はじめに
皆さん、こんにちは! 永和システムマネジメントの久納です。
皆さんはChatGPTを使っていますか?
今更説明は不要かと想いますが、ChatGPTはGPTというOpenAIによって訓練された大規模言語モデルを使用したチャットベースのAIです。GPTは自己注意メカニズムを用いたTransformerというアーキテクチャに基づいて作成されおり、これにより入力データ全体の文脈を理解し、より精密な予測を生成することができるようになっています。
今回私達は、FDOという社内組織の活動として、このGPTのAPIを使用してなにか面白いものが作れないかと考え図1のようなぬいぐるみと会話ができるようにしてみました。
FDO(未来デザイン室)について
FDO(未来デザイン室)は永和システムマネジメント社内におけるソフトウェア開発の全社的な技術進歩を目的とする組織です。技術力のエビデンスづくり、新たな開発領域の探求、人材育成を目的として2020年度から特に機械学習分野のキャッチアップを中心として、1期毎にメンバーを変更しながら活動を続けてきました。
どんなものを作ったか

図1. 話すぬいぐるみ
前述の通り、トランスフォーマアーキテクチャを採用しているGPTは従来の自然言語モデルに比べ、入力データの全体的なコンテキストを捉えることを得意としており、さらに多言語対応しているので色々な使い道を考えることができます。そのため、GPTを利用する様々な便利なサービスの案を考えることができますが、今回私達はGPTと目的もなくただ会話ができるとどういう体験が得られのかという点に興味を持ち、それを実現してみました。
動画1. 実際に会話しているところ
どのようにしてこれを作ったか、作った際に得られた知見、そしてどんな体験が得られたかを連載で紹介します。
どのようにして作ったか
さて、では制作したものの概要をお見せします。
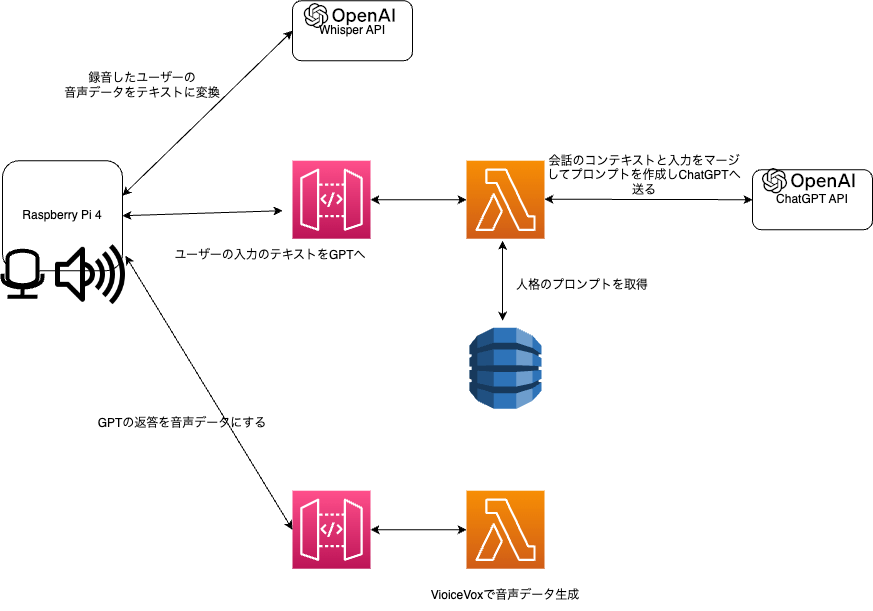
図2. アーキテクチャ図

図3. クマのバッグの中身
今回は、図2のようなアーキテクチャで喋るぬいぐるみを実現しました。図3のように、ぬいぐるみに背負わせたバッグの中にはユーザーと会話をする端末としてRaspberryPi 4が入っています。使用した機材や実装方法に関しては別の記事で詳しく説明しますので、ここでは大まかな処理の流れを説明します。
はじめに、ユーザーが話したデータをRaspberryPiに接続したマイクで録音しています。この録音した音声データはGPTへ送るためにはテキスト化をする必要があり、OpenAIのWhisper APIを使用することでこれを実現しています。
次に、Whisper APIを使用して得られたテキストデータをGPT APIへのリクエストとして送る必要があるのですが、RaspberryPiから直接OpenAIのGPT APIを呼び出すのではなく、AWSのLambdaを経由しています。AWSのLambda側ではDynamoDBに保存された人格を表すプロンプトとユーザーからの入力をマージして、GPT APIへリクエストを行います。
DynamoDBには複数の人格用プロンプトが保存されており、どのプロンプトを使うかはAWS側のエンドポイントで区別しています。
そのため、どのエンドポイントへリクエストを送るかを端末側で決めることで、図4や図5のように会話相手の人格を変更することができるようになっています。
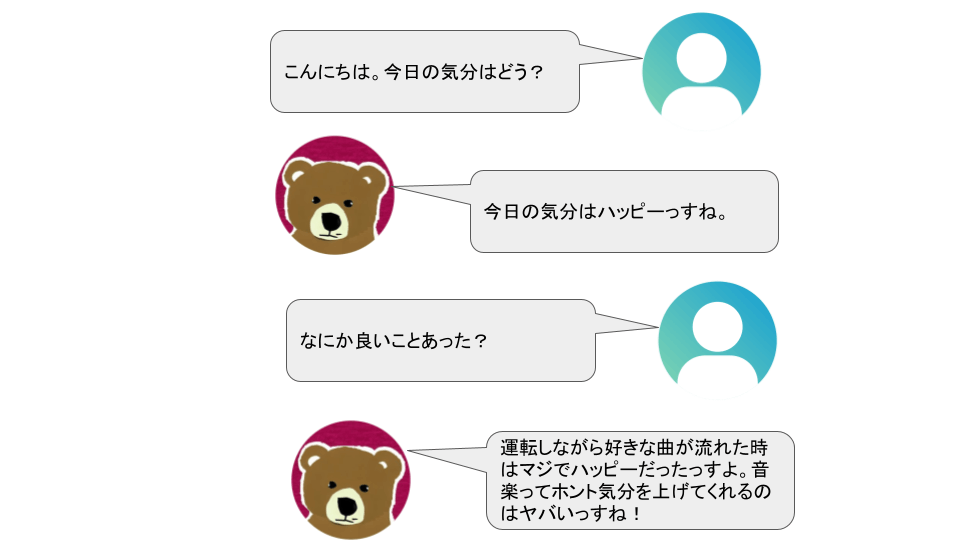
図4. 人格1との会話イメージ

図5. 人格2との会話イメージ
最後に、GPTが返してきたテキストを元にVoiceVox-coreライブラリを使用して音声データを生成し、RaspberryPiに接続したスピーカーでその音声を再生します。VoiceVox-coreはRaspberryPi上で動かすと音声の生成に非常に時間がかかるため、こちらもAWS Lmabda上にAPIを作成し、そのAPIをRaspberryPi側から使用する形で実現しています。
次回以降は詳しい実現方法の説明や、開発を通して得られた知見、実際に会話をしてどんな体験が得られたかを連載していきます。

Discussion