【論文紹介】PharmaGPT
タイトル:PharmaGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry
執筆者:EQUESエンジニア 武馬光星
※ 本ページの図は特筆がない限り全て本論文から引用しています。
今回は、「PharmaGPT: Domain-Specific Large Language Models for Bio-Pharmaceutical and Chemistry」という論文を紹介したいと思います。この論文では、バイオ医薬および化学分野に特化したドメイン特化型LLMを提案しています。本記事では、PharmaGPTの背景、アーキテクチャ、学習手法、評価などについて、論文に基づきながら解説していきたいと思います。
はじめに
ChatGPTやClaudeに代表される大規模言語モデル(LLM)は、文書の要約、翻訳、質問応答、コード生成など、従来は個別の機械学習モデルが必要だったタスクをこなせるようになりました。この汎用知能化は、膨大なパラメータとトレーニングデータを活用したことで実現しました。
しかし、このようなLLMにはいくつか課題が残されています。特に課題として挙げられるものが、専門領域への応用です。医薬・化学・法務・金融といった分野では、高度な専門知識と厳密な用語の理解が求められます。これらの分野では、誤った情報は社会的・倫理的に重大な結果を招くため、モデルの精度や信頼性が非常に重要となります。
多くの汎用LLMは、一般的な文書から学習しているため、専門用語に対する知識の深さや文脈理解には限界があります。例えば、医薬品の名称や化学構造、臨床ガイドラインなどにおいて、専門家から見て不十分な応答が見られます。さらに、英語中心のデータに依存しているため、多言語対応や各国の制度への理解も弱い傾向があります。
本論文で紹介される「PharmaGPT」は、バイオ医薬および化学分野に特化したドメイン特化型LLMです。パラメータ数は13Bおよび70Bで、OpenAIのGPT-3.5やGPT-4よりも小さい規模ながら、専門タスクでこれらの汎用LLMを凌駕する性能を示しました。
背景
LLMの基本的な仕組みとして「Language Modeling」が挙げられます。これは、ある単語列が出現する確率を学習し、新たな文を生成するという考えに基づいています。初期のn-gramモデルから始まり、Word2VecやGloVeのような単語ベクトル手法を経て、BERTやGPTのような文脈を加味したモデルへと発展してきました。
特に現在の主流は、Transformerをベースにした自己回帰型モデルで、文の前半をもとに次に来る単語を予測します。さらに、最近ではモデルのスケーリング(パラメータ数やデータ量の拡大)によって、タスク固有の事前学習なしでも高精度に処理できる「zero-shot」や「few-shot」と呼ばれるコンテキスト内での学習が行われています。
こうした技術の進化により、医薬・化学分野にもLLMの活用が広がっています。たとえば、BioBERTやChemBERTaといった分野特化モデルは、論文データなどを元に訓練され、疾患や薬品名、化学構造に関する文脈理解に長けています。これにより、以下のような応用が可能になりました:
- 新規タンパク質の機能性の予測
- 化学反応の予測と最適化
- 望ましい特性を持つ実現可能な化合物の提案
しかし課題は多く、汎用モデルでは対応が難しい細かい知識や表現に対応するには、より深く専門的な知識を組み込んだLLMが必要とされています。
データセット
PharmaGPTは、バイオ医薬・化学分野に特化した大規模データセットで訓練を行いました。その内訳は、以下のようになっています。
このように多岐にわたるソースから集められたデータにより、PharmaGPTは単なる単語の暗記ではなく、実際の応用文脈に強いモデルとして設計されました。
PharmaGPTでは、言語数を絞り込み、英語と中国語を中心の学習データを構成しています。これは、対象分野で主に使われる言語に集中することで、ドメイン内での深い理解と精度の向上を図るためです。
データの収集後には、以下のような工程を経てモデル学習に適したデータに整えられました:
- スクレイピング:PDFやHTMLから自動収集するために、テキストを抽出する新しいツールを開発
- 高品質フィルタリング:「人間が人間のために書いた自然なテキスト」を基準としたフィルタリング
-
重複除去・匿名化:文書単
 位での厳格な重複排除と、正規表現ベースでの個人情報の除去
位での厳格な重複排除と、正規表現ベースでの個人情報の除去
モデルの学習
PharmaGPT は以下の3つのステップで学習を行う:
- 継続事前学習(Continual Pre-training)
- Instruction Fine-tuning
- 人間のフィードバックによる強化学習(RLHF: Reinforcement Learning from Human Feedback)
継続事前学習
PharmaGPT 70Bは、MetaのLLaMA2モデルをベースに、医薬・化学分野に特化した文献データで継続事前学習を行っています。これにより、一般的な文法・語彙力を維持しつつ、専門性の高い知識の学習を行います。また、SentencePieceを使って新たなBPEトークナイザを構築し、LLaMA2の語彙と統合します。語彙サイズが55,296に拡張された新しいトークナイザーとなり、中国語テキストと固有なドメインに対するトークン圧縮効率を高めます。この新しいトークナイザに対応するため、単語の埋め込みと出力のサイズも変更しました。
以下の2段階に分けて学習を行う:
- フェーズ1(153Bトークン):Web、ニュース、論文、特許を中心としたデータで基盤知識を学習
- フェーズ2(43Bトークン):報告書、試験問題、対話、コードなどのデータで応用力を強化
この継続事前学習により、PharmaGPTは専門性と応用力の両立を図ります。
詳しい実験設定は以下の通りです。

Instruction Fine-tuning
次に、モデルを実際の応答形式に近づけるため、instruction形式のデータでFine-tuningを行います。これは、ユーザーがプロンプトを入力した際に、自然かつ適切な応答を出すための学習となります。T0モデルの手法に基づき、多数の自然言語プロンプトで多様なタスクの学習を行いました。以下の式に基づいて学習を行います。

この時、プロンプトはLossの計算から除外します。また、αは学習時の重みとなっていて、ドメインに近いデータでFine-tuningする場合に、重みが大きくなるように設定されます。
RLHF
最後に、RLHFを通じてモデルの応答を人間の判断に近づける最適化が行ないます。人間の判断や倫理的配慮により近づけることで、モデルの性能をさらに向上させることが期待されます。薬物作用の予測や治療法の推奨など、特定のタスクでモデルの出力を評価する領域経験者からのフィードバックに基づいてデータは作成します。
****Reward Modelは、PharmaGPT-70Bを用いて、各応答に対して「どれくらい好ましいか」を数値スコアで予測するモデルとして学習されます。この時、以下の式に基づいて学習を行います。
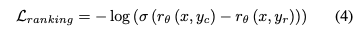
これにより、好ましい応答のスコアがより高くなるようにモデルが学習されます。
上で学習した報酬モデルを使ってPPOによる強化学習を行い、モデルの学習を行います。各プロンプトに対し4つの応答を生成し、最も高スコアな応答だけを使って学習を進めるという手法が採用されています。
評価
PharmaGPTの性能を検証するにあたり、著者らは以下の3点を重視しました:
- 実際の業務・試験に近いタスク設定
- 汎用モデル(GPT-3.5, GPT-4など)との比較
- 言語・分野の多様性をカバー
これらの評価を行うために、以下の4つのタスクで評価を行いました。
- **Multitask Multilingual Language Understanding (MMLU):**複数分野・複数言語にまたがる選択式問題を通じて、モデルの一般知識・言語理解力を評価するベンチマーク
- **Machine Translation:**英語↔中国語の医学・化学文の翻訳
- **NAPLEX(北米薬剤師試験):**米国で薬剤師資格を取得するための国家試験
- **中国薬剤師試験:**中国語で出題される国家試験
それぞれの結果を以下に示します。
- MMLU
結果は図8のようになりました。特に生物学、医学、解剖学、生理学に関連するタスクにおいて、PharmaGPTはGPT-3.5-turboよりも高いスコアを達成するだけでなく、多くの場合、GPT-3.5-turboに大差をつけました。また、PharmaGPTは、いくつかのタスクでGPT-4に近いスコアを記録し、生理学、健康科学、生物学などの分野ではGPT-4をわずかに上回ることもありました。

- Machine Translation
PharmaGPT、GPT3.5、CLAUDE3、GOOGLEの4つの言語モデルの性能を、生物医学論文の翻訳タスクで評価しました。段落、文、単語の3つの粒度で翻訳品質はBLEUを用いて評価を行います。結果は図7に示されました。
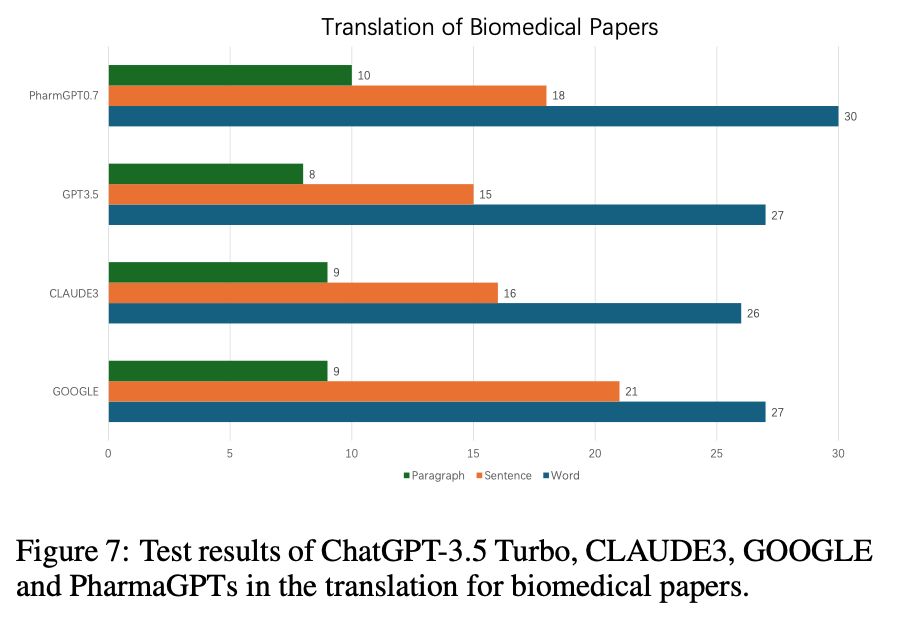
これらの結果からPharmaGPTは、生物医学論文の翻訳において非常に優れた性能を発揮することが明らかになりました。この結果は、PharmaGPTが生物医療分野のニュアンスや複雑さを捉えるのに適していることを示唆しました。また、段落、文、単語の各レベルで高い翻訳品質を維持できることから、PharmaGPTは、生物医学論文内のさまざまな文脈に対応できる頑健性と適応性を備えていると言えます。
- NAPLEX
結果は図5に示されました。NAPLEXの3つのセクションすべてにおいて、PharmaGPTモデルは70~80%のスコ アを達成しています。この高いスコアは、PharmaGPTモデルが包括的な薬学文献と教育データで効果的にトレーニングされていることを示唆しています。また、NAPLEXのすべてのセクションにおいて、PharmaGPTはGPT-3.5- turboを上回っています。これらの結果から、ドメインに特化した学習の優位性を確認することができました。

- 中国薬剤師試験
結果は図6に示されました。4つの試験カテゴリすべてにおいて、PharmaGPTモデルはいずれも70~80%のスコアを達成し、医薬知識および関連分野における強力な能力を実証しました。また、NAPLEXと同様に、すべての試験カテゴリーにおいて、PharmaGPTモデルはGPT- 3.5-turboのパフォーマンスを上回っています。PharmaGPTモデルが4つのカテゴリーでGPT-4よりも高いスコアを達成しました。これらのことからも、ドメインに特化した学習の優位性を確認することができました。

まとめ
本記事では、医薬・化学分野に特化した大規模言語モデル「PharmaGPT」について、その設計方針から訓練方法、そして評価結果までを見てきました。
PharmaGPTは、単に巨大なモデルを構築するのではなく、専門性に特化した高品質なデータと、命令調整・RLHFによる学習を通じて、専門領域で実際に使えるレベルの性能を実現しました。特に、GPT-4を上回る正答率を示した薬剤師試験の結果や、英中翻訳でのBLEUスコアは、ドメイン特化型LLMの可能性を強く裏付けました。
また、PharmaGPTの開発プロセスでは、プライバシーや偏りといった倫理的配慮にも重点が置かれています。
今後、PharmaGPTのような特化型モデルが、法律・金融・環境・教育などの他分野にも応用されていくことで、より精度の高い・現場で信頼されるAIの実現が期待されます。
おわりに
EQUESでは引き続き、「最先端の機械学習技術をあやつり社会の発展を加速する」をミッションに研究開発と社会実装に取り組んでいきます。一緒に事業を創出する仲間を募集しています。詳しくは以下をご覧ください。
EQUESは経産省・NEDO「GENIAC」の採択事業者として薬学分野・製薬業務に特化したLLMの開発、およびその社会実装に挑戦しています。この領域にご興味ある方のご連絡をお待ちしています。詳しくは以下もご覧ください。
Discussion