タスク管理ツールをZenHubからJiraに移行しました
はじめに
こんにちは、エビリーでmillvi開発部の部長をしている長谷川です。
今回は、millvi開発部で利用しているタスク管理ツールの話をしたいと思います。
ZenHubからJiraに移行しました
世の中にはタスク管理ツールは色々ありますよね。
私がエビリーに入社した当時から、タスク管理ツールはZeHhubを利用していました。
ですが、今年の1月にJiraに引っ越しました。
ちなみに、エビリーでは以下の資料にあるツールを利用してます。(Jiraの記載がないですけど使ってます。ZenHubはもう使ってません。)
Jiraに移行した理由
Jiraに移行した理由をいくつか挙げてみます。
- kamui tracker開発部がJiraを使っており(2022年夏ごろにJiraを利用開始)、millvi開発部のメンバーからもJiraを使いたいという要望が多数あがっていた。
- ZenHubは課題一覧表示ができないが、Jiraだと可能。
- 事前にJiraを触ってみて、ZenHubよりも使いやすいと判断。(私自身はJiraを初めて使います。)
- 最近、ZenHubの画面表示に以前に比べて時間がかかるようになってきた。
移行の流れ
Jira側にCSVから課題を一括登録する機能があったので、GitHub/ZenHubのデータをCSVにすれば移行作業は難しいものではないです。
どちらかといえば、移行作業よりもJiraをどのように利用するかといった、Jira運用イメージの方が大事です。
細かいことは割愛しますが、大きく以下の流れで移行しました。
1. GitHubとZenHubのAPIを利用して、ZenHubに登録済みのチケットをCSVに出力する。
- 利用したAPIは以下の2つ。
https://api.github.com/repos/:user_name/:repo_name/issueshttps://api.zenhub.com/p1/repositories/:repo_id/issues/:issue_number
- GitHubAPIでissueを取得し、ZenHubAPIをissue毎に実装してZenHub側の情報(パイプライン、ストーリーポイント、EPIC等)を取得。
-
ZenHubAPIを実行するときは、適度にsleepを仕込んで上げないと、ZenHubのAPIが正常に値を返してくれなかった。適度なsleepは大事!
- 体感でsleepなしだと20-30%程度は値が返ってこない
- 0.5秒くらいsleepを入れれば100%値が返ってきた
- JiraがCSVで一括登録できることは事前に調べていたので、必要な情報をピックアップしてCSVに含めた。
2. Jiraの標準機能を利用して、CSVから課題を一括登録する
- CSVを読み込んだ後にCSVの項目とJiraの項目をマッピングできるので、特に問題なく登録完了。
- 1回で登録できる件数に上限があったので、複数ファイルに分けて登録実施。
ZenHubとJiraのメリット/デメリット(個人の意見です)
ZenHubの良いところ:
- GitHubとの連携部分。データ自体はGitHubにあるので、ZenHubを使わなくなった場合(解約した場合)でも、GitHubを使い続けている限り、過去のデータはGitHubに残る。なので、データ移行といったことを考えなくてもOK。
ZenHubの使いづらいところ:
- ボード表示がメインなので、課題を一覧で見たいと思っても見れない。
- 課題の量が増えてくると、フィルターを駆使しないと全量を把握するのが大変。地味に使いづらい。
Jiraの良いところ
- ボードの表示が直近のスプリントの課題だけに限定されているので、着手中の課題の状況を把握しやすい。
- JQLをうまく活用すれば、必要な情報を手軽に取得できる。
- アトラシアン製品との親和性が非常に高い。Confluenceを一緒に利用しているが、とても使いやすい。
- Confluenceはコラボレーションツール。ドキュメント管理やナレッジ共有など様々な用途に使える。10名以下であれば無料枠内で利用可能。
- Googleスプレッドシートのアドオン(Jira Cloud for Sheets)を活用して、タスク管理まわりの分析が良い感じにできる。
- GitHubと連携可能
Jiraの使いづらいところ:
- 今のところ、特になし!
Jiraの設定
まだまだ勉強中ですが、以下のような設定を入れてます。
課題タイプ
millvi開発では、初期の課題タイプに加えて「QA」「問い合わせ」「課題」を追加してます。
課題のフィルターや分析する際に活用できてます。
また、フィールドは色々と追加してます。(チームで業務を進める上で、この情報があれば便利になるだろうなという観点で追加しています。)
ちなみに、date関連(開始日時/レビュー依頼日時/完了日時)は自動セットされるようにしています。

自動化
ステータスを変更したら、開始日時/レビュー依頼日時/完了日時を自動セットしたり、GitHubと連動してパイプラインを変更したり、といったものを自動化してます。
例えば、課題のステータスをTODOから進行中に変更した時に、課題のStart dateに日時をセットする場合は、以下のようなルールを作ります。
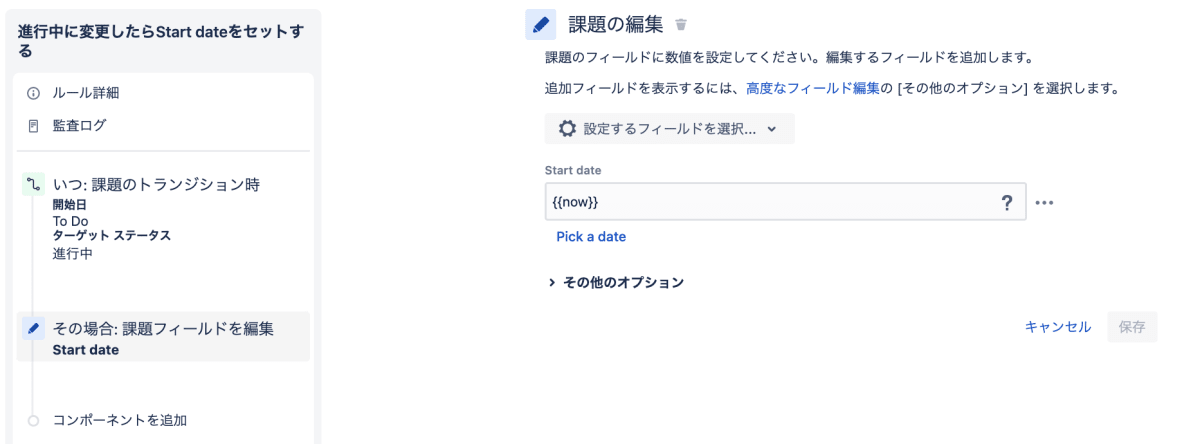
同様に、課題のステータスをレビューに変更すればreview request dateに日時をセットしたり、完了に変更すればEnd dateに日時をセットしています。
手軽にいろんな自動化ルールが作成できるので、時間がある時に色々と触ってみようと思ってます。
カスタムフィルター(JQL)
JQLとは、Jira Query Languageの略称です。JQLを使いこなせれば課題の状況確認がかなり楽になります。
よく使うJQLは保存しておくことですぐに利用することが可能です。
JQLを活用することで、課題に追加した色々なフィールドが役立ってきます。
使ってみて便利だなと思うJQLを少し紹介します。
最近追加された課題の確認
millvi開発チームでは、バグ/課題などは気づいた人がいつでもJiraに課題として登録するルールになってます。
その時のルールは、エピックに課題(未分類)を設定しておくことです。
そして毎日実施しているデイリーミーティングの中で、課題(未分類)かつ担当者が未設定の課題をフィルターして、対応方針/対応時期/対応者の決定を行なっています。
JQLはこんな感じです。
project = プロジェクトID AND parent = 課題(未分類)のエピックID AND assignee = EMPTY AND created >= "-14d" ORDER BY created ASC

レビューになってから一定時間経過している課題の確認
millvi開発チームでは、実装したメンバー以外がコードレビューを実施しています。
しかし、レビューを依頼されても忘れてしまうこともあります。
その対策として、以下のようなJQLでレビュー依頼日から一定の時間が経過した課題を取得して、デイリーミーティングで確認しています。
project = プロジェクトID AND status = レビュー AND "review request date" <= "-5d"
5日以上レビューのままの課題を確認してます。ここでクエリに利用しているreview request dateは自動セットしている値です。
Confluenceを利用している場合は、ちょっと便利な情報です。
Jiraで課題を検索すると、クエリ情報がURLにGETパラメータ化されてます。
なので、検索後のURLをコピーしてConfluenceのページに貼り付けると、ページ内に課題の検索結果一覧が埋め込まれて表示されます。これは地味に便利です。
ページ内に複数埋め込むことができるので、以下のような使い方もできます。

集計はGoogleスプレッドシートで
JQLでは集計が難しいです。
Jiraのダッシュボードと組み合わせれば簡単なことはできますが、数値の集計などは出来ないです。(私の実力不足かもしれませんが。)
ストーリーポイントベースで状況が知りたいということがよくあるのですが、EPIC毎の進捗はどうなってるの?とか、今のsprintの個人毎の進捗はどうなっているの?とか、全体スケジュールを把握/調整する上で知りたい情報が色々あったりします。
そこで役立つのが、Jira Cloud for Sheets です。
Jiraの課題をGoogleスプレッドシートに出力してくれるツールになります。
スプレッドシートであれば、集計は好きなように出来ちゃいますね。
Jiraから最新の課題を出力するシートを1つ準備しておき([A])、そのシートをベースに集計するシートを別途準備しておけば、必要な時に[A]を最新にするだけで、現時点の集計情報が取得可能となります。
まとめ
結果として、millvi開発部ではタスク管理ツールをZenHubからJiraに移行して、以前よりも色々と便利になりました。
チームメンバーの作業状況が以前よりも見えやすくなったり、課題管理もやりやすくなったり、自動化の活用が進んだりと、チーム開発が進めやすい環境になってきてます。
まだJiraを使い始めたばかりなので、他にも色々な活用方法がありそうです。
エビリーのプロダクトや組織について詳しく知りたい方は、気軽にご相談ください。
Discussion