kubernetess・ネットワーク・AWS・GithubActions
目次
- kubernetess
- ネットワーク
- ipアドレスとdns
- SRE
- terraform + githubactionsのフロー
要点
-
kubernetessとEKS(AWS)は別
-
ネットワーク構築
- ローカル
- serviceがロードバランシングをしてくれる感じ
- 外部
- Ingress を挟むことで接続可能
- サブネット
- 外部の接続のIngressとか
- 内部クラスターはプライベートサブネット
- 内部はルーティングやSG groupはそんなにきししないで良い
- ローカル
-
EKS
- ポイント
- ALB は AWS Ingress Controllerで簡単に作成できる
- kubernetessのサービスアカウントにIAMを不要して、AWSリソースにアクセス
- ポイント
-
AWS・ECSの理解
- EKSを使うにおいても、AWSの理解が必須
-
notion
https://www.notion.so/kubernetes-kindle-udemy-23c031b7ac3d80138dfef9f01908e2fb
kubernetess 作って学ぶ
todo
- [] chapter7
- [] chapter8で理解の深掘り
メモ
- chapter5がpodの扱いのメイン
コンテナの必要性
- 仮想環境より高速
- マイクロサービス化が進んだ
コンテナ基本
kubernetess アーキテクチャー
- コントローラーパネル
- ワーカーノード
この本の読み方
- 壊してみるは逆に少しわかりずらい
- 大体、get describe して、editでマニュフェストファイルを変更なのでスキップして良い
共通のデバック考え方
- インフラかアプリケーションか切り分けて
- インフラ
- k get リソース
- k get describe
- k logs リソース
- k edit xxx => マニュフェストを変更する
- アプリケーション
- k logsで内部のエラーが出る感じや
- インフラ
ツール
- kubectl
- kind
クラスター作成
➜ kubernetes kind create cluster --image=kindest/node:v1.29.8
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.29.8) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community 🙂
➜ kubernetes kubectl cluster-info --context kind-kind
Kubernetes control plane is running at https://127.0.0.1:62290
CoreDNS is running at https://127.0.0.1:62290/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
➜ kubernetes
➜ kubernetes kind delete cluster
Deleting cluster "kind" ...
Deleted nodes: ["kind-control-plane"]
➜ kubernetes
chapter 3全体像
- server コード
chapter4 クラスタ上にアプリケーションを立てる
- nginx.yaml
apiVersion: v1
kind: Pod // kimd はpod
metadata:
name: nginx // podの名前をnginx
spec: // コンテナの仕様 dockerfileなくても作成できるみたい
containers:
- name: nginx
image: nginx:1.25.3
ports:
- containerPort: 80
- myapp.yaml: サーバーのコード
apiVersion: v1
kind: Pod
metadata:
name: myapp
labels:
app: myapp
spec:
containers:
- name: hello-server
image: blux2/hello-server:1.0
ports:
- containerPort: 8080
pod を動かす
// クラスターがないとだめ
kind create cluster --image=kindest/node:v1.29.8
➜ kubernetes kubectl get nodes
NAME STATUS ROLES AGE VERSION
kind-control-plane NotReady control-plane 10s v1.29.8
➜ kubernetes kind get clusters
kind
// podがあるか
➜ kubernetes kubectl get pod --namespace default
No resources found in default namespace.
➜ kubernetes kubectl apply --filename myapp.yaml --namespace default
pod/myapp created
// 2つ目のpodを作成してる
➜ kubernetes kubectl run myapp2 --image=blux2/hello-server:1.0 --namespace default
pod/myapp created
// 作成された
➜ kubernetes kubectl get pod --namespace default
NAME READY STATUS RESTARTS AGE
myapp 1/1 Running 0 11s
// output
kubectl get pod --output yaml --namespace default
kubectl get pod --output wide --namespace default
// wideつけるとnodeの情報まで
➜ kubernetes kubectl get pod --output wide --namespace default
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp 1/1 Running 0 14m 10.244.0.5 kind-control-plane <none> <none>
➜ kubernetes kubectl get pod --namespace default
NAME READY STATUS RESTARTS AGE
myapp 1/1 Running 0 14m
➜ kubernetes
chapter 5 トラブルシューティング
- podの状態確認
- ステータスがrunningか?
- pending だったりする場合
- ログで原因を探る
- pending だったりする場合
- ステータスがrunningか?
状態確認
// podのステータスを確認できる
➜ kubernetes kubectl get pod --namespace default
NAME READY STATUS RESTARTS AGE
myapp 1/1 Running 0 3m55s
// これでdiffをとったりするみたい
kubectl get pod --output yaml --namespace default > pod.yaml
// json はjqみたいなことができる
kubectl get pod --output jsonpath='{.spec.containers[].image}' --namespace default
## describe
➜ kubernetes kubectl describe pod myapp
Name: myapp
Namespace: default
Priority: 0
Service Account: default
Node: kind-control-plane/172.18.0.2
Start Time: Sat, 26 Jul 2025 12:19:08 +0900
Labels: app=myapp
Annotations: <none>
Status: Running
IP: 10.244.0.5
IPs:
IP: 10.244.0.5
Containers:
hello-server:
Container ID: containerd://6fd23a5ecff1a94706fa5df03862d0295b57089e557281e7f5ee40ecde23297e
Image: blux2/hello-server:1.0
Image ID: docker.io/blux2/hello-server@sha256:35ab584cbe96a15ad1fb6212824b3220935d6ac9d25b3703ba259973fac5697d
Port: 8080/TCP
Host Port: 0/TCP
State: Running
Started: Sat, 26 Jul 2025 12:19:13 +0900
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-n44ml (ro)
## logs
// podのログが見れる
➜ kubernetes kubectl logs myapp
2025/07/26 03:19:13 Starting server on port 8080
- デバック
apiVersion: v1
kind: Pod
metadata:
name: myapp
labels:
app: myapp
spec:
containers:
- name: hello-server
image: blux2/hello-server:1.0
ports:
- containerPort: 8080
## デバック用のコンテナを立てて、curlする
// --targetはcurl先のコンテナを明示してる
kubectl debug --stdin --tty myapp --image=curlimages/curl:8.4.0 --target=hello-server --namespace default -- sh
podの作成方法は2
- kubectl apply + マニュフェストファイル.yml
- kubectl run --image でimage指定
k --namespace default run curlpod --image=curlimages/curl:8.4.0 --command -- /bin/sh -c "while true; do sleep infinity; done;"
// curl のpodもできた
➜ kubernetes k get pod --output wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
curlpod 1/1 Running 0 5m9s 10.244.0.6 kind-control-plane <none> <none>
myapp 1/1 Running 0 118m 10.244.0.5 kind-control-plane <none> <none>
// ログイン
➜ kubernetes k exec --stdin --tty curlpod -- /bin/sh
~ $ curl 10.244.0.5:8080
Hello, world!~ $
port-foward でアプリにアクセス
k port-forward <pod名> <転送先port>:<転送元port>
➜ kubernetes k port-forward myapp 5555:8080
Forwarding from 127.0.0.1:5555 -> 8080
Forwarding from [::1]:5555 -> 8080
Handling connection for 5555
// リクエストを投げる
➜ ~ curl localhost:5555
Hello, world!%
➜ ~
障害を直す
- kubectl edit <リソース>
- マニュフェストファイルの変更
- 履歴が残りずらいのでバットプラクティス
- マニュフェストファイルの変更
// pod ここ、deploy serviceなどでもできそう
kubectl edit pod myapp
デバックフロー
- getでステータス
- describeで詳細
- editでリソース修正
chapter 6リソースを作って壊そう
- podのライフサイクル
- scheduled => pending => running => failed or succeeded
- podの冗長化
- ReplicaSet
- pod を1対多で持つ
- Deployment
- ReplicaSetを1対多で持つ
- ReplicaSet
replicaset
- nginx を複数台立てる
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: httpserver
labels:
app: httpserver
spec:
replicas: 3
selector:
matchLabels:
app: httpserver
template:
metadata:
labels:
app: httpserver
spec:
containers:
- name: nginx
image: nginx:1.25.3
k apply --filename replocaset.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.24.0
ports:
- containerPort: 80
k apply --filename deployment.yaml
ReplicaSetとDeploymentの違い
- 役割の違い
- Replicaset
- 同じ仕様の Pod を指定した数だけ保つ
- Deplyment
- コードやコンテナイメージを更新すると自動で新しい Pod に置き換える(ローリングアップデート)
- Replicaset
- 無停止で更新をする必要がある
- 新しいマニュフェストを適応する必要がある => 複数のreplicasetを紐づけることで更新できる
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx --templeteのlabelsと一致している必要があるらしい
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.24.0
ports:
- containerPort: 80
deployment
-
ポイント
- ReplicasSetとの役割の違い
- Strategt
- StragegyType
- RollingUpdateStarategy
-
podを維持する マニュフェスト
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 10
strategy:
type: Recreate
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.24.0
ports:
- containerPort: 80
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 10"]
podの監視でpodのリカバリ確認
- テスト
// podの監視
k get pod --watch
// podを削除する
➜ kubernetes k delete pod nginx-deployment-58556b4d6b-29pvc
pod "nginx-deployment-58556b4d6b-29pvc" deleted
// Terminatting されていることがわかる。新たに、nginx-deployment-58556b4d6b-65qs2 が作成されてpodの数が保たれる
nginx-deployment-58556b4d6b-g2gl8 1/1 Running 0 1s
nginx-deployment-58556b4d6b-hfm5p 1/1 Running 0 1s
nginx-deployment-58556b4d6b-29pvc 1/1 Terminating 0 21s
nginx-deployment-58556b4d6b-65qs2 0/1 Pending 0 0s
nginx-deployment-58556b4d6b-65qs2 0/1 Pending 0 0s
nginx-deployment-58556b4d6b-65qs2 0/1 ContainerCreating 0 0s
nginx-deployment-58556b4d6b-65qs2 1/1 Running
service
- deploymentはipアドレスを持たないらしい
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-server
labels:
app: hello-server
spec:
replicas: 3
selector:
matchLabels:
app: hello-server
template:
metadata:
labels:
app: hello-server
spec:
containers:
- name: hello-server
image: blux2/hello-server:1.0
ports:
- containerPort: 8080
- service
- selectorでdeploymentを指定して紐づける
apiVersion: v1
kind: Service
metadata:
name: hello-server-service
spec:
selector:
app: hello-server
ports:
- protocol: TCP
port: 8080
targetPort: 8080
- 検証
// deployment 実行
k apply --filename hello-server.yaml
// service
k apply --filename service.yaml
## port-foward => pod か serviceか指定可能でserviceの場合は svc/のプレフィックスが必要
➜ kubernetes k port-forward svc/hello-server-service 8080:8080
Forwarding from 127.0.0.1:8080 -> 8080
Forwarding from [::1]:8080 -> 8080
curl http://localhost:8080/
ServiceType
- 内部
- CluseterIP
- 外部
- node ip
- loadbalancer
DNS
-
<Service名>.<Namespace名>.svc.cluster.localで接続可能
ConfigMap
- configmapありのマニュフェスト
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-server
labels:
app: hello-server
spec:
replicas: 1
selector:
matchLabels:
app: hello-server
template:
metadata:
labels:
app: hello-server
spec:
containers:
- name: hello-server
image: blux2/hello-server:1.4
env:
- name: PORT
valueFrom:
configMapKeyRef:
name: hello-server-configmap
key: PORT
---
apiVersion: v1
kind: ConfigMap // kindはここでConfigMap
metadata:
name: hello-server-configmap
data:
PORT: "8081"
volume
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-server
labels:
app: hello-server
spec:
replicas: 3
selector:
matchLabels:
app: hello-server
template:
metadata:
labels:
app: hello-server
spec:
containers:
- name: hello-server
image: blux2/hello-server:1.5
volumeMounts:
- name: hello-server-config
mountPath: /etc/config
volumes:
- name: hello-server-config
configMap:
name: hello-server-configmap
---
apiVersion: v1
kind: ConfigMap
metadata:
name: hello-server-configmap
data:
myconfig.txt: |-
I am hungry.
volume p177
secret 189
job p193
chapter 7 安全でステートレス
probe
調査するの意味合いらしい
- readnessProbe
- これは一定間隔でhealthチェックして 200~400以外の場合は、serviceの対象から外す
- 一定感覚でチェックされるので、successしたらサービスの対象になる
- これは一定間隔でhealthチェックして 200~400以外の場合は、serviceの対象から外す
- livenessProbe
- 失敗するとpodを再起動する
複数設定が現実的みたい
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 8080
periodSeconds: 5
failureThreshold: 3
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
resource
- リソースの要求をrequestsとするらしい
apiVersion: v1
kind: Pod
metadata:
labels:
app: hello-server
name: hello-server
spec:
containers:
- name: hello-server
image: blux2/hello-server:1.6
resources:
requests:
memory: "64Mi"
cpu: "10m"
limits:
memory: "64Mi"
cpu: "10m"
- ノードにpodが多で紐づく
- pod 毎のリソースの合計がnodeのリソース
affinity ・anti-affinity
- スケジューリング
- 新しいpodをどのノードで動かすかを決める作業
- 考慮する内容
- リソース
- ノードのラベル
- podとの関係 ,podAffinity ・podAntiAffinity
- Taint と Toleration
- Taint: このノードには原則Podを置かないで
- Toleration: 例外としてその taint を無視できるPodの設定
- 優先度とポリシー
- リソースが足りない時に優先度が低いpodを矯正終了して、高いpodが動く
- トポロジー分散
- ゾーンやノード間で分散させる仕組み
- リージョン > ゾーン > クラスター > ノード > Pod
- ゾーンやノード間で分散させる仕組み
- など
- 考慮する内容
- 新しいpodをどのノードで動かすかを決める作業
- affinity
- このpodは特定のpodの近くで動かしたいなど
- webアプリpodとキャッシュpodを同じnodeに起きたい
- このpodは特定のpodの近くで動かしたいなど
- anti-affinity
- 同じnodeに置きたくない
chapter 8復習
最終的なコード
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-server
labels:
app: hello-server
spec:
replicas: 3
selector:
matchLabels:
app: hello-server
template:
metadata:
labels:
app: hello-server
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
values:
- hello-server
operator: In
topologyKey: kubernetes.io/hostname
containers:
- name: hello-server
image: blux2/hello-server:2.0.1
env:
- name: PORT
valueFrom:
configMapKeyRef:
name: hello-server-configmap
key: PORT
resources:
requests:
memory: "256Mi"
cpu: "10m"
limits:
memory: "256Mi"
cpu: "10m"
readinessProbe:
httpGet:
path: /healthz
port: 8082
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8082
initialDelaySeconds: 10
periodSeconds: 5
---
apiVersion: v1
kind: ConfigMap
metadata:
name: hello-server-configmap
data:
PORT: "8082"
HOST: "localhost"
---
apiVersion: v1
kind: Service
metadata:
name: hello-server-external
spec:
type: NodePort
selector:
app: hello-server
ports:
- port: 8082
targetPort: 8082
nodePort: 30599
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: hello-server-pdb
spec:
maxUnavailable: 10%
selector:
matchLabels:
app: hello-server
不足
- ingress l7ルーティング
- Secret パスワードやキー
- オートスケール
- ログ・メトリクス・アラート
構造
- hello-server というアプリケーションを 3つの Pod(複数レプリカ)でデプロイ
- Pod のヘルスチェックを行い、自動的に不健康な Pod を切り離す
- 外部アクセスのための NodePort サービスを提供
- Pod の分散配置 (Anti-Affinity) と PodDisruptionBudget で高可用性を確保
- 設定値を ConfigMap 経由で注入
chapter 9 kubernetessのアーキテクチャ
chapter 10 ワークフロー
chapter 11 オブザーバビリティ
ネットーワーク DNS
ipアドレス・ネットワーク部・ホスト部
- ipアドレス(IPv4)は 32bit
- /24の場合は8bit開ける
- 8bit は 2^8 で 256 なので 0 ~ 255
10.0.0.0/24
10.0.0.[0-255] の範囲が1つのネットワーク
- vpc
- 10.0.0.0/16 => 10.0.x.x
- ネットワーク 10.0
- ホスト部: 残り16ビット: 10.0.0.0〜10.0.255.255
- 10.0.0.0/16 => 10.0.x.x
- サブネット
- 10.0.1.0/24: A
- ネットワーク部 = 10.0.1
- ホスト部 = 0〜255
- 10.0.2.0/24: B
- 10.0.1.0/24: A
ipアドレスの割り当て 例
- 16/ 24で切られることが多いはず
- vpc
- 10.0.0.0/16 => 10.0.x.x
- ネットワーク 10.0
- ホスト部: 残り16ビット: 10.0.0.0〜10.0.255.255
- 10.0.0.0/16 => 10.0.x.x
- サブネット
- 10.0.1.0/24: A
- ネットワーク部 = 10.0.1
- ホスト部 = 0〜255
- 10.0.2.0/24: B
- 10.0.1.0/24: A
- 上記で、vpcとサブネットを切ると下記のような感じで割り当てられる
- ec2をサブネットAに2台おいた時に、「予約IPアドレスを除いた」10.0.1.4〜10.0.1.254の範囲で割り当てられる。
- RDSの場合も所属してるサブネットの中から割り当てられる
10.0.1.1 ← AWSのデフォルトゲートウェイ
10.0.1.4 ← フロント用EC2
10.0.1.5 ← API用EC2
10.0.1.6 ← RDS (自動割当)
オートスケーリングの仕組み
- ALBでターゲットグループでオートスケーリング
- これも自動でサブネットの範囲のipアドレスからターゲットグループに入れて、リクエストを振り分けてくれる
通信の基本
-
通信はリクエストとレスポンスで成り立つ
- レスポンスはアウトバウンドのセッションの一部として戻ってくるだけなので、「インバウンド」と解釈しない
-
アウトバウンドの通信制御
- router && route テーブル
-
インバウンド
- 外部からの通信 で sg groupで制御
router(送信先・アウトバウンド)
- アタッチ先
- サブネット
- routeテーブル考え方
- サブネットの中のリソース(ec2・alb)などがどの宛先に通信を送れるのか?を設定するもの
- 「送信方向」を決めるものなので、アウトバウンドの通信の設定の意識で良い
- 「戻りの通信」は逆向きにたどる
- 役割
- 通信のコントロール
-
10.0.0.0/16 → localで内部通信は、パブリックサブネットからだろうが、プライベートサブネットだろうがipアドレスを知っていればリクエストできる - 外部通信の
-
- 通信のコントロール
security group(インバウンドの制御)
- sg groupで制御
- 許容先を設定
- ipアドレス(0.0.0.0/0)や、sg group
- portの設定
- 許容先を設定
DNS
用語
- レジストリ
- .comのドメインなどの情報を管理
- レジストラ
- ドメインを売買する仲介者で、お名前.comが ,exmapleaki.comのドメインを仲介
- 「誰がネームサーバーであるか?」をレジストリに登録すること
- route53
- ネームサーバー
ドメイン解決の流れ
- macがプロバイダDNSに問い合わせ(ネットなど)
- レジストリに問い合わせ
- .comのネームサーバー => route53のネームサーバーだと
- route53へ問い合わせ
- ns-1276.awsdns-31.org.だよ
- IPアドレスの取得
DNSサーバーは2種類ある
- リゾルバ(キャッシュDNSサーバ): 権威サーバーに問い合わせる仲介役
- ネットのプロバイダー: 俺の場合ソフトバンク
- 権威サーバー(ネームサーバー): ドメインの最終的な答え(Aレコード/CNAMEなど)を持っているサーバ
- お名前.com
- AWS route53など
DNSキャッシュ
1度問い合わせたら、DNSキャッシュされるのでDNSサーバーがリクエスト多すぎて落ちるってことはない
お名前.comとRoute53 とALBの関係
- お名前.comでドメインを取得
- この時点では、権威サーバー(最終的な情報を保持するサーバー)はお名前.com
- お名前.comのネームサーバーにroute53の情報を設定する
- 権威サーバーをRoute53に移動する行為
- Route53のAレコードにドメインの設定しALBに紐付け
- 転送をする感じ
softbankのネットからアクセスする
- softbankのリゾルバ経由でroute53のに問い合わせる
- route53でAレコードで albを紐付けているので、albに通信を送る
ネットワークレイヤー AWS
L3
- vpc・サブネット・RouteTable
L4
- SG (Security Group)
- L3/L4 (ネットワーク層+トランスポート層)
- IPレベルでは L3
- ポートレベル: L4
- L3/L4 (ネットワーク層+トランスポート層)
L7
- ALB・Route53(DNS)
tcp/ipの理解・使い所
あります。AWSなどのクラウド環境でも TCPハンドシェイクが成立しない(3-way handshake が完了しない)ことは普通にあります。
原因はオンプレでもクラウドでもほぼ同じですが、クラウド特有の要因もあります。
1. TCPハンドシェイクができない原因(AWSでよくあるパターン)
(1) セキュリティグループ / NACL がブロック
-
SG(Security Group) がインバウンド/アウトバウンドで許可していない
→ SYNパケットが送信されても RST または無視される -
NACL でDenyしている
→ 片方向のパケットが落ちるのでSYN/ACKが返ってこない
(2) ルートテーブルの設定ミス
- 送信先サブネットへのルートが無い
- NAT Gateway / Internet Gateway の設定不足で外部に出られない
(3) ALB/NLBのリスナーやターゲット登録ミス
- ALBのターゲットグループが正しく登録されていないと、SYNはALBで止まる
- NLBのヘルスチェック未通過で実サーバーに届かない
(4) OS側のFirewall (iptables, ufw)
- EC2内部のファイアウォールでポートが拒否
(5) ミスったAZまたぎ/VPC Peering
- Peering設定でルートを張っていないとパケットが戻らない
- PrivateLinkのDNS解決ミスで意図しない宛先へ行っている
(6) クラウドサービスの制限・閉じた環境
- LambdaやFargateなど直接ポートを開けられないサービスは、そもそもTCPリスニングできない
- VPC Endpoint経由の場合、内部的にTCPが別の経路で中継されるので直接のハンドシェイクが見えないこともある
2. ハンドシェイクできない時の調べ方(AWS)
-
EC2内から
tcpdumpsudo tcpdump -i eth0 tcp port 443SYNが届いているか、SYN-ACKが返せているかを見る
-
VPC Flow Logs
- どのIP/ポートの通信が許可/拒否されているかを確認
-
ACCEPTかREJECTで判断可能(L3/L4レベルまで)
-
ALB/NLBのアクセスログ
- ALBならログに「リクエストすら来ていない」かどうかが分かる
-
Traffic Mirroring
- より詳細にパケットをキャプチャして確認
3. 実例
-
セキュリティグループでポート80を開け忘れていた
→ クライアントから SYN を送信 → 応答なし (SYN/ACKなし) → タイムアウト -
ALBのターゲットがUnhealthy
→ SYNはALBまで届くが、バックエンドに転送されずにクライアントはハング -
NACLのOutbound制限
→ インバウンドSYNを受けたが、アウトバウンドのSYN/ACKがブロックされるので3-way handshakeが成立しない
まとめ
AWSでもTCPハンドシェイクができないことはよくあります。
多くの場合、原因はネットワークACL / セキュリティグループ / ルーティング / LB設定で、
パケットキャプチャ(tcpdump)するとSYNまでは届いてるのにSYN/ACKが返ってこない、という状況で気づきます。
次に知りたいのはどっち?
- 実際にハンドシェイクが失敗している様子(tcpdumpの例)
- ハンドシェイクできないときに最初に確認するチェックリスト(順番つき)
sreってなんぞや?
- インフラ構築・障害対応
- CI・CD
- セキュリティ
- SLA・SLOを満たすための施策提案と実施
っぽいな、なんとなくインフラエンジニアがやってることが理解できて
背景
ほぼその理解で合っています。もう少し背景を分解すると、SRE(Site Reliability Engineering)がポジションとして広まった理由は次のような流れです:
1. 背景:クラウド化とインフラ自動化の進展
-
昔(オンプレ時代)
インフラエンジニアの仕事は、物理サーバのセットアップ・ミドルウェアのインストール・監視設定といった「構築・運用作業」が中心。 -
クラウド・コンテナ時代
AWS/GCPの登場、Infrastructure as Code(IaC)、Kubernetesなどによって、- 環境構築がコード化・自動化される
- サーバ台数増減もAPIで制御できる
→ 人力オペレーションの比重が大幅に減った
これにより「手作業での構築・運用」の価値が相対的に下がり、より上位の課題(可用性、信頼性、改善活動)に時間を割けるようになった。
2. Google発のSRE思想の普及
Googleが2003年頃に提唱した「SRE」は、
“運用をソフトウェアエンジニアリングの問題として扱い、サービスの信頼性を高める”
というアプローチで、
- SLO/SLA/SLI(信頼性指標)を定義
- エラーバジェット(許容できる障害の範囲)を決め、
- 人力作業ではなくコードで運用を最適化することを重視
という思想でした。
3. クラウド化がSREを加速させた理由
クラウドの進化によって:
- サーバ増設・負荷分散・監視がAPIやマネージドサービスで簡単にできる
- ログ・メトリクス収集基盤がサービスとして提供される
- これらを組み合わせて「信頼性を設計・改善」することが主な価値に
結果として、
「運用作業」から「信頼性・パフォーマンスの改善」を主業務とする役割が成立し、SREというポジションが一般企業でも採用されるようになりました。
まとめ
クラウド化と自動化で作業コストが減った →
その分、SLO/SLA・信頼性・運用改善に専念できるようになった
→ それを専門に担うSREというポジションが成立した
まさにご質問の理解は正しく、その背景にGoogleのSRE思想とクラウドの普及が大きく関係しています。
補足として:
- クラウドが無い時代でもGoogle内部ではSREは存在していました(オンプレでも自動化を徹底していた)。
- しかし、クラウドの普及が一般企業でのSRE職普及を加速させたのは間違いありません。
もう少し深く知りたいのは
「SREがSLO改善に注力するようになった経緯」か
「インフラ→SREへの役割のシフト」どっちですか?
=> だから構築やってる人は割とオンプレの人が多いのか?
=> SREって名称じゃないけど、会社のインフラがオンプレからクラウド => IaC => SLO/SLAの監視と運用か
セキュリティ
とても良い視点です。
SREの中でセキュリティは重要な役割の一部です。特にクラウド時代では信頼性とセキュリティは表裏一体なので、SREがセキュリティの観点を持っていることが求められます。
1. SREに求められるセキュリティ範囲
SREが担当するのは、セキュリティ専任エンジニアほど深くはありませんが、次の分野がカバー範囲になります:
-
クラウド基盤のセキュリティ
- IAM(認証・認可)
- セキュリティグループ・ネットワークACL
- シークレット管理(Secret Manager、KMS)
-
運用のセキュリティ
- CI/CDパイプラインでの脆弱性チェック
- ログ監視、検知・アラート
-
インシデント対応
- 攻撃や異常検知の初動
- 再発防止の仕組み化
-
SLO観点のセキュリティ
- セキュリティ障害(鍵漏洩、脆弱性攻撃)がSLOに影響するので
設計・運用段階で考慮
- セキュリティ障害(鍵漏洩、脆弱性攻撃)がSLOに影響するので
2. 勉強のステップ
(1) 基礎:クラウド・Linux・ネットワーク
-
クラウド (AWS/GCP/Azure)
- IAMの最小権限
- VPC/Firewallの概念
-
Linuxセキュリティ
- 権限・パーミッション
- SSH設定
-
ネットワーク
- TCP/IP、TLS、DNSの理解
ここはSRE業務で必須の前提。
(2) セキュリティの基本原則
-
書籍
- 「体系的に学ぶ 安全なWebアプリケーションの作り方」(徳丸本)
- 「Real World HTTP」(通信周り)
-
OWASP Top 10
これを知っておくとWebサービスのリスク全体が見えます。
(3) 実践系
-
CTF(Capture The Flag)初心者向け問題
Web脆弱性・ネットワーク解析・ログ解析の感覚が掴めます。 -
クラウドセキュリティのハンズオン
- AWS Well-Architected Labs (Security)
- GCP Cloud Security Foundations
(4) 運用・監視寄り
-
セキュリティ監視ツールの使い方を覚える
- AWS GuardDuty / CloudTrail
- GCP Security Command Center
-
脆弱性スキャン
- Trivy, Clair, Snyk
3. 学習順序のおすすめ
SRE視点では、攻撃手法を深掘りするよりも「守る設計と検知」重視で勉強すると実務に直結します。
- クラウドとLinuxのセキュリティ基礎
- OWASP Top 10でWebの弱点を把握
- ログ・監視・インシデントレスポンスの流れを学ぶ
- 余裕が出たらCTFや脆弱性診断にチャレンジ
4. まとめ
SREのセキュリティは、
- 実装する人ではなく
-
安全に運用・改善する人として
広く知識を持っておくのが重要です。
補足
現場では**「Security Champion」のようにSREの中からセキュリティ担当を立てるケースもあります。
最初は深さより幅広く守るポイントを把握しておく**のが良いです。
次に深掘りしたいのはどっちですか?
- SREがやるべき「セキュリティの実務例」
- 勉強用の具体的なロードマップ(何をどの順番で)
AWS
-
AWSでの環境構築の要点
- 最小単位のインフラ構築
- ALB・ドメイン設定
- teraformで構築
- pipline ci・cdの構築
AWSでの環境構築の要点
ECSで、コンテナを立ち上げるだけだけど、結構要点が詰まっている
- vpc・サブネット
- 10.0.0.0/16
- 10.0.1.0/24 => パブリックサブネット => ecsのコンテナはこの範囲内で作成されることがわかる
- 10.0.0.0/16
- imageのビルドは、--platform linux/amd64のフラグが必要
- mac はarm64で ecrに合わせてあげる必要がある
- コンテナにロール付与
- cloud watch にログを書き込むために権限が必要
- ecrにアクセスの権限も必要
- route table: ネットワークの送信経路を設定
- ECRからimageをとってくるために必要
- IGW
- vpc にアタッチし、ルートテーブに紐付けないと ECRに接続できない
- SG group
- ブラウザからリクエストを受け付ける設定

flowchart LR
user[Browser/Client] -->|HTTP 80->8080| ecs_task[ECS Task go API]
subgraph VPC
subgraph PublicSubnet
ecs_task
sg[SG 8080 open]
end
rt[RouteTable 0.0.0.0/0 -> IGW]
igw[IGW]
end
%% ECSタスクからのログ送信
ecs_task -->|IAM Role: log write| cw[CloudWatch Logs]
%% ECRからのイメージプル
igw --> ecr[ECR Container Image]
ecs_task <-.-> igw
ecs_task -.pull image.-> ecr
%% 関連性
sg -. applied to ENI .-> ecs_task
rt --> igw
- ドメイン適応 + ロードバランサー
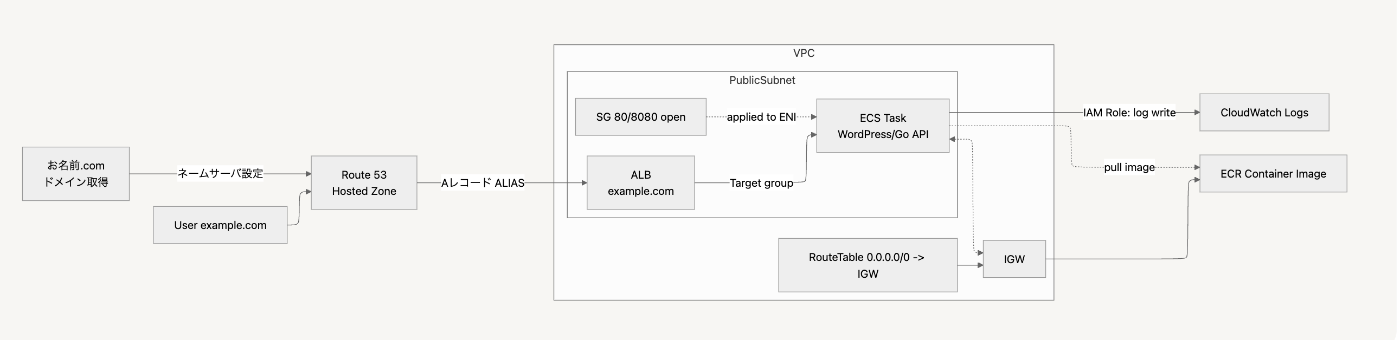
flowchart LR
user[User sample-domain.com] --> route53[Route 53<br>Hosted Zone]
route53 -->|Aレコード ALIAS| alb[ALB<br>example.com]
alb -->|Target group| ecs[ECS Task<br>WordPress/Go API]
ecs -->|IAM Role: log write| cw[CloudWatch Logs]
subgraph VPC
subgraph PublicSubnet
alb
ecs
sg[SG 80/8080 open]
end
rt[RouteTable 0.0.0.0/0 -> IGW]
igw[IGW]
end
%% ECR image pull
igw --> ecr[ECR Container Image]
ecs <-.-> igw
ecs -.pull image.-> ecr
%% SG適用
sg -. applied to ENI .-> ecs
rt --> igw
%% 外部ドメイン
domain_registrar[お名前.com<br>ドメイン取得]
domain_registrar -->|ネームサーバ設定| route53
関連知識
- githubactions
- secrets
- cli のaws でecrの操作
terraform + githubactionsでのフロー
- コード作成
- main.go アプリ
- dockerfile
- ecrのリポジトリを作成 + push
- teraformで環境構築
- ネットワーク
- ecsの構築
- タスクとecrの紐付けの為に1,2の後に実行する
- github actionsでprがマージされたら自動で更新
- github secretsに acces key secretを登録して
terraform
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
tags = { Name = "ecs-test-go"}
}
resource "aws_subnet" "public" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.1.0/24"
availability_zone = "ap-northeast-1a"
tags = { Name: "ecs-test-go-public-subnect"}
}
resource "aws_internet_gateway" "igw" {
vpc_id = aws_vpc.main.id
tags = { Name = "ecs-test-go-igw" }
}
// ルートテーブル iwgを紐付ける
resource "aws_route_table" "public" {
vpc_id = aws_vpc.main.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.igw.id
}
tags = { Name = "ecs-test-go-public-rt" }
}
resource "aws_security_group" "ecs_sg" {
vpc_id = aws_vpc.main.id
name = "ecs-service-sg"
ingress {
from_port = 8080
to_port = 8080
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
// サブネットとルートテーブルを紐づける
// このサブネットに属する リソースは インターネットに接続できる
resource "aws_route_table_association" "public_assoc" {
subnet_id = aws_subnet.public.id
route_table_id = aws_route_table.public.id
}
resource "aws_ecs_cluster" "main" {
name = "ecs-test-go-cluster"
}
# resource "aws_iam_role" "ecs_task_execution_role" {
# name = "ecsTaskExecutionRole"
# assume_role_policy = jsonencode({
# Version = "2012-10-17",
# Statement = [{
# Effect = "Allow",
# Principal = {
# Service = "ecs-tasks.amazonaws.com"
# },
# Action = "sts:AssumeRole"
# }]
# })
# }
# resource "aws_iam_role_policy_attachment" "ecs_task_execution_policy" {
# role = aws_iam_role.ecs_task_execution_role.name
# policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy"
# }
data "aws_iam_role" "ecs_task_execution_role" {
name = "ecsTaskExecutionRole"
}
resource "aws_ecs_task_definition" "go_task" {
family = "go-app-task"
requires_compatibilities = ["FARGATE"]
network_mode = "awsvpc"
cpu = "256"
memory = "512"
# execution_role_arn = aws_iam_role.ecs_task_execution_role.arn
execution_role_arn = data.aws_iam_role.ecs_task_execution_role.arn
container_definitions = jsonencode([
{
name = "go-app"
image = "xxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/ecs_test_go:latest"
essential = true
portMappings = [
{
containerPort = 8080
hostPort = 8080
}
]
logConfiguration = {
logDriver = "awslogs",
options = {
"awslogs-group" = "/ecs/go-app"
"awslogs-region" = "ap-northeast-1"
"awslogs-stream-prefix" = "ecs"
}
}
}
])
}
resource "aws_cloudwatch_log_group" "ecs" {
name = "/ecs/go-app"
retention_in_days = 7
}
resource "aws_ecs_service" "go_service" {
name = "go-app-service"
cluster = aws_ecs_cluster.main.id
task_definition = aws_ecs_task_definition.go_task.arn
desired_count = 1
launch_type = "FARGATE"
network_configuration {
subnets = [aws_subnet.public.id]
assign_public_ip = true
security_groups = [aws_security_group.ecs_sg.id]
}
}
actions
- ecsへの更新
name: Deploy to ECS
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
# リポジトリをチェックアウト
- name: Checkout
uses: actions/checkout@v4
# AWS CLI をセットアップ
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-1
# Docker build & push to ECR
- name: Log in to Amazon ECR
id: login-ecr
run: |
aws ecr get-login-password --region ap-northeast-1 | \
docker login --username AWS --password-stdin 123456789012.dkr.ecr.ap-northeast-1.amazonaws.com
- name: Build, tag, and push image to Amazon ECR
run: |
IMAGE_TAG=latest
ECR_REPO=123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/myapp
docker build -t $ECR_REPO:$IMAGE_TAG .
docker push $ECR_REPO:$IMAGE_TAG
# タスク定義ファイルの更新
- name: Register new task definition
run: |
sed -e "s|<IMAGE>|123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/myapp:latest|" ecs-task-def.json > new-task-def.json
aws ecs register-task-definition --cli-input-json file://new-task-def.json
# ECS サービス更新 (最新タスクでデプロイ)
- name: Update ECS service
run: |
aws ecs update-service \
--cluster my-cluster \
--service my-service \
--force-new-deployment
- ecs-task-def.json の例
- リソース設定(CPU・メモリ)・port・ロール
{
"family": "my-task",
"networkMode": "awsvpc",
"requiresCompatibilities": ["FARGATE"],
"cpu": "256",
"memory": "512",
"containerDefinitions": [
{
"name": "myapp",
"image": "<IMAGE>",
"essential": true,
"portMappings": [
{
"containerPort": 8080,
"protocol": "tcp"
}
]
}
],
"executionRoleArn": "arn:aws:iam::123456789012:role/ecsTaskExecutionRole"
}