Amazon Lookout for Metrics ハンズオン
はじめに
2021/5/22(土)に以下のハンズオンに参加した際の内容を紹介する。
AWSの基礎を学ぼう 特別編 最新サービスをみんなで触ってみる はじめての異常検知
この特別編では、2020年12月にアナウンスされた、異常検知を行うAIサービスであるAmazon Lookout for Metricsが一般提供開始となり東京リージョンでも使えるようになったため、こちらを皆で触って学びましょう
異常検知とは
通常の動作の範囲から大きく外れたデータを検知すること。
例えばクレジットカードの不正利用の検知で利用されており、
三井住友カードの場合だと、不正利用のパターンに合致した際にカード利用を保留にしたりしている。
他にも、工場における機械の故障予測などでも利用されている。
Amazon Lookout for Metricsとは
機械学習(ML)を使って運用データの異常を自動検出するサービス。
Lookout for Metricsを使用すると、以下を自動で実施してくれる。
- 様々なデータソース[1]に接続してデータを収集
- 機械学習を用いて異常を検出
- 関連性の高い異常をグループ化・重大度の順にランク付け
これにより分析に時間をかけず、迅速に異常の原因を特定できるようになる。
ハンズオンの概要
ECサイト「売上データ」と「アクセス数」の異常検出を行う。
事前準備
機械学習用データのアップロード
S3バケットを作成し、CloudShell経由でデータセットをアップロードする。
S3バケット作成
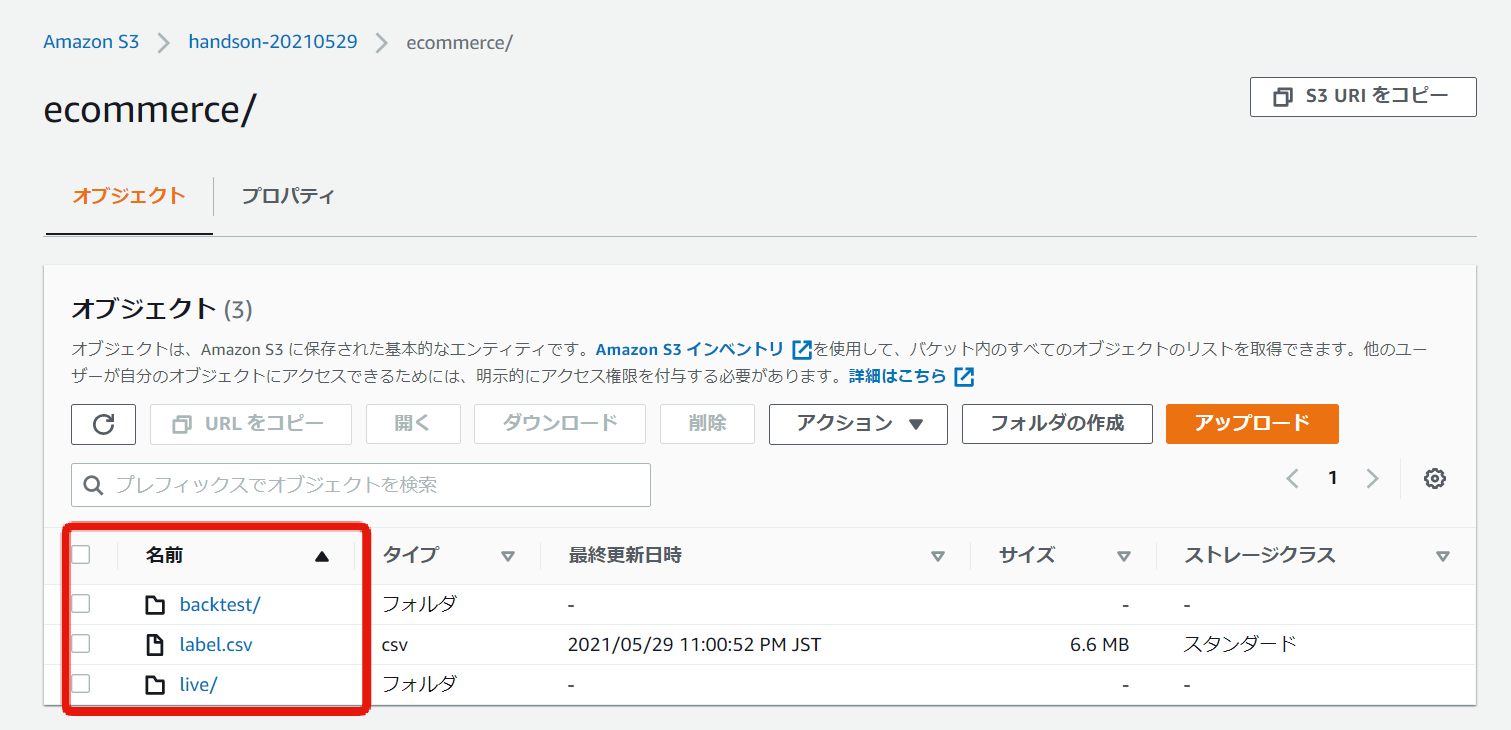
データのアップロード
CloudShell上にファイルをアップロードし、S3バケットへ転送する。
手動よりも早くファイルをアップロードできる。
!aws s3 sync ./ecommerce/ s3://{S3バケット名}/ecommerce/
CloudShell
CloudShellは、AWSコンソールからコマンドラインでAWS サービスに接続できるサービス。

sync コマンド
syncコマンドは転送元と転送先の差異を確認して、その差異を転送先に反映するコマンド。
ECサイトの異常データを検出する
Amazon Lookout for Metricsにアクセス。
異常検出モデルを作成する
異常データを自動で検出するための検出器(Detector)と
学習用データの準備を行う。
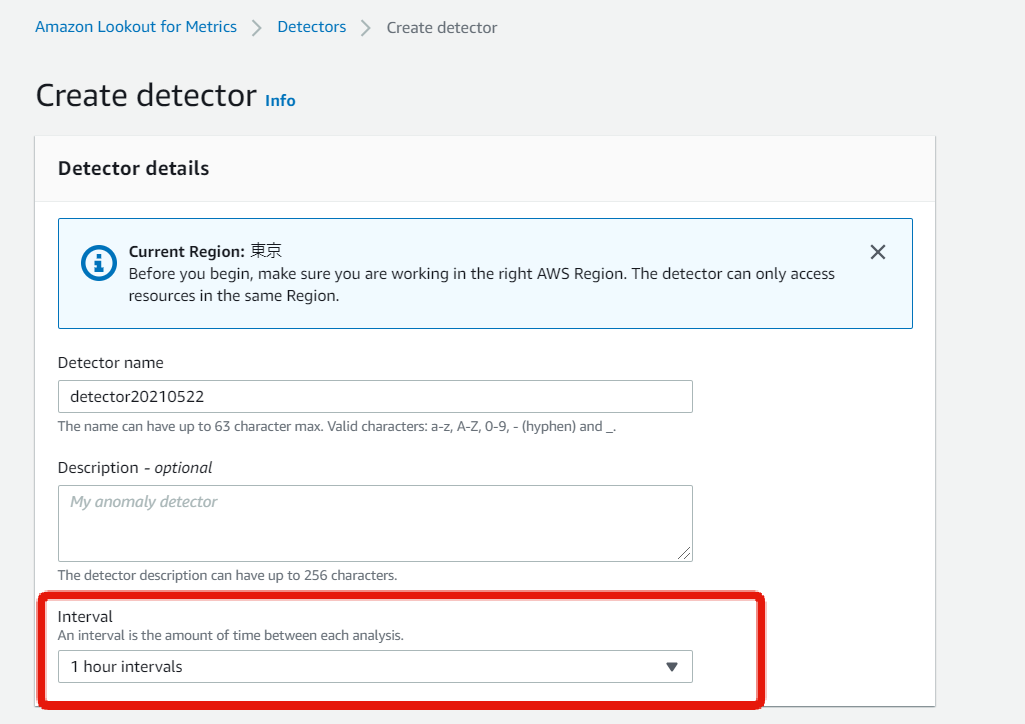
Detectorの設定
「Interval」は、用意したデータ間隔と一致している必要がある。
データ中身(CSV)ではなくフォルダ構造に合わせて設定すること。
【補足】今回はS3に1時間間隔でデータを格納している。
- フォルダ:1時間ごと(HHMM)
- ファイル:1時間ごとの連続データ
s3://handson-20210530/ecommerce
live/20210101/0000/20210101_000000.csv
live/20210101/0100/20210101_010000.csv
live/20210101/0200/20210101_020000.csv
~以下省略~
Detector 作成完了
「Create」押下でDetectorが作成される。
この時点ではデータ未学習のため何もできない。
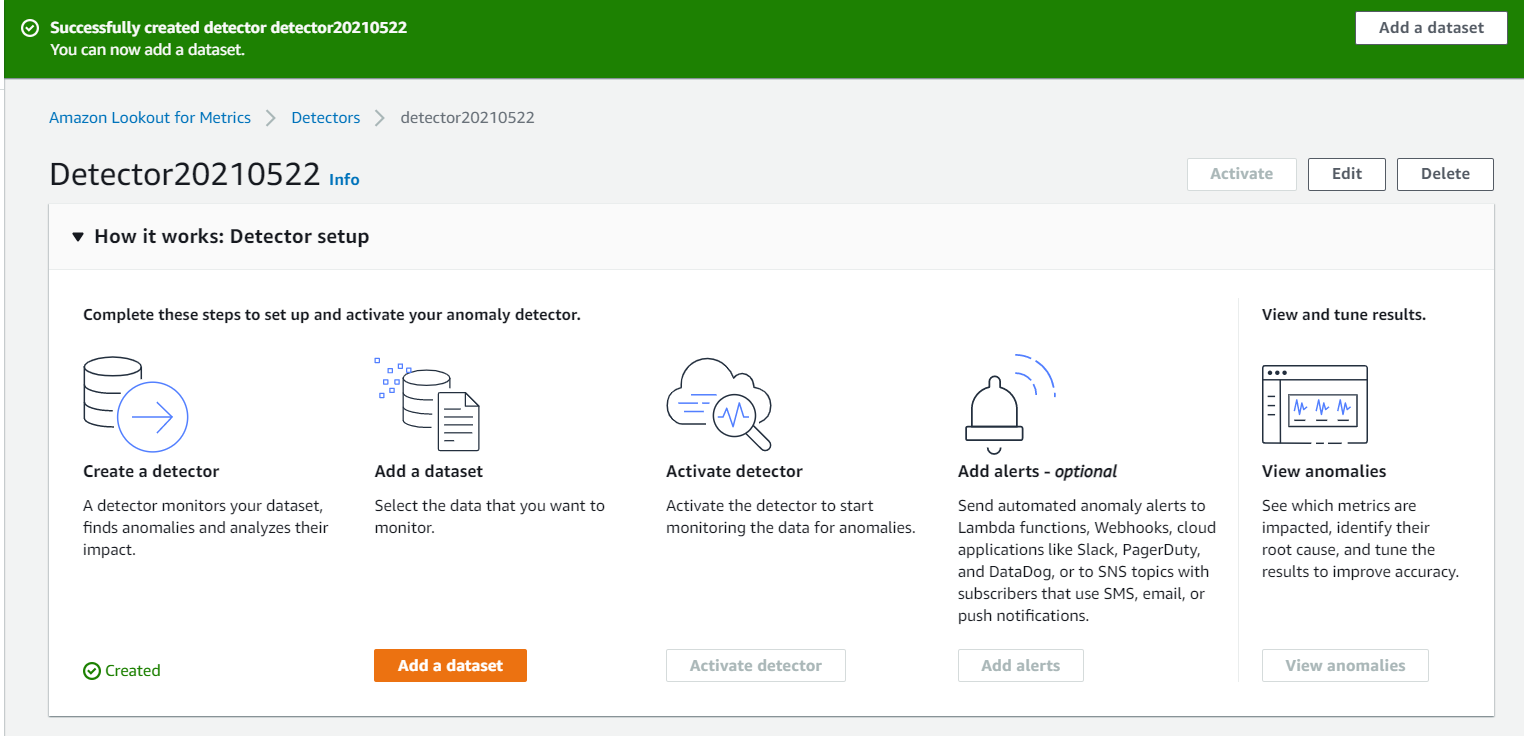
学習用データの基本情報入力
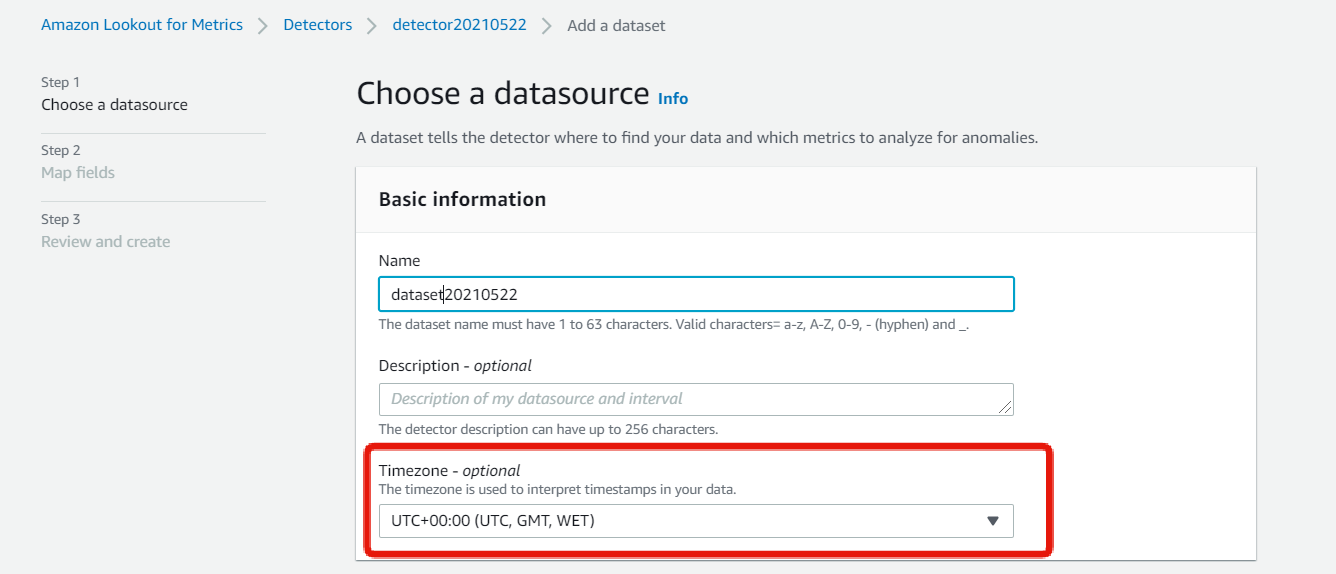
検出器に渡すデータ種類の選択
「過去データ」と「現在データ」の2種類のデータを検出器に提供できる。
今回は過去データをもとに学習を行うので「Backtest」を選択し、以下を設定する。
- 「Historical data」にS3パスを指定
- 「Most recent date」にデータの最新日付を指定
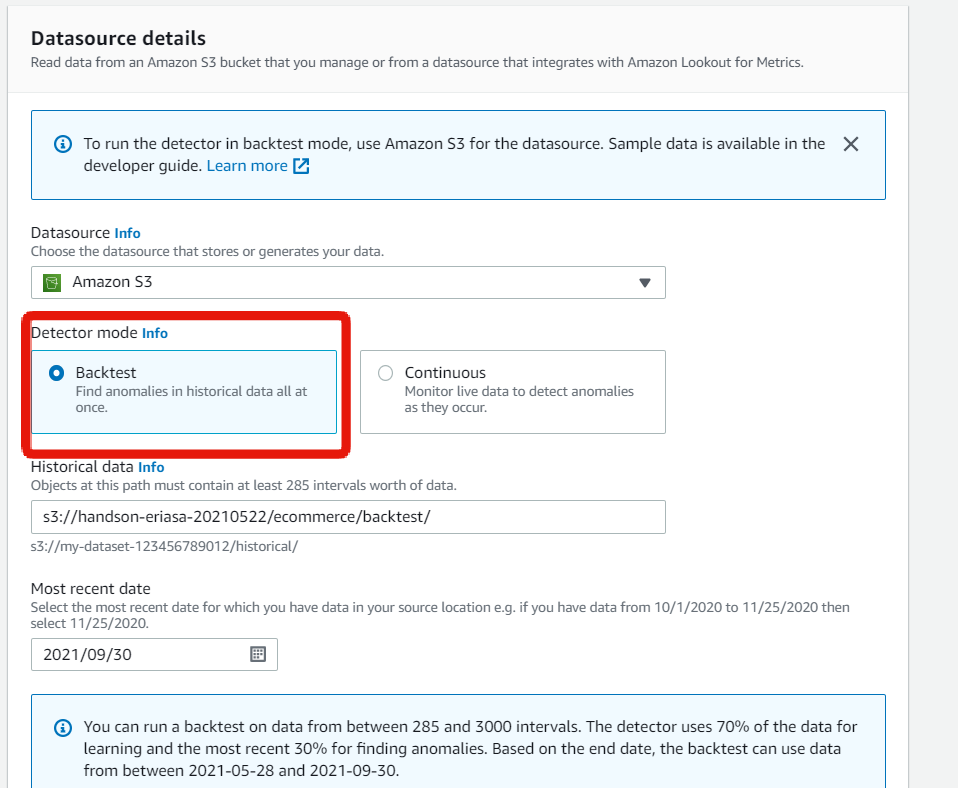
「Continuous」モード
商用環境だと「Continuous」モードで最新のデータを取込むことが多い。
- 「Interval」に設定した間隔でデータを読みに行く
- 「Historical data」を指定して、過去データを学習し精度向上できる
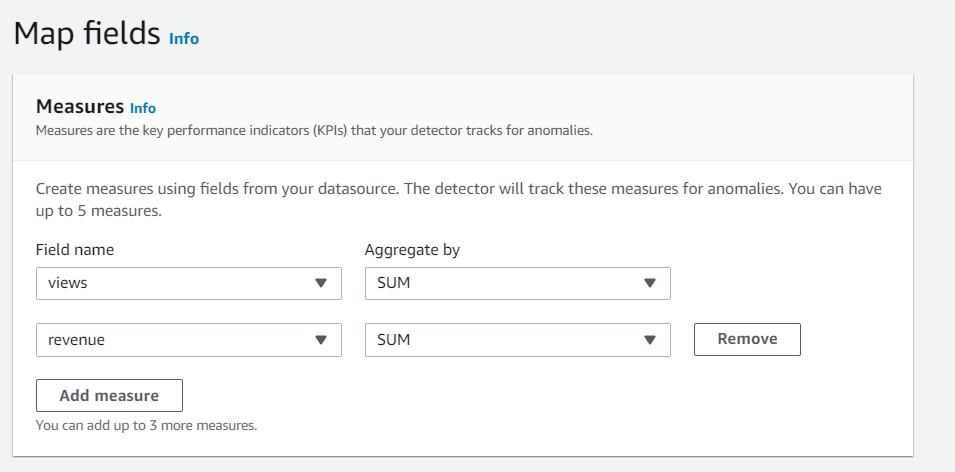
異常検知を行う対象値の設定
異常として検知したい項目をMeasureに設定する。
今回はECサイトの以下項目の異常を検知したい。
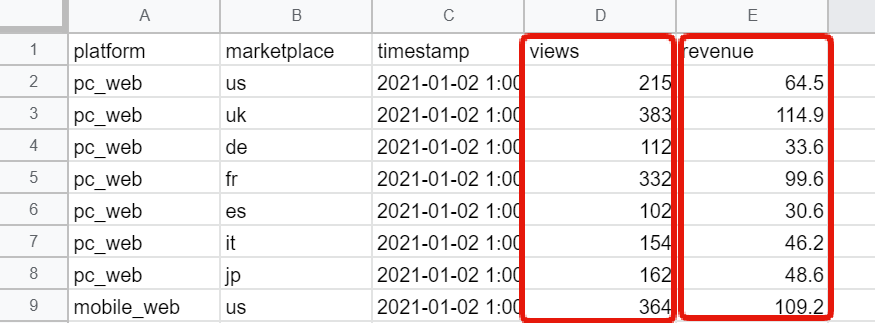
- ページビュー(views)
- 売上(revenue)
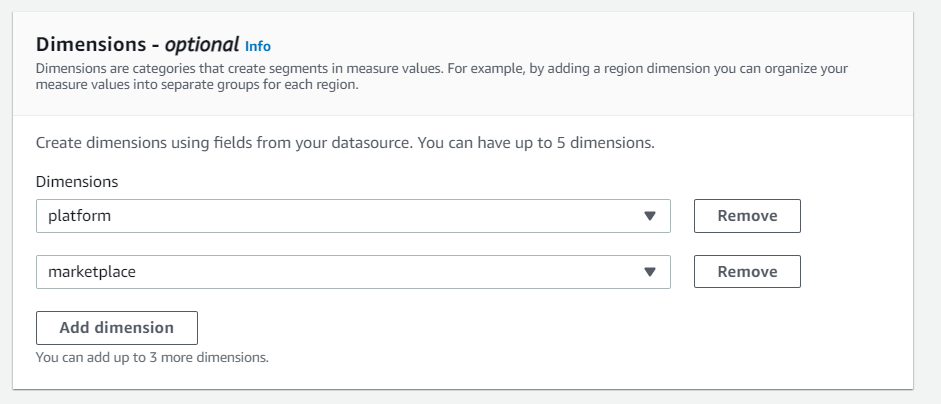
異常値に影響を与える項目の設定
Measureで設定した項目に、影響を与える項目をDemensionsに設定する。
- 使用媒体は何か?(platform)
- どの国からのアクセスか?(marketplace)
例えば、売上を「platform」と「marketplace」ごとにグループ化できる。
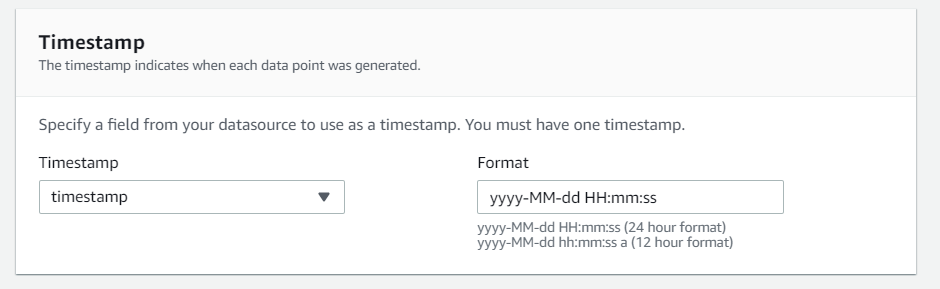
タイムスタンプの設定
「Timestamp」をCSVファイルのフォーマットに合わせる
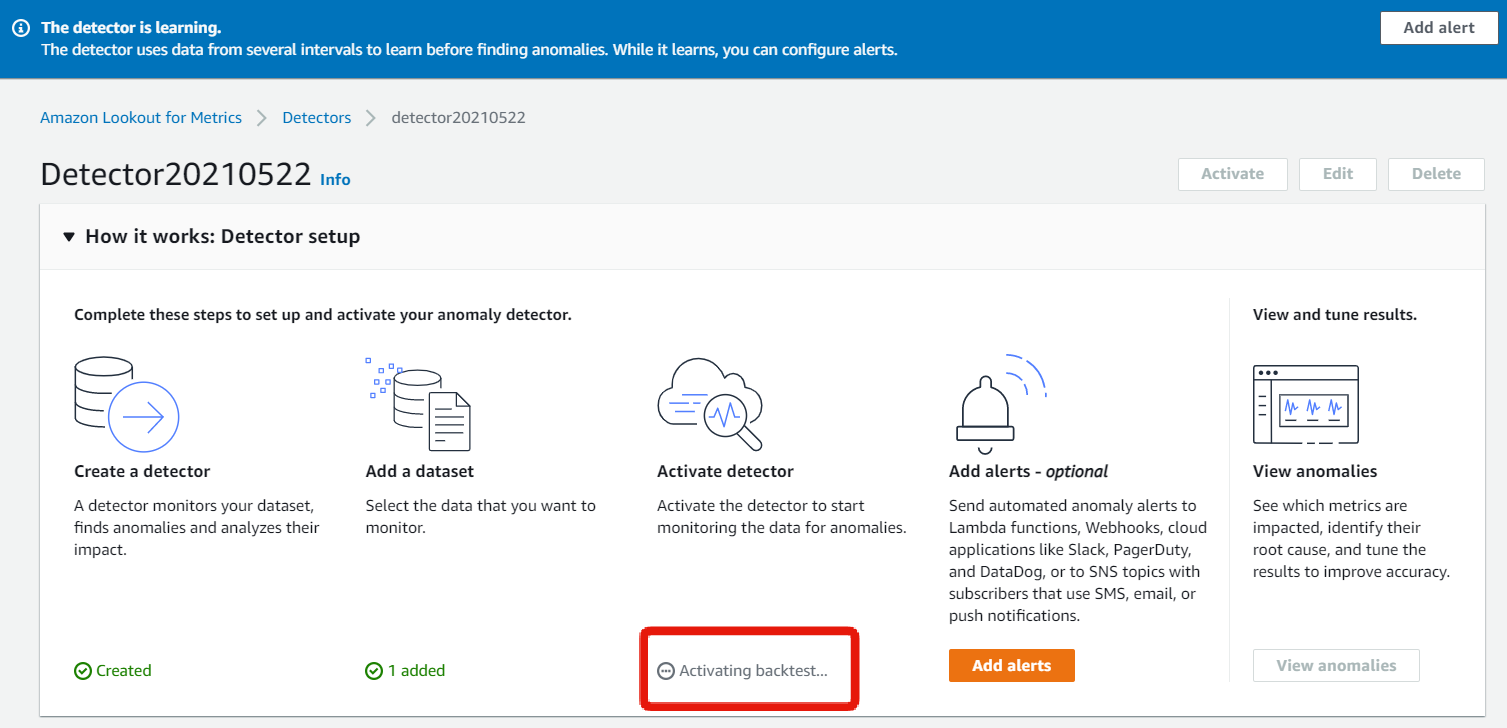
Detectorの学習・推論を実施する
70%を学習に使い、残りの30%を推論に使う。
検知した異常を確認する
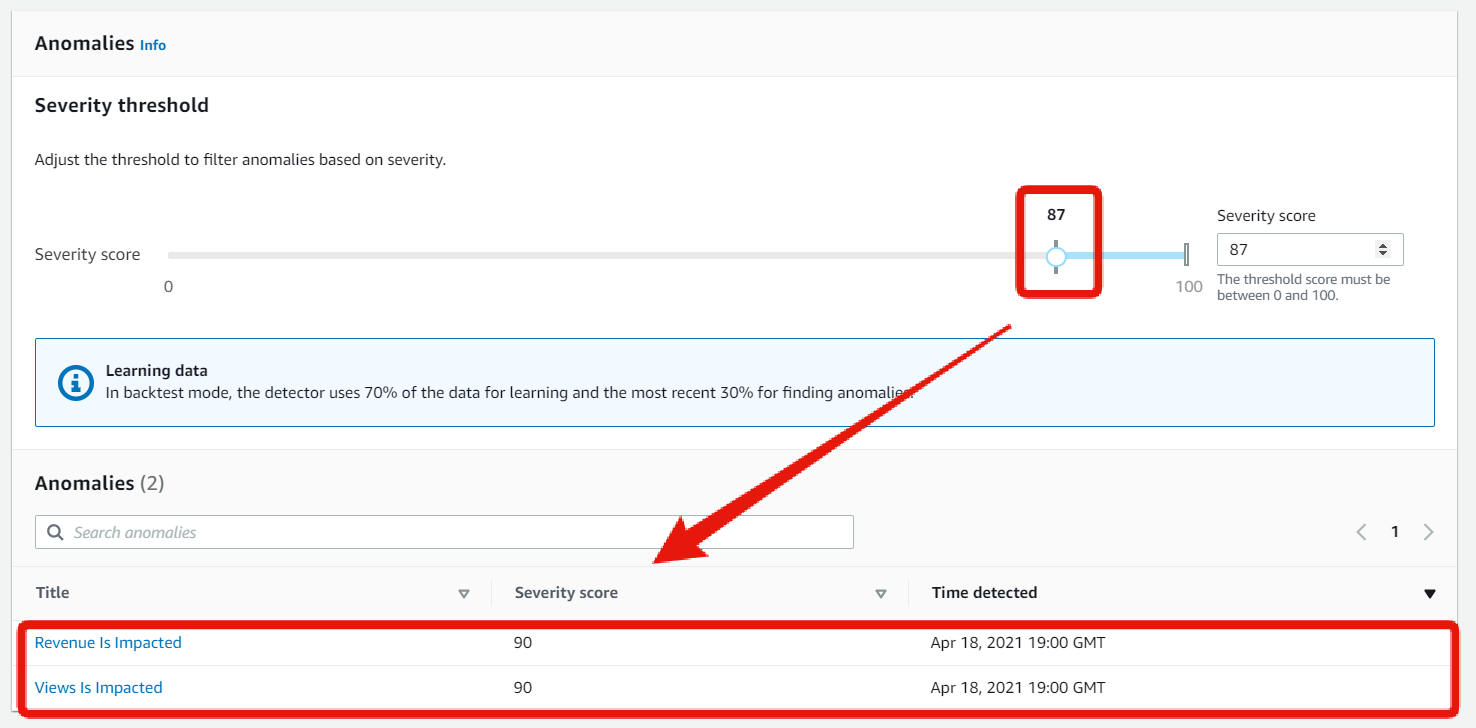
閾値の設定
閾値を設定して異常値を絞り込む。
結果はAnomaliesで確認できる。
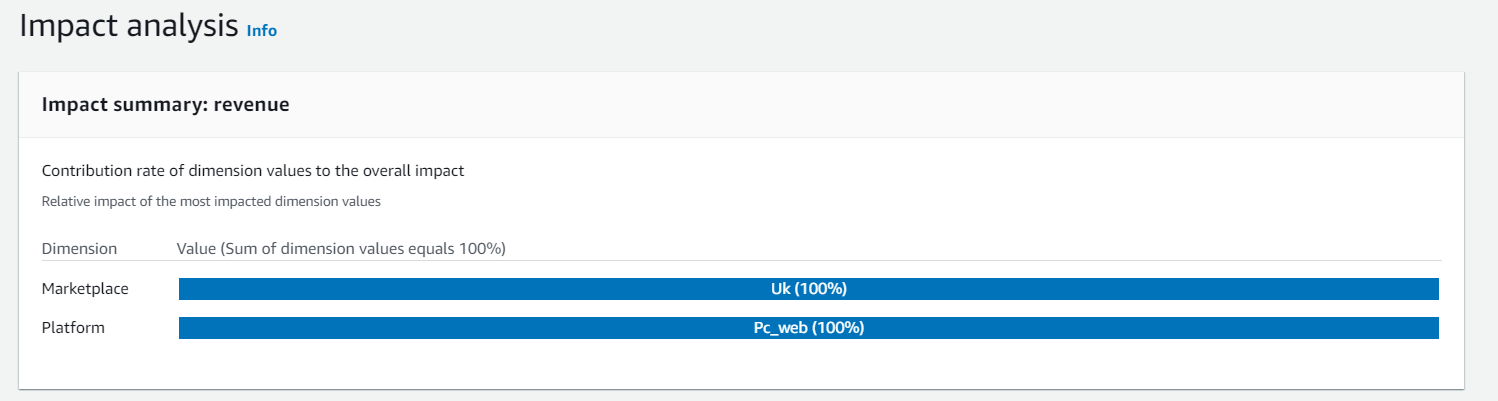
異常の詳細を確認
売り上げの異常詳細をみると、イギリスからのアクセスで売上が落ちている。
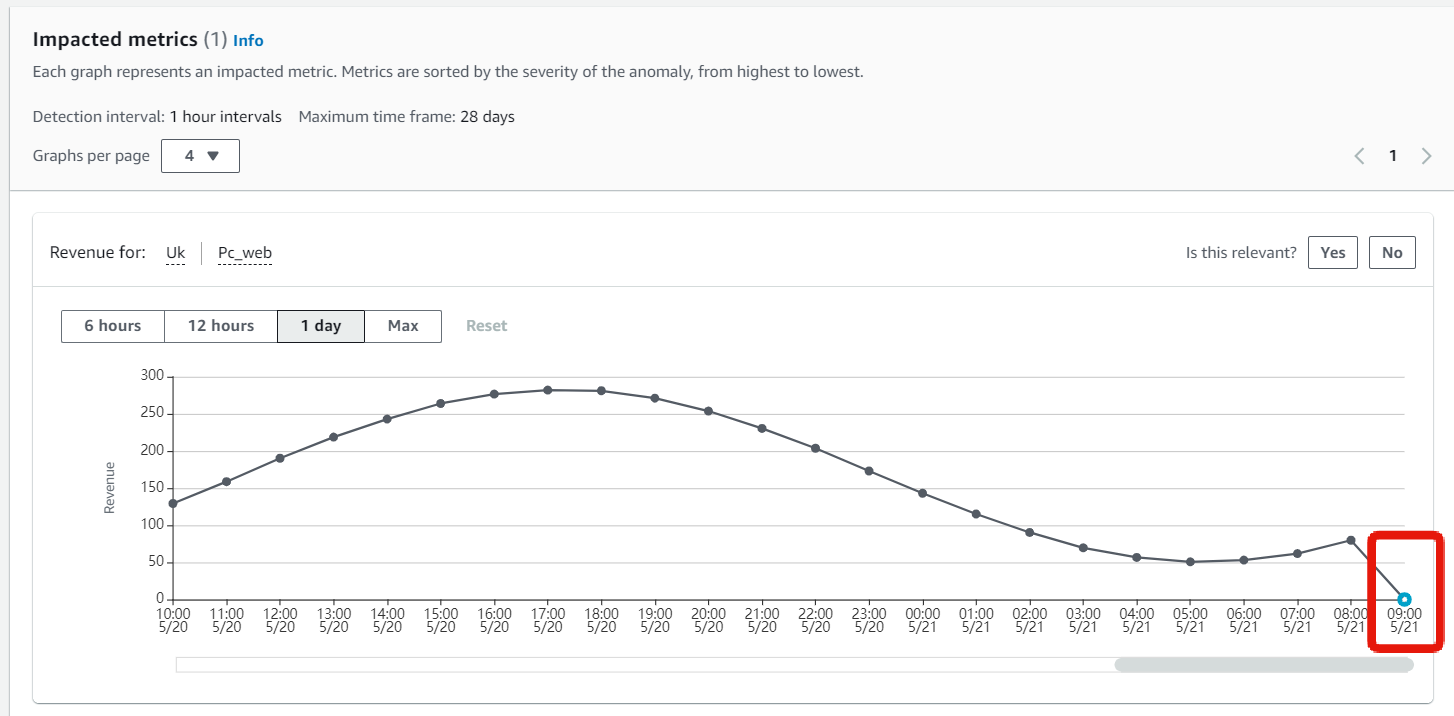
フィードバックの提供
フィードバックを送信することで、異常検知の性能を高めることができる。

おわりに
自分の業務に適用するんだったら何ができるか?って考えていたらこんなツイートが。
普段PCキッティングをしているのでこの辺は気になるかも。
あとは緊急依頼の割合と背景が出せたら面白そうだな☺
実際に活用された方のお話はとっても参考になった。
私もブログアクセス数の異常検知やってみたいな~(^▽^)/
アウトプットのやり方も取り入れてみたいと思った。
また、構成理解の手助けをしてくれるツイートありがたい。
ハンズオン中は自分のことで必死になりがちなので、
こういったツイートがあると聞き逃しても後で確認できて安心(^^)/
来週も楽しみ!
参考資料
-
AWS:Amazon S3、Amazon Redshift、Amazon Relational Database Service (RDS)
サードパーティ:Salesforce、Servicenow、Zendesk、および Marketo など ↩︎
Discussion