概要
仕事でParquetファイル保存したデータをPandasを用いて読み書きしている。
せっかくなのでParquetとはなにかについて調べてみたいと思う。
本記事では、Apache Parquet サイトの内容をDeepLに翻訳を頼りながら読み進めていく。
Apache Parquet とはなにか?
サイトのトップには以下のように書いている。
Apache Parquetは、効率的なデータ保存と検索のために設計されたオープンソースの列指向データファイル形式です。
複雑なデータを一括処理するための高性能な圧縮およびエンコード方式を提供し、多くのプログラミング言語や分析ツールでサポートされています。
なるほど。Apache Parquet とは
・効率的なデータ保存と検索のために設計された列指向データファイル形式
・複雑なデータを一括処理するための高性能な圧縮およびエンコード方式を提供している
ものらしい。
列指向データファイル形式とはなにか?
行指向データベース / 列指向データベース の説明が、詳説 データベース ―ストレージエンジンと分散データシステムの仕組みに記載されているため参考とさせてもらう。
データベースを分類する1つの方法は、ディスク上にデータがどのように格納されるか、
つまり行方向または列方向のどちらで格納されるかによるものです。
テーブルは、同じ行に属する値をまとめて格納する水平方向と、同じ列に属する値をまとめて格納する垂直方向のいずれかで区別できます。
行指向データベース
- 1つの行に関連する複数の属性(カラム)がディスク上で隣接して保存される。
- 1つの行のデータをまとめて読み書きしやすいため、トランザクション処理(OLTP)に適している。
※ OLTP : Online Transaction Processing
例

データの並び例

プロダクト
以下に代表されるリレーショナルDB
列指向データベース
- 同じ属性(カラム)のデータがディスク上で隣接して保存される。
- カラム単位でデータがまとまっているため、特定の属性を対象とした集計や分析処理(OLAP)に適している。
※ OLAP : Online Analytical Processing
例
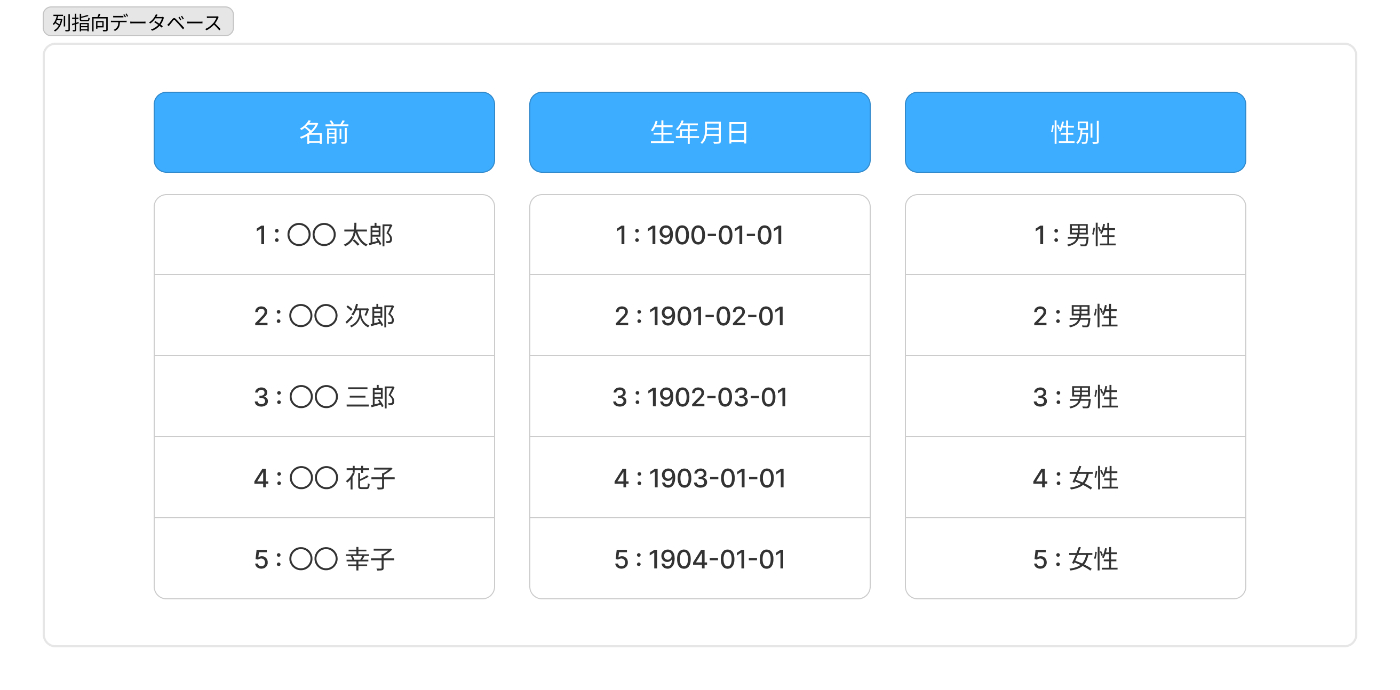
データの並び例

プロダクト
参考URL
Apache Parquet を語るうえ出てくる概念
用語
Block (HDFS block)
-
HDFS : Hadoop Distributed File System
- Hadoop(大規模データ分析アプリ)用に設計された分散型ファイルシステム
- データはブロック単位で分割され、HDFSのDataNode(データを保存するノード) に分散保存される
-
Block :
- 1つのデータを分割する単位
- 通常128MB
-
参考記事
Row Group
- データを論理的に水平に分割したもの。
- 例)行指向データ(ID,名前,生年月日,性別)が10000行あった場合、100行単位で分割して100個のRow Groupを作るイメージ
Column chunk
- 特定の列のデータの塊
- 特定の行グループに存在し、ファイル内で連続していることが保証されている
Page
- Column chunk の中のデータを更に分割した塊
- 圧縮やエンコーディングの観点では、概念的には分割できない単位
Row Group / Column chunk / Page を図で表すと
Parquet File
├── Row Group 1
│ ├── Column Chunk (Col A)
│ │ ├── Page 1 ← 実際のデータ
│ │ ├── Page 2
│ │ ├── ...
│ ├── Column Chunk (Col B)
│ │ ├── Page 1
│ │ ├── Page 2
│ │ ├── ...
│ ├── Column Chunk (Col C)
│ │ ├── Page 1
│ │ ├── Page 2
│ │ ├── ...
├── Row Group 2
│ ├── Column Chunk (Col A)
│ │ ├── Page 1
│ │ ├── Page 2
│ │ ├── ...
│ ├── Column Chunk (Col B)
│ │ ├── Page 1
│ │ ├── Page 2
│ │ ├── ...
│ ├── Column Chunk (Col C)
│ │ ├── Page 1
│ │ ├── Page 2
│ │ ├── ...
└── ...
並列化の単位
- MapReduce : File/Row Group 単位
- I/O : Column chunk 単位
- エンコード/圧縮 : Page 単位
Apache Parquet の定義仕様
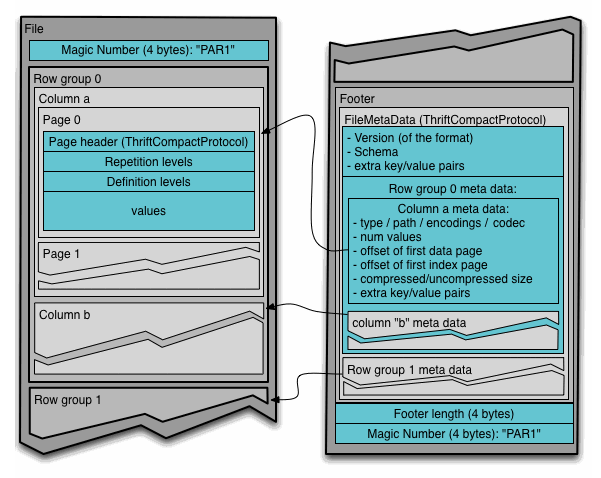
ファイル フォーマット
テーブルに N個の列があり、M個の行グループに分かれている例
- ファイルのメタデータの中にすべての列のチャンクの開始位置が含まれている
- メタデータに含まれる内容は、Thriftの定義に記載されている
- メタデータはシングルパス書き込みを可能にするため、データの後に書き込まれる
- ファイルからデータを読み込むには以下の手順が必要
- メタデータを読む
- メタデータから興味のあるカラムチャンクを見つける
- カラムチャンクを順次読み込む
- メタデータ と データを明確に分離できるように設計されている
- カラムを複数のファイルに分割できる
- 1メタデータファイルで複数のparquetファイルを参照できる
4-byte magic number "PAR1"
<Column 1 Chunk 1>
<Column 2 Chunk 1>
...
<Column N Chunk 1>
<Column 1 Chunk 2>
<Column 2 Chunk 2>
...
<Column N Chunk 2>
...
<Column 1 Chunk M>
<Column 2 Chunk M>
...
<Column N Chunk M>
File Metadata
4-byte length in bytes of file metadata (little endian)
4-byte magic number "PAR1"
https://parquet.apache.org/docs/file-format/ より
設定値
Row Group Size
- Row Group(データを論理的に水平に分割したもの)のサイズ
- Row Group のサイズを大きくすると、Column Chunk も大きくなり、シーケンシャル I/O の効率が向上する
- ただし、メモリ使用量も増えるため、適切なサイズの設定が重要
- おすすめは、512MB 〜 1GB
- HDFS ブロックサイズに合わせるのが理想
- HDFS ブロックサイズも設定可能なので、1 Row Group を 1 HDFS ブロックに収めると効率的
Data Page Size
- Page(Column Chunk 内のデータをさらに分割した最小単位)のサイズ
- エンコーディングおよび圧縮の最小単位
- サイズを小さくすると、エンコード/圧縮時のデータ量が減り、メモリ使用量が抑えられる
- サイズを大きくすると、ページ・ヘッダーの数が減り、パース時のオーバーヘッド(ヘッダー処理のコスト)が軽減される可能性がある
- 一般的な推奨値は 8KB
拡張性
- Parquetフォーマットには、拡張時に互換性を行わないための仕組みがある
- ファイルのバージョン
- ファイルのメタデータにはバージョンが含まれている
- エンコーディング
- エンコーディングはenumで指定され、将来さらに追加される可能性がある
- ページタイプ
- ページタイプを追加し、安全にスキップすることができる
- ファイルのバージョン
メタデータ
- メタデータには、ファイルメタデータとページヘッダーメタデータの2種類がある。
File metadata

Page header

Page の種類
| タイプ | ヘッダー構造体 | 説明 |
|---|---|---|
| DATA_PAGE | DataPageHeader | 古い形式のデータページ |
| DATA_PAGE_V2 | DataPageHeaderV2 | 改良版のデータページ |
| DICTIONARY_PAGE | DictionaryPageHeader | 辞書エンコーディングに使われるページ。出現する値のリストを先に保持し、以降の Data Page でインデックスとして利用。 |
| INDEX_PAGE | IndexPageHeader | 定義はあるが未使用。実装されていない |
型
| タイプ | 説明 |
|---|---|
| BOOLEAN | 1 ビットの真偽値 |
| INT32 | 32ビットの符号付き整数 |
| INT64 | 64ビットの符号付き整数 |
| INT96 | 96ビットの符号付き整数(非推奨・タイムスタンプ用途が多い) |
| FLOAT | IEEE 32ビット浮動小数点数 |
| DOUBLE | IEEE 64ビット浮動小数点数 |
| BYTE_ARRAY | 任意長のバイト配列 |
| FIXED_LEN_BYTE_ARRAY | 固定長のバイト配列 |
論理型
Nested Encoding
Bloom Filter
Data Pages
データページには、3つの情報がページヘッダーの直後に連続してエンコードされて格納される。
ページ内にはパディング(余白や余計なデータ)は一切入れてはいけない。
3つの情報は、次の順番で並んでいる:
- repetition levels data
- definition levels data
- encoded values
ページヘッダー内の uncompressed_page_size の値は、3つの情報をすべて合わせたもの。

- encoded valuesは、必須
- definition levels data と repetition levels data はスキーマ定義に基づくオプション
- カラムが入れ子になっていない(つまり、カラムへのパスの長さが1である)場合、繰り返しレベルはエンコードされない(常に値1を持つことになる)。
- 必須であるデータについては、定義レベルはスキップされる(エンコードされた場合、常に最大定義レベルの値を持つことになる)。
圧縮
- ページ(辞書ページやデータ・ページ)内のデータ・ブロックを圧縮して、スペース効率を向上させることができる
- 圧縮率/処理コストの異なる領域をカバーする複数の圧縮をサポートしている
- 圧縮バッファと伸長バッファの正確な割り当てに必要な情報は、PageHeader構造体に記述されている。
- 圧縮バッファ : PageHeader.compressed_size
- 伸長バッファ : PageHeader.uncompressed_page_size
- 非推奨のLZ4コーデックを除くすべての圧縮コーデックでは、ページの生データは、フレームやパディングを追加することなく、そのまま圧縮ライブラリに供給される
コーデック
UNCOMPRESSED
- データは非圧縮のまま
SNAPPY
- Snappy圧縮フォーマットに基づくコーデック
GZIP
- RFC1952で定義されたGZIP形式に基づくコーデック
LZO
- LZO圧縮ライブラリをベースとした、またはLZO圧縮ライブラリと相互運用可能なコーデック
BROTLI
- RFC 7932で定義されたBrotliフォーマットに基づくコーデック
LZ4
- LZ4 圧縮アルゴリズムをベースにした、非推奨の圧縮コーデック
- このコーデックには 追加で「未公開のフレーミング方式」(データの区切り方)も使われている
ZSTD
- RFC 8478で定義されたZstandardフォーマットに基づくコーデック
LZ4_RAW
- LZ4ブロックフォーマットに基づくコーデック
エンコーディング
Plain: (PLAIN = 0)
- 型に対してサポートされなければならないプレーンエンコーディング
- 最も単純なエンコーディング
- 値を圧縮・変形せず、そのまま(raw binary形式)で連続的に書き出す方法
- プレーンエンコーディングは、より効率的なエンコーディングが使用できない場合に使用される
- データは以下の形式で保存される:
| 型名 | エンコード方式 |
|---|---|
BOOLEAN |
ビットパック(LSB 先頭) |
INT32 |
4バイトのリトルエンディアン |
INT64 |
8バイトのリトルエンディアン |
INT96 |
12バイトのリトルエンディアン(非推奨) |
FLOAT |
4バイト IEEE 754 浮動小数点(リトルエンディアン) |
DOUBLE |
8バイト IEEE 754 浮動小数点(リトルエンディアン) |
BYTE_ARRAY |
先頭4バイトに長さ(リトルエンディアン)、続いてバイト列 |
FIXED_LEN_BYTE_ARRAY |
固定長のバイト列(長さ分のバイトがそのまま) |
- ネイティブ型の場合、データをリトルエンディアンとして出力する
- 浮動小数点型はIEEEでエンコードされる。
- バイト配列型の場合、長さは4バイトのリトルエンディアンでエンコードされ、その後にバイトが続く
Dictionary Encoding (PLAIN_DICTIONARY = 2 and RLE_DICTIONARY = 8)
- 辞書エンコーディング
Checksumming
Column Chunks
- Column Chunk は、複数のページを連続して保持する構成になっている

- ページは、それぞれPageHeader構造体の情報を持っている
- 利用者は、PageHeader構造体を読み、興味のないページを読み飛ばすことができる
- ページ データはヘッダーに続き配置される
- repetition levels data
- definition levels data
- encoded values
- ページ データは圧縮および/またはエンコードが可能で
- 使用した圧縮およびエンコードはPageTypeごとのPageHeader構造体に保持される
- encoding
- repetition_levels_encoding
- definition_levels_encoding
- 使用した圧縮およびエンコードはPageTypeごとのPageHeader構造体に保持される
Error Recovery
Nulls
Page Index
- Parquetフッターの列インデックスページのフォーマットについて
- これらのページにはDataPagesの統計情報が含まれている
- 順序付けされた列や順序付けされていない列のデータをスキャンする際にページをスキップするために使用できる
問題提起
- 以前のバージョンのフォーマットでは、統計情報(statistics構造体データ)はColumnMetaData内のColumnChunksと、DataPageHeader構造体内の個々のページに格納されていた
- ページを読むとき、読者はページヘッダを処理して、統計情報に基づいてそのページがスキップできるかどうかを判断しなければならない
- 必要なページに辿り着くために、カラム内のすべてのページにアクセスしなければならない
- これだと、カラム・データのほとんどをディスクから読み込む可能性がある
Goals
-
統計情報(statistics構造体データ)の最小値と最大値に基づくページへの直接アクセスを可能にすることで、範囲スキャンとポイント検索の両方をI/O効率化する
- 行グループのソート・カラムに基づく行グループ内の単一行検索
- 検索されたカラムごとに1つのデータ・ページしか読み込まないようにする
- ソート列の範囲スキャン
- 関連するデータを含む正確なデータページのみを読み取る必要がある
- 他の選択的スキャンをI/O効率的にする
- ソートされていない列に対して非常に選択的な述語(条件)を持つ場合、他の検索された列に対しては、マッチする行を含むデータページにアクセスするだけでよいはず
- 行グループのソート・カラムに基づく行グループ内の単一行検索
-
選択述語のないスキャン
- 全行グループスキャンでは、追加のデコードの労力は発生しない
- リーダーがインデックスデータを読む必要がないと判断した場合、オーバーヘッドは発生しない。
-
ソートされた列のインデックスページは、ページ間の境界要素のみを格納することにより、最小限のストレージしか使用しない
Non-Goals
- セカンダリーインデックスのサポート
Technical Approach
-
RowGroupのメタデータに、列ごとに2つの新しい構造を追加する:
-
ColumnIndex
- カラム値に基づいてカラムのページへのナビゲーションを可能にする
- スキャン述語(条件)にマッチする値を含むデータページを見つけるために使用される。
-
OffsetIndex
- 行インデックスによるナビゲーションを可能にし、ColumnIndexを介してマッチとして識別された行の値を取得するために使用する。
- ある列の行がスキップされると、他の列の対応する行もスキップされなければなりません。
- したがって、RowGroup内の各列のOffsetIndexは一緒に格納されます。
-
ColumnIndex
-
上記は新しいインデックス構造は、RowGroupとは別にフッター付近(FileMetaDataの上)に格納される。
- リーダが選択的スキャンを行わない場合、それらを読み取るためのI/Oとデシリアライズのコストを支払う必要がないようにするため。
- インデックス構造体の位置と長さはColumnChunk構造体に格納されている。
- ColumnIndexの位置と長さ
- ColumnChunk.column_index_offset
- ColumnChunk.column_index_length
- OffsetIndex構造体の位置と長さ
- ColumnChunk.offset_index_offset
- ColumnChunk.offset_index_length
- ColumnIndexの位置と長さ

- ColumnIndex構造体について
pub struct ColumnIndex {
pub null_pages: Vec<bool>,
pub min_values: Vec<Vec<u8>>,
pub max_values: Vec<Vec<u8>>,
pub boundary_order: BoundaryOrder,
pub null_counts: Option<Vec<i64>>,
pub repetition_level_histograms: Option<Vec<i64>>,
pub definition_level_histograms: Option<Vec<i64>>,
}
- OffsetIndex構造体について
pub struct OffsetIndex {
pub page_locations: Vec<PageLocation>,
pub unencoded_byte_array_data_bytes: Option<Vec<i64>>,
}
- PageLocation構造体について
pub struct PageLocation {
pub offset: i64,
pub compressed_page_size: i32,
pub first_row_index: i64,
}
いつくかの見解
- 最初のページの下限と最後のページの上限を記録する必要はない。均一性を保つため、オーバーヘッドは無視できるほど小さくなります。
ColumnMetaData の Static構造体に min_values、max_values が記録されているため、改めて ColumnIndex に入れる必要はなさそう。
-
ColumnIndex の min_values, max_values には各ページの値の上限値と下限値を保存する。
- 基本的には、ページ上に存在する実際の値の上限値と下限値である。
- そうではなく、ページ上に存在しない(よりコンパクトな)値であることもある。
- 例えば、""Blart Versenwald III""を格納する代わりに
- min_values[i]="B"、max_values[i]="C "と設定することができる
- Writerは大きな値を切り捨てることができる
- これによりインデックス構造のサイズに何かしらの合理的な強制すべきである
-
ColumnIndex構造体をサポートするReaderは、ページ統計を利用するべきではない
- もし、ColumnIndex構造体をサポートするときに、ページレベルの統計情報を書く唯一の理由は、古いReaderをサポートするため(非推奨)
Ordered Columuns の場合、min_values, max_values でバイナリ検索を行うことで、Readerはマッチするページを見つけることができる。
Unordered Columuns の場合、min_values, max_values を順次読み込むことでマッチするページを見つけることができる。
range scans の場合、各列でスキャンする行の範囲、ページインデックス、ページオフセットを返すことができる。Readerは、各列のスキャンを初期化し、スキャンの開始行に早送りすることができる。
min_valuesとmax_valuesは、フッターのFileMetaData構造体のcolumn_ordersフィールドに基づいて計算されます。

ENECHANGEグループは、「エネルギー革命」を技術革新により推進し、より良い世界を創出することをミッションとするエネルギーベンチャー企業です。 enechange.co.jp/
Discussion