僕らは何故Kubernetesを使うのか
最初に
お仕事で「Kubernetesはいいので、次のプロジェクトで使いたい」と言うと
「何がいいんですか?」とか「何ができるの?」とか聞かれてうまく答えれない事がまぁまぁあったので自分なりにKubernetesがなぜ生まれたのか、なんで使いたいのかと何ができるかをまとめてみた
リソース調達の歴史から見るKubernetesが現在の地位につくまで
リソース(アプリケーションを動かすためのサーバなど)調達の視点から、Kuberenetes誕生までを見ていきます。
物理サーバを調達する時代

原初のアプリケーション開発では、アプリケーションを開発してキャパシティを予測して、リソース見積もりを行い、サーバ購入を行っていました。
この方法では以下のような課題がありました。
リソースを用意するのに、数週間から数ヶ月かかる

サーバを注文してから、到着するまでの時間もかかりました。
またその前のリソース見積もりや、社内での承認なども時間がかかったと思います。
リソース用意後にスペックの変更などが難しい

実稼働前にキャパシティを予測するのは非常に難しいでしょう。特にBtoC的なサービスだと
予測したキャパシティより低いと余剰リソースは無駄になってしまいますし、高いと処理が捌けきれずに問題となります。
サーバ仮想化の誕生

より柔軟にリソースを扱えるように1つの物理サーバの上で複数のサーバを動かすサーバ仮想化という技術が生まれます。
1998年にVMwareが生まれたあたりから広まっていきます。
サーバ仮想化により、物理サーバ時代の課題が解決されます。
リソース(仮想サーバ)は数分で用意できるようになり、仮想サーバのスペック変更や起動台数なども柔軟に変更できるようになりました。
しかしながら、仮想サーバを動かす物理サーバを社内で抱えてるかぎり、余剰リソース分の費用もかかるようという課題は変わっていませんでした。

IaaSの誕生

2005年にAWSが生まれたあたりから、IaaSという利用体系が生まれます。
IaaSのサービス提供者は大量の物理マシンを管理しており、ユーザーはその物理サーバから指定したスペックの仮想サーバを作成・管理できます。
またユーザーは利用した仮想サーバ分の料金だけを支払います(オンデマンド)
これにより仮想サーバで課題だった余剰料金の問題を解決しました。
リソース利用の効率に関する新たな課題
ほとんどの課題はパブリッククラウド誕生で解決しましたが、人間は現状に満足できないもので
もっと便利になりたいと思い始めます。
IaaS/クラウドの利用者は如何にお金を安く抑えるかということを考え始めました。
そのためには以下2つの課題があると認識しました
- より短時間でのリソース量の調整
- アプリケーションが使う以外のリソースが無駄になっている
より短時間でのリソース量の調整 -> より高速に
お金を抑えるために、リソースの要求に応じてサーバをスケールすることが行われ始めました。

ですが、仮想サーバの起動時間では無駄なリソース消費であったり、トラフィックが捌けないことも発生し得ました
より短時間でのリソース量の調整を行うためには、リソースをより高速に起動できるようにしたいという要求が発生しました。

アプリケーションが使う以外のリソースが無駄になっている -> より軽量に
リソースの要求に応じてサーバをスケールするのには水平スケールがよく利用されました。
水平スケールで複数の仮想サーバを立ち上げると、アプリケーションが使うリソース以外にカーネル周りなどでも消費されて、無駄なリソース利用が発生しました。
ここを効率よく使用したいという要求が発生しました。

高速・軽量という要求の実現のためにサーバレス、コンテナと言った技術が誕生します(サーバレスは今回の対象じゃないので割愛します)
コンテナ技術の誕生
コンテナはサーバ仮想化技術の1つになります
一般的な仮想サーバ(ハイパーバイザ型)と比較して、OSのカーネル部分などをコンテナ間で共通利用することで
アプリケーションなどの部分だけを仮想化することで、高速起動・軽量を実現しています。

2013年にDockerが誕生してから一気に普及した(技術・使用自体は以前からあった)
Dockerでコンテナ技術の実装が誕生したことにより、リソース調達が数分単位から、数秒単位に縮まり、リソースをより効率的に扱えるようになりました。
また、それまでの仮想サーバでは環境間(Dev/QA/Prod)で差分が発生しないように
ansibleやchefと言った構成管理ツールを利用したり、仮想サーバをそのままインポートするといったことをしていましたが

Dockerはよりシンプルに環境間差分を発生を減らすこと(ポータビリティ)も利点の一つでした(コンテナは、カーネルのタイプ(Linux, Windows)さえ合ってれば基本的にどの環境でも動作する)

コンテナを商用環境で動かすためのコンテナオーケストレーション技術
コンテナの利用シーンとしては、
当初は開発者が手元でミドルウェアを動かしたりするなど、開発の効率化的な利用シーンが多かった印象です。
2014年にGoogleが社内の全てのサービスを20億以上のコンテナで動かしていると発表したり
徐々にコンテナを商用環境で動かすという流れが出始めました。
シンプルに単一サーバで複数のコンテナを固定台数動かすだけであれば、docker-composeなどを利用すれば良いでしょう。
しかし商用のワークフローでは
- 複数のサーバ上で複数のコンテナを動かしたい
- コンテナに割り当てるリソースを制御したい
- コンテナの稼働状況を監視したい
- webアプリコンテナをリクエスト量に応じてスケールするようにしたい
- cron的にコンテナを起動して処理したい
- 複数のコンテナで1つのストレージを共有したい。
などなど、多数の要求が生まれました。

これらを解決するための方法として、2015年あたりからコンテナオーケストレーションという技術が誕生しました。
コンテナオーケストレーション戦国時代

先にあげた商用ワークフローを解決するためのコンテナオーケストレーションですが
多数の実装が生まれました。
- Docker公式のSwarm
- Googleを中心としたOSSのKubernetes
- Mesos社によるMarathon
- CoreOS社によるfleet
- HashiCorp社によるNomad
- AWSによるElasic Container Service
などなどが生まれます。
以下は個人的な体感ですが
2016年くらいまではDocker Swarmが標準の座につきそうに見えました。
SwarmはDockerが公式に開発していることもありとっつきやすかた認識です
Kubernetesは当時は構築・管理が複雑すぎるという意見が多かった印象です
その他のツールは各社の環境に依存するため、ベンダーロックイン的な理由で避けられてるように見えました。
Kubernetesがデファクトスタンダードになるまで
Kubernetesは技術的な完成度、コミュニティの成長という2点でデファクトスタンダードになったと思います。
技術的な完成度

KuberenetesはGoogleが長年社内で仮想サーバのオーケストレーションとして使われていたBorgという技術がベースになっています。
そのためコンテナ、仮想サーバという違いはありますが、長年の実績があったこと
またKuberenetesでは3ヶ月に1回アップデートを行うという、とても速いリリースサイクルがあります。
これにより多数の要求に素早く答えた点も普及につながった点だと考えられます。
コミュニティの成長
コンテナオーケストレーション技術のうちKuberenetesはGoogleを中心としつつもOSSで、他技術は各社が開発してる状況でした。
コミュニティの規模というのは重要だと思います。(デカすぎても舵きりできずに大破しそうですが)
2015年にGoogleは「クラウドネイティブソフトウェアのための持続可能なエコシステムの構築」のためにCloud Native Computing Foundation(CNCF)を設立しました。
そして、GoogleはCNCFのファーストプロジェクトとしてKuberenetesを献上しました。
![]()
CNCFは徐々に参加企業を増やしていき、MicrosoftやAmazonと言った主要クラウドプロバイダーも参加しました。
そして2017年には

と言った追い風が生まれ
この辺りからKubernetesがデファクトスタンダードとして扱われるようになっていき、2020年の現在では標準の座を確固たるものにしています。
Kubernetesの歴史まとめ
サーバ調達の視点からコンテナ技術が誕生して、それを商用環境で動かすためにkuberenetesが生まれた経緯を見ました。
- リソースを効率的に利用するためにコンテナ技術が使われだした
- コンテナを商用環境でスケーラブルに扱うためにコンテナオーケストレーション技術が誕生した
- 多数の企業を巻き込んだKubernetesがコンテナオーケストレーションのデファクトスタンダードになった
Kubernetesの概要
全てを説明するにはkubernetesは巨大すぎるので、特徴的だと思う点を3つ紹介します。
- 多様なワークフローに対応できるほどに多機能
- 宣言的設定と突き合わせループによるリソース管理
- CRDなど拡張性が高い
多様なワークフローに対応できるほどに多機能

Kubernetesには多種多様なリソースが存在します。
これらのリソースはKubernetesクラスタを構築後その中で論理的なリソースとして扱えます。
これらを正しく選択, 設定して起動させることで商用でコンテナ利用する際に求められるワークフローのほとんどに対応できます。
以下に代表的なリソースをあげておきます。
| 名称 | icon | 概要 |
|---|---|---|
| Pod | kubernetes上で動かしたいコンテナ | |
| Deployment | Podの管理方法を定義 | |
| DaemonSet | クラスタが動作するサーバ1つにつき、必ず1つは起動させたいPodを定義する(サーバのメトリクス収集とかで使われる) | |
| Job | 処理を行って終了するようなPodを定義する | |
| CronJob | JobリソースをCronのように定期的に定義する | |
| Service | 外部やクラスタ内からのリクエストをPodに割り振るようなネットワーク定義 | |
| ConfigMap | Podで利用する設定(環境変数など)を定義する | |
| Secret | Podで利用する設定のうち秘匿な情報を定義する | |
| Volume | Podで利用するストレージを定義する |
宣言的設定と突き合わせループによるリソース管理
Kubernetesでは前述の各種リソースをマニフェストと呼ばれるファイルを書き、それをクラスタに渡すことで各種リソースを生成できます。
このマニフェストでリソースを定義/生成は宣言的設定と突き合わせループという考え方が使われています。[3]
宣言的設定(Declarative Configuration)
マニフェストは「リソースをいくつ起動しろ」という命令的な定義ではなく、「リソースをいくつある状態にしろ」という宣言的な定義になります。
これによりKubernetesは自律的に動作することが可能になります。
突き合わせループ(Reconciliation loop)

マニフェストをクラスタに渡すと、クラスタ内でのリソースの状態と,マニフェストのリソース定義を比較し
リソース定義の状態になるように調整を行います。
突き合わせループはこれを繰り返すことになります。
宣言的設定と突き合わせループで障害に強くなる
宣言的なリソース定義は障害に対して強くなります。
例えば負荷量に合わせてPodの数を調整することを考えます。
命令的アプローチとして、負荷が増えたら1つPodを増やすというなことをして、あるタイミングでPodを増やす処理を失敗した場合、以降のスケールは想定のPod数より1つ少なくなることが考えれます。
宣言的アプローチとして、負荷N%に対して、PodをM個存在するようにするというようなことをすると、あるタイミングでPod数の変更処理を失敗したとしても、突き合わせループの次サイクルでまた正しい数に変更できます。
このようにKubernetesは宣言的アプローチを取ることで、障害に対して強くなります。
これの実現のためにKubernetesはトレードオフとして、複雑なコンポーネント構成・アーキテクチャになっています。

ただ、前述の通り現在ではほぼ全てのクラウドプロバイダーがKubernetesのマネージドサービスを用意しており
この複雑さをクラウドプロバイダーが負担してくれているので、パブリッククラウドを利用すれば恩恵のみを受け取ることができます。
CRDなど拡張性が高い
KubernetesではPodやDeploymentといったリソースがあるというのは前述の通りですが
Custom Resource Definitionという機能を使ってユーザーが独自のリソースを定義することができます。
例として、Argo CDでは、CI/CDをKubernetes上で行えるOSSがあります。
このArgo CDではCDのパイプラインをCRDで定義しており、PodやDeploymentのマニフェストと同じフォーマットでCDパイプラインを定義できます。
また最近ではGCPやAWSのリソースもCRDで扱えるサービスも出てきたりしてきてます[4]
これは何が嬉しいかというと「プロジェクト内で扱うリソースを統一したフォーマットで統一した管理が行える」ということだと思います。
例えばあるプロジェクトでAWS上でKubernetesやDBを動かして、システム開発をするとします。
ここでAWSのリソースはterraform, アプリのリソースをkubernetesのマニフェスト, アプリのCI/CD設定をGithub Actionsの設定などで管理すると,
それぞれ管理がバラバラになりますし、それぞれの記法を学習する必要があります。

CRDを用いれば、これらを統一したkubernetesマニフェストという形で定義し管理することができます。
(またGitOpsなどを用いれば、運用も統一化が夢見れます。)

CRDは日々新しいのがGithubなどで生まれていってるため、今後どんどんいろんなリソースを手軽に扱えることが想定できます。
僕らがKubernetesを使うべきな理由
最後にKubernetesを使うべき利点(個人的主観)などを書いていきます。
企業的利点
会社としてKubernetesを採用した際の利点です。
機能・使用性にコストを割くことができる
Kubernetesを利用して開発を行うと、チームは機能・使用性に集中して取り組むことができます。
この理由は2つあります。
1つはkubernetesというよりコンテナ技術寄りの話ですが、コンテナにメインアプリケーションを乗せて
その他の補助的な機能(ロギングや通信時の暗号化など)をアタッチアブルにできる点です。
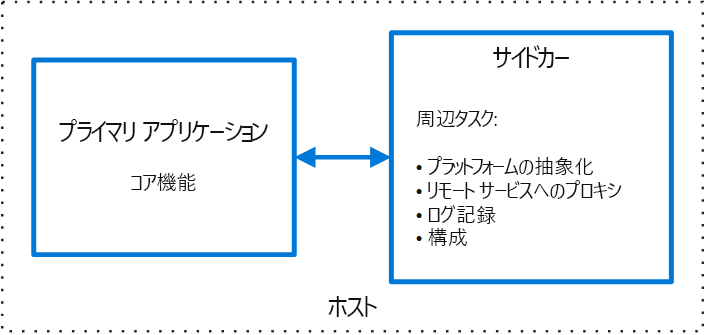
サイドカーパターンと呼ばれるものがあり[5]
メインアプリケーションとセットでサイドカーコンテナを動かし
メインアプリケーションが他コンテナと通信時にプロキシ的に動作し、通信を暗号化したり
メインアプリケーションとボリュームを共有し、アプリケーションが吐いたログをログ収集基盤に送ったりします。
このような一般的なサイドカーの機能はOSSとして公開されていることが多く手軽に利用できます。
これによりチームはメインアプリケーションのコア機能に集中して取り組むことができます。
2つ目はKubernetesのエコシステムが非常に発達している点です。
前述のサイドカーなどもそうですが、Kubernetesを動かす上での一般的な課題などを解決するOSSは非常に多く開発されています。
またその多くはKubernetesの標準リソースもしくはCRDを用いたものが多く
簡単に用意できます。
例えばKubernetesクラスタのメトリクスを可視化するKuberenetes Dashboardは以下のコマンド1つで用意できます。
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.4/aio/deploy/recommended.yaml
このように企業特有の要求などがない限りは、既存のものを利用でき
同じくアプリケーション開発に専念できます。
障害に強い構成を作りやすい
前述の通り、Kubernetesは宣言的定義のアプローチを取っているため、障害に対して強い構成を組みやすいです。
移植性が高い
KuberenetesはOSSとして開発されており、各種クラウドベンダーはもちろんオンプレミスでも動作できます。
またKuberenetes上で動かすものはほとんどKubernetesリソースとして抽象化されているので、
たとえAWSからGCPへ移行したとしても、マニフェストなどをほとんど変えずに移行することができます。
開発者的利点
開発サイクルを高速に回しやすい
作り方によるとは思いますが、自分は机上で細かく検討してから作るというよりは
とりあえず作って動かしてみて、ログやメトリクスを見て、また修正して動かしてという開発スタイルが好きです。
Kubernetesを利用すると、このサイクルが非常に回しやすいです。
- ローカルでアプリを修正
- docker build
- docker push
- kubectl rollout restart
- メトリクスやログの確認
といったサイクルになります。
体感的にすごく高速で回せるなと思います。
開発言語でGoとかを採用していると、docker buildやpushも早いので、1サイクルを1分で回したりもできます。
使ってて楽しい
すごく主観的ですが、楽しいです。
上の開発サイクルを回しているのも楽しいですし、エコシステムが発展しておりKubernetes周りの技術が日々作られていて、追っているだけで最先端にいる気がして楽しいです。
欠点
利点だけではあれなので欠点も少し触れておきます。
定期的にクラスタのアップデートが必要
Kubernetesでは1つのバージョンが9ヶ月間しか保守されないため、かなり早いサイクルでクラスタのアップデートをかけないといけません。
Kubernetesのバージョンはx.y.zの形式で表現され、xはメジャーバージョン、yはマイナーバージョン、zはパッチバージョンを指します
Kubernetesプロジェクトでは、最新の3つのマイナーリリースについてリリースブランチを管理しています。
マイナーリリースは約3ヶ月ごとに行われるため、マイナーリリースのブランチはそれぞれ約9ヶ月保守されます。[6]
クラウドプロバイダーのマネージドサービスなどでは、クラスタの更新機能などもサポートはしていますが
バージョンアップによってKubernetesリソース定義の一部がdeprecatedされた場合はユーザ側で対応しないといけません。
長期的に学習を続けていかないといけない
前の話と被りますが、kubernetesはリリースサイクルが早い上に頻繁に機能が廃止・追加されます。
こういった部分を学習していかないと安定した稼働は難しくなります。
-
https://gihyo.jp/admin/column/newyear/2018/container-and-cloud ↩︎
-
https://www.publickey1.jp/blog/17/kubernetescoreosfleetkubernetes.html ↩︎
-
https://deeeet.com/writing/2018/12/13/how-kubernetes-change-our-way-of-automation/ ↩︎
-
https://aws.amazon.com/jp/blogs/opensource/aws-service-operator-kubernetes-available/ ↩︎
-
https://docs.microsoft.com/ja-jp/azure/architecture/patterns/sidecar ↩︎
-
https://kubernetes.io/ja/docs/setup/release/version-skew-policy/ ↩︎
Discussion