はじめに
はじめまして、EpicAIでインターンをやっておりますSwkimaです!
早速ですが、Xでこんな投稿を見つけました
どうやら、M4 Mac Mini 4台とMacBook Pro M4 Maxをつなげた5台のクラスタを作り、LLMのパイプライン並列をやっているみたいです
「こんなんかっこよすぎるけど金かかりすぎだろ...」
ということで、ギリギリ大学生らしく"安く"LLMパイプライン並列を試していこうと思います
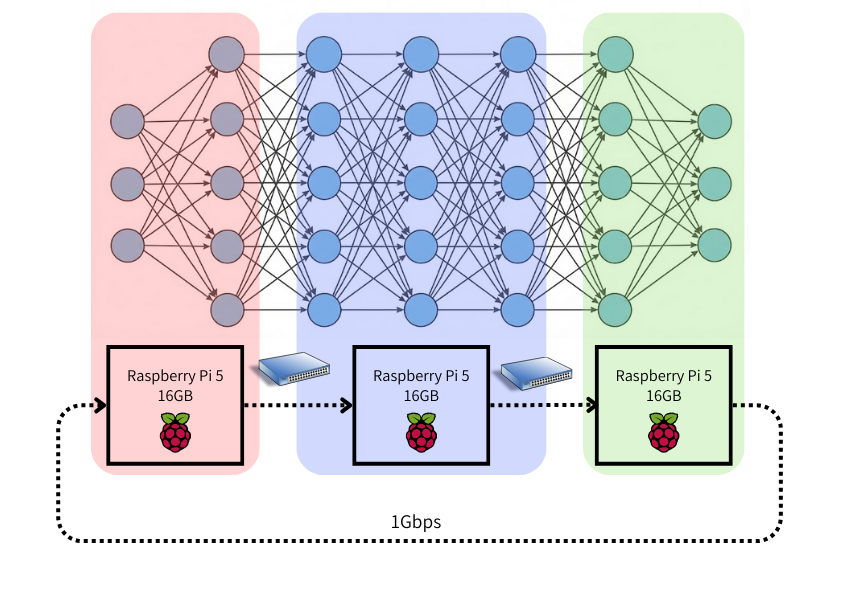
アーキテクチャ概要
ハードウェア
今回購入したものはこちら

| 名前 | 一個あたりの金額 | 個数 |
|---|---|---|
| Raspberry Pi 5 / 16GB | ¥22,440 | 3 |
| USB電源アダプター 5V 5A Type C (Pi 5用) | ¥2,420 | 3 |
| Piケース 金属製 ヒートシンク (Pi 5用) | ¥1,166 | 3 |
| エレコム スイッチングハブ ギガビット 8ポート | ¥5,980 | 1 |
| エレコム LANケーブル CAT6A 1m | ¥487 | 3 |
| KIOXIA microSD 64GB | ¥740 | 3 |
| 合計 | - | 約 ¥90,000 |
(今回はラズパイが3個使われていますが、最安でパイプライン並列を試すだけなら2個で十分です)
早い話がRaspberry Pi 5 16GBをつなげてクラスタを作って、LLMを動かそう!ということです。実際、Adafruitというラズパイの周辺機器などを扱っている電子工作企業が「ローカルでGemma動かせるぜ」と言っているくらい、Raspberry Piの性能は向上しています。ただし、あくまで小さなモデルに限られ、パラメータ数は一桁Bが関の山です。
通信にはギガビットスイッチを使うので、Raspberry Pi間の通信速度は理論上Max1Gbpsとなります。一般的なLLMの分散処理システムなら10Gbpsが出る10ギガビットイーサネットやThunderbolt (数十Gbps)を使うらしいですが、今回は予算の都合上ギガビットスイッチを利用します。
ソフトウェア
exoを使います
exoとは、複数のPCやデバイス(Windows PC、Mac、Raspberry Piなど)を束ねて「自宅に AI クラスターを構築」できるようにするオープンソースソフトウェアのことです
本来クラスタリングをしようと思うとk8sなどの面倒な設定が必要ですが、exoならただexoを立ち上げるだけで自動で他機器を認識して接続を行ってくれます
これはかなり革新的だと感じたので、後ほど解説します
最終的な全体像はこのようになりました
ハードウェア↓

exoでの論理的な繋がり↓3つのラズパイが三角形に繋がっていることがわかります。

イメージ的にはこんな感じ↓
準備も揃ったところで、いざLlama-3.1-1Bを分散処理していきます!
試した結果
⚠静止画ではありません

もうおっっそい。泣いちゃう
一番最初のトークンが生成されるまでに59.27sec、Tokens/secは0.2という結果になりました。ただ、一応出力自体はできていて、最終的な応答は以下のようになりました。
💬who are you?
🤖I'm an artificial intelligence model known as Llama. Llama stands for "Large Language Model Meta AI."Llama 3.2 1B- 59.27 SEC TO FIRST TOKEN 0.2 TOKENS/SEC 22 TOKENS
exoとは
今回使用した exo ですが、一言で言うと「手持ちのデバイスを束ねて、一つの巨大なGPUとして扱えるようにする」オープンソースソフトウェアです。
通常、LLMの分散推論(複数のマシンでAIを動かすこと)を行おうとすると、ネットワーク設定やモデルの分割(シャーディング)、データの同期など、インフラ・ネットワーク・分散処理の細かい知識と面倒な設定が山のように必要になります。Kubernetesでクラスタを組んで、パイプライン並列化をするDockerfileを書いて...と作業量が膨大になります。
しかし、exoは以下の特徴によってこれらのプロセスを劇的に簡略化しています。
1. 動的パーティショニング (Dynamic Model Partitioning)
これがexoの最大の肝です。通常、LLMのモデルを複数のデバイスに分割する場合、「誰がどのレイヤーを担当するか」を手動で決める必要があります。
一方exoは、接続されたデバイスのメモリ(RAM/VRAM)容量を自動的に検出し、「Ring Memory Weighted Partitioning」 という戦略を用いて、メモリ容量に比例してモデルのレイヤーを自動配分します。
実際にexoのコードを見てみましょう (main/exo/topology/ring_memory_weighted_partitioning_strategy.py)
コードがやっていることは、
メモリの大きいノードにより多くのレイヤーを割り当てる
という非常に単純な仕組みです。
###以下はコードの抜粋###
class RingMemoryWeightedPartitioningStrategy(PartitioningStrategy):
def partition(self, topology: Topology) -> List[Partition]:
nodes = list(topology.all_nodes())
nodes.sort(key=lambda x: (x[1].memory, x[0]), reverse=True)
total_memory = sum(node[1].memory for node in nodes)
partitions = []
start = 0
for node in nodes:
end = round(start + (node[1].memory/total_memory), 5)
partitions.append(Partition(node[0], start, end))
start = end
return partitions
思っていたよりもシンプルなコードです。具体例として8GBのラズパイと16GBのMacがある場合を考えながら、コードを読み解いていきましょう。
コード前半では、まず準備として
nodes = list(topology.all_nodes())
nodes.sort(key=lambda x: (x[1].memory, x[0]), reverse=True)
total_memory = sum(node[1].memory for node in nodes)
でノードのリストに[8GBのラズパイ,16GBのMac]が渡され、メモリ容量の降順にソートされます。その後、クラスタ全体のメモリ総量24GBがtotal_memoryに格納されます。
続いて
partitions = []
start = 0
for node in nodes:
end = round(start + (node[1].memory/total_memory), 5)
partitions.append(Partition(node[0], start, end))
start = end
return partitions
にて、各ノードについて、round(start + (node[1].memory/total_memory), 5)が計算されることで、各ノードのメモリ/総メモリの割合に応じてニューラルネットワークの層が割り当てられることになります。
上記のフローによって最終的に8GBのラズパイ:16GBのMac = 1:2の割合で計算負荷(レイヤー数)を自動分割してくれます。
また、通常の分散フレームワークでは、同じGPU(例:A100 x 8枚)で揃えることが前提(らしい)です。つまり、exo公式が言うような「2 x Raspberry Pi 400 with 4GB of RAM each (running on CPU) + 1 x 8GB Mac Mini」といった異機種でクラスタを組むことはあまり好まれません。
しかしexoは、推論エンジンとしてMLX (Apple Silicon用)、tinygrad (AMD/NVIDIA/CPU用)、PyTorch (汎用) をバックエンドで使い分けることで、MacBook、ゲーミングPC、そして今回のRaspberry PiのようなCPUデバイスを一つのクラスタに混在させることを可能にしています。OSすら超えたクラスタが簡単に組めるのは驚きです。
2. 自動デバイス認識(Automatic Device Discovery)
exo はノード (デバイス) 間で自動的に発見 (device discovery) を行う機構があり、手動で設定をすることなくLAN 内にある複数のマシンを自動でクラスタ化してくれます。同じネットワーク内に exo を起動したデバイスがいれば、P2Pで勝手にお互いを見つけ出し、即座にクラスタリソースとして統合されるということです。
一番驚いたのは、「どのノードでも、いつexoを立ち上げてもOK」という点です
いわゆるリッスン状態で接続を待つようなことは必要なく、ターミナルでexoを打てば任意のタイミングで勝手に接続が完了します
3. GPT互換のAPIを自動提供(ChatGPT-compatible API)
exoは起動するだけでChatGPTライクなAPIエンドポイントを提供してくれます。ローカルLLMを使った閉じたサービスを開発する際に、APIまで自動で用意してくれるというのは魅力かもしれません。
さらに、"試した結果"の部分でお見せしたChatGPTっぽいWeb UIも提供してくれます。本当に至れり尽くせりです。
まとめると
上記3つをexoを立ち上げるだけで自動でやってくれるわけですから、"インフラよりも、LLMを動かしたり研究したりすることに集中したい"というニーズに明確に答えています。すごい。
セットアップ
exoの起動は簡単ですが、OSのインストールから依存関係の解消までを3台分やろうとすると手間がかかります。ラズパイ側でやることは基本的に以下のフローだけですが、必要に応じてAnsibleなどの構成管理ツールを使うと良いでしょう。
- "Ubuntu Server 24.04.3 LTS"をラズパイ用MicroSDに焼く
↓ - 各ラズパイのIPを固定し、手元のデバイスからssh接続
↓ - 依存関係のインストール
↓ - exoのインストール
↓ -
exoで起動、モデルのダウンロード
"1. 2." は省略します。探せばいくらでも詳しい記事がありますし、わからなかったらGeminiやGPTに聞きましょう。
個人的に3. が一番詰まったので、3.以降の手順について解説します
依存関係のインストール
ubuntu serverが立ち上がってssh接続が終わったら、下記のコマンドを実行してください
sudo apt update
sudo apt upgrade
sudo apt install python3.12-venv python3-pip libdrm-dev libgl1 libglib2.0-0 libsm6 libxext6 clang
補足
一応、各パッケージがなぜ必要なのかを軽く補足します
-
python3.12-venv, python3-pip: Pythonの仮想環境を建てるのに必要 -
libdrm-dev, libgl1, libglib2.0-0, libsm6, libxext6: exoの立ち上げに必要Ubuntu Server に必要なGUI系のライブラリなどを含む -
clang: GPTライクなWeb UIを利用する際にこれが無いとエラーが発生(より正確に言えば、Pythonのパッケージが内部的に利用するC/C++の拡張モジュールをビルドするために必要となる)
これらが事前に入っていないと、exo導入後にエラーが頻発して手戻りが発生しまくる(体験談)ので、入れておくことをおすすめします
exo自体のインストール
公式に従えばOKですが、Ubuntu Server では仮想環境を使わずにexoを含むpythonのライブラリをインストールしようとすると警告が出ます。git clone後に設定しておきましょう。
git clone https://github.com/exo-explore/exo.git
cd exo
(以下は私の行ったフローです。ここから先は公式に従えば問題ありませんが、念の為記録に残しておきます。)
ここで必要なら仮想環境を準備
python3 -m venv venv-exo
source venv-exo/bin/activate
llvmliteのインストール
pip install llvmlite
exo自体のインストール
pip install -e .
実行
exo
もしllvmliteに関するエラーが出たら
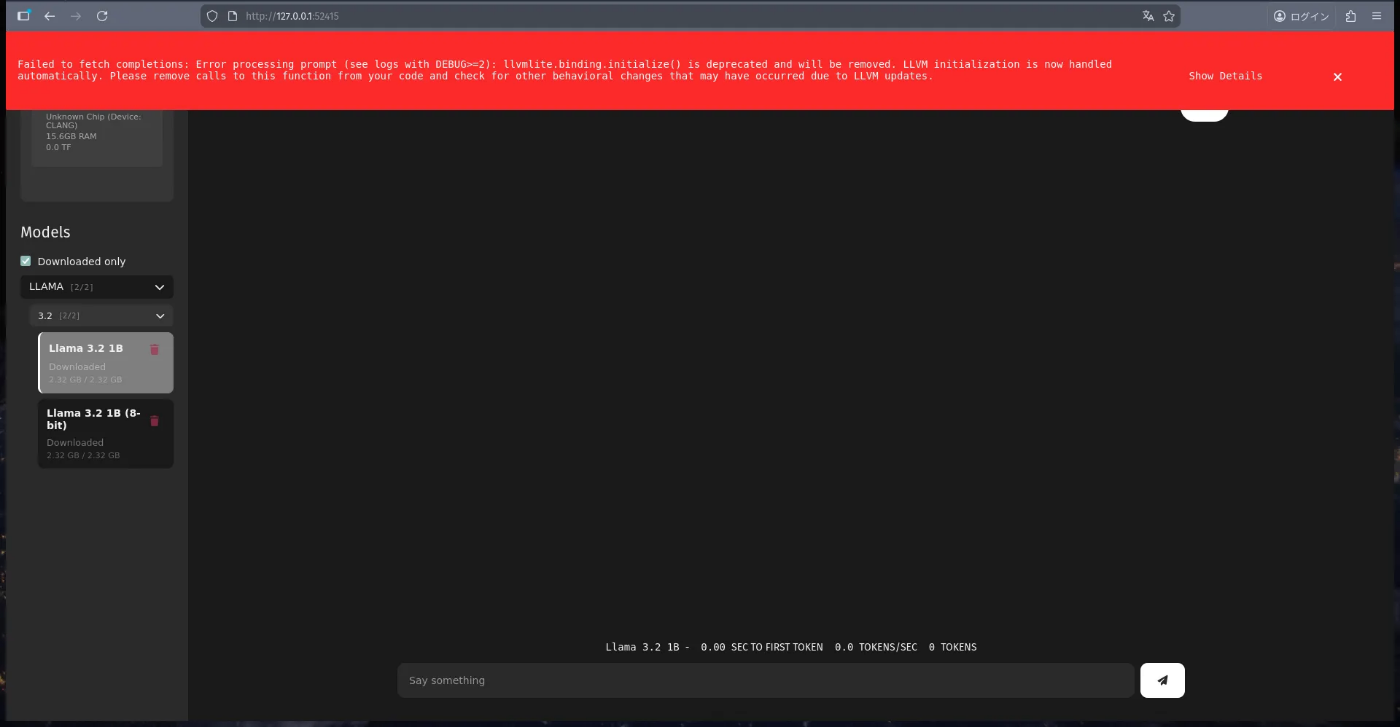
こういったエラーが出たら、まずはllvmliteのバージョンを確認してください。
どうやら、2025年12月8日現在ではexoがllvmliteのバージョンが0.44以下であることを想定しているらしく、llvmlite のバージョン0.45↑系だと破壊的な変更が加えられているためこのようなエラーがでるっぽいです
解決策としては、llvmliteのバージョンをダウングレードするのが一番手っ取り早いです
pip uninstall llvmlite
pip install llvmlite==0.44.0
3台のラズパイそれぞれで exo コマンドを叩くと、ターミナルに以下のようなグラフができます。これが出れば成功です!
勝手にお互いを認識し、クラスタが構築されました。
あとは、メインとなる操作端末からexoのターミナルUI上部に書いてあるWeb UI(ChatGPTっぽい画面)にアクセスして、モデルを選んでチャットを投げるだけです。
ブラウザからWeb UIへのアクセスが拒否される場合はSSHローカルポートフォワーディング(SSHトンネル)を作りましょう(これもLLMに聞けばすぐ答えてくれます。参考までに)
ボトルネックの特定
さて、本題の「なぜ0.2 tokens/secなのか」です。人間が読める速度が大体5〜10 tokens/secと言われているので、その25〜50倍遅いことになります。カップラーメンが出来上がる間に20単語くらいしか喋ってくれません。
今回の場合ボトルネックは明白で、ネットワーク& ハードウェアの速度です。
ネットワークの速度
今回の構成では、各ラズパイは 1Gbps (ギガビットイーサネット) でハブに繋がっています。
パイプライン並列処理では、前のデバイスが計算した結果(Activations/Tensors)を次のデバイスに送る必要があります。LLMの推論において、このデータ転送はトークンごとに発生します。
今回のケースでは、
- 通信頻度: 1トークン生成するたびに、巨大なデータを隣のラズパイに送る必要がある
- 帯域幅: 1Gbps = 理論値 125MB/s。実効速度はもっと落ちて、恐らく100MB/s程度
CPU推論で使うRAMですら最近のものは20GB/sのアクセス速度を保証することを鑑みると、1台のRaspberry Pi 5でLLM全体を実行する場合と比べてネットワークでの通信が 200倍遅いことになります
よって、計算そのもの(CPUの処理)よりも、「隣のラズパイにデータを送る待ち時間」 が大半を占めていると考えられます。
実際、同じパラメータサイズ1Bのモデルをラズパイ1台で動かした検証を行っている記事を見ると、明らかにexoを使う場合より早く動いています...
ちなみに、データセンターで使われるようなGPUクラスタでは、NVLink (900GB/s) や InfiniBand (400Gbps = 50GB/s) という、桁違いに速いネットワークを使っているそうです。
ハードウェアの速度
GPUが無いのが大問題です
いくらメモリが16GBになったラズパイを3台繋げたとて、しょせんは27Wの消費電力しか使わないRaspberry Pi のCPUでLLMを動かすので、計算スピードなんてたかが知れています
反省と今後
今回の検証を行うにあたって2点反省が得られたので、次初期投資の必要な検証をするならどうするか?という視点でまとめておきます
1. インフラは導入前に妥当性を検証しよう
コードはなにか間違いがあってもすぐ直せますが、インフラはそうは行きません。特に、今回のRaspberry Piやスイッチのような物理的なインフラは、一度購入してしまえば基本的にお金は返ってきません。
実は、当初の目的は1つのPCでは動かないレベルのパラメータ数(13Bくらい)の大きいLLMをクラスタリングを使ってローカルで動かすことでした。ただ、結果としては1Bで試せばもはやそれが不可能なことがわかる程度に、理想と現実が乖離していました。
今思えば、同じ9万円の予算だったとしても
- 一旦Raspberry Pi 5 16GB 1台でLLMを動かしてみて、クラスタリング後の速度を想像する
- 予算内でGPUを複数個買って、それらをクラスタリングする
という検証をした方が遥かに現実的だったと思います。
ネットワークやハードウェアのボトルネックは少し計算すればわかります。今回はそれを分かった上で安さと体験だけを求めたわけですが、「実際にやってみて、トークン生成の様子を眺めながら『あ、これ計算と通信待ちで無理だな』と肌で感じる経験」は、机上の計算だけでは得られない貴重な一次情報でした。
ボトルネックがどこにあるのかを体感として理解できたことは、今後のエンジニア人生において「なぜ遅いのか」を直感的に特定するための大きな糧になるはずです(と、自分に言い聞かせて検証不足を正当化しています)。
2. 他の人の意見に耳を傾けよう
検証の前段階で、何人かの人から「GPU無いと無理では」という指摘を頂いてました。
当時は「いやいや、最新のRaspberry Pi 5は1台でもLLMが動くし、exoならソフトウェアの力でなんとかしてくれるはず!」という謎の自信で突っ走ってしまいましたが、物理的な制約(帯域幅)はソフトウェアの工夫だけでは超えられない壁があることを痛感しました。
今振り返ると、有識者の「GPUがないと厳しい」「帯域がボトルネックになる」という意見は、考えてみれば当たり前のことでした。それを「やってみないとわからない」という言葉で片付けず、もっと真摯に受け止めて計算してみるべきでした。
次にお金のかかる新しい技術構成を試すときは、まずはミニマムな構成(例えばラズパイ1台+α)で実測値を取り、そのデータを元にスケールした時の性能を予測してから、本格的な機材購入に踏み切ろうと思います。
さいごに
「遅すぎてだめ、もはや1台で動かすより遅い」という悲しい結果になりましたが、ひとまずLLMの分散処理を体感できて良かったと感じています。GPUの必要性を身を持って感じました。
残ったRaspberry Pi 5とスイッチは、Kubernetesで遊ぶ実験場として使おうと思います。結局すごくお金かかったので
皆さんも、押入れに眠っている古いPCを全部繋げて、最強の「自宅LLMキメラ」を作ってみてはいかがでしょうか?
それでは
参考
- https://learn.adafruit.com/local-llms-on-raspberry-pi/overview
- https://zenn.dev/hellorusk/books/e56548029b391f
- https://github.com/exo-explore/exo
- https://blog.exolabs.net/day-1/
- https://ledge.ai/articles/distributed_llm_exo_home_cluster
- https://www.youtube.com/watch?v=J4fapEFQOk0
- https://qiita.com/nijigen_plot/items/ebd64d7257b0b4f6d952

Discussion