【論文紹介】Tensor Programs V
※ 本ページの図は特筆がない限り全て本論文から引用しています。
執筆者:EQUESエンジニア 武馬光星
今回は、「Tensor Programs V:Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer」 という論文を紹介したいと思います。Tensor Programs (TP)は、大規模ニューラルネットワークの挙動を理論的に解析するためにGreg Yang氏が開発した理論的枠組みで、「TP I」から「TP VI」までにわたってシリーズ化されています。シリーズVにあたるこの論文は、大規模モデルの効率的なハイパーパラメータのチューニング方法である「μTransfer」について提案を行っています。小規模モデルから大規模モデルへのハイパーパラメータの転送を行うことによって、従来よりも計算コストを抑えながら適切なハイパーパラメータチューニングを行うことを可能にしました。
はじめに
適切なハイパーパラメータを用いることは、モデルの学習の際に非常に重要です。ハイパーパラメータの選択が悪いと、 パフォーマンスが劣り、学習が不安定になってしまいます。しかし、モデルサイズが大きいモデルのハイパーパラメータをチューニングすることは難しく、計算資源や時間などの学習コストの問題も発生します。そこで本論文では、小規模モデルでチューニングしたハイパーパラメータを大規模モデルにゼロショットで転送できる「µTransfer」という新しい手法を提案しています。
従来手法と提案手法の比較を以下の図で示しています。
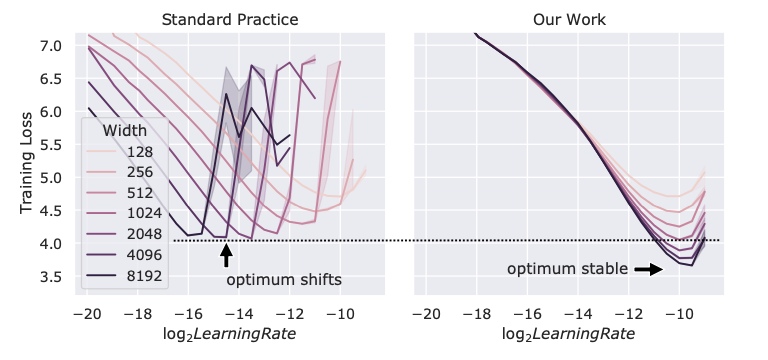
図から分かるように、従来の方法では、モデルサイズ(Width)が大きくなるにつれて、最適な学習率が変化していることがわかります。そのため、異なるモデルサイズのモデル間で同じハイパーパラメータを用いて適切な学習を行うことはできません。一方、提案手法では、モデルサイズが変化しても、最適な学習率がほぼ同じとなっています。また従来手法よりも学習Lossが低くなっていることがわかります。このことから、今回の提案手法では、ハイパーパラメータチューニングの際の学習コストを大幅に下げるだけでなく、より良いパフォーマンスを出すことができています。また、BERTやTransformer、GPTなどによらず、同じ構造のモデルであればこの手法を使うことが可能になっています。
このµTransferが適応可能なパラメータは以下のようになっています。


なお、*がついているものはTransformerのみ適応可能となっています。
グリッドサーチでハイパーパラメータをチューニングする従来の手法よりも、提案手法によって、かなり効率的なハイパーパラメータのチューニングが可能になりました。
ここでは、
従来のパラメータチューニング手法:Standard Parametrization(SP)
提案されるパラメータチューニング手法:Maximal Update Parametrization(μP)
と表記します。
従来手法(SP)での問題点
ニューラルネットワークの幅(隠れ層のニューロン数や埋め込み次元)が変化すると、最適な学習率が変動するため、従来の方法では異なる幅のモデル間で同じ学習率を使用すると学習が不安定になりやすいという問題があります。特に、従来手法では、モデルの幅が変わるたびに最適な学習率がシフトし、各層が異なる速度で更新されるため、学習のバランスが崩れやすくなります。
Transformerのような複雑なモデルでは、以下の図のように、SPを使用すると、モデルの幅が大きくなった場合にattention logitsの更新が急激になる一方で、単語埋め込みの更新はあまり変化がない傾向があります。この結果、全体の学習バランスが崩れ、モデルの安定性が損なわれます。
一方、μPを使用すると、各層の重みやバイアスのスケーリングを調整することで、全ての層が同じ速度で更新されるようにモデルが設計されます。μPでは、モデルの幅や深さに依存しない形でパラメータの初期化や更新をスケーリングするため、異なる幅のモデル間でも学習が安定し、最適なハイパーパラメータの転送が可能になります。
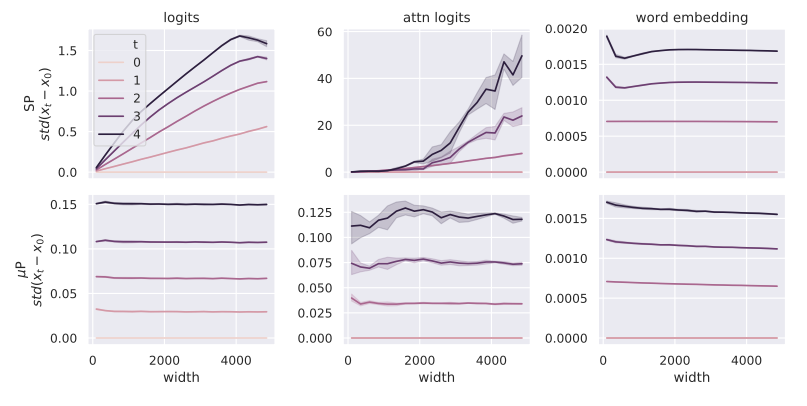
μPの手法
このμPの具体的な手法について紹介します。
1. モデルスケーリング
μPを実現するためには以下のようにモデルのスケーリングを行います。

赤字が今回新たに変更する部分になっています。fan_in、fan_outは、入力次元数、出力次元数を表します。これだけの変更でμTransferを実現することができるようになります。
例として、実際にAdamを使用した際の設定について紹介します。
パラメータの初期化
- 入力層のWeightと全てのバイアス:1 / fan_inでスケーリング
- 出力層のWeight:1 / fan_in^2でスケーリング
- 隠れ層のWeight:1 / fan_inでスケーリング
学習率
- 入力層のWeightと全てのバイアス:スケーリングなし
- 出力層のWeight:1 / fan_inでスケーリング
- 隠れ層のWeight:1 / fan_inでスケーリング
実装は以下のgithubに公開されています。
GitHub - microsoft/mup: maximal update parametrization (µP)
2. 小規模モデルでのハイパーパラメータチューニング
次に、大規模なターゲットモデル(実際にハイパーパラメータチューニングしたいモデル)の小規模モデルを準備し、小規模モデルでハイパーパラメータをチューニングします。小規模モデルは計算コストが少ないため、学習率などのハイパーパラメータをランダムサーチやグリッドサーチなどで効率よく探索することができます。先ほどのスケーリングによって、小規模モデルでのチューニング結果がターゲットモデルにも適用できるようになります。
3. 大規模ターゲットモデルへのハイパーパラメータ転送
小規模モデルで最適化されたハイパーパラメータを、そのまま大規模モデル(ターゲットモデル)に適用します。μPにより、幅や深さが異なるモデル間でのハイパーパラメータが安定しているため、追加のチューニングなしでターゲットモデルが安定して学習できるようになります。この手法により、従来必要だった大規模モデルでの直接チューニングが不要になり、計算コストが大幅に削減することができます。
実験結果
Transformer
Transformer 40Mをそのままハイパーパラメータチューニングした場合と0.25倍のTransformer、μPを使用した0.25倍のTransformerでの3通りのハイパーパラメータチューニングの比較を行いました。機械翻訳ベンチマークであるIWSLT14 De-Enで評価を行いました。
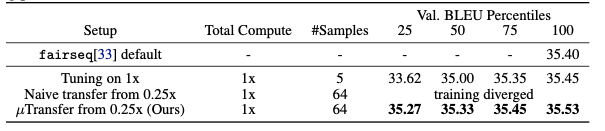
結果は、図のようになり、μPを使用した0.25倍のTransformerでハイパーパラメータチューニングをした場合が最も優れた評価となりました。一方、μPを使用しないで0.25倍のTransformerでハイパーパラメータチューニングした場合は、学習に失敗しています。また、~~従来手法(大規模モデルでそのままハイパーパラメータチューニング)~~従来手法(SP)よりも評価結果が優れていました。このことからμPを用いることで、Transformerにおいて、従来よりも最適なハイパーパラメータチューニングができていることがわかります。
さらに、Transformer 211Mを同じ3通りの手法で、WMT14 En-Deで評価した場合にも同様に、μPを使用した0.25倍のTransformerでハイパーパラメータチューニングをした場合が最も優れた評価となりました。
BERT
MegatronBERT(345M)をそのままハイパーパラメータチューニングした場合とBERT 13M、μPを使用したBERT 13Mでの3通りのハイパーパラメータチューニングの比較を行いました。
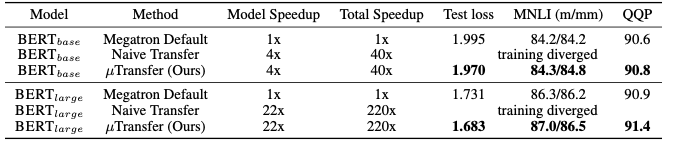
BERTでも同様に、μPを使用したハイパーパラメータチューニングが、学習コストの節約だけでなく、評価結果でも最も優れていることがわかりました。
GPT
GPT-3(6.7B)をそのままハイパーパラメータチューニングした場合とμPを使用したGPT-3(40M)でのハイパーパラメータチューニングの比較を行いました。
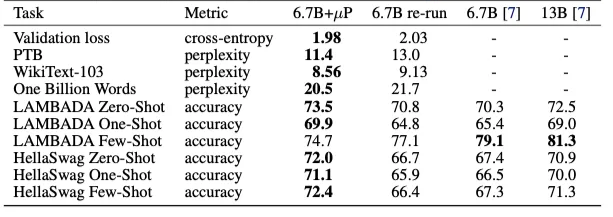
GPT-3においても、μPを使用した場合には、そのままハイパーパラメータチューニングするよりも評価結果が優れた結果となりました。モデルサイズが168分の1のモデルでチューニングすることに成功し、チューニングにかかった総コストは、従来の事前訓練にかかった総費用のわずか7%に抑えることができました。
また、興味深いのはμPを使用したハイパーパラメータチューニングによって、最適なチューニングを行うことで、13Bを超えるほどの評価精度を出していました。いかに適切なハイパーパラメータチューニングが大切かがわかります。
まとめ
- μPを用いることで、小規模なモデルでチューニングしたハイパーパラメータを大規模なモデルにそのまま適用できるようになる。(µTransfer)
- μPでは、モデルの幅に依存しない学習を行うことができる。
- BERTやTransformer、GPTなどによらず、同じ構造のモデルであれば適用可能。
- 従来の手法での学習よりも、学習コストを下げるだけでなく、より最適な学習率をチューニングすることで評価結果でも上回ることができる。
- 最適なハイパラメータチューニングによって、さらに大きいモデルに匹敵する精度を出すことができる。
個人的には、今回紹介したµTransferが継続事前学習にも適用可能なのか非常に興味を持ちました。継続事前学習は、既存のモデルを新しいドメインやデータセットに適応させるための重要な手法であり、さまざまな分野で広く利用されています。継続事前学習のような元のモデルのパラメータを活用したい場合にもこの枠組みを適用することができるのか、元の事前学習データと新しいデータとの相違が大きい場合でも適用することができるのかなどは今後の重要な研究テーマの一つになると感じました。
この枠組みが新しいドメインへの学習の適応を可能にするならば、さらに多くの分野での活用が期待されます。
おわりに
EQUESでは引き続き、「最先端の機械学習技術をあやつり社会の発展を加速する」をミッションに研究開発と社会実装に取り組んでいきます。一緒に事業を創出する仲間を募集しています。詳しくは以下をご覧ください。
EQUESでは現在経産省・NEDO「GENIAC」の採択事業者として薬学分野・製薬業務に特化したLLMの開発に挑戦しています。この領域にご関心のある方のご連絡をお待ちしています。詳しくは以下もご覧ください。
Discussion