含む、または同義の短文(句点や「〜または〜」等の余分表現は許容)。EM を包含する。
- NG:上記いずれにも該当しないもの。
集計(評価外 1 件〈case_08〉を除外して 9 件で集計)
- EM(完全一致): 4/9(44.4%)
- Soft(一致含む・文章化許容): 8/9(88.9%)
- NG(不一致): 1/9(11.1%)
参考(case_02 も評価外にした場合、8 件で集計)
- EM: 3/8(37.5%)
- Soft: 7/8(87.5%)
- NG: 1/8(12.5%)
全件一覧(質問は原文のまま)
| case | question | gold | answer | 判定 | メモ |
|---|---|---|---|---|---|
| 00 | 新たに語(単語)を造ることや、既存の語を組み合わせて新たな意味の語を造ること | 造語 | 造語 | EM | 単語で正答 |
| 01 | 新たに造られた語のことを新語または何という? | 新造語 | 新語または新造語 | Soft | gold を含むが余分語あり |
| 02 | たに語(単語)を造ることや、既存の語を組み合わせて新たな意味の語を造ること、また、そうして造られた語を意味する言葉は? | 造語 | 造語 | EM | 文頭欠落はデータ側由来だが影響軽微 |
| 03 | 新たに語を造ることや、既存の語を組み合わせて新たな意味の語を造ることを何という? | 造語 | 造語 | EM | 単語で正答 |
| 04 | 既存の語を組み合わせたりして新しく単語を造ることを何と言う? | 造語 | 造語 | EM | 単語で正答 |
| 05 | 「その語が造語(されたもの)であるかどうか」という分類は意味を成すか成さない? | 成さない | 意味を成さない。 | Soft | 句点付きだが内容一致 |
| 06 | 単語の成り立ちを歴史的に捉える上で大きな手がかりとなりるものと言えば?漢字2文字で答えよ。 | 造語 | 諡号 | NG | 検索段階の話題ずれが主因 |
| 07 | 現在の全ての語は、何らかの意図や何によって造語されたものか? | 必要性 | 現在伝わっている全ての語は、何らかの意図や必要性によって造語されたものである。 | Soft | gold を含むが文章化 |
| 08 | 現在伝わっている全ての語は、いずれかの時代に何によって造語されたものである | 何らかの意図や必要性 | はい | 評価外 | 文末欠落により体裁不備(データ側由来) |
| 09 | 聖武天皇の尊号は。 | 天璽国押開豊桜彦天皇 | 天璽国押開豊桜彦天皇、勝宝感神聖武皇帝、沙弥勝満 | Soft | 複数正解の列挙(gold を含む) |
所見
- なお、コンテキストが複数正解を示唆する設問(別名・敬称など)は、Soft を主指標とし、EM は参考値としています(例: case_09)。
- 単語で答えるタイプの設問には強く、EM 4/9。
- 文体自由の設問は gold を含む文章応答になりやすく、Soft を確保(Soft 8/9)。
- 唯一の明確な誤答(case_06)は、retriever の topK に質問無関係な断片(「聖武天皇」など)が混入し、回答がそちらへ引っ張られた可能性が高い。
- データ品質の影響(case_02, 08)
case_02 は文頭欠落により質問文単体では不十分だが、retriever のスニペットが補助的に機能した可能性が高い。今回は軽微欠落として含めた。一方、case_08 は体裁不備の影響が大きいため評価外とした。
4.6 代表事例
-
誤答の例(case_06)
- Q:単語の成り立ちを歴史的に捉える上で大きな手がかりとなりるものは?(漢字2文字)
- Gold:造語
- Answer:諡号
- TopK 抜粋(distance:小さいほど近い)
- 0.448:聖武天皇 … 尊号(諡号)を 天璽国押開豊桜彦天皇、勝宝感神聖武皇帝、沙弥勝満 とも言う…
- 0.457:造語 … 造語(ぞうご)は、新たに語(単語)を造ることや…
- 要因:1位が「聖武天皇/諡号」に寄っており、回答が引っ張られた。
- 対策:クロスエンコーダ再ランキング/topic メタデータでフィルタ。
-
形式はズレるが内容は正しい例(case_01, 05, 07, 09)
gold を含む一方で、文章化や列挙により EM を逃す。軽い形式ガイドと後処理で改善余地あり。 -
データ品質の影響(case_02, 08)
どちらも質問文が部分欠落。スクリプトはquestionを無加工で保存しており、欠落は入力データ由来。公平性のため、case_08 は評価外とした。
4.7 改善の方向性
S3 Vectors特有の領域
- スキーマ/メタデータ
- 粗い絞り込み用は filterable に(doc, source, lang, version など)、長文スニペットはnon-filterableフィールドに格納する。S3VECTORS-EMBED-SRC-CONTENT は non-filterable 推奨。version を必ず持たせ異なるバージョン間の混在を防ぐ。
- インデックス設計
- 埋め込みモデル/ドメイン/言語ごとにインデックスを分割し、dimension/距離関数をモデルに合わせる。Lambda/Bedrock とインデックスのリージョンは揃える。
- 品質ゲート
- 距離のしきい値で低信頼なヒットを除外し、ドキュメント単位の採用上限で分散を確保。近似重複を排除して多様性を確保。
- ペイロード/コスト最適化
- QueryVectorsは必要最小限(returnMetadata=False など)で取得し、上位n件のみ GetVectors で詳細メタデータ/スニペット取得の二段構えにする。
- 更新/運用
- content_hash をメタデータに持たせ重複排除。version 付きで新旧併走→切替の安全運用。距離分布・ヒット率を継続的にモニタリングして topK/しきい値をチューニング。
一般的な RAG 領域
-
Retrieval(検索)
- topK をやや増やし、クロスエンコーダ(質問と候補スニペットを同時入力して関連度を判定する再ランカー)等で再ランキングして話題のずれを抑制。
- メタデータ(title/section/topic)を持たせ、質問トピックに合致するスニペットを優先。
- 検索結果(topK)に出た重複・類似重複(near‑duplicate)のチャンクは、取り込み時または検索時に重複フィルタで除外する(本稿のプレビュー実装で対応済み)。
-
Generation(生成)
- プロンプトに軽い形式ガイドを追加(「単語で答えられる場合は語だけ/指定がなければ一文で簡潔に」など)。
- 後処理で軽整形(「、」「または」「/」などで分割→最短語 or gold と一致する候補を優先)で EM を底上げ。
4.8 Retriever の戻り値を確認する(デバッグ)
S3 Vectors を呼び出す Lambda の生応答を確認すると、どの断片が LLM に渡ったか(S3VECTORS-EMBED-SRC-CONTENT)と距離が分かります。
CLI 例(日本語 JSON を扱うため --cli-binary-format raw-in-base64-out を付与)
aws lambda invoke \
--function-name "$LAMBDA_FN" \
--region "$AWS_REGION" \
--cli-binary-format raw-in-base64-out \
--payload '{"query":"造語とは?","topK":3,"filter":{"doc":{"$eq":"jsquad_demo"}}}' \
out.json >/dev/null && jq . out.json
見るポイント
-
results[].distanceは小さいほど近い -
results[].metadata["S3VECTORS-EMBED-SRC-CONTENT"]が LLM に渡したスニペット -
metadata.source/doc/idが期待どおり付与されているか
4.9 まとめ
- 最小構成の RAG を S3 Vectors 上で実装し、s3vectors-embed-cli → Vector bucket/index → Lambda(QueryVectors) → Bedrock(埋め込み/LLM)の処理フローを確認。インデックスは埋め込み次元・距離(Cosine)をモデルに合わせ、各サービスのリージョンの整合性を確保。
- JSQuAD 10件で簡易検証(欠落2件のうち1件は評価外)。集計9件では EM 4/9(44.4%)、Soft 8/9(88.9%)、NG 1/9(11.1%)。短答に強く、唯一の明確な誤答は検索段階の話題ずれが主因。
- 設計上の要点: 粗い絞り込みキー(doc/source/lang/version)は filterable、長文スニペットは non‑filterable(S3VECTORS-EMBED-SRC-CONTENT 推奨)に分離。モデル/ドメイン/言語ごとにインデックスを分割して運用・精度調整を容易に。
- 品質/コスト制御: 距離のしきい値で低信頼なヒットをフィルタリングし、ドキュメント単位の最大採用数と近似重複を除外して多様性を確保。QueryVectors は必要最小限にし、上位のみ GetVectors で詳細メタデータ/スニペット取得する二段構えでペイロードを抑制。
- 次のステップ: 再ランキングやメタデータ活用の強化、プロンプト/後処理で形式揺れを低減。content_hash と version による排除/置換管理、距離分布・ヒット率を継続的にモニタリングして、topK/しきい値をチューニングし、本番環境での A/B テスト切り替えに備える。

Discussion