はじめまして!4月から新卒として入ったエクサウィザーズの綱島です。
2025年5月29日から5月31日まで東京ビッグサイトで開催されていた、第31回画像センシングシンポジウム(SSII2025)に聴講参加をしてきました。
SSIIは主にセンサデータに関連するコンピュータビジョンの研究が発表される学会です。センサとは、我々が普段スマホで使っている通常のカメラであるRGBカメラであったり、3Dの形状(点群)を取ることができるLiDARなどが例としてよく挙げられると思います。センサデータという特性上、企業の方の発表や、産業応用の発表が非常に多いです。そこで、今回の記事では産業界において価値を生み出すことに繋げやすそうな話を主軸に、綱島の主観や説明を混ぜながら述べていきます。
講演
ニューラルネットワークをエッジデバイスで動かす際の取り組みについての話です。元々ニューラルネットワークをエッジデバイスで動かす際には、大きく分けて4つの取り組みがありました。画像処理であればMobileNetのようにCPUで動作する際に高速に処理可能な仕組みを作るネットワーク自体の改良、ニューラルネットワークの重みを32bitから16bit等に丸める量子化、ニューラルネットワークの重みを部分的に削除する剪定(pruning)、大きいモデルの出力を模倣するように小さいモデルを学習する蒸留です。余談にはなりますが、綱島は昔画像生成モデルに関する敵対的蒸留というものを提案しています。ご興味がある方はご覧ください(Adversarial Knowledge Distillation for a Compact Generator)。
近年ではLLMやVLMが産業界では圧倒的ユースケースを占めていると思います。それゆえ、訓練を伴うネットワーク自体の改良や剪定や蒸留というよりは、重みを32bitから8bitや4bitまで極端に量子化する枠組みや、ハードウェア律速への対応に人気があります。上記の2講演は量子化に関する近年の取り組み、ハードウェア律速への対応についてを取り扱っており、非常にプラクティカルな講演で面白かったです。
- SSII2025 [OS2-02] イベントカメラの研究紹介と可視光通信への応用
- SSII2025 [OS2-03] マルチ/ハイパースペクトル領域における高度な画像撮影および処理技術
- SSII2025 [OS2-01] 自動運転の性能と共に進化するセンシングデバイス
センシングデバイスは我々が日常生活で普段触れるRGBカメラだけでなく、時間分解能が高いイベントカメラ(前の観測からの差分のみを取得するので、100万fps近い処理が可能)、可視光波長以外も取得可能なマルチ/ハイパースペクトルカメラ、3Dの点群を取得することができるLiDARなどが例としてあります。
イベントカメラは直接RGBデータを取得するのではなく、差分観測を取得するため、プライバシーに配慮した処理に用いたり、高速に動作する物体を捉えることに有効です。マルチ/ハイパースペクトルカメラは、赤外線などを捉えた上での処理が可能で、高度な深層学習ベースのモデルを使わずとも、センサデータから古典的アルゴリズムで解決が可能であったりします。LiDARは、光を照射して返ってきた時間や反射強度から深度を計算することで3D点群を構築し、3Dを考慮した処理を実現することができます。上記の3講演では、イベントカメラ、マルチ/ハイパースペクトルカメラ、自動運転に用いるセンシングデバイスの研究紹介と、応用事例について紹介しており、非常に興味深いです。
AIにおいて、中身がブラックボックスで、なぜその答えが出ているのかがわからないと困るケースというのは往々にしてあると思います。例えば、医療における病理診断において、理由もわからずAIが癌と診断したとなれば、それは診断結果を伝える医者としても患者としても困ったことになるでしょう。この点について主にAI分野において近年取り組まれていることとして、解釈性と説明性があります。解釈性は、どういう仕組みでその出力が得られたのかが説明できることを指します。説明性は、出力自体がどのようにして得られたのかを後付けで分析して説明できることを指します。解釈性と説明性は非常に紛らわしいですが、解釈性は計算過程が明瞭であることを求められ、説明性は計算過程は不明瞭であっても結果についての説明ができれば問題ないということです。解釈性はその特性から、単純な構造に落ち着きがちなため、近年の大規模モデルのブームの中では説明性が重要になっています。
ところで、説明性というと何を以て「説明できている」ということになるのでしょうか?これは実は説明をされる対象によって変化します。例えば、機械学習に明るくない方に対して、「SHAPという、入力に対して出力がどれほど影響を受けていたかの手法のバイオリン図を見てください。ほら!この変数が出力に影響を与えているでしょう!」と言っても何も伝わらないでしょう。一方、機械学習の専門家であれば、こうした具体的な説明のほうが理解しやすいでしょう。上記の講演は、説明性に関してAIの信頼性との関係性を話し、信頼性に関連して大規模言語モデル(LLM)にバックドアが仕込まれたりするポイズニング関係の話をなさっている非常に興味深いものです。綱島個人的には、LLMのポイズニングやセキュリティ関係の話は興味を持っており、学術的にもホットな領域です。
- SSII2025 [TS3] 医工連携における画像情報学研究
- SSII2025 [OS3] どの論文でもダメなんだけど! 〜実応用とその課題〜
- SSII2025 [OS3-01] End-to-End自動運転の実応用の現場から
- SSII2025 [OS3-02] 広告における画像生成技術の実応用の現状
- SSII2025 [SS2] 横浜DeNAベイスターズの躍進を支えたAIプロダクト
実世界のデータを扱ってモデルを作る際、様々なギャップで苦しめられると思います。例えば、学習データに対してテストデータの分布が大きく違っていることで、全然性能が出ないということや、センシングデバイスを実際に使うと様々なセンサに関するノイズが乗っており(暗所でのRGBカメラのISO感度をあげたことによるノイズ、移動距離を測るセンサに誤差が乗っている等々)、学習データとの分布ギャップによって性能がでない等々の問題が起こります。
上記の5講演では、データ数が極端に少ないケース、論文通りの結果が出ない、実世界データを使ったプロダクトのチームビルディングを話しているものであり、様々な示唆が得られると思います。
画像生成は、近年拡散モデルの発展により、非常に品質の高い画像や動画が生成できるようになってきました。しかし、生成画像は物理的に不自然な絵になっていたり(指の形が崩壊しているなど)、生成動画で物理現象とはおかしい挙動をしていたり(石が転がる動画を生成したら山の斜面を駆け上っていくなど)ということは未だに起こります。これは、基本的に現在の最先端の拡散モデルは、物理的に整合性の取れた画像を生成するための制約などがほとんど入っておらず、大規模なデータからルールを発見しなくてはいけないことが主な原因です。上記の講演では、光学・物理原理に基づいて自然な画像や動画を生成するための研究についての話が展開されます。綱島は以前画像生成についての研究を行っており、顔であったり構造物が物理的におかしく崩壊するということはよく起きており、その問題を改善するための研究が以前よりかなり進展してきたということは非常に興味深かったです。これからは、今までよりも加速して画像生成がアーティスティックなことや広告にも展開されていくと思われるので、こうした物理的整合性を保った画像・動画生成というのはますますホットになっていくと思われます。
我々エクサウィザーズには、LLMのエッジデプロイだけでなく特定ユースケースでのエッジデバイス用のモデルの開発(剪定、蒸留も)の知見を有したエンジニア、マルチ/ハイパースペクトルカメラに精通したエンジニア、綱島を含めて画像生成、動画生成、3D関係に明るいエンジニアがいます。
また、多数のセキュリティやインフラのプロフェッショナルが在籍しており、LLM関係サービスをデプロイして、安全なワークフローを提供することができます。エクサウィザーズは、国内での信頼のあるサービスとして提供することができ、金融や機密性の高いデータを取り扱うための高いセキュリティ要件を満たすことができるサービスも提供することができます。様々な画像のお困りごとやAIの活用についてお気軽にお問い合わせください。
ポスター(全てのポスターは撮影と掲載許可をいただいています※)
ここからは、綱島が個人的に面白かったポスターをいくつかピックアップして簡単にご紹介していこうと思います。他にもたくさん面白いポスターがあったので、ぜひSSIIに来年は遊びに行ってみると楽しいと思います。
※ 掲載に不都合等がございましたら、ご連絡いただけましたら速やかに削除いたします。
ニューラルネットワークにおいて、データセット中の少数クラスの性能が低下してしまうLong-tail分布の問題は広く知られています。この研究では、クラスごとに最小のロスを設定し、多数クラスの学習が過剰に進みすぎないような正則化を加えることで、不均衡データの性能改善に取り組んでいます。今はLLMやVLM全盛の時代ですが、まだまだ特定の領域ではスクラッチやfine-tuningをしていくことはあります。Long-tail分布の問題からは基本的に逃げられないので、こうした研究は非常に重要だと思いました。

こちらは弊社の山下と加藤と千葉大学の久保研の方々と共同研究した結果になります。強力なレーザー光源無しに流体の流れのベクトル(流れ場)を可視化に挑戦するために、光の振動方向が撮れる偏光カメラとナノセルロースファイバーを利用している研究になります。

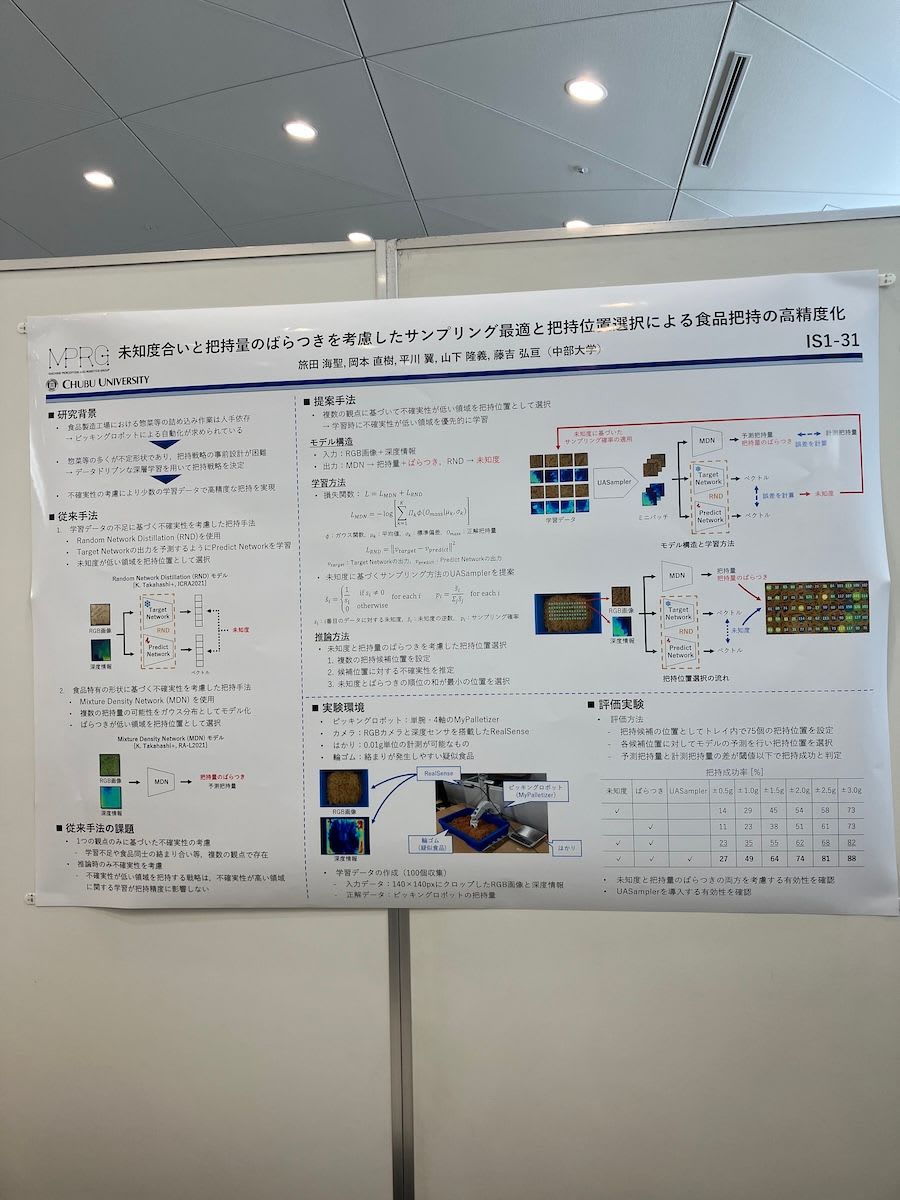
物体の把持(ピッキング)において、ノイズの影響を軽減した構造的未知を検出可能なRandom Network Distillation (RND) を用いて未知度を算出し、既知に近い領域(学習データ分布に近い)から把持を行っていく研究でした。面白かった点として、把持を既知から行っていくと、最後は未知だけが残りそうな気もしますが、次第に物体が崩れていって段々と既知の形が多くなるようです。
自動車の運転席において、自動車の運転での注視領域を学習したモデルを推論時に使う際、日常シーンの注視領域を学習したモデルの出力を自動車の運転での注視領域を学習したモデルの出力から引くことで、自動車の運転での注視領域を学習したモデルのノイズを取り除くことができる研究とのことでした。日常シーンの一般的注視領域というのが自動車の運転席のシーンというドメイン違いのデータにも使えるというのがかなり興味深かったです。

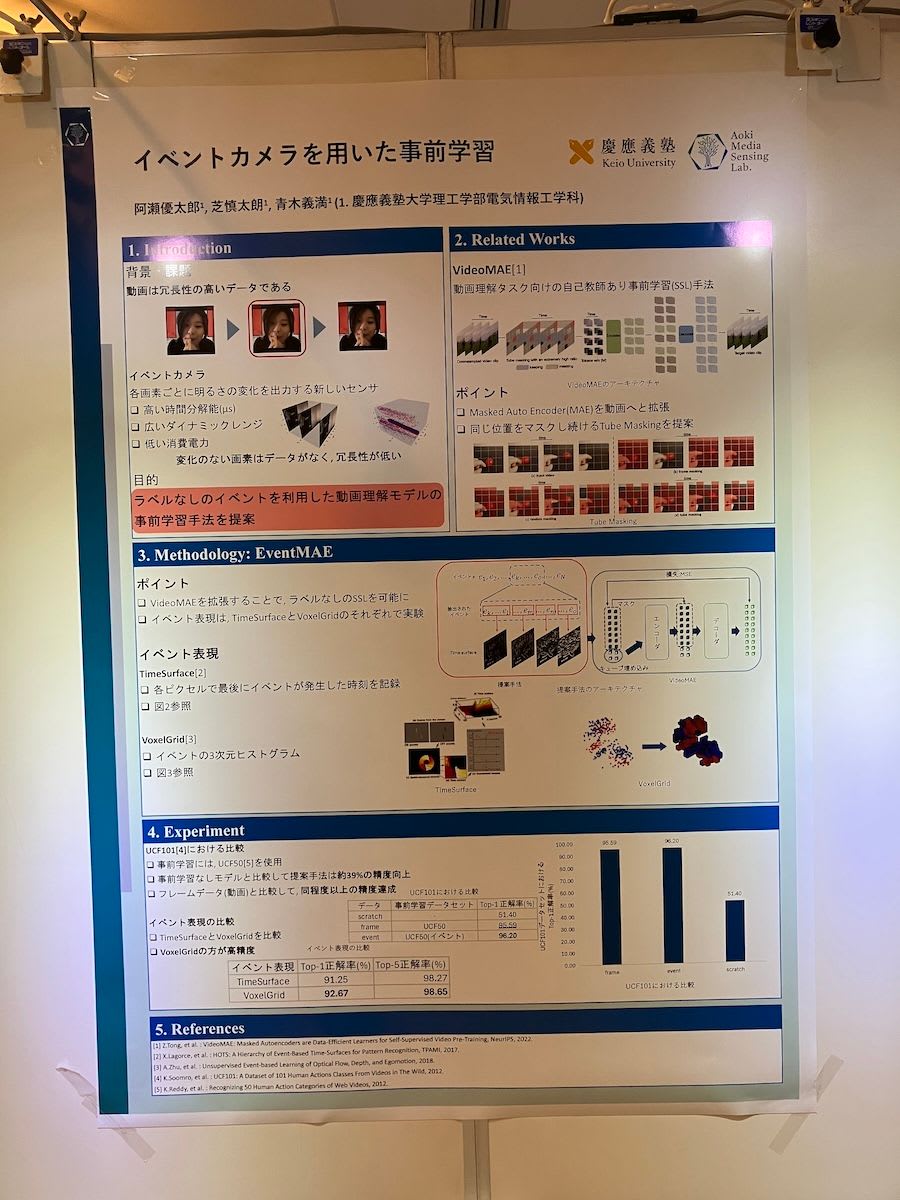
前の観測からの差分を取得することで、時間分解能が高いイベントカメラの事前学習の研究になります。事前学習として、一般的な動画での事前学習の手法のVideoMAEを用い、イベントカメラのデータの表現方法として、ボクセル表現を使うのか、各ピクセルの変化と変化時間のデータを使うのかで調査していました。イベントカメラデータの事前学習というトピック自体興味深いものであり、活用の方向性について興味深い研究でした。
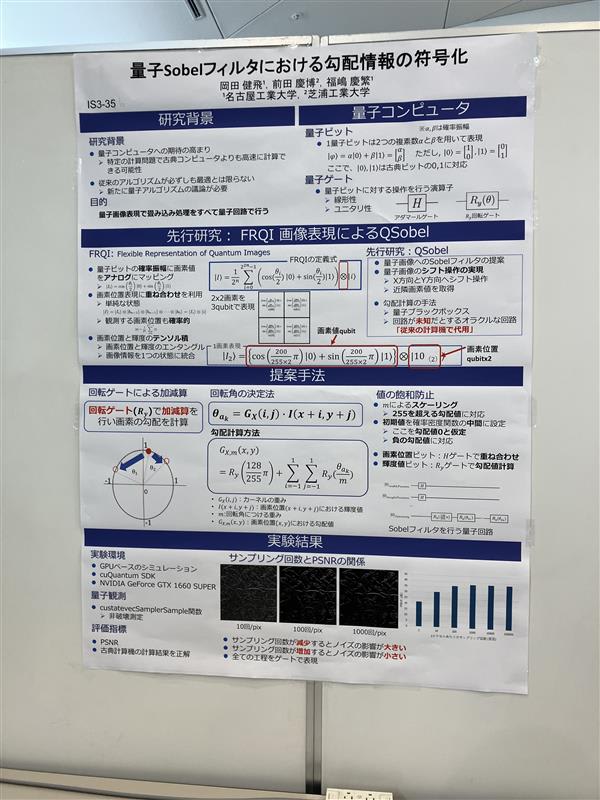
量子コンピュータの挙動をGPUでシミュレーションし、実際の量子コンピュータの計算で使えるエッジ抽出のSobelフィルタのアルゴリズムを提案した研究になります。現在は量子ビットの計算の性能的に、現在の通常のCPUやGPUの計算速度には及ばないとのことでしたが、いずれは量子コンピュータが広く普及したときにはさらに高速になるとのことで、非常に将来が楽しみな研究でした。
電動車いすに乗る方の支援を目的とした、歩行者との衝突リスク推定の研究とのことでした。HCIとして、衝突リスクということについての定義と、ユーザーエクスペリエンス(UX)について検討を行っており、綱島の出身研究室でHCIでの障碍者支援を行っていたこともあり、非常に興味深かったです。

ドライブレコーダの映像と地図データベースであるOpenStreetMapからリアルな三次元復元を行う研究とのことです。アメリカではWaymoが多額の投資によって、街の三次元再構成を行ったりということはありますが、基本的には全ての企業がそのようなことを行えるわけがありません。それゆえ、それを回避するような興味深いアプローチだと思いました。

室内の三次元再構成をする際には、手作業で撮影した写真を使うケースが多いですが、この研究では撮影をドローンで自動化するという枠組みに取り組んでいました。三次元再構成を行なっていく上で、自動化する枠組みというのは世の中のプロジェクト的に必要になるシーンも出てくる可能性はあるので、産業に応用できそうだと思いました。一応、巨大な建造物を複数のドローンを同期して写真を撮影し、三次元再構成をするという研究を綱島は見たことがあります。


まとめ
SSIIでは産業的に興味深い講演や発表があるだけでなく、学術的にも面白い研究も多くあり、企業の人にとってはより興味深い学会なのではないかと思います。
エクサウィザーズでは一緒に働く人を募集しています。中途、新卒両方採用していますので、興味のある方は是非ご応募ください!

Discussion