はじめに
こんにちは。株式会社EVERSTEELでソフトウェアエンジニアをしているebikenです。
本ブログでは2025年4月から取り組んでいるオブザーバビリティ改善プロジェクトについて紹介します。
EVERSTEELについて
弊社では鉄スクラップの画像解析を行う「鉄ナビ検収AI」というプロダクトを提供しています。鉄鋼会社やリサイクル会社のスクラップヤードに取り付けたカメラにより鉄スクラップを撮影し、AIにより等級判定や異物検出を自動で行うアプリケーションの開発を行っています。
対象読者
- システム運用で監視やオブザーバビリティに課題を感じている方
「システムが複雑になってきて、何が起きているのかわからない」
「障害が発生しても、原因特定に時間がかかってしまう」
システム運用においてこのような悩みを抱えているチームは多いのではないでしょうか。我々も同様の課題に直面し、オブザーバビリティの改善に取り組んできました。このブログが同じ課題を抱えている方々の参考になれば幸いです。
オブザーバビリティとは
まず簡単に オブザーバビリティ (Observability, 可観測性)について紹介します。
オブザーバビリティとは、システムの状態を外部からの観測で把握する能力を示す指標、あるいはその仕組みのことです。異常が発生した時に、その異常が どこで、何が、なぜ 発生したのかを把握するためにはオブザーバビリティ非常に重要です。適切な情報を適切な方法で収集していくことで、システムの内部状態を解像度高く外部から理解できるようになります。
なぜオブザーバビリティが重要なのか
オブザーバビリティを整備することで、以下のようなことが可能になります。
- 現状把握: 今サービスで何が発生しているのか(リクエストがどれくらい来ているのか、どのようなエラーが発生しているのか、システムのリソースをどれくらい消費しているのか)を把握できる
- 迅速な検知: いち早く問題に気づき、影響が拡大する前に対処できる
- 迅速な障害対応: 問題発生時に、状況を把握し原因を特定するまでの時間を短縮できる
- パフォーマンス改善: パフォーマンスに問題があるシステムに対して、ボトルネックを特定しやすくなる
- 品質の定量化: システムの稼働時間やエラーが発生していた時間が可視化されると、SLI/SLOベースでの信頼性評価が可能になる
参考
- Observability入門 - OpenTelemetry
- オブザーバビリティ(可観測性)の概要 - splunk
- 入門 監視
- What Is Observability & How Does it Work? - Datadog
チーム構成、技術スタック
2025年4月当時のチーム構成や技術スタックなど前提を共有します。
- チーム規模: (ほぼ)フルタイムのエンジニア3名 + 副業エンジニア数名
- 言語: TypeScript (backend: Node.js + NestJS, frontend: Next.js)
- クラウド環境: AWS (ECS, Lambda, Aurora MySQL)
- オンプレ環境: 工場に設置されたサーバーで基幹システム連携、カメラ撮影、画像処理などを行う
- オブザーバビリティ関連ツール:
- ログ: CloudWatch Logs
- メトリクス: CloudWatch にデフォルトで記録されるもののみ (ECS, Lambda, Aurora MySQL など)
- アプリケーションエラー管理: Sentry
- アラート: なし
- トレース、プロファイラ: なし
- ダッシュボード: なし
アーキテクチャの概要
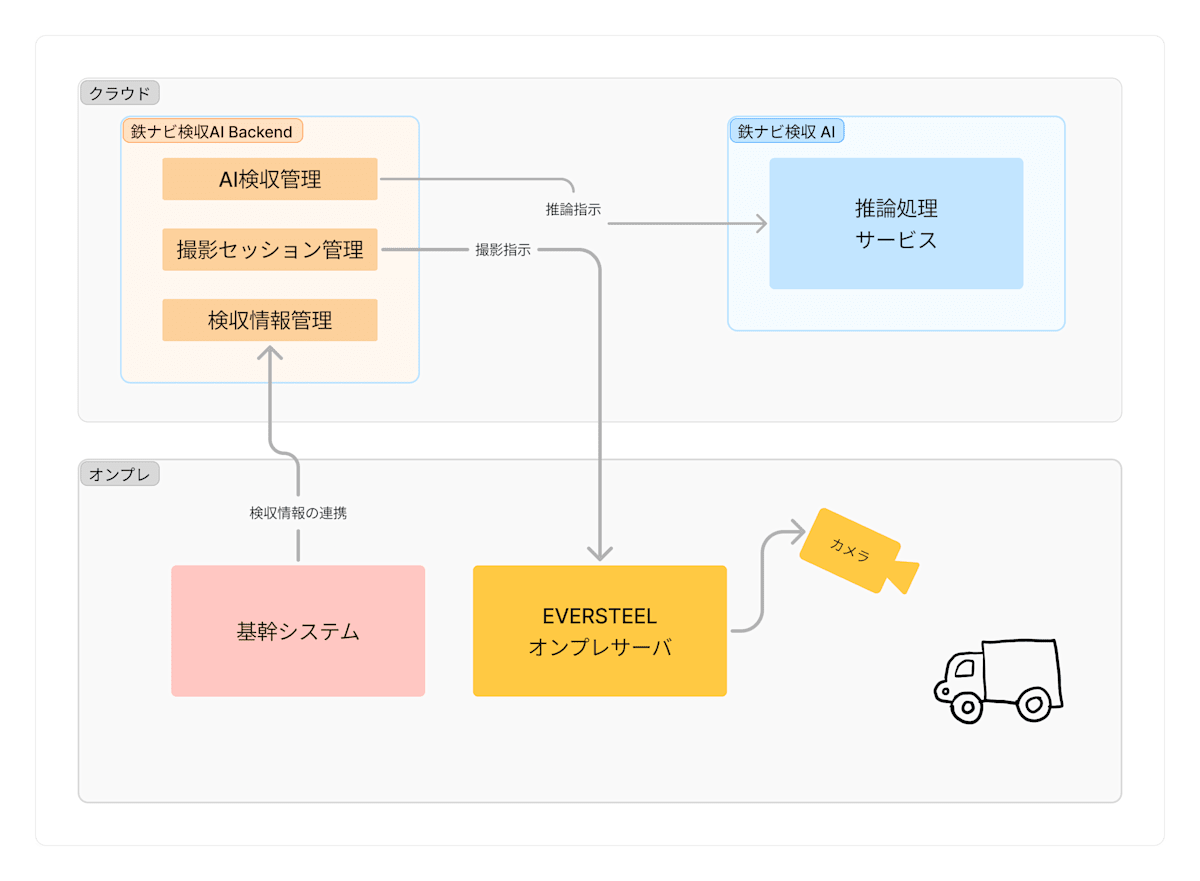
アーキテクチャの詳細については先日公開された弊社の knagiri の記事をぜひご覧ください。
「鉄ナビ検収AI」のアーキテクチャを紹介します!
また、自分はこれまで Google Cloud に触れる機会が多く、AWSについては比較的歴が浅いです。今回の内容で、もっとこういうサービス、アーキテクチャにすると良い、この使い方は注意した方が良い、などあればぜひコメント等で教えていただけると嬉しいです。
抱えていた課題
当時我々のシステムでは以下の課題を抱えていました。
問題の検知に時間がかかる
- Sentry でアプリケーションエラーを記録していたが、大量にエラーが溜まっていて管理できていない状態だった
- CloudWatch Logs に記録されたエラーログを Slack にそのまま流して確認するフローになっており、相対的に数が少ないエラーが埋もれることがあった
- お客様からの問い合わせによって問題が発生していることに気づくこともあった
障害が起きても原因特定に時間がかかる
- エラーメッセージが不十分で、根本原因の特定に時間がかかっていた
- リクエストに紐づくログを簡単に探す方法がなく、関連するログを見つけるには近い timestamp のログを頑張って探していた
- 実装を把握している人にとってはどこで問題が起きているのか推測できるが、関連する実装に詳しくない人にとっては難しかった
- 問題によっては、お客様に直接聞かないと何が起きているのかわからなかった
パフォーマンス悪化の把握、原因特定が難しい
- 変更によってAPIのレイテンシが高まってしまった時、普段から頻繁にその機能を使っている人が触って初めて気づく状態だった
- APIのレイテンシを計測するには、リクエストのログの timestamp から計算するしかなかった
- パフォーマンスの問題が発生した際、どの処理がボトルネックになっているのか調査が難しかった
ビジネス要求の高まり
鉄ナビ検収AIは数年間にわたってPoC期間を重ねてきました。顧客数やAPIリクエスト数が比較的少なかったため、これまでは課題を抱えながらも対応できていました。しかし、導入社数の増加などプロダクトが拡大フェーズに入っており、今後多くのお客様に安心してご利用いただくためには、システムの信頼性向上が不可欠となってきました。
改善プロジェクトの進め方
優先順位を決める
オブザーバビリティを構成する3つの要素 (The three pillars of observability) として、Logs (ログ), Metrics (メトリクス), Traces (トレース) が挙げられます。限られたリソースの中で迅速かつ効果的に改善を進めるために、その3要素を参考にしつつ、今回は以下の流れで取り組みました。
※ 実際には同時並行で進められるものもあったため必ずしもこの順番通りに導入したわけではありません。
1. データの記録
- ログ: 適切なログレベルの設定、必要な情報を追加、検索性の向上
- メトリクス: サービスの状況把握に必要なメトリクスの作成
- アプリケーションエラーの記録: Sentry に溜まっているエラーの整理
2. 問題の検知
- アプリケーションエラー: アラートのトリガー条件見直し、対応フローの整備
- アラート: 対応が必要なものに絞ってアラートの通知を行う基盤の整備
3. 原因の特定をサポート
- トレース: パフォーマンス問題が発生している際にボトルネックの調査に役立つツールの導入
- プロファイラ: CPU, Memory ヘビーな処理のボトルネックを調査に役立つツールの導入
- フロントエンドのユーザー行動解析ツール: 実際にユーザーがどのような状況なのか把握できるツールの導入
- メトリクスダッシュボード: サービスの状態の全体感を簡単に確認できるダッシュボードの作成
※フロントエンドのユーザー行動解析ツールに関しては、システムの内部状態を可視化するためのツールという位置付けには適切ではないかもしれませんが、ユーザー体験の全体像やエラー発生前後の操作内容の把握などに役立つため今回のプロジェクトに含めています。
参考
実際にやったこと
全て詳しく書いていくと膨大な量になるので、今回は最初に優先度高く取り組んだデータの記録と問題の検知にフォーカスして紹介します。
※ これから紹介する内容は一部、環境や使い方によっては導入したことでかなりコストが嵩んでしまう可能性があるものも含むため、導入する前にはコストを確認するようにしてください。
ログの改善
まずはデータを記録しなければ始まらないため、ログの改善から着手しました。
必要な情報の追加
リクエストの interceptor や middleware で出力しているリクエストログに以下の情報が含まれるようにしました。
- リクエストのコンテキストやメタデータ
- リクエスト/レスポンスの中身
- ステータスコード
- 処理のレイテンシ
- リクエストを受け取った timestamp
- ログを出力した timestamp
- エラーが発生した場合のエラー内容 (ユーザーに返したメッセージ、内部のエラー、スタックトレースなど)
上記に加え、リクエストログに限らず全てのログにテナントIDやリクエストID(APIリクエストごとに発行する一意なID)を付与し、CloudWatch Logs 上で関連するログをまとめて閲覧できるようにしています。
注意点
ログにリクエスト/レスポンスの中身やヘッダーなどを出力する際、ログに秘匿情報が含まれないように注意が必要です。我々のシステムでは秘匿情報がそれらに含まれているのが数カ所だったため、簡単な対応で済みました。
また、画像など巨大なバイナリデータをログに出力することも避けた方が良いです。サイズによってはCPUやメモリへの負荷が大きくシステム全体に影響を与える可能性があります。
構造化
これまでテキスト形式だったログを、フォーマットを定めてJSONで構造化しました。(正確には一部構造化されているものもありました)
テキスト形式のログでは、基本的に正規表現や部分一致による検索しかできません。構造化して出力することで自動でパースして表示されるようになりますし、request.body.x_idのようにフィールド指定してログを絞り込めるようになります。これは日常のログ検索時に非常に便利であり、後述するメトリクス作成時にも大いに役立ちます。
参考
- AWS Observability Best Practices - Logs
- Accelerate troubleshooting with structured logs in Amazon CloudWatch
ログレベルの統一
適切なアラート通知を実現するため、チーム内でログレベルの基準を統一し、それに沿った形で実装を進めました。
| レベル | 用途 | アラートの設定 | 開発者の対応 | 出力例 |
|---|---|---|---|---|
| DEBUG | ローカル環境でのデバッグ | しない | 不要 | モジュールのロード DBクエリの実行内容 その他ローカルでの開発に有用な一時的な出力 |
| INFO | 処理の内容やイベントを記録する | しない | 不要 | 成功レスポンスを返すリクエストログ アプリケーションの処理 外部サービスとの通信内容 |
| WARN | 問題を起こした可能性があるイベントを記録する | 状況によっては通知する | 不要 | 失敗レスポンスを返すリクエストログ 外部サービスとの通信が失敗した |
| ERROR | 問題が起きたことを記録する | 通知する | 即時に対応する必要がある | 想定していないデータの不整合によるエラー |
| FATAL | プロセスを中断させるレベルのクリティカルな問題を記録する | 通知させる | 緊急で対応する必要がある | アプリケーションを起動できない プロセスを中断せざるを得ない |
参考
メトリクスの記録
システムメトリクスの追加
弊社ではECS、Aurora MySQLなどAWSマネージドサービスを使用しているため、デフォルトである程度のメトリクスは CloudWatch に記録されています。しかし、一部のメトリクスは明示的に有効化しないと記録されません。設定を有効化するだけで導入が非常に簡単であり、有効化による追加コストも軽微であったため、ECS Container Insights と Aurora Performance Insights を有効化しました。
参考
- Amazon CloudWatch - User Guide - Container Insights
- Amazon RDS - User Guide for Aurora - Monitoring DB load with Performance Insights on Amazon Aurora
CloudWatch Logs メトリクスフィルターによるメトリクスの作成
CloudWatch に標準で記録されるメトリクスで、システムリソース(CPU, Memory, Network など)の監視は概ね可能でした。しかし、システムリソースのメトリクスだけでは、我々のサービスにおいてはシステムの状態を十分に把握することができません。追加で以下のメトリクスが必要でした。
- リクエスト数
- エラー発生回数
- レイテンシ
これを監視する手法は RED Method (Rate, Errors, Duration) と呼ばれており、ユーザーが直接触るWebサービスのようなシステムにおいてはこの3つの指標がユーザー体験に直結するため、まず監視すべき指標として知られています。近い概念として、Latency、Traffic、Errors、Saturation を「The Four Golden Signals」と呼ぶものも存在します。
前述した構造化ログの対応とログフィールドの整理により、必要な情報がログに含まれるようになったため、ログからメトリクスを作成できる CloudWatch Logs のメトリクスフィルター機能を利用し、上記の3種類のメトリクスを作成しました。また、メトリクスフィルターには dimension と呼ばれる任意のメタデータを付与することができます。HTTP Method + URL (加えて GraphQL を採用しているため query/mutation の名前も含む) などを付与し、APIごとに各種メトリクスを確認できるようにしました。
参考
- Amazon CloudWatch - User Guide - Creating metric filters
- Splunk - RED Monitoring: Rate, Errors, and Duration
- Grafana - The RED Method: How to Instrument Your Services
- Google SRE Books
アラートの設定
メトリクスの作成によってシステムの状態を把握できるようになったため、次のステップとしてアラートの設定に取り組みました。具体的な設定方法については本ブログでは言及しませんが、以下のサービスを利用して Slack に通知が送信されるように設定しました。
- CloudWatch alarms
- Amazon SNS (Simple Notification Service)
- Amazon Q Developer (旧 AWS Chatbot)
アラートの設定において重要なのは、実際にアクションが必要なものに絞って設定することです。ユーザーが実際に問題に遭遇していることを適切に検知することが重要なので、サービスの状況が悪化してユーザーに不利益をもたらしている状態もしくは、そのような状況に陥る可能性が高い時に通知されるよう設定します。アクションの必要がないアラートが多すぎると、所謂アラート疲れ (Alert Fatigue) やオオカミ少年のような状態になってしまいます。アラートが鳴っていることが常態化し、実際にアクションが必要なアラートを見逃してしまう可能性があります。
具体的にはまず以下の2つの指標に絞ってアラートを設定しました。どちらも前述のメトリクスフィルターで作成したメトリクスを利用しています。
- エラー発生数が閾値を超えた (例: 10件以上のエラーが発生した)
- レイテンシが閾値を超えた (例: p95レイテンシが3000msを超えた)
最初はメトリクスが存在せず閾値を定めるだけの情報が足りなかったため、最初は決めうちで閾値を決めてから徐々に適切な値へと調整していきました。また、処理の性質に応じて異なる閾値を設定しているものや、一部のAPIでは重い処理を許容しているためにアラートの対象から除外するなどの細かい調整も行いました。
従来はエラー発生数に関してはエラーログの流量や内容を確認したり、お客様からの問い合わせによって問題に気づいていた状況でしたが、このアラートの設定により閾値を超えると即座に Slack に通知が送信されるようになり、問題を迅速に検知できるようになりました。レイテンシに関しても、従来は直接アプリケーションを操作して感覚的に確認していたところが、悪化したことをシステム的に迅速に検知できるようになりました。
参考
- AWS Observability Best Practices - Alarms
- Using Amazon CloudWatch alarms - Amazon CloudWatch
- Understanding Alert Fatigue & How to Prevent it
アプリケーションエラーの管理
メトリクスベースのアラートだけでは見逃す可能性があるエラーも存在します。例えばエラー率にアラートを設定している場合、1件のみ発生したエラーが閾値に達せず検知できない場合や、1000件のうち10件だけ発生したエラーが埋もれてしまい気づけないといった問題が発生する可能性があります。そのような問題を適切に検知/管理するため、Sentry を使用してアプリケーションで発生しているエラーを管理しています。
参考
既存エラーの整理
Sentry は以前から導入されていたものの、十分に活用されていませんでした。Issue(発生した問題のことを Sentry 上ではそう呼びます)が大量に溜まって放置されており、どれが確認済みで放置されているエラーなのか、未知のエラーなのかが判別できない状態でした。まずはこの状況を整理しないと、サービスでどのような問題が発生しているのかを把握することができないため、非常に泥臭い作業ですが、backend/frontend 合わせて数百件あった Issue を一つ一つ、必要に応じて状況に詳しいメンバーに背景を確認しつつ整理していきました。
具体的には以下のように分類しています。
- 解決済み → Resolve (再発したら Sentry から通知される)
- 対応中 → 既存のタスクに紐付けて対応
- ネットワークの問題など一時的な問題のため対応が不要 → Archive (通知されなくなる) もしくは、実装側で Sentry に送らないようにする
- 発生していることを認識していなかった → タスク化して対応
エラー情報の充実
アラートが発生した際に円滑に調査を進められるように以下の情報をエラーに紐づけるようにしました。
- リクエストID
- テナントID
- ユーザー情報などメタデータ
リクエストID(前述のログ改善のところで紹介した、リクエストごとに必ず発行される一意のID)を付与することで、エラーが発生したリクエストの関連するログを簡単に確認できるようになります。
参考
運用フロー
まだ運用が本格化していない段階で最初から仕組みを作り込んでも継続が難しいので、現在は以下のようなシンプルなフローで運用しています。
- 新規/再発エラーが検出されると即座に Slack にメッセージが送信される
- 運用を担当しているメンバーがまず確認し、優先度と担当者を決定する。即時対応が必要なものは迅速に対応し、そうでないものはタスク化する
- 定期的に進行状況を確認する
これまで Sentry のエラーに対して確認する習慣がなかったため、定着するまでは自分が積極的にメンションして確認を促すようにしたり、定期的に確認が漏れているものがないかチェックするといったことも行っています。
その他の取り組み
ここまで紹介してきた内容の他にも様々な細かい対応を入れています。例えばログに関しては CloudWatch Logs への出力方法の修正やロググループ名の整理、ログ出力内容のフィルタなど様々な実装/修正を入れています。
本ブログでは特に優先度高く取り組んだデータの記録と問題の検知の改善について紹介しましたが、問題を検知した時の原因特定が楽になるように以下の仕組みも導入済み、または現在導入を進めているところです。
- トレース: AWS Distro for OpenTelemetry を利用してトレースを AWS X-Ray に記録
- メトリクスダッシュボード: CloudWatch 上にダッシュボードを作成
- フロントエンドのユーザー行動解析ツール: Amplitude の導入
また、オブザーバビリティは一度整備したら終わりではなく、サービスの状況やチーム構成など様々な状況に合わせて継続的に改善していく必要があります。引き続き信頼性の高いサービス運用に取り組んでいきます。
参考
最後に
オブザーバビリティはシステムの信頼性向上や障害対応の効率化に大きく貢献します。プロジェクト初期からある程度整えられているとかなり運用が楽になると思いますが、そのようなプロジェクトは決して多くはないと感じています。PoCの実装の延長で開発が進んでいた、初期フェーズでは運用の経験が浅いメンバーが担当していた、リリースまでの期間が極端に短かったなど、様々な背景があるかと思います。
ですがオブザーバビリティへの投資は複利で効いてくるものです。プロダクトが成長フェーズに入り運用負荷が高まってきている時(できればその前)には、ぜひオブザーバビリティの改善に取り組んでみてください。このブログが同じような課題を抱えている方の参考になれば幸いです。

Discussion