Stable Diffusionを試してみた(DALL-Eとも比較)
はじめに
話題のStable Diffusionを試してみました。
Google Colabのほうが手軽に使えますが、今回はローカル環境で試してみました。
DALL-Eとの違い
テキストTo画像生成にかんしては、以前DALL-Eも話題になりました。
DALL-EはWeb画面でプロンプトを入力する必要がありますが、Stable Diffusionはpythonとかプログラムから実行できるのが大きなメリットですね。
あと、実際両者を使ってみて同じ文章を入力しても、それぞれ得意不得意な分野はありそうです。
環境準備
Huggingfaceのアクセストークンを取得
Huggingfaceを利用します。
Huggingfaceにログインして、「Settings」→「Access Tokens」でアクセストークンを取得します。
Access Repositoryに登録
Huggingfaceにログインしたままの状態で、以下にアクセスします。
Jupyter Notebookで実行
使い慣れているJupyterNotebookの環境で実行してみました。
!pip install diffusers transformers
TOKEN="*************************"
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=TOKEN)
「pipe.to("cuda")」でGPUを利用できますが、残念ながらローカル環境はGPUが無いので入れていません。
入力するテキストは適当に以下にしました。
- 「ピカチュウが川で釣りをしている北斎の絵。背景には富士山と東京タワーが見える夏の夕方。」
これを英語にしてpromptに指定します。
prompt = "Hokusai's painting of Pikachu fishing in the river. A summer evening with Mount Fuji and Tokyo Tower in the background.."
image = pipe(prompt)["sample"][0]
結果
こんなのが出ました。
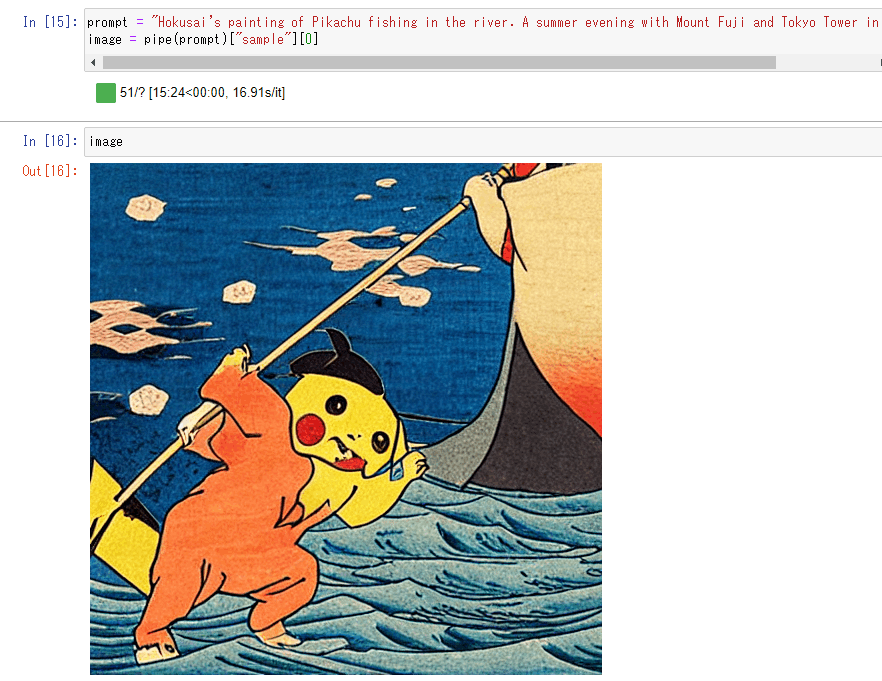
たしかにピカチュウですね。
北斎っぽい絵になっています。
ただ、東京タワーとか富士山の絵が無いので省略されてしまったのかもしれません。
DALL-Eとの比較
まったく同じ文章をDALL-Eでも試してみました。
- 「ピカチュウが川で釣りをしている北斎の絵。背景には富士山と東京タワーが見える夏の夕方。」
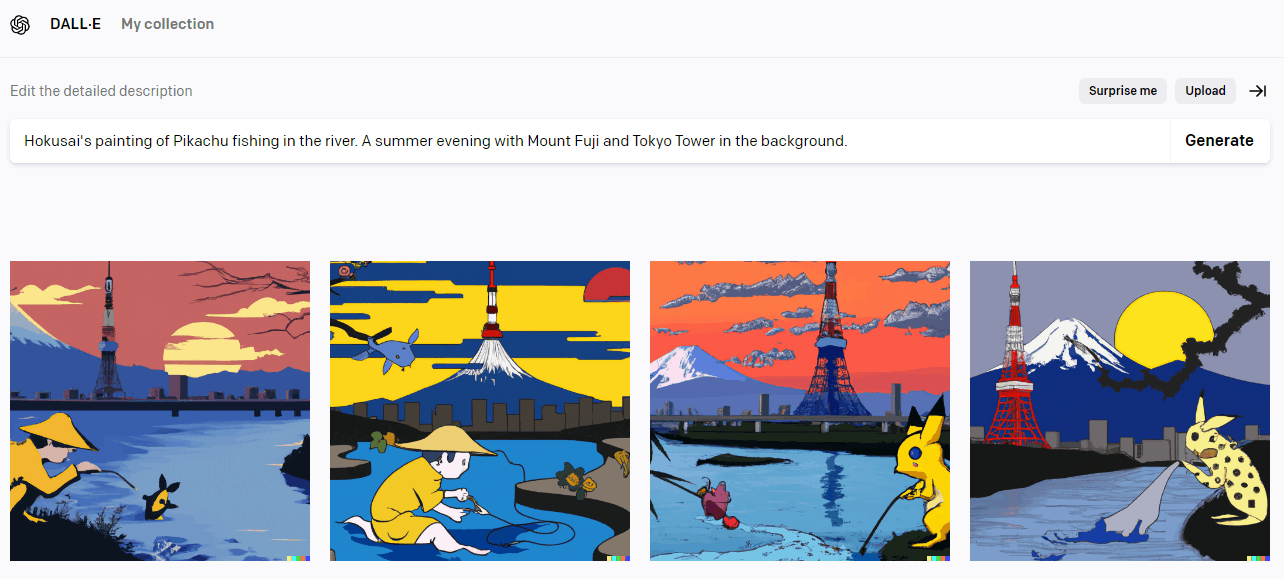
北斎っぽさが薄れましたがDALL-Eのほうは、ちゃんと東京タワーと富士山を描いてくれてますね。
ただ、DALL-Eのほうはピカチュウが残念な感じになっています。
もしかしたらDALL-Eはピカチュウのことを学習してないのでしょうか?
試しに、「スーパーサイヤ人になったピカチュウ」 をDALL-Eに書いてもらいましょう。

ちゃんとピカチュウになりました。DALL-Eでもピカチュウはわかってるようです。
でも文章次第ではピカチュウっぽさが消えてしまうので、プロンプトの文章にはコツが必要そうですね。
まとめ
事前にDALL-Eを使ってましたので、Stable Diffusionの結果にそれほど大きなインパクトはなかったですが、最初に述べたようにプログラムからプロンプトを指定して実行できるのが大きなメリットですね。自動的に繰り返し実行できますので。
Stable DiffusionはDALL-Eに匹敵するという情報も見かけましたが、使ってみた感想としてはDALL-Eのほうが言葉を丁寧に解釈して再現してくれてるような印象がありました。
このあたりは、いろんなプロンプトを指定して比較しないとまだ何とも言えないですが、同じテキストTo画像生成といっても個性はありそうです。
参考記事
実行方法は以下を参考にしました。
Discussion