AWS LambdaでPDFを画像ファイルに変換すると文字が消えた件
はじめに
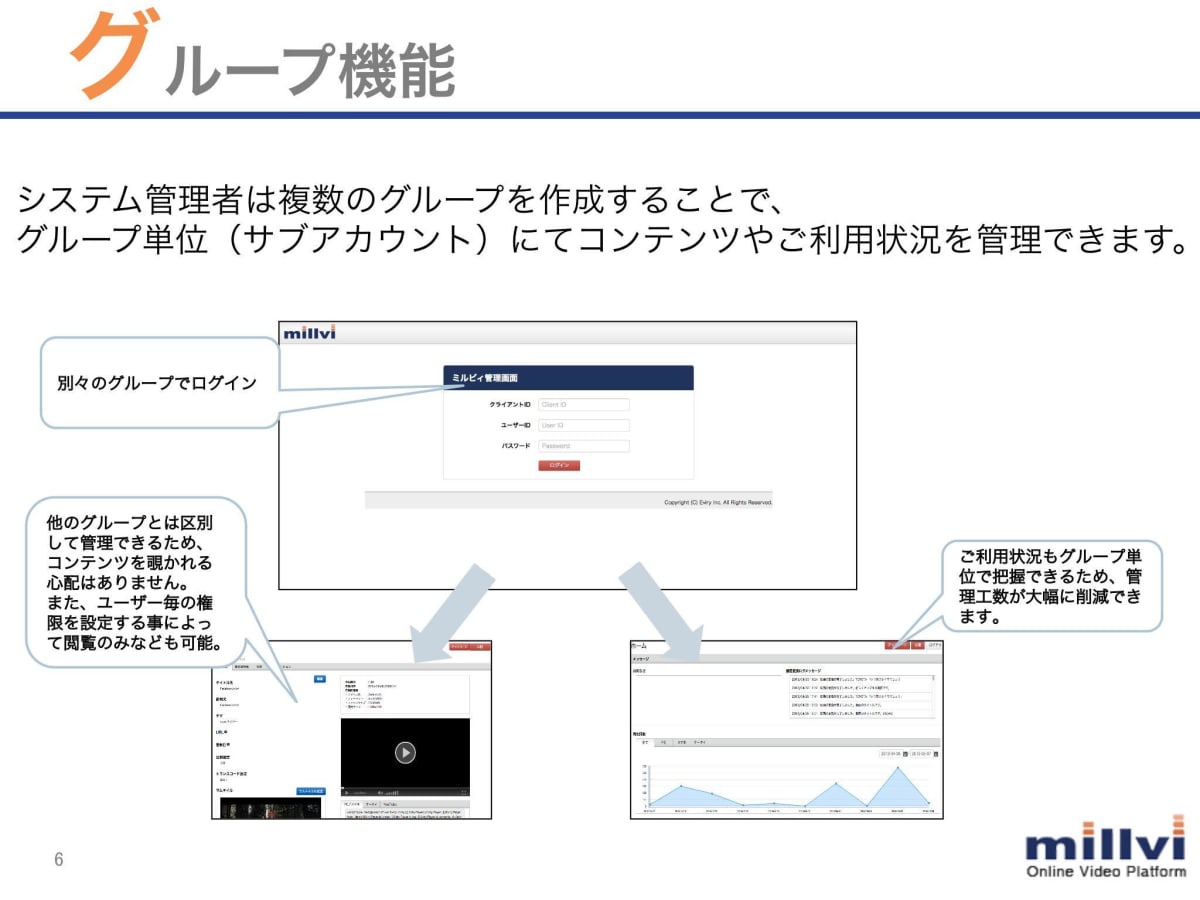
はじめまして、エビリーで動画配信システム『millvi(ミルビィ)』の開発を担当しているukisuと申します。
millviは動画配信やライブ配信を売りにしていますが、PDFをアップロードしWebページ上で配信する機能も提供しています。
今回は、millviの基盤技術のリプレイスにあたって、PDFから画像への変換機能をAWS Lambdaを用いて開発した際に直面した問題と、その解決法について、お話していきます。
なお、現在millviの開発では、Pythonをバックエンドにおけるメイン言語としているため、この記事ではサンプルコードとしてPythonを用いることとします。
LambdaでPDFを画像に変換...のはずが...
millviのリプレイスにあたっては、バックエンドは原則サーバーレスを利用することになったため、AWS Lambdaで開発を行うこととなりました。
PythonでPDFから画像への変換を行うには、pdf2imageという便利なライブラリがあったため、それを利用して実装を進めていきました。
処理の流れとしては、大まかに以下のフローとなります。
- S3バケットへのPUTイベントをトリガーにLambda関数が実行される
- PUTされたオブジェクト(PDFファイル)をダウンロードし、
pdf2imageを用いて画像ファイルへ変換する - 変換された画像ファイルをS3バケットへPUTする
以下に簡単なサンプルコードを載せておきます。
import io
import urllib.parse
from pathlib import Path
import boto3
from pdf2image import convert_from_bytes
s3 = boto3.client("s3")
def lambda_handler(event, context):
s3_info = event["Records"][0]["s3"]
bucket_name = s3_info["bucket"]["name"]
object_key = urllib.parse.unquote_plus(s3_info["object"]["key"], encoding="utf-8")
# S3からファイルを取得
try:
response = s3.get_object(Bucket=bucket_name, Key=object_key)
pdf_file_data = response["Body"].read()
except Exception as e:
print(e)
return
try:
dirname = Path(object_key).parent
filename = Path(object_key).stem
page_count = 0
first_page = 0
while True:
# PDFを画像に変換
images = convert_from_bytes(
pdf_file_data,
fmt="jpeg",
poppler_path="/opt/",
first_page=first_page,
last_page=first_page + 9,
size=(
2048,
None,
),
dpi=200,
)
if len(images) == 0:
break
else:
first_page = first_page + 10
# 画像をS3に保存
for image in images:
page_count += 1
with io.BytesIO() as img_bytes:
image.save(img_bytes, "jpeg")
img_bytes = img_bytes.getvalue()
output_file_name = (
f"{dirname}/images/{filename}-{page_count:05d}.jpeg"
)
s3.put_object(
Body=img_bytes,
Bucket=bucket_name,
Key=output_file_name,
ContentType="image/jpeg",
)
return page_count
except Exception as e:
print(e)
return
ただ、これだけでは必要なライブラリがLambdaインスタンス上にインストールされておらずエラーとなるため、以下のライブラリをLambda Layerに追加する必要があります。
ここまでのリソースをAWS上に展開したことで、PDF変換機能は一旦の決着をみた...
はずでした
展開されたPDF変換機能の動作確認を行っていたある社員から、「PDF変換を試してみたら、文字が消えた」との報告があがりました。
どういうことか分からぬまま見てみると、確かにPDF内の文字が消えており、自分で実行してみても同じ結果となりました。
以下が実際の変換前後の画像です。
- 前
- 後
え...?
ページ内の日本語だけ見事に消えています。
何が起きた...?
Docker上でLambdaを動かす
この現象についていろいろググってみると、目ぼしい記事がちらほら。
どうやらフォントが埋め込まれたPDFを変換した場合、Lambdaインスタンス上にそのフォントがインストールされていないと、変換後の画像から当該フォントが使われた文字が消えてしまうようです。
ということで、Lambdaインスタンス上にフォントデータを組み込んでやれば上手くいくのでは?、と思いいろいろと試してみましたが、尽く失敗...。
- 対応策(一例)
- 日本語フォントをLambda Layerに追加
- poppler-data を含めたものをzip化してLambda Layerに追加
万事休す、サーバーレスは諦めてEC2の利用も已む無しかという声も出始めた時、引き続きLambdaを調べていると一筋の光明が...
ここで分かったのは、Lambdaの実行環境としては、AWSが提供する汎用的な環境と、開発者が独自に構築した環境のどちらかを選択して利用できる、ということ。
今までは前者の汎用的な環境でしか構築していませんでしたが、もしかしたら後者の独自構築の手法でやれば解決できるのでは...?
ということで、早速Dockerを用いて独自環境を構築してみることに。
FROM public.ecr.aws/lambda/python:3.9
COPY ./ ${LAMBDA_TASK_ROOT}
RUN yum -y install poppler-utils adobe-*
RUN pip3 install pdf2image --target ${LAMBDA_TASK_ROOT}
CMD [ "lambda_function.lambda_handler" ]
上記の2行のRUNコマンドで、PDFから画像への変換に必要なライブラリとフォントのインストールを行っています。
初めから実行環境にインストールしておけるので、Lambda Layerを利用する必要はなくなりました。
上記のDockerfileを基に独自に構築した環境で動くLambda関数を作成します。
詳細なデプロイ方法については、以下のAWS公式ドキュメントをご参照ください。
こうやって構築したLambda関数で、フォントが埋め込まれたPDFの変換を行うと、文字が消えることなく無事に画像ファイルを生成することができました。
まとめ
AWS LambdaはAWSでサーバーレスアーキテクチャを構築する際のコアとなるサービスです。
ただ、AWSが用意した環境をそのまま使うだけでは、汎用的に利用できるがゆえに、様々な開発ニーズを満たせない場面が多々出てくるかと思います。
そんな場合は、コンテナイメージを利用することで、個別の開発ニーズに最適な環境でサーバーレスアーキテクチャを構築できます。
Discussion