Claude Prompt Cachingは本当に効果的なのか検証してみた
Prompt Cachingとは
2024年8月15日、Anthropic APIに新機能「Prompt Caching」が追加されました。この機能により、コンテキストをキャッシュできるようになりました。反復的なタスクや一貫した要素を持つコンテキストのコストと応答遅延の大幅な削減に寄与することが期待できます。
ドキュメントによると、コストを最大90%削減、応答遅延を最大85%短縮できることが示されています。
本記事では、Prompt Cachingの基本的な使い方と、実際にコスト削減および応答速度の向上にどの程度貢献するのかを検証していきます。
基本的な使い方
以下は、Messages APIでのPrompt Cachingの実装例です。
import anthropic
client = anthropic.Anthropic()
response = client.beta.prompt_caching.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=1024,
system=[
{
"type": "text",
"text": "あなたは日本の童話に詳しいAIアシスタントです。",# キャッシュされる
},
{
"type": "text",
"text": "<'桃太郎全文'>",# キャッシュされる
"cache_control": {"type": "ephemeral"} # キャッシュを有効にする
}
],
messages=[
{"role": "user",
"content": "桃太郎を要約して" # キャッシュされない
}
],
)
print(response)
cache_controlパラメータを使用してプロンプトをキャッシュします。
この例ではsystemの先頭からcache_controlブロックまでのシステムプロンプトをキャッシュしています。
これにより次のAPI呼び出しから再利用できるので、大きなプロンプトを毎回再処理することがなくなるため応答が速くなります。また、キャッシュから読み出した際の入力トークンのコスト削減に貢献します。
キャッシュを作成する際は、通常の入力トークンより25%多くのコストがかかりますが、一度キャッシュすると次回以降のAPI呼び出しでは通常の入力トークンと比べて90%低コストで再利用できます。
なお、出力トークンに対しては通常通りのコストが掛かります。
料金
| モデル | 入力トークン数 | キャッシュ書き込みトークン数 | キャッシュ読み込みトークン数 | 出力トークン数 |
|---|---|---|---|---|
| Claude 3.5 Sonnet | $3 / MTok | $3.75 / MTok | $0.30 / MTok | $15 / MTok |
| Claude 3 Haiku | $0.25 / MTok | $0.30 / MTok | $0.03 / MTok | $1.25 / MTok |
| Claude 3 Opus | $15 / MTok | $18.75 / MTok | $1.50 / MTok | $75 / MTok |
キャッシュ書き込みは入力トークンより25%高価、キャッシュ読み取りは入力トークンより90%安価になります。
仕様
サポート
現在(2024/9/3)は以下のモデルをパブリックベータ版でサポートしています。
Claude 3.5 SonnetClaude 3 HaikuClaude 3 Opus
キャッシュできるパラメータ
toolssystemmessages
tools -> system -> messageの順番でキャッシュが参照されます。
最小トークン数
キャッシュ対象となるコンテキストが最小トークン数未満の場合、キャッシュは行われません。マルチターンの会話においては、トークン数が最小トークン数を超えた時点で初めてキャッシュが有効になります。
| モデル | 最小トークン数 |
|---|---|
| Claude 3.5 Sonnet | 1024 |
| Claude 3 Opus | 1024 |
| Claude 3 Haiku | 2048 |
キャッシュの参照
レスポンスよりusageオブジェクトの各プロパティから参照できます。
usage.cache_read_input_tokensusage.cache_read_input_tokens
キャッシュの期限
"cache_control": {"type": "ephemeral"}
現在はephemeralパラメータのみがサポートされており、キャッシュの有効期限は5分です。将来的には、長時間の有効期限を持つパラメータにも対応する可能性があるかもしれません。
- キャッシュにアクセスが無いまま5分経過した場合に削除されます。
- キャッシュにアクセスがあった場合、期限は更新されます。
- キャッシュしたコンテキストを書き換えた場合に削除されます。
上記以外でキャッシュをクリアする方法は現在はありません。
ブレークポイント
cache_controlブロックは4つまで使用できます。
マルチターンの会話において、各ターンでcache_controlブロックを実装すると、すぐに上限の4つに達してしまいます。そのため、効果的にキャッシュを管理するためには工夫が必要です。
Prompt Cachingによる応答速度向上の効果検証
Prompt Cachingによる応答遅延の削減効果を検証します。
コストを考慮し、使用するモデルは Claude 3 Haiku とします。キャッシュなしとキャッシュありの状態で、それぞれの応答速度を比較検証します。なお、今後他のモデルについても順次検証する予定です。
検証には、Project Gutenbergより「高慢と偏見」の全文(187,336トークン)取得し、それをシステムプロンプトとして使用します。このプロンプトに基づく質問をAPIに投げ、各応答時のレイテンシを測定します。
コード
Project Gutenbergより「高慢と偏見」(187,336トークン)をスクレイピング
import requests
from bs4 import BeautifulSoup
def fetch_article_content(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Remove script and style elements
for script in soup(["script", "style"]):
script.decompose()
# Get text
text = soup.get_text()
# Break into lines and remove leading and trailing space on each
lines = (line.strip() for line in text.splitlines())
# Break multi-headlines into a line each
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
# Drop blank lines
text = '\n'.join(chunk for chunk in chunks if chunk)
return text
# Fetch the content of the article
book_url = "https://www.gutenberg.org/cache/epub/1342/pg1342.txt"
book_content = fetch_article_content(book_url)
print(f"Fetched {len(book_content)} characters from the book.")
print("First 500 characters:")
print(book_content[:500])
API実行
import anthropic
import time
client = anthropic.Anthropic(api_key=API_KEY,)
def make_non_cached_api_call():
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text":book_content,
"cache_control": {"type": "ephemeral"} # キャッシュなしの場合はコメントアウト
},
{
"type": "text",
"text": "本のタイトルは何? タイトルのみ出力してください。"
}
]
}
]
start_time = time.time()
response = client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=300,
messages=messages,
extra_headers={"anthropic-beta": "prompt-caching-2024-07-31"}
)
end_time = time.time()
return response, end_time - start_time
non_cached_response, non_cached_time = make_non_cached_api_call()
print(f"Non-cached API call time: {non_cached_time:.2f} seconds")
print(f"Non-cached API call input tokens: {non_cached_response.usage.input_tokens}")
print(f"Non-cached API call output tokens: {non_cached_response.usage.output_tokens}")
print("\nSummary (non-cached):")
print(non_cached_response.content)
測定結果
キャッシュなし
| 回数 | 入力トークン数 | 出力トークン数 | 応答速度(s) |
|---|---|---|---|
| 1 | 187362 | 8 | 3.09 |
| 2 | 187362 | 8 | 3.20 |
| 3 | 187362 | 8 | 2.89 |
| 4 | 187362 | 8 | 2.49 |
| 5 | 187362 | 8 | 3.12 |
キャッシュあり
| 回数 | 入力トークン数 | キャッシュ書き込みトークン数 | キャッシュ読み取りトークン数 | 出力トークン数 | 応答速度(s) |
|---|---|---|---|---|---|
| 1 | 26 | 187336 | 0 | 0 | 2.35 |
| 2 | 26 | 0 | 187336 | 8 | 3.28 |
| 3 | 26 | 0 | 187336 | 8 | 2.17 |
| 4 | 26 | 0 | 187336 | 11 | 2.83 |
| 5 | 26 | 0 | 187336 | 8 | 3.09 |
比較結果

グラフを見る限り、キャッシュありとキャッシュなしの応答速度には有意な差が見られません。今回の検証では、入力トークン数が187,336で、モデルのコンテキストウィンドウ上限である200,000トークンに近い状態でした。Claude 3 Haikuは元々応答速度が速いモデルのため、キャッシュの有無による差が顕著に現れなかった可能性があります。
また、質問内容が本文全体を参照するようなケースでは、結果が異なる可能性もあります。
| モデル名 | 比較レイテンシ | コンテキストウインド |
|---|---|---|
| Claude 3.5 Sonnet | Fast | 200,000 |
| Claude 3 Haiku | Fastest | 200,000 |
| Claude 3 Opus | Moderately fast | 200,000 |
Prompt Cachingによるコスト削減効果の検証
Prompt Cachingによるコスト削減効果を検証します。
マルチターン会話(長いシステムプロンプトを伴う)でのやり取りにおけるトークン使用量を追跡し、キャッシュなしとキャッシュありの状態でそれぞれを比較します。これにより、Prompt Cachingがトークンのコスト削減にどれほど貢献するかを検証します。
コード
青空文庫より桃太郎(5811トークン)をスクレイピング
import requests
from bs4 import BeautifulSoup
def fetch_article_content(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Remove script and style elements
for script in soup(["script", "style"]):
script.decompose()
# Get text
text = soup.get_text()
# Break into lines and remove leading and trailing space on each
lines = (line.strip() for line in text.splitlines())
# Break multi-headlines into a line each
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
# Drop blank lines
text = '\n'.join(chunk for chunk in chunks if chunk)
return text
# Fetch the content of the article
book_url = "https://www.aozora.gr.jp/cards/000329/files/18376_12100.html"
book_content = fetch_article_content(book_url)
print(f"Fetched {len(book_content)} characters from the book.")
print("First 500 characters:")
print(book_content[:500])
マルチターンでの会話 API実行
※キャッシュなしの検証ではcache_controlをコメントアウトします。
class ConversationHistory:
def __init__(self):
# 会話ターンを保存するための空のリストを初期化
self.turns = []
def add_turn_assistant(self, content):
# 会話の履歴にアシスタントの発言を追加する
self.turns.append({
"role": "assistant",
"content": [
{
"type": "text",
"text": content
}
]
})
def add_turn_user(self, content):
# 会話の履歴にユーザーの発言を追加する
self.turns.append({
"role": "user",
"content": [
{
"type": "text",
"text": content
}
]
})
def get_turns(self):
# 特定の形式で会話ターンを取得する
result = []
user_turns_processed = 0
# 会話履歴の最新を取得するため逆の順序でターンを繰り返します。
for turn in reversed(self.turns):
if turn["role"] == "user" and user_turns_processed < 2:
result.append({
"role": "user",
"content": [
{
"type": "text",
"text": turn["content"][0]["text"],
"cache_control": {"type": "ephemeral"}# 最新のユーザー2件にブロックをつける。(過去のキャッシュを保持しつつ、最新のQAをキャッシュするため)
}
]
})
user_turns_processed += 1
else:
# 他のターンもそのまま追加
result.append(turn)
# ターンを元の順序に戻す
return list(reversed(result))
# 会話履歴を初期化する
conversation_history = ConversationHistory()
# 書籍のコンテンツを含むシステム メッセージ
system_message = f"<file_contents> {book_content} </file_contents>"
# シミュレーション用のあらかじめ定義された質問
questions = [
"この小説のタイトルは何ですか?",
"作者は誰ですか?",
"いつ作成されたものですか?",
"この小説の主なテーマは何ですか?",
"主人公の名前を教えてください",
"主な登場人物を教えてください",
"仲間の名前を教えてください",
"敵を教えてください",
"この物語で伝えたいメッセージはなんですか?",
"この小説の感想は何ですか?",
]
def simulate_conversation():
for i, question in enumerate(questions, 1):
print(f"\nターン {i}:")
print(f"ユーザー: {question}")
# ユーザーの入力を会話履歴に追加
conversation_history.add_turn_user(question)
# パフォーマンス測定のために開始時間を記録
start_time = time.time()
# アシスタントへのAPIコールを行う
messages=conversation_history.get_turns()
response = client.messages.create(
model=MODEL_NAME,
extra_headers={
"anthropic-beta": "prompt-caching-2024-07-31"
},
max_tokens=300,
system=[
{"type": "text", "text": "あなたは日本童話に詳しいAIアシスタントです。質問には簡潔に答えてください。"},
{"type": "text", "text": system_message, "cache_control": {"type": "ephemeral"}},# システムプロンプトをキャッシュ
],
messages=messages, # ユーザーの会話履歴からとってくる
)
# 終了時間を記録
end_time = time.time()
# アシスタントの返信を抽出
assistant_reply = response.content[0].text
print(f"アシスタント: {assistant_reply}")
# トークン使用情報を表示
input_tokens = response.usage.input_tokens
output_tokens = response.usage.output_tokens
input_tokens_cache_read = getattr(response.usage, 'cache_read_input_tokens', '---')
input_tokens_cache_create = getattr(response.usage, 'cache_creation_input_tokens', '---')
print(f"ユーザー入力トークン数: {input_tokens}")
print(f"出力トークン数: {output_tokens}")
print(f"入力トークン数 (キャッシュ読み取り): {input_tokens_cache_read}")
print(f"入力トークン数 (キャッシュ書き込み): {input_tokens_cache_create}")
# 経過時間を計算して表示
elapsed_time = end_time - start_time
# アシスタントの返信を会話履歴に追加
conversation_history.add_turn_assistant(assistant_reply)
# シミュレーションされた会話を実行
simulate_conversation()
結果
コスト削減に寄与する出力トークン数以外のトークン数です。
キャッシュなし 出力結果
| ターン | 入力トークン数 |
|---|---|
| 1 | 5875 |
| 2 | 5909 |
| 3 | 5941 |
| 4 | 6019 |
| 5 | 6147 |
| 6 | 6180 |
| 7 | 6366 |
| 8 | 6418 |
| 9 | 6484 |
| 10 | 6718 |
キャッシュあり 出力結果
| ターン | 入力トークン | キャッシュ書き込みトークン数 | キャッシュ読み取りトークン数 |
|---|---|---|---|
| 1 | 4 | 5860 | 0 |
| 2 | 4 | 34 | 5860 |
| 3 | 4 | 29 | 5894 |
| 4 | 4 | 85 | 5923 |
| 5 | 4 | 173 | 6008 |
| 6 | 4 | 35 | 6181 |
| 7 | 4 | 157 | 6216 |
| 8 | 4 | 88 | 6373 |
| 9 | 4 | 118 | 6461 |
| 10 | 4 | 318 | 6579 |
キャッシュあり 料金比に基づいたトークン数
料金表に基づき、入力トークンを基準にキャッシュ書き込みを1.25倍、キャッシュ読み込みを0.1倍として計算し、トークンの料金比に基づいたトークン数を算出します。
| ターン | 入力トークン数 | キャッシュ書き込みトークン数 | キャッシュ読み取りトークン数 | 合計トークン数 |
|---|---|---|---|---|
| 1 | 4 | 7325.00 | 0 | 7329.00 |
| 2 | 4 | 42.50 | 586.0 | 632.50 |
| 3 | 4 | 36.25 | 589.4 | 629.65 |
| 4 | 4 | 106.25 | 592.3 | 702.55 |
| 5 | 4 | 216.25 | 600.8 | 821.05 |
| 6 | 4 | 43.75 | 618.1 | 665.85 |
| 7 | 4 | 196.25 | 621.6 | 821.85 |
| 8 | 4 | 110.00 | 637.3 | 751.30 |
| 9 | 4 | 147.50 | 646.1 | 797.60 |
| 10 | 4 | 397.50 | 657.9 | 1059.40 |
コスト削減効果
キャッシュ使用の有無によるターン毎に加算した合計トークン数(料金比)を比較して、コスト削減効果を示します。
| ターン | 合計トークン数(キャッシュなし) | 合計トークン数(キャッシュあり) | コスト削減効果 (%) |
|---|---|---|---|
| 1 | 5875 | 7329 | -25 |
| 2 | 11784 | 7961.5 | 32 |
| 3 | 17725 | 8591.15 | 52 |
| 4 | 23744 | 9293.7 | 61 |
| 5 | 29891 | 10114.75 | 66 |
| 6 | 36071 | 10780.6 | 70 |
| 7 | 42437 | 11602.45 | 73 |
| 8 | 48855 | 12353.75 | 75 |
| 9 | 55339 | 13151.35 | 76 |
| 10 | 62057 | 14210.75 | 77 |
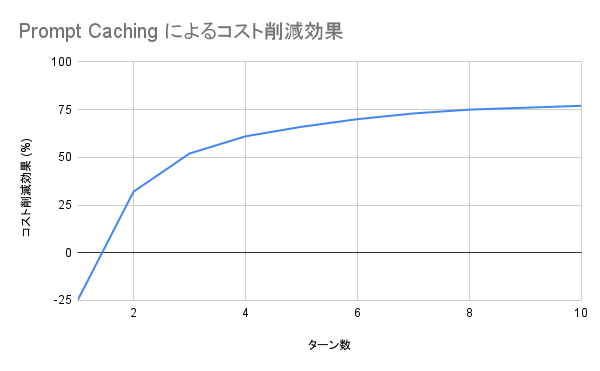
Prompt Cachingを有効にすると、1ターン目にはコストが25%増加しますが、2ターン目以降はコスト削減が見られ、10ターン目には77%のコスト削減が達成されました。
グラフからは、ターンが進むにつれてコスト削減効果が向上し、最終的には90%近い削減に達することが予測できます。
結論
応答遅延の削減
Claude 3 Haikuにおいては、応答速度の向上に関して有意な差は確認されませんでした。
コスト削減
入力トークンに対して、顕著なコスト削減効果が確認されました。
このことから、以下のようなケースで効果を実感できることが期待できます。
- 長文コンテンツの参照:ドキュメント、書籍や論文の内容をプロンプトに埋め込んでの参照
- 会話エージェント: 詳細な指示セット、長時間の会話やツール使用での反復的なAPI呼び出しによるトークンコストを削減
- コーディングアシスタント: 長いコードスニペットでのQ&A
Discussion