【論文紹介】D-CPT Law
タイトル:D-CPT Law: Domain-specific Continual Pre-Training Scaling Law for Large Language Models
https://arxiv.org/abs/2406.01375
執筆者:EQUESエンジニア 武馬光星
※ 本ページの図は特筆がない限り全て本論文から引用しています。
今回は、「D-CPT Law: Domain-specific Continual Pre-Training Scaling Law for Large Language Models」という論文を紹介したいと思います。この論文では、継続事前学習における最適なドメインデータと一般データの比率を決めるスケーリング方法「D-CPT Law」を提案しています。
はじめに
大規模言語モデル (LLM) の継続事前学習 (CPT, continual pretrainingの略) は、モデルの特定のドメインタスク (たとえば数学やコード生成など) に知識を拡張し、ドメインに適応するために広く使用されています。
ドメイン特化した継続事前学習では、ドメインデータでのパフォーマンスを向上させるために高品質のドメインコーパスに加えて、一般的な能力の壊滅的忘却を軽減するために一般的なコーパスも併せて学習することが多いです。ドメイン固有LLMのCPTの場合、一般的なコーパス (Dolma、Slim-pajama など) とドメインコーパスの間の最適な混合比を選択する方法が重要な問題として挙げられます。従来は、混合比を変えてグリッドサーチを行う必要があるため、学習コストが高くなることが問題でした。この提案手法では、小さいモデルサイズ(0.5Bや1.8B)で得られたデータから、より大きなモデルサイズ(例: 7B)での損失を予測するスケーリングを行うことができます。以下のようにスケーリングを行い、一般的なタスク損失とドメインタスク損失から適切な混合比率を決定することができます。

また、複数のドメインに対応したスケーリング法則である「Cross-Domain D-CPT Law」も提案され、これにより新しいドメインのトレーニングコストが大幅に削減されました。
概略図は以下のようになっています。

手法
D-CPT Law
Chinchilla Scaling Lawを拡張して、以下のようにスケーリングを行う式を定義します。

L:Loss, N:モデルパラメータ数, D:データセットサイズ, r:データ混合比
Cross-Domain D-CPT Law
また、ドメイン様々なドメインのデータで学習を行う場合は、各ドメインのドメイン固有のパラメータを表すドメイン固有学習可能係数(DLC, Domain-specific Learnable Coefficient)を導入して、各ドメインの特性に基づいて検証損失を予測します。下の式中のKは、各ドメインの学習しやすさや特異性を示すパラメータ(DLC)であり、D-CPT Lawに組み込むことで、未知のドメインにも柔軟に適用可能な法則として拡張されます。
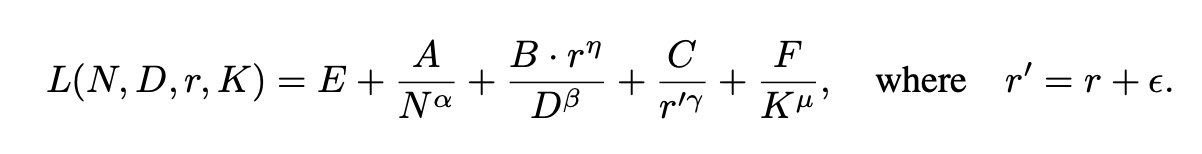
実験手法
D-CPT Lawの有効性と汎化性を示すために、モデルサイズ0.5Bから4Bパラメータ、データセットサイズ0.1Bから26Bトークン、混合比0から1を使用して広範な実験を行います。モデルはQwen-1.5、データセットは、コード、数学、法、化学、音楽および医療を用います。
ここでは、モデルサイズを固定し、混合比を変化させてデータポイントの収集を行います。一般データとドメインデータの間の混合比は以下の9つとします。
{0:10, 1:9, 2:8, 3.3:6.7, 5:5, 6.7:3.3, 8:2, 9:1, 10:0}
3 つのモデルサイズ (0.5B、1.8B、4B)、9 つのデータ混合比率、および 200 個の検証損失データポイント (1000 回のトレーニングステップごとに収集され、合計 200000 回のトレーニングステップ) の組み合わせとなります。したがって、3×9×200 = 5400個のデータポイントを1つのドメインデータに対して収集することになります。
※レビューでの追記によると、5000 回のトレーニングステップごとに損失を収集することで、必要なデータポイントを1/5とすることができるそうです。その際にも、精度は大きく変化しないそうです。
データポイントを元に、L-BFGSと呼ばれる最適化アルゴリズムでパラメータを決定します。
実験結果
D-CPT Lawの有効性を確かめた結果は以下のようになりました。
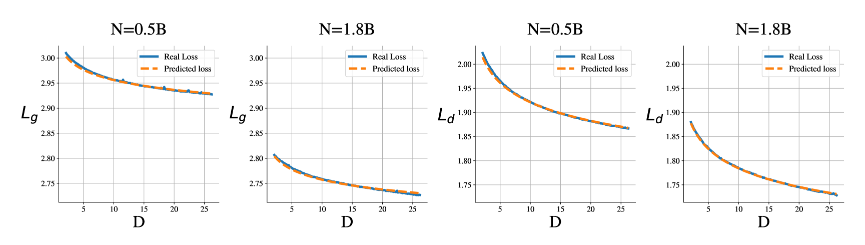
Lgが一般的なデータに対する損失、Ldがドメインデータに対する損失になります。
この図は、混合比を0.5に固定した場合の各データ量、モデルサイズに対する損失の図になります。オレンジのプロットが予測された損失、青色のプロットが実際の損失になっています。図から予測損失を実際の損失がほぼ一致していることがわかります。このことから、適切なスケーリングができていることがわかります。
スケーリングに用いたモデルよりも大きいモデルでのLossの予測を行った結果が以下のようになります。

これは、モデルサイズを7B、一般データの比率を20%とした時の結果になります。青色の予測プロットに対して、赤色が実際の結果ですが、スケーリングに用いたモデルより大きなモデルに対しても適切に予測できていることがわかります。
このように適切なスケーリングを行うことで、以下のように混合データ比率を変えた際の一般、ドメイン損失を比較することができます。

よって、一般的な能力の低下を抑えつつ、ドメイン特化能力を向上させるための最適なデータ混合比率を見つけることが可能になります。
Cross-Domain D-CPT Lawでの結果は以下のようになりました。

これは、一般データを20%に固定した場合の各データ量、モデルサイズに対する損失の図になります。図から予測損失を実際の損失がほぼ一致していることがわかります。このことから、Cross-Domain D-CPT Lawにおいても適切なスケーリングができていることがわかります。既存のドメインから学習されたDLCのパターンを活用して、新しいドメインでの学習も適切に行うことができます。
まとめ
- 本研究では、モデルサイズ、データサイズ、混合比率に基づいて検証損失を予測するD-CPT Lawを提案し、学習コストを削減しながら最適な設定を探索可能にした。
- Cross-Domain D-CPT Lawを導入し、新しいドメインに対しても既存データからの学習を基に損失を予測し、トレーニングコストを削減した。
- 提案手法により、学習コストを抑えつつ、一般能力とドメイン特化能力の最適なバランスを見つけられることを実証した。
おわりに
EQUESでは引き続き、「最先端の機械学習技術をあやつり社会の発展を加速する」をミッションに研究開発と社会実装に取り組んでいきます。一緒に事業を創出する仲間を募集しています。詳しくは以下をご覧ください。
EQUESでは現在経産省・NEDO「GENIAC」の採択事業者として薬学分野・製薬業務に特化したLLMの開発に挑戦しています。この領域にご関心のある方のご連絡をお待ちしています。詳しくは以下もご覧ください。
Discussion