で、JOINで結合するクエリの実行計画(MySQL)はどうやってみればいいの?
MySQLの実行計画、EXPLAINの見方といえば奥野幹也さんのこの記事が有名ですね。
すでに15年ほど前の記事だということが驚きですが、私もディスプレイがすり減るほど読んだ記憶があります。
今では「MySQL EXPLAIN」や「MySQL 実行計画」などで検索すれば、図を使って詳細に説明された記事をたくさん見ることができます。
やっぱりEXPLAINの見方がわからない
これらの記事を読んで「さぁ実際にパフォーマンスチューニングしていくぞ」と意気込んだ当時の私はコンソールの出力を見て絶望することになりました。
mysql> EXPLAIN SELECT * FROM actor INNER JOIN film_actor ON film_actor.actor_id=actor.actor_id INNER JOIN film ON film_actor.film_id=film.film_id WHERE actor.last_name LIKE 'a%' AND film_actor.last_update='2006-02-15 05:05:03' AND film.title LIKE 'c%';
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
| 1 | SIMPLE | film_actor | NULL | ALL | NULL | NULL | NULL | NULL | 5462 | 10.00 | Using where |
| 1 | SIMPLE | actor | NULL | eq_ref | PRIMARY,idx_actor_last_name | PRIMARY | 2 | sakila.film_actor.actor_id | 1 | 5.00 | Using where |
| 1 | SIMPLE | film | NULL | eq_ref | PRIMARY,idx_title | PRIMARY | 2 | sakila.film_actor.film_id | 1 | 9.20 | Using where |
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
_人人人人人人人人人人人人人人人人人人人人人人人人人人_
> JOINされたクエリの実行計画の見方が全然わからない <
 ̄Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y ̄
いろいろな記事を見て単一テーブルの実行計画の見方とチューニングはわかるようになったけど、結果が1行以上になると何が何やらわからない。
そして、実際のシステムで使われているクエリはほとんどが複数テーブルをJOINするので、結局パフォーマンスチューニングができない。という現実が待っていました。
当時はこのあたりを解説したページはあまり見当たらず(今はそんなことはないのかも)、上記の奥野さんのページでもJOINやサブクエリについて触れられてはいるものの、記事としてはその点にフォーカスしたものではなくサラッと書かれていたため、その時の自分では理解が追いつきませんでした。
みんなどうやってこのあたりを勉強しているのだろうと思っていたら、会社でも偶に聞かれることがあったため、せっかくGWなのでこれをネタに記事を書いてみました。
Nested Loop Join
この記事で解説するクエリは単純なNested Loop Join(NLJ)での実行計画となります。
MySQLでは他にもHash JoinやBlocked Nested Loop Joinなどの結合アルゴリズムがありますが、多くの場合は単純なNLJが採用されると思います。
3 つのテーブル t1、t2、および t3 間の結合が、次の結合型を使用して実行されるとします。
Table Join Type
t1 range
t2 ref
t3 ALL
単純な NLJ アルゴリズムを使用した場合、結合は次のように処理されます。for each row in t1 matching range { for each row in t2 matching reference key { for each row in t3 { if row satisfies join conditions, send to client } } }https://dev.mysql.com/doc/refman/8.0/ja/nested-loop-joins.html より引用
これを見ると分かる通り、NLJでは駆動表から条件にマッチする行を1行取得して、それを次の内部表と結合している事がわかります。
嘘です「わかります」と書きましたが、実はこれが全然わかりませんでした
なんとなくわかった気はするものの、やはり擬似コードだけではイメージがし辛いかと思います。
ということで、理解を助けるために私が頭の中でいつも考えているイメージを説明してみようかと思います。
記事で使用するデータ
この記事でサンプルとして使用するデータはMySQLが公式で提供しているSakila Sample Databaseを使用します。
複数のテーブルが存在しますが、今回は「actor(役者)とfilm(映画)、film_actor(映画の出演者情報の関連付け)の3テーブルだけを使用します。
各テーブルの関係については上記のリンク先に画像が掲載されています。
テーブル定義は以下の通りです。
actorテーブル
mysql> SHOW CREATE TABLE actor\G
*************************** 1. row ***************************
Table: actor
Create Table: CREATE TABLE `actor` (
`actor_id` smallint unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
film_actorテーブル
film_actorテーブルは元のテーブル定義から、説明のために主キー(actor_id, film_id)を削除しています(それに伴う外部キー制約も)。理由については記事の後半で説明します。
mysql> SHOW CREATE TABLE film_actor\G
*************************** 1. row ***************************
Table: film_actor
Create Table: CREATE TABLE `film_actor` (
`actor_id` smallint unsigned NOT NULL,
`film_id` smallint unsigned NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
filmテーブル
mysql> SHOW CREATE TABLE film\G
*************************** 1. row ***************************
Table: film
Create Table: CREATE TABLE `film` (
`film_id` smallint unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(128) NOT NULL,
`description` text,
`release_year` year DEFAULT NULL,
`language_id` tinyint unsigned NOT NULL,
`original_language_id` tinyint unsigned DEFAULT NULL,
`rental_duration` tinyint unsigned NOT NULL DEFAULT '3',
`rental_rate` decimal(4,2) NOT NULL DEFAULT '4.99',
`length` smallint unsigned DEFAULT NULL,
`replacement_cost` decimal(5,2) NOT NULL DEFAULT '19.99',
`rating` enum('G','PG','PG-13','R','NC-17') DEFAULT 'G',
`special_features` set('Trailers','Commentaries','Deleted Scenes','Behind the Scenes') DEFAULT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`film_id`),
KEY `idx_title` (`title`),
KEY `idx_fk_language_id` (`language_id`),
KEY `idx_fk_original_language_id` (`original_language_id`),
CONSTRAINT `fk_film_language` FOREIGN KEY (`language_id`) REFERENCES `language` (`language_id`) ON DELETE RESTRICT ON UPDATE CASCADE,
CONSTRAINT `fk_film_language_original` FOREIGN KEY (`original_language_id`) REFERENCES `language` (`language_id`) ON DELETE RESTRICT ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
サンプルのクエリ
今回実行計画をチェックするクエリは下記のとおりです。
SELECT
actor.first_name,
actor.last_name,
film.title,
film.release_year
FROM
actor
INNER JOIN
film_actor ON film_actor.actor_id=actor.actor_id
INNER JOIN
film ON film_actor.film_id=film.film_id
WHERE
actor.last_name LIKE 'a%'
AND film_actor.last_update=’2006-02-15 05:05:03’
AND film.title LIKE 'c%'
取得するカラム
-
actorテーブルから性名を取得 -
filmテーブルからタイトルと公開日を取得
フィルタ条件
-
actorのlast_nameはaから始まるもの -
film_actorは中間テーブルでactorテーブルとfilmテーブルの関連が最後に更新された日付(last_update)が2006-02-15 05:04:03もの -
filmのtitleはcから始まるもの
サンプルクエリの実行計画がこちら。3行表示されています。
mysql> EXPLAIN SELECT * FROM actor INNER JOIN film_actor ON film_actor.actor_id=actor.actor_id INNER JOIN film ON film_actor.film_id=film.film_id WHERE actor.last_name LIKE 'a%' AND film_actor.last_update='2006-02-15 05:05:03' AND film.title LIKE 'c%';
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
| 1 | SIMPLE | film_actor | NULL | ALL | NULL | NULL | NULL | NULL | 5462 | 10.00 | Using where |
| 1 | SIMPLE | actor | NULL | eq_ref | PRIMARY,idx_actor_last_name | PRIMARY | 2 | sakila.film_actor.actor_id | 1 | 5.00 | Using where |
| 1 | SIMPLE | film | NULL | eq_ref | PRIMARY,idx_title | PRIMARY | 2 | sakila.film_actor.film_id | 1 | 9.20 | Using where |
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
ちなみにクエリ結果はこんな感じになります。
+------------+-----------+----------------------+--------------+
| first_name | last_name | title | release_year |
+------------+-----------+----------------------+--------------+
| CHRISTIAN | AKROYD | CAPER MOTIONS | 2006 |
| CHRISTIAN | AKROYD | CATCH AMISTAD | 2006 |
| CHRISTIAN | AKROYD | CHANCE RESURRECTION | 2006 |
| CHRISTIAN | AKROYD | CONFUSED CANDLES | 2006 |
| CHRISTIAN | AKROYD | CUPBOARD SINNERS | 2006 |
| ANGELINA | ASTAIRE | CARRIE BUNCH | 2006 |
| ANGELINA | ASTAIRE | CRANES RESERVOIR | 2006 |
| KIRSTEN | AKROYD | CASABLANCA SUPER | 2006 |
| KIRSTEN | AKROYD | CHARADE DUFFEL | 2006 |
| CUBA | ALLEN | CHAPLIN LICENSE | 2006 |
| CUBA | ALLEN | CHICAGO NORTH | 2006 |
| CUBA | ALLEN | CINCINATTI WHISPERER | 2006 |
| KIM | ALLEN | CARIBBEAN LIBERTY | 2006 |
| KIM | ALLEN | CLASH FREDDY | 2006 |
| KIM | ALLEN | CLEOPATRA DEVIL | 2006 |
| DEBBIE | AKROYD | CLUB GRAFFITI | 2006 |
| MERYL | ALLEN | CHANCE RESURRECTION | 2006 |
| MERYL | ALLEN | CLUE GRAIL | 2006 |
| MERYL | ALLEN | CLYDE THEORY | 2006 |
+------------+-----------+----------------------+--------------+
19 rows in set (0.01 sec)
まずクエリ内の各テーブルの構成要素を分ける
このクエリではactor, film_actor, filmという3つのテーブルが結合されています。
取得するカラムやWHEREでのフィルタ条件についても、それぞれ2つ、または3つのテーブルの要素が指定されています。
これらが1つのクエリにまとめられていることが解り難さの元になっているので、それぞれの要素に色を付けて区別してみます。
Zennでは文字に色をつけることができないので、画像にしたものを貼り付けます。

actorテーブルは赤
film_actorテーブルは緑
filmテーブルは青色にしました。
これでこのクエリを構成する3つのテーブルの要素がひと目で分かるようになりました。
クエリを分解する
見通しが多少良くなったところで、一旦EXPLAINの結果に戻ります。
全てのidカラムが同じ場合、一番上に表示されているテーブルが駆動表になりますので、この場合はfilm_actorテーブルが最初に取得対象になります。
| 1 | SIMPLE | film_actor | NULL | ALL | NULL | NULL | NULL | NULL | 5462 | 10.00 | Using where |
ということで、先程のクエリからfilm_actorテーブル、つまり緑色に関連するところだけを見てみます。
ここで、いくら色分けをしたとは言ってもやはりいくつものテーブルが出現しているクエリでは見づらいので、いっそのことfilm_actorテーブルに関するところだけを別のクエリとして抜き出してしまいます。

抜き出した結果が上記のクエリになります。
ポイントとしては、元のクエリではSELECT句ではfilm_actorテーブルのカラムは取得していませんでしたが、INNER JOIN ONで結合のために使用していましたので、暗黙的に取得対象となります。
取得したカラムは一時的なデータ置き場(オレンジ色)に保存されるものと考えてください。
さて、ここでようやく勉強したEXPLAINの結果、実行計画の見方が出てきます。
film_actorという単一のテーブルに対してのクエリとして考えているため、他のテーブルとの関連に惑わされることはありません。
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
| 1 | SIMPLE | film_actor | NULL | ALL | NULL | NULL | NULL | NULL | 5462 | 10.00 | Using where |
<2行目以降の結果はsnip>
これを見ると、type=ALLとなっておりテーブルスキャンになっています。これはよろしくないですね。
改めてテーブル定義を確認してみましょう。
mysql> SHOW CREATE TABLE film_actor\G
*************************** 1. row ***************************
Table: film_actor
Create Table: CREATE TABLE `film_actor` (
`actor_id` smallint unsigned NOT NULL,
`film_id` smallint unsigned NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
なんとインデックスが存在しません。
これだとどのような条件であっても常にテーブルスキャンになってしまいます。早急な改善が必要です。
が、これは想定通りです。
本記事ではクエリチューニングまでワンセットで行いたいので、元々あった主キー(actor_id, film_id)を削除し、意図して効率が悪いクエリとしています。
チューニングは後ほど行うこととして、一旦よろしくない実行計画であることは無視します。
JOINで結合されたテーブルの実行計画をどのように読み解いていくかを見ていきましょう。
2つ目のテーブルとの結合
前段で駆動表であるfilm_actorテーブルのデータが取得されて、一時的なデータ置き場(オレンジ色)に置かれました。
先にリンクを張ったNested Loop Joinの擬似コードを見ると、for each row in t2 matching reference keyとのことで、次はその取得されたfilm_actorテーブルの行データを使用して2つ目のテーブルにクエリを実行するようです。
2つ目のテーブルは実行計画を見るとactorテーブル、つまり赤色で記載した要素になります。
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
| 1 | SIMPLE | film_actor | NULL | ALL | NULL | NULL | NULL | NULL | 5462 | 10.00 | Using where |
| 1 | SIMPLE | actor | NULL | eq_ref | PRIMARY,idx_actor_last_name | PRIMARY | 2 | sakila.film_actor.actor_id | 1 | 5.00 | Using where |
<snip>
これも同じように元のクエリから赤色の要素だけを抽出してみます。

ここでのポイントはWHERE句の最後にactor.actor_id = film_actor.actor_idという条件が追加されていることです。
左辺のactor.actor_idはactorテーブルのカラムなのでわかります。
右辺のfilm_actor.actor_idはどこから来たのでしょうか? このクエリはactorテーブル、つまり赤文字の要素だけを抽出したのですが…?
実はここがクエリのINNER JOINのON句で指定した結合条件を表したものとなります。
元のクエリでいうとこの箇所になります。

ONからWHEREに条件が移ったことがイマイチ腹落ちしない場合は、INNER JOINによる結合はこのように書き換えられることを思い出すと理解が進むかもしれません。
SELECT
actor.first_name,
actor.last_name,
film.title,
film.release_year
FROM
actor,
film_actor,
film
WHERE
actor.last_name LIKE 'a%'
AND film_actor.last_update='2006-02-15 05:05:03'
AND film.title LIKE 'c%'
AND film_actor.actor_id=actor.actor_id
AND film_actor.film_id=film.film_id
さて、この追加された条件でやっていることを書くと(逆にややこしく感じるかもしれませんが)
「film_actorテーブルで取得したactor_idカラムの値」が「actorテーブルのactor_idの値」と合致する行を取得している。
になります。
合致すると判断された行は、残りのWHERE句での条件last_name LIKE 'a%'が判定されて最終的に取得対象とするか否かが判断されます。
取得されたデータは、同じようにオレンジ色で書かれている一時的なデータ置き場に保存されます。
これでfilm_actorとactorテーブルのデータが結合された途中結果のデータが作成されました。
さて、ここでactorテーブルに対しての実行計画を見てみましょう。
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
<film_actorの実行計画はsnip>
| 1 | SIMPLE | actor | NULL | eq_ref | PRIMARY,idx_actor_last_name | PRIMARY | 2 | sakila.film_actor.actor_id | 1 | 5.00 | Using where |
<filmの実行計画はsnip>
ここではkey=PRIMARYが選択されておりtype=eq_refなっています。
この情報を改めて奥野さんの記事で確認すると
const・・・PRIMARY KEYまたはUNIQUEインデックスのルックアップによるアクセス。最速。
eq_ref・・・JOINにおいてPRIARY KEYまたはUNIQUE KEYが利用される時のアクセスタイプ。constと似ているがJOINで用いられるところが違う。
https://nippondanji.blogspot.com/2009/03/mysqlexplain.html より引用
なるほどなるほど。
単一テーブルで主キーによる一意なルックアップではtype=constと表示されるけど、JOINで主キーによる一意な結合キーの特定ではtype=eq_refということですね。
実際にactorテーブルの定義を確認してみると
mysql> SHOW CREATE TABLE actor\G
*************************** 1. row ***************************
Table: actor
Create Table: CREATE TABLE `actor` (
`actor_id` smallint unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
確かに主キーがactor_idなので、主キーによる一意なルックアップが実行されるはずです。
実行計画を見てもrows=1となっています。
ということはactorテーブルに対するWHERE句は最良のものとなり、改善の余地がないことがわかります。
同じように3つ目のfilmテーブルも結合する
ここまででfilm_actorとactorを結合したデータが得られました。
あとは3つ目のテーブルfilmに対してのクエリも同様に抽出してみます。

これも基本的にはfilmテーブルに対してのみのクエリとなりますが、先のactorの時同様に,
WHERE句の最後に既に一時的なデータ置き場に置かれているfilm_actor.film_idとの比較条件が追加されます。
こちらも実行計画とテーブル定義を確認します。
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
<film_actorとactorテーブルの実行計画はsnip>
| 1 | SIMPLE | film | NULL | eq_ref | PRIMARY,idx_title | PRIMARY | 2 | sakila.film_actor.film_id | 1 | 9.20 | Using where |
+----+-------------+------------+------------+--------+-----------------------------+---------+---------+----------------------------+------+----------+-------------+
mysql> SHOW CREATE TABLE film\G
*************************** 1. row ***************************
Table: film
Create Table: CREATE TABLE `film` (
`film_id` smallint unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(128) NOT NULL,
`description` text,
`release_year` year DEFAULT NULL,
`language_id` tinyint unsigned NOT NULL,
`original_language_id` tinyint unsigned DEFAULT NULL,
`rental_duration` tinyint unsigned NOT NULL DEFAULT '3',
`rental_rate` decimal(4,2) NOT NULL DEFAULT '4.99',
`length` smallint unsigned DEFAULT NULL,
`replacement_cost` decimal(5,2) NOT NULL DEFAULT '19.99',
`rating` enum('G','PG','PG-13','R','NC-17') DEFAULT 'G',
`special_features` set('Trailers','Commentaries','Deleted Scenes','Behind the Scenes') DEFAULT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`film_id`),
KEY `idx_title` (`title`),
KEY `idx_fk_language_id` (`language_id`),
KEY `idx_fk_original_language_id` (`original_language_id`),
CONSTRAINT `fk_film_language` FOREIGN KEY (`language_id`) REFERENCES `language` (`language_id`) ON DELETE RESTRICT ON UPDATE CASCADE,
CONSTRAINT `fk_film_language_original` FOREIGN KEY (`original_language_id`) REFERENCES `language` (`language_id`) ON DELETE RESTRICT ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
先のactorテーブルと同様に、主キーであるfilm_idが選択されているため(key=film_id)、type=eq_ref, rows=1となっており最適化の余地がないことがわかります。
結果となるデータ
さて、3つのテーブルデータの結合が無事終わったので、一時的なデータ置き場には次のデータが格納されています。

このうち、結合のために使用した(INNER JOIN ON句の中で使用した)***_idについては、元のSELECT句で取得対象カラムとして指定されていないため、結果のデータからは取り除かれます。
これで取得対象となるデータがすべて揃ったため結果がクライアントに返されます。
注意:1行ずつの実行であることを忘れずに
ここで改めてNested Loop Joinの解説を見てみると一番外側のforの条件のところにこのように書かれています。
for each row in t1 matching range {
https://dev.mysql.com/doc/refman/8.0/ja/nested-loop-joins.html より引用
ここまで、わかりやすさのために1つのクエリを3つに分解して解説してきました。
そのため、それぞれのフェーズで対象となるテーブルに対して実際にクエリを実行されるようなイメージを抱かれたしれません。
が、実際には各テーブルで1行取得される毎に次のテーブルの1行を取得されて処理が進むようになっています。
つまり、駆動表であるfilm_actorに対してのクエリ

が実際に我々がmysqlコマンドでクエリを実行するのと同じように実行され、その結果を全て取得してから次のテーブルの処理に入るのではなく、クエリで取得される1行が読み取られる毎に次のテーブルの処理に入っています(以降のテーブルも同様)。
この事は更に進んだチューニング、例えばyoku0825さんのWhere狙いのキー、order by狙いのキーで書かれている内容を読み解いていく際には大きな意味を持ちますのでご留意ください。
アクセスされる行数を計算する
さて、このクエリは結局テーブルスペース(ディスク、あるいはバッファプール)から何行のデータを読み込むのでしょうか?
駆動表として選択されたfilm_actorテーブルについてはtype=ALLとなっていたため、全ての行が読み込まれます。行数をチェックしてみましょう。
mysql> SELECT COUNT(*) FROM film_actor WHERE last_update='2006-02-15 05:05:03';
+----------+
| COUNT(*) |
+----------+
| 5462 |
+----------+
1 row in set (0.00 sec)
5,462行でした。
(これは実行計画にあるrowsの値と同じでしたが、この値はあくまでも統計情報から取得された見込みの数なので常に正確であるとは限りません)
WHERE句でlast_updateの値を条件として渡していますが、実はこれ全ての行に同じ値が設定されています。なので元のクエリにも入れる必要がなかったのですが、クエリを分割することを強調するために入れました。
mysql> SELECT last_update, COUNT(*) FROM film_actor GROUP BY last_update;
+---------------------+----------+
| last_update | COUNT(*) |
+---------------------+----------+
| 2006-02-15 05:05:03 | 5462 |
+---------------------+----------+
1 row in set (0.00 sec)
次にfilm_actorの各行に対してactorテーブルへのクエリが実行されますが、これはactorテーブルの実行計画がtype=eq_refだったのでfilm_actorテーブルの1行に対してactorテーブル1行のみが取得される、つまり1行の取得クエリが5,462回発行されるため5462 * 1 = 5,462行がアクセスされます。
ここまででテーブルスペースには5,462 + 5,462 = 10,924行がアクセスされています。
ここで、actorテーブルへのクエリにはlast_name LIKE 'a%'という条件が設定されています。
ということは、ここで先に取得した5,462行がある程度刈り込みされるということです、何行になるでしょうか。
mysql> SELECT COUNT(*) FROM film_actor INNER JOIN actor ON film_actor.actor_id=actor.actor_id WHERE film_actor.last_update='2006-02-15 05:05:03' AND actor.last_name LIKE 'a%';
+----------+
| COUNT(*) |
+----------+
| 196 |
+----------+
1 row in set (0.00 sec)
196行となります。
この196行がfilmテーブルに対して1行ずつアクセスすることになりますが、actorテーブルと同様にfilmテーブルもtype=eq_refだったので取得される行は1行に対して1行となるため、196 * 1 = 196行となります。
ということで、このクエリでアクセスされる行数は5,462 + 5,462 + 196 = 11,120行であることがわかります。(繰り返しになりますが、ここでは理解のしやすさのために196行を取得してからfilmテーブルへの処理に入るように書いていますが、実際には1行ずつ次のテーブルに処理が進んでいます)
実際にこの値が正しいか、long_query_time=0を設定してslowlogで確認してみます。
# Time: 2024-05-06T13:42:20.487475Z
# User@Host: root[root] @ [172.17.0.1] Id: 16
# Query_time: 0.003874 Lock_time: 0.000003 Rows_sent: 19 Rows_examined: 11120
SET timestamp=1715002940;
SELECT actor.first_name, actor.last_name, film.title, film.release_year FROM actor, film_actor, film WHERE actor.last_name LIKE 'a%' AND film_actor.last_update='2006-02-15 05:05:03' AND film.title LIKE 'c%' AND film_actor.actor_id=actor.actor_id AND film_actor.film_id=film.film_id;
どうやら正しそうです。
最終的にfilm.title='c%'のフィルタが適用されてクライアントに返された行数は19行となっています。
最適化の余地を探る
ざっくりではありますが、JOINでテーブルを結合するクエリの実行計画の見方がわかったところで、いよいよ本題です。このクエリを最適化するにはどうしたら良いでしょうか。
actorとfilmについてはtype=eq_refとなっているので最適化の余地はなさそうです。
逆にfilm_actorこいつはtype=ALLなので何らかの改善ができそう、ではなく必要そうです。
もう一度元のクエリと分離されたfilm_actorへのクエリを見てみましょう。
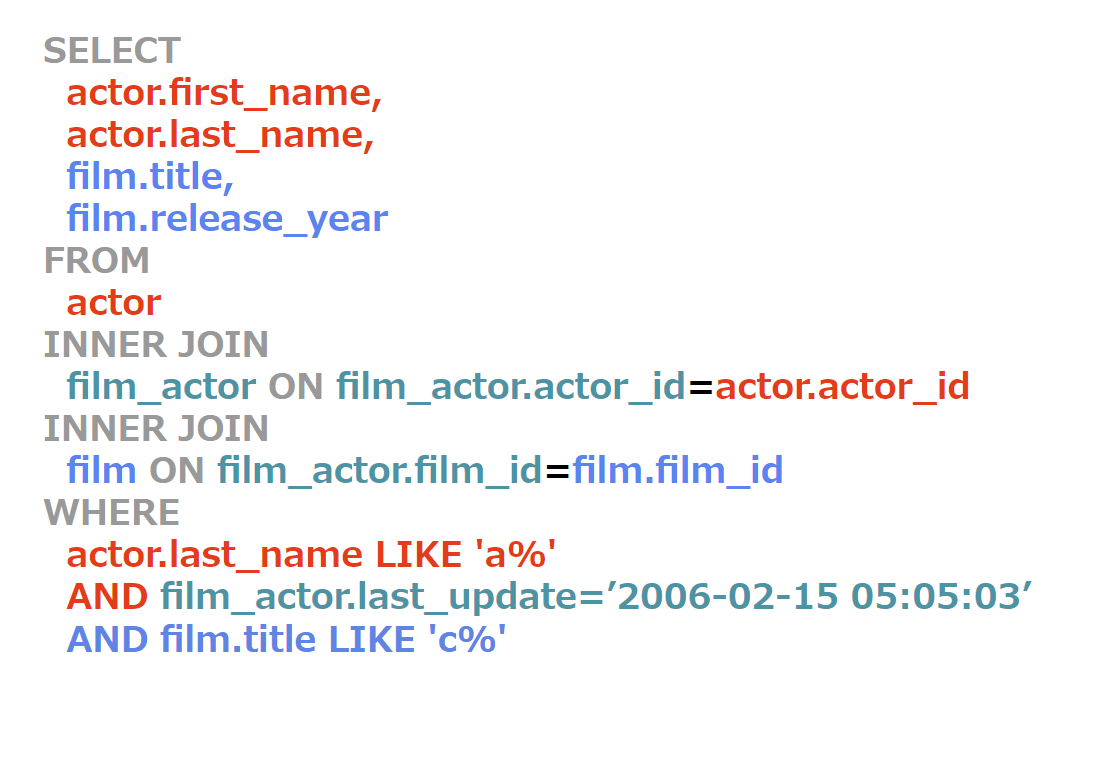
分離したクエリ

film_actorのテーブル定義も再掲します。
mysql> SHOW CREATE TABLE film_actor\G
*************************** 1. row ***************************
Table: film_actor
Create Table: CREATE TABLE `film_actor` (
`actor_id` smallint unsigned NOT NULL,
`film_id` smallint unsigned NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
そもそもインデックスが作成されていないので、何らかのインデックスを作成してやると良さそうです。
では、WHERE句で指定されているlast_updateでしょうか?
これは先に述べた通り、全ての行で値が同じなので意味がなさそうです。
でも、actor_idやfilm_idはWHERE句で指定されていないから意味がない…?
と、わざとらしく書いてみましたがもちろん意味があります。
(わざわざ非効率な実行計画になるように事前にALTER TABLE film_actor DROP INDEX 'PRIMARY'しましたので)
最適化してみる
ということで、削除した主キーを復活させてどうなるか見てみましょう。
mysql> ALTER TABLE film_actor ADD PRIMARY KEY(`actor_id`, `film_id`);
Query OK, 0 rows affected (0.10 sec)
Records: 0 Duplicates: 0 Warnings: 0
この状態で取得したサンプルクエリの実行計画がこちら。
mysql> EXPLAIN SELECT * FROM actor INNER JOIN film_actor ON film_actor.actor_id=actor.actor_id INNER JOIN film ON film_actor.film_id=film.film_id WHERE actor.last_name LIKE 'a%' AND film_actor.last_update='2006-02-15 05:05:03' AND film.title LIKE 'c%';
+----+-------------+------------+------------+--------+-----------------------------+---------------------+---------+---------------------------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+-----------------------------+---------------------+---------+---------------------------+------+----------+-----------------------+
| 1 | SIMPLE | actor | NULL | range | PRIMARY,idx_actor_last_name | idx_actor_last_name | 182 | NULL | 7 | 100.00 | Using index condition |
| 1 | SIMPLE | film_actor | NULL | ref | PRIMARY | PRIMARY | 2 | sakila.actor.actor_id | 27 | 10.00 | Using where |
| 1 | SIMPLE | film | NULL | eq_ref | PRIMARY,idx_title | PRIMARY | 2 | sakila.film_actor.film_id | 1 | 9.20 | Using where |
+----+-------------+------------+------------+--------+-----------------------------+---------------------+---------+---------------------------+------+----------+-----------------------+
3 rows in set, 1 warning (0.00 sec)
ポイントをまとめると
-
actorが駆動表になった -
actorの実行計画がtype=range, key=idx_actor_last_name, rows=182になった -
film_actorが内部表になった -
film_actorテーブルの実行計画がtype=ref, key=PRIMARY, rows=27になった -
filmテーブルの実行計画は変わらず
これを先程と同じようにクエリを分解して考えていきます。
まずは駆動表となったactorテーブルへのクエリを抽出。

先ほどは結合のためにWHERE句の最後にactor.actor_id = film_actor.actor_idがありましたがそれが無くなりました。
主キーであるactor_idが使えなくなったため、代わりにidx_actor_last_name(中身はlast_name)がインデックスとして選択されています。
次に内部表になったfilm_actorテーブル、これはどうでしょうか。

内部表となったため、結合のための条件film_actor.actor_id = actor.actor_idがWHERE句の最後に追加されています。
先ほどはインデックスが存在しなかったためtype=ALLとなっていましたが、今回は主キーとして(actor_id, film_id)が追加されたためtype=ref, key=PRIMARYとなっています。
key=PRIMARYなのにtype=eq_refではなくrefなのは、主キーが複合インデックスでその前半部分であるactor_idしか指定していないため一意に行を選択できず複数行の取得となっているためです。
filmテーブルについては特に実行計画は変わっていないので省略します。
行数を計算する
さて、この実行計画は本当にアクセスする行数が減っているのでしょうか?
rowsの総和は減っていますが、actorテーブルへのアクセスがtype=eq_refからrefに変わってrowsの値が増えていますが…?
先ほど同じように計算していきます。
まずactorテーブル。
mysql> SELECT COUNT(*) FROM actor WHERE last_name LIKE 'a%';
+----------+
| COUNT(*) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)
取得されるのは7行。実際のデータ(last_nameがaから始まるactor_id)がこちら。
mysql> SELECT actor_id FROM actor WHERE last_name LIKE 'a%';
+----------+
| actor_id |
+----------+
| 58 |
| 92 |
| 182 |
| 118 |
| 145 |
| 194 |
| 76 |
+----------+
7 rows in set (0.00 sec)
このそれぞれが
SELECT
film_actor.film_id
FROM
film_actor
WHERE
film_actor.last_update=’2006-02-15 05:05:03’
AND
film_actor.actor_id = <<ここに上のactor_idが入る>>
のクエリを実行します。
この時、last_updateのフィルタ条件は常に真なので取得された行に対して刈り込みは発生しません。
mysql> SELECT COUNT(*) FROM film_actor WHERE film_actor.actor_id IN (58,92,182,118,145,194,76);
+----------+
| COUNT(*) |
+----------+
| 196 |
+----------+
1 row in set (0.00 sec)
ということで、ここまでで7 + 196 = 203行へのアクセスが発生しています。
最後はfilmテーブルですが、こいつはtype=eq_refなので先程の196行分、それぞれ1行ずつの取得となるので196行のアクセスが発生します。
最終的なアクセス行数は7 + 196 + 196 = 399となるはず。slowlogで確認してみます。
# Time: 2024-05-06T14:47:22.090701Z
# User@Host: root[root] @ [172.17.0.1] Id: 16
# Query_time: 0.000739 Lock_time: 0.000003 Rows_sent: 19 Rows_examined: 399
SET timestamp=1715006842;
SELECT actor.first_name, actor.last_name, film.title, film.release_year FROM actor, film_actor, film WHERE actor.last_name LIKE 'a%' AND film_actor.last_update='2006-02-15 05:05:03' AND film.title LIKE 'c%' AND film_actor.actor_id=actor.actor_id AND film_actor.film_id=film.film_id;
大丈夫そうですね。
改善前の11,120と比較して3.5%程度まで削減することができました。
ということで
軽く書くつもりが何故か妙に長くなってしまいましたが、これが私が実行計画を見ていくときの頭の中の流れになります。
最初のうちは実際に分解したクエリを手元に書いていましたが、ある程度慣れてくると簡単なものであれば実行結果の出力を見て「あー、このテーブルに問題があるな」ということがわかるようになりました。(まあ単純にrowsが多かったらそれがダメなやつではあるのですが)
ここまで読んで「でもこれって普通に外部キーとかきちんと設定されていればあんまり問題になることなくない?」と思われた方、正しいです。
正しいのですが、きちんと設定されていないケースも、やはり普通に存在するのでそういったときにこの記事が役立てば何よりです。
最後に
読みやすさのために断定口調で書いてありますが、まだまだ勉強中なので間違っている箇所があるかもしれません。その際はコメントで指摘いただけると嬉しいです。
無理やり非効率なクエリにするためにfilm_actorテーブルの主キーを削除したけど、そのせいで中間テーブルが駆動表になるという、直感的に理解が難しい実行計画になってしまいました。
過去に会社で改善した例を参考にすればもっと良いサンプルが作れそうでしたが、GW中ということもあり諦めてそのまま突き進みました。
これも機会があれば別の記事で。
Discussion