【論文紹介】FramePack解説
タイトル:Packing Input Frame Context in Next-Frame Prediction Models for Video Generation
ArXivリンク:https://arxiv.org/pdf/2504.12626
※ 本ページの図は特筆がない限り全て本論文から引用しています。
執筆者:EQUES ANIMINSチーム 田中龍之介
今回は「Packing Input Frame Context in Next-Frame Prediction Models for Video Generation」という論文を、メインとなるアイデアに重点を置いて紹介したいと思います。
概要
FramePackは6GB程度の小さいVRAMでも画像からの動画生成ができるという点で優れた技術です。本論文ではそれを実現するため、忘却(forgetting)とドリフティング(drifting)という2つの問題を解決するための提案がされており、それを既存の動画生成モデル(特にHunyuanVideoなどのDiTsモデル)と組み合わせて使用しています。また、本論文の実装がGitHubで公開されています。
用語解説
forgetting(忘却)
メモリの制約のため過去のコンテクストを切り捨てる時に起こる情報の欠損。これにより、時間が経つにつれて初期フレームの情報が薄れ、キャラクターの色や構図が崩れてしまう。
drifting(ドリフティング)
逐次生成のモデルにおいて、時間が経つにつれて誤差が雪だるま式に増大してしまう現象。
forgetting-drifting dilemma
forgettingとdriftingの2つの問題がトレードオフの関係であり、同時に解決するのが難しいというジレンマ。
メモリを強くすことでforgettingは抑えられるが誤差の累積も速くなってしまいdriftingが作新されてしまう。一方で、履歴への依存度を下げるとdriftingは抑えられるがforgettingが強くなってしまう。
改善手法
Anti-forgetting
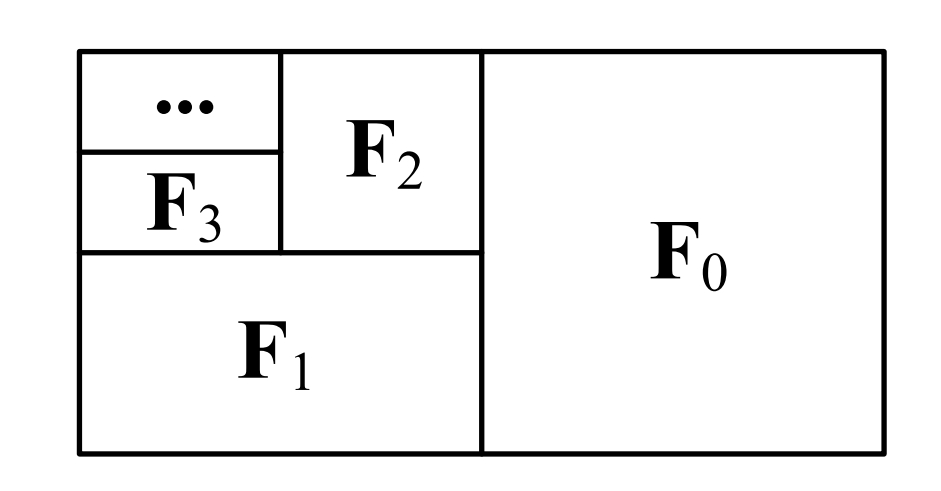
フレームの重要度に応じて等比数列的にコンテクスト長を与えることで、ビデオの長さに依存せずに総コンテクスト長を定数で抑えることができ、forgettingが根本的に解決されます。
具体的には以下のような式で各フレーム
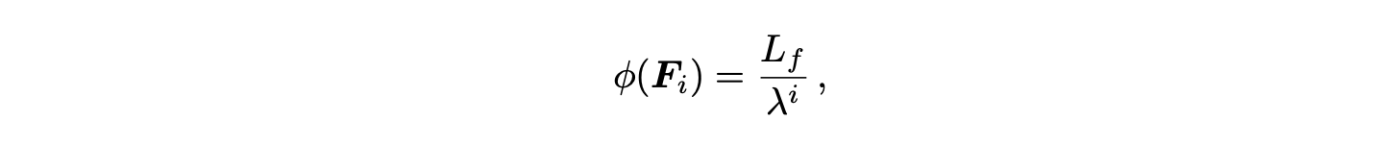
ただし

すると総コンテクスト長

ただし

以下は
また、収束する級数を考えれば以下のように多彩な圧縮を考えることができます。


この時に行うフレームごとの圧縮は、Transformerのパッチ化カーネル(patchify kernel)のサイズ・形状をフレームごとに変えることで実現しています。
Anti-drifting
FramePackでは、従来のモデルのように最初のフレームから順番に生成するのではなく、はじめに最後のフレームも生成してから中間のフレームを生成していくため、誤差が累積してしまうことを防ぎます。
FramePackは以下の(b),(c)の2手法を提案しています。
(a)従来のモデル。
(b)はじめに最初と最後のフレームを生成してからその中間を前から生成する。
(c)はじめに最初と最後のフレームを生成してからその中間を後ろから生成する

性能評価
モデルはGlobal Metrics, Drifting Metrics(driftingの幅・小さい方が劣化が少ない), 人間による評価の主に3カテゴリで評価された。
以下はHunyuan Video をベースにした、他の手法とFramePackの評価である。

提案された手法ではGlobal Metricsを従来の手法と程度に保ちつつ、Drifting Metrics は大幅に向上していることが分かる。
まとめ
- FramePackはDiffusion Transformerをベースとした動画の逐次生成モデル。
- 幾何級数的なメモリ構造を設計することで、動画の長さに依らず使用メモリ量を
O(1) - 先に最後のフレームも生成することで、時間経過につれてフレームが大きく劣化する現象(drifting)を防いだ。
おわりに
ANIMINS(アニミンズ, ANIMe INSight)はオー・エル・エム・デジタル社が実施するデータ・生成AI利活用実証事業です。AIを「ツールの一つであり、クリエイターをサポートするもの」と明確に位置づけ、アニメ制作現場でAIの利活用が本当にできるのかを徹底的に調査しています。
詳しくは以下のホームページもご覧下さい。
EQUESでは引き続き、「最先端の機械学習技術をあやつり社会の発展を加速する」をミッションに研究開発と社会実装に取り組んでいきます。一緒に事業を創出する仲間を募集しています。詳しくは以下をご覧ください。
Discussion